![]()
This article assumes you're familiar HTML, COM, C++, and JScript.
Download the code (101KB)
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
Data Over the Web? XML Marks the Spot
Joe Graf |
| XML and HTML share a common heritage, but serve complementary purposes. Where HTML is the Web's display language, XML works behind the scenes to serve up an application's data. |
|
In this industry, any technology that is static is probably dead. Like everything else, the HTML content description language has undergone and will continue to undergo evolutionary changes. The introduction of Dynamic HTML is just one example . The Extensible Markup Language (XML) is another. For rich user experiences, there needs to be a flexible method of exchanging data between the client and server. Exchanging data like this within the HTML framework can be a cumbersome task, and this is where XML helps out.
XML was developed to separate data from the user interface. Both HTML and XML have roots in SGML, an early data description language that preceded the Web. XML could be considered "SGML Lite" since it has fewer syntactic requirements than SGML, but shares a number of common features such as opening and closing tags, attributes, and Document Type Definitions (DTDs), which describe the structure of a document. The real power of XML is that a document that employs it can describe its own format. This, coupled with Dynamic HTML, allows for flexible client applications. DTDs describe the format of a document by defining data tags, their order, and the nested structure of the tags. Since the creator gets to define the tags, they can have mnemonic names like <AUTHORS>. Any XML-compatible parser can read any document assuming it is well formed—meaning that every opening tag has a matching closing tag. A validating parser uses the DTD to verify that every required tag is present in the specified order. This makes for a powerful way to create industry-standard methods of data exchange. A number of industries are working on creating standard DTDs for interchangeable data. These vertical market standards will allow the industries to exchange data using either off-the-shelf software or homegrown solutions. Open Financial Exchange (OFX) is one such standard. Even though OFX does not meet the requirements of XML, it gives financial institutions a standard method of connecting customers to their internal data, using Microsoft® Money or Quicken to pay bills and check account balances. Because there is a common specification, banks and brokerage houses can offer this integration into their environments without having to develop multiple solutions for each software client. This is a huge cost and time savings, and it empowers their customers. To illustrate the development of applications that use XML as their data exchange format, I developed a simple three-tier sample application. This suite of applications shows how to receive XML data from a client via HTTP or FTP, and how to return data to the client as an XML document. This rather simplistic client/server implementation will show how easy it is to build more involved systems.
System Overview
|
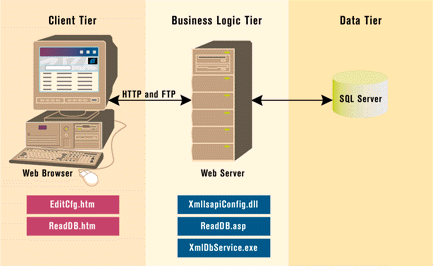
Since the service waits for files to land in a specific directory, there must be a way to configure it to know where to look. This is done with an HTML file on the client side and an ISAPI DLL on the server side. The configuration data is stored in the Windows NT registry. Both the client and server applications use the Microsoft COM-based XML parser, MSXML, to process the XML documents.
The Client Tier
Before you start testing the database bulk loading, you'll need to configure XmlDbService. You do this by reading the current configuration from the remote server, using an ISAPI DLL as the intermediary. The ISAPI command reads the server's settings and returns them as an XML document. The following code is an example of an XML document:
|
|
Using the MSXML COM component and JScript™, you can parse the XML document and copy the data into the form within the HTML page (see Figure 2). When the user commits the new settings, the form gets POSTed to the ISAPI DLL, where it saves the settings via the server's COM interface. |
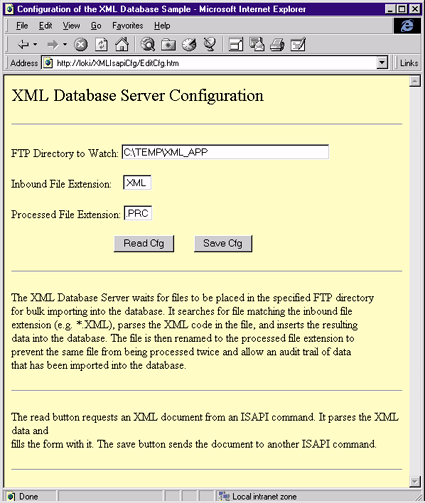 |
| Figure 2: Configuring XmlDbService |
|
There are four elements to the XML document. The <DBBULKCFG> element is the parent wrapper for all of the other elements. It contains no data itself because its main purpose is to act as the root node of the XML tree. The root node of the tree has special meaning for the MSXML parser; all other children are accessed through this node (see get_root in Figure 3). The remaining three elements contain the
configuration data. <FTPDIR> is the directory that the service is meant to watch, <INEXT> is the file extension to look for, and <PROCEXT> is the new file extension given to the file name once the processing is done. If the server has not yet been configured, these values will be C:\, .XML, and
.PRC, respectively.
