Michael P. Antonovich
When it comes to standards, most programmers would say, "I have preferences, you have biases, and Jon down the hall has prejudices." Yet without standards, code-sharing is like building a custom car–expensive and time-consuming. But standards are more than just a few rules like variable naming, comment usage, and code indenting. In this article, Michael Antonovich looks at proven techniques to make code reuse a reality. In later articles in this new series, he’ll leverage code reuse to create an "assembly line" approach to application design and process automation.
Over the years, I’ve hunted for ways to reuse code across applications. Of course, I’ve used custom libraries of procedures and functions since the FoxBase days. Visual FoxPro supports class libraries and good things like inheritance and encapsulation. But about two years ago, I realized that there’s another dimension to application development. I noticed that users run many similar applications, often on a regular basis. Typically the user interacts with the program to prepare data files, to move data from one directory to another, and to execute a number of small applications in predefined sequences.
With a closer look at the workflow, I discovered that many of these applications used similar sequences of code called in different ways. There are only so many ways to write programs to merge two or more data files, eliminate duplicate records, extract data from one table into another table, and prepare lists of selected fields such as names and addresses. Yet I found that most programs "reinvented" these common code procedures each time they were needed. What a waste! I started wondering if it would be possible to build at least some applications on the fly using small standard modules like an assembly line. To get started, I needed a set of common code modules, or building blocks. Then I could write a program to assemble those blocks into applications without recreating all of the code for each application.
The purpose of this series is to retrace my path of enlightenment toward developing an assembly-line approach to selected application development and deployment. My first step, and thus the focus of this article, was the realization that code normalization is just as important as data normalization. Standards are another critical success factor. This month, I’ll review what I hope are familiar concepts, but if they’re not, I urge you to consider adopting standards and code normalization as the best way to increase the productivity of your programming shop.
Getting started–obey the three rules of application code normalizationYou’re probably familiar with the three rules of data normalization:
• Atomize the fields in each table and remove any redundancy.
• All fields in a table should support the primary index for that table.
• All fields should support only the primary key.
Perhaps you never thought of it before, but creating reusable code follows the same three rules.
Rule 1. All code should appear only once (eliminate redundancy), and the code in any one procedure, function, or object method should perform only one task (it should be atomized).When you think of code reusability, you need to start with the principle of granularity. Whether you’re writing new procedures, functions, or methods in an object, you only want to write as much code as necessary to accomplish that one task. (From this point on, I’ll refer to procedures, functions, and object methods generically as code or modules.) If the code attempts to accomplish two tasks, split the code into two different modules and let one module call the other, or even better, let a third module call both.
Suppose that you have two different modules to calculate interest between two dates. Now further suppose that you find an error in one module when calculating the number of days in February 2000. If you have multiple modules that perform the same calculation, you need to find and correct them all. Miss one, and an application will fail. On the other hand, if you eliminate all duplicate code occurrences except for one and reference that one instance everywhere, you can make corrections at one time, in one place. Okay, deciding on whether to keep that one instance of code as a procedure, function, or object method is open to debate, but the concept of "store once" is what’s important.
The biggest reason developers think they can’t reuse code from a prior project is that they packed too many options into a single procedure, making it too unique. Reduce procedures to a single task, and they’ll be reusable.
Rule 2. All code within a task should enhance and support the requirements of that one task.Let’s assume that you need a function to calculate taxes on an invoice. This function contains code that looks at the customer’s address to identify the state (or country as needed) in which he or she resides and then determines the applicable tax rate to apply. To generalize the code, you’ll want to pass the state name or abbreviation as a parameter to the function. You don’t want to force the tax function to read different tables to get the state name. Why? Unless you’re lucky and are able to define field names from the start, it’s likely that one table will call the field STATENAME, while another might call it STATE or even ST. A solution is to write a separate procedure or a wrapper to read the table and pass the appropriate field to the tax function. The important point is that the act of reading a table doesn’t directly supporting the calculation of the tax rate. But once the state is obtained, performing a simple lookup by state to get the tax rate and return the tax rate does support the tax function’s basic task. In other words, the tax function should only contain steps directly related to determining the appropriate tax rate.
What if the programmer before you (because you would never do this) also included code in his or her tax function to calculate shipping costs? While it’s true that determining shipping costs is related to the customer’s address and, specifically, the state, shipping cost calculations are a different task. Therefore, shipping costs should be calculated in their own code module.
Rule 3. All code within a task should support the primary purpose of the module and nothing else.Let’s continue with the tax code example. What if a data record didn’t include the state name? If the application is an order entry system, you obviously need the state to ship the order. So you might think that as long as you have the ZIP code, you could just perform a quick lookup to identify the state. But finding the state, as important as it is in calculating the tax rate, doesn’t solely support the calculation of the tax. The state name is obviously a field that other program modules such as shipping and billing also need (okay, I’m simplifying here). Determining a missing state isn’t really required solely for the calculation of taxes. Therefore, it should be a separate routine. You can then call this function before or from the tax function to determine the state.
I’m sure that just like there are more than three rules for data normalization, I could find ways to extend these code normalization rules further. I could probably even find valid reasons for breaking the rules, but I’ll leave that for a future discussion.
Encapsulate and standardize everything!Even after you normalize your code, that doesn’t mean that you can easily build applications by executing a sequence of your building blocks. As you start building libraries of normalized procedures, functions, and objects, you must establish standards that allow data to flow seamlessly from one code block to the next. Remember, the ultimate goal is to use code blocks in any sequence with no dependencies and minimal customization. You also want to be able to pull out one code block and insert another module to quickly change the functionality of the application, sort of like plug-and-play programs. To get you started, I’d like to share 10 guidelines to help make module sharing and interchange easier.
Guideline 1. Localize variables.When working with objects, the concept of localized variables is enforced automatically. Variables created in an object can only be seen within the object in which they’re declared, unless you declare them PUBLIC.
Variables declared in procedures or functions aren’t isolated as well. The default behavior allows a variable declared in a procedure or function to be visible to any child process. At first, this sounds great. Variables defined at the top of the call sequence can be used in child processes simply by referencing them. No need for extra work passing variables as parameters. Unfortunately, as many developers found out by accident, forgetting which variables were used two or three levels up the call stack can lead to unexpected results. A common mistake might be for Jon to assign the variable "I" in a FOR-NEXT loop. However, Jon might forget that a command within that loop calls a subroutine that calls a subroutine that uses another FOR-NEXT lookup with the same index "I". By the time execution returns to the parent routine, the value of "I" is usually totally different from when it left. As a result, the loop might terminate, or it might restart at an unexpected index value. In any case, you find Jon scratching his head and wondering why the FOR-NEXT loop in the first routine is "broken."
Use LOCAL and LPARAMETERS liberally. In fact, declare all variables local unless you specifically need to cascade a variable value through the call stack, and under no circumstance less than special presidential order should you use PUBLIC.
Guideline 2. Use an application object for "global" variables.Okay, so what do you do with variables, such as configuration variables, that must be referenced throughout the application? You could stuff them in a configuration file. However, you don’t want to reopen the configuration file each time you need to read the values. All that extra disk access is inefficient.
Another approach is to create a custom object at the start of the application called the APP object. Predefine a basic definition for APP in a class library along with some default information, like program name, company name, and so forth. You might predefine properties that most of your applications will need, even if their values are undefined until the application runs. You can also use this object to include methods that perform common tasks such as turning off the system toolbars and menus, and setting the title bar name. You might even store the current environment into a .VUE file so that it can be restored when the application ends (see the APP object in class DEMOCLASS.VCX in the accompanying Download file).
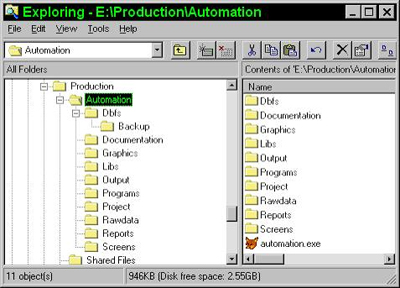
Guideline 3. Use a standard directory structure for each application.Generalized code must work for any application no matter where the application is physically stored. Taking a page from Web design practices, establish a standard directory structure for each application and store the application’s files in this structure. Typically, the basic structure consists of a root directory for the application (sort of like the Web root in HTML). The final executable APP or EXE file together with a configuration file should be the only files in the root. (Yes, exceptions exist. For interpreted programs, I often put the main program here to point to the same start directory as the EXE would report.) Off the root, create subdirectories for each file type. Figure 1 shows a suggested structure.