Before I get into a discussion of how the XML file is retrieved and then processed using JScript, it is important to understand the object hierarchy that MSXML exposes through OLE Automation (see Figure 4). Three objects are used: the document, the element collection, and the element. The document object, IXMLDocument, loads XML documents and maintains the information that is normally found in the XML header and other related state data. This includes the character set used, the size of the document, the version of XML the document adheres to, and the document's MIME type. This interface also loads XML documents using the put_URL method. The put_URL method is executed synchronously; this is actually bad form, since it blocks the browser's screen updates while waiting for a large XML file to parse. Although this will be fixed in future releases, it's good practice to use window.setTimeout just in case. Two other non-state-related methods are createElement, which creates a new IXMLElement that can then be added to the document, and get_root, which returns the root node (an IXMLElement) for this document's XML tree. The get_readyState method is of particular interest as it reports the internal state of the XML parser as it goes through the stages of loading and parsing the document.
The methods of the IXMLElement interface are grouped into to three categories: navigation, child maintenance, and state maintenance. The navigation methods allow you to move through the tree by getting child elements or a parent element. You can navigate to the children in the tree by using the get_children method, which returns an IXMLElementCollection, then using this object's item method. The child maintenance functions let you add or delete child elements. The state maintenance functions give you access to the tag name, tag value, its attributes, and the element's type. Unfortunately, the attributes cannot be gathered into a collection and then enumerated—unless you're running Internet Explorer 4.01 Service Pack 1 (http://www.microsoft.com/windows/ie/download/windows.htm), which adds an attribute collection—so you have to know which attributes can be present on a given tag. The final object in the hierarchy is the IXMLElementCollection (see Figure 6). This is a standard OLE Enumeration collection. It gathers child elements into an object, which allows for easy enumeration. Child elements are retrieved by either index, name, or both. Since the MSXML parser does not enforce order (it's nonvalidating), use care when retrieving elements by index. Now let's look at the JScript-based code that handles XML document configuration. JScript execution starts when the user chooses the Read Cfg button on the HTML form (see Figure 2). This action calls the following function: |
|
|
As you can see, there isn't much going on at this point. The MSXML parser object is created and assigned to a variable. The next line is where the work takes place: it tells the IXMLDocument object to load a URL. For security reasons, this URL must reside in the same virtual directory as the EditCfg.htm file. The code then pauses for 100 milliseconds while it gives the parser the chance to fetch and parse the data. Because of the speed restrictions inherent on the Internet, it is unlikely that the parsing will finish by the time it enters the FillForm function.
If you remember from the discussion of the IXMLDocument, the get_readyState method is used to determine where the parser is in its internal state machine. The FillForm JScript function polls the ready state until the document has finished parsing (see Figure 7). This function checks the ready state of the document and, if it has not yet completed parsing, it sleeps for another 100 milliseconds before checking again. Once the parsing is completed, the function sets the root node, which is specified by the <DBBULKCFG> tag. With this root object, a specific item is retrieved by name from the child collection. That element is then queried for the value of the text contained in the element and assigned to the corresponding field in the form. These same principles are used in the dynamically built HTML code that processes the contents of the remote database and turns the records of the XML document into an HTML table. Rather than waiting for the user to tell the JScript code to load and parse the XML document, ReadDB.htm (see Figure 8) automatically reads the XML data upon loading. It uses the same XML schema (DTD) as the XmlDbService that runs in the middle tier. Figure 9 shows a sample file. It borrows the same functional structure to create the MSXML object and poll for the completion of parsing. The only difference in structure is the change of names to OnFetchXmlData and CheckProgress. |
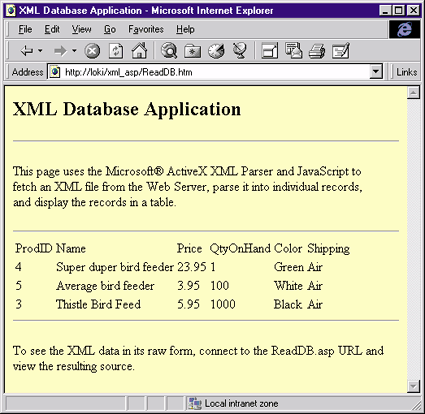 |
| Figure 8: ReadDB.htm |
|
Rather than building the HTML table in the CheckProgress function as I did with the FillForm function in the previous example, the JScript in ReadDB.htm uses a subroutine called BuildXMLTable to handle that processing. It uses the root node as in the previous example. However, there can be an arbitrary number of children in the <ITEMLIST> tag (as seen in Figure 9) prompting for a different method of processing. The first example was nested only one layer deep, while this XML document is two layers deep. Since there is an array of <ITEM> tags in an <ITEMLIST>, the code gathers the children into a collection. It then enumerates each <ITEM> in the collection, building the HTML code for a row in the table using named child resolution as in the previous example. The code snippet in Figure 10 illustrates this.
Now that you understand how the XML data is handled on the client side, it's time to look at the server side of things. The conversion from XML to the database and vice versa occurs in this layer.
Business Logic Tier
|
|
|
This code writes out the individual configuration settings and is wrapped within the <DBBULKCFG> tag.
The final piece that runs on the server is ReadDB.asp (see Figure 12). It uses ADO to gather a recordset of the contents of the Products table. The code walks through the recordset generating an <ITEM> with its child tags for each record. This code is written in VBScript and also shows how much easier it can be to code in an Active Scripting language than in C++ when Automation is involved.
Data Tier
|
|
|
This information is only accessed directly via the COM interface within XmlDbService. This shows that the data tier is not always a database and can include any persistent storage.
Conclusion
|
From the July 1998 issue of Microsoft Interactive Developer.