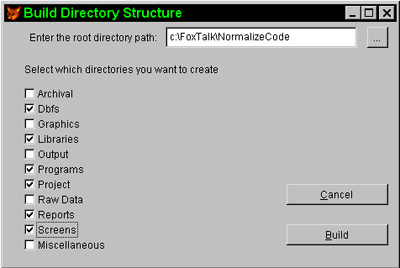
The form BUILDDIR in the code for this article helps to automate this task. Figure 2 shows the screen used to build an application’s directory structure.
My breakdown of subdirectories might not suit your needs. Your directory structure might require additional or fewer subdirectories. Whatever structure you choose, be consistent across all applications. For example, don’t call the subdirectory containing your DBFs \DATA in one application and \DBFS in another. If you do, your standard code modules that reference data will fail. Also, I prefer to name subdirectories using plural names, since they’re containers of multiple instances of that file type. Whatever naming convention you use, stick with it. Over time, you might add new subdirectories, but you should never remove or rename existing ones.
Why bother with directory standards? Well, a standard directory structure allows your application’s generic procedures to reference files using commands like the following (for VFP 6):
For data
cmd = Application.ActiveProject.HomeDir ;
+ "\DATA\" + DataFileName
USE &cmdFor programs
cmd = Application.ActiveProject.HomeDir ;
+ "\PROGRAMS\" + ProgramName
DO &cmdFor reports
cmd = Application.ActiveProject.HomeDir ;
+ "\REPORTS\" + ReportName
REPORT FORM &cmdIf you’re using an earlier version of FoxPro, simply replace the first part of the preceding expressions with your own expression that defines the project’s root directory. For people using VFP5, you may use my procedure SETDEFAULTDIR in the file DEMOPROCS.PRG in this article’s code to determine the application’s home directory.
Guideline 4. Store common code/data in a common subdirectory.Unless your entire development effort consists of a single application, you’ll also need to maintain shared data, libraries, graphics, and other files. The most convenient way to address the need for shared resources is to create a "shared project" using the structure defined in Guideline 3. While I recommend using a separate project container to organize your shared files, your individual application projects will only include references to the shared files needed by that application.
What goes into the shared directories? Any file that two or more applications could potentially use. For example, a table of valid ZIP code ranges by state can be used by more than one application. It should be in the shared \DATA directory. The graphic logo your company uses on forms and reports should be in the shared \GRAPHICS directory. Libraries of functions, procedures, and objects should be in the shared \LIBS directory. You might even have a separate subdirectory for each type of library.
Guideline 5. All modules must be self-contained.Modules must open all files and define all variables that are used (with the exception of the objects like APP that are kept open through the project). Never assume that a table, library, or other file is open. Similarly, never assume that it’s closed, or even that it exists. Rather than include similar code to open or close tables in each module I write, I’ve bent the rule slightly to create support procedures. These procedures perform single tasks like opening or closing a table. In this article’s code, you’ll find a procedure library named DEMOPROCS.PRG. It contains several modules for opening and closing tables to give you an idea what to do. A main module can then call these support modules, passing needed parameters to perform support tasks.
While it’s possible for one module to call another module, remember that any coded references to other modules become a permanent part of the execution of that module. Calling a procedure like OPENFILE to open a table within a module is acceptable because you’ll want to do that each time the main module is run. However, avoid having a main module call another main module. In other words, don’t have the tax calculation module call the shipping cost module. Use a main program to call each module sequentially. Procedures should only be allowed to call support modules as defined in the previous paragraph.
Guideline 6. All modules must clean up after themselves.Modules must close all files they open, release variables and objects they create, and in general return the environment to the same state it was in when the module started. Imagine if people had to do the same thing before they left a room, the beach, or a campsite. This requirement is because the next module can’t assume a state. Of course, variables, files, and objects can be left open if the current module calls a support procedure as defined in the last guideline. Just remember that a module should close or release anything it opens or creates before that module ends. Programmers often forget to clean up temporary files, especially tables and indexes, before leaving an application. Before you know it, the application directory is littered with data droppings from your application. Please curb your code. Also, don’t wait until the end of the application to clean up the mess made by temporary files. Dispose of them as soon as possible, in the same module in which they were created if you can. This way, you’re less likely to orphan temporary files should your system abend.
Guideline 7. Use error handling in all major objects.Error handling is a little different in the object world. Once upon a time, all you needed was a single error routine called by ON ERROR DO <errorhandlername>. And while you can still do that, many other approaches have been proposed for handling errors in objects using the Error event and trapping errors at the lowest level possible. There have been some interesting articles in prior issues of FoxTalk, as well as in other Visual FoxPro magazines and even some DevCon sessions devoted to error handling. Very briefly: You want to handle errors specific to the current class in that class instance’s Error event. But then you also want to bubble up general errors to your base class Error event. Only if the base class Error event can’t handle the error do you want to bubble the error to the container, form, or application error handler. Finally, the ON ERROR DO should only be used as a last resort, because an error here has no place to bubble to except to one of the more helpful VFP error messages such as "Illegal operation error."
Guideline 8. Use subclassing of VFP foundation classes wisely.I know that everyone has heard that you should subclass the VFP foundation classes and bases classes before using them. If you’re not doing this, you should. The most obvious reason is to buffer your application from potential changes Microsoft might make to these classes in future VFP releases. You can then simply modify your subclassed versions to return to the earlier behavior or reinstate original property values.
More importantly, this level of subclassing can be used to implement corporate-wide standards. For example, suppose you always want all forms to have a yellow background with 12-point red Comic Sans MS as a font. Make these changes once in the form subclass and in your subclasses of the other base classes. Store the corporate subclasses in a shared \LIBS directory, as discussed in Guideline 4.
But wait! Don’t build applications directly on this subclass level. Subclass another level from the corporate standard as the application standard. This allows the application to have its own look and feel. Store this subclass level in the application \LIBS directory discussed in Guideline 3.
Guideline 9. Naming variables and fields in tables.Much has been written about naming conventions, which is why I’m not going to repeat it here. Most good VFP books cover naming conventions. Just pick one and stick to it. Rather, I want to talk about extending the naming convention to variables and fields across applications and tables.
Suppose you have a variable used in several applications or a field in multiple tables that represents the same domain, object, or thing. In that case, use the same name. Furthermore, the variable or field should have the same type and size. Suppose you have field ORDERNO that’s an eight-character field in your order entry system. Then your order-processing system should also refer to field ORDERNO as an eight-character field, not a seven-digit numeric field called ORDERNUM. Similarly, your billing modules should use the same field name and characteristics for the order number. To justify using the same name, ask yourself if a field or variable has the same type, size, and domain (or use).
Because you’re trying to create generic modules that plug into any application, it stands to reason that you need to consider the impact of variable names on table fields and variables. Suppose you want to create a program to validate the state customers live in by looking at their ZIP code. In the customer table, you have fields CUSTST and CUSTZIP for the state and ZIP code fields, respectively. You also want to use the same validation routine for suppliers. However, the state and ZIP code fields in the supplier table are SUPPST and SUPPZIP.
You have two choices. First, you could change all tables to use a common name for fields like state and ZIP code, such as STATE and ZIPCODE. However, because the domain of these fields is different–one is Customers and the other is Suppliers–I prefer to retain unique names. The second possibility is to write a "wrapper" around the call to the state validation routine to read the customer fields and pass them as parameters to the generic module that uses local variables STATE and ZIPCODE. Similarly, use a second wrapper to read the supplier fields. I’m still convinced that a cross-application data dictionary can really help here, but that’s another story.
Guideline 10. Get management to buy into the concept of normalizing your code.While normalizing code will benefit your own development, the real benefits only manifest themselves when everyone you work with normalizes their code and adopts common standards. While getting universal acceptance of standards within your development team might be a challenge like putting a man on the moon, the benefits are worth the effort. Not only will you be able to easily share code between developers and projects, but you’ll also be able to more easily debug the errors in Jon’s programs when he goes on vacation for two weeks or takes that job at a competitor for twice your salary. Try to keep standards extensible, but don’t change the standards once they’re adopted.
Next steps
Well, that’s enough on standards to get you started. Next time, I’ll show how to apply these standards to create plug-and-play code blocks from which to assemble applications. I’ll also look at building shared code blocks from procedures, functions, objects, and executable programs. I’ll even explain how to modify a form to allow you to use it both as a standard form and as a non-visual code module.
Download
09ANTON.exeMichael P. Antonovich is a consultant working out of Orlando, FL. He is the author of Using Visual FoxPro Special Edition from Que for VFP 3.0 and 5.0.
www.micmin.com, mike@micmin.com.
{kind=link}
{kind=link}