John M. Dlugosz
You’ve probably heard by now that 8-bit character sets are being shoved out of the way in favor of Unicode. In the Windows world, NT is native Unicode, and not only will Windows 2000 add more abilities in this area, but future languages supported by Windows will be Unicode only (no ANSI code page). Why you need to use Unicode in your programs has been covered more than enough in various globalization and localization articles. In this article, John Dlugosz introduces you to your new friends–they’re quite the characters.
There are numerous names you’ll be encountering concerning character sets and programming techniques for dealing with them. I’ll give you a solid overview of what’s what. First we’ll look at the "old" 8-bit character sets. If you could just jump into Unicode, you wouldn’t need to know this. But much of the work of new "international" programming concerns converting between these schemes and Unicode.
We all know and love ASCII. Some of us have been around long enough to have it memorized. ASCII, also known as ISO-646, contains 96 characters and 32 control codes, for 128 code positions. This was great when it came out, because it had lower-case letters and exotic punctuation missing on older computers.
By the time MS-DOS came around, 8-bit fundamental units of storage was the norm, and the first PCs defined a video ROM with 256 code positions, so any byte, when stuck in video RAM (0xb8000, if anyone cares to reminisce), showed a usable character. However, different countries used a different set of 256 characters. Today in Windows programming, these are known as OEM code pages.
The OEM code pages are still used, in two major ways. First, and most permanently, floppy disks (and FAT-formatted hard disks) use an OEM code page for the filenames in the directories. Second, the text-mode console, even the pure 32-bit console in NT, uses an OEM code page as its default character set. The character set it uses can be changed on the fly.
When Windows came out, it encoded characters differently than DOS. There’s no real need for line drawing characters, bullets, and other non-letters in a graphics environment, while they were very useful in a pure text environment. So Windows left out those characters and instead included more characters useful for other languages. These are the ANSI code pages.
Microsoft based its design of the ANSI code pages on existing standards. Specifically, the English code page I’m most familiar with, since I live in the United States, Microsoft calls 1242, and it looks just like ISO 8859-1 with some extra characters added in. The area from positions 0x80 through 0x9F inclusive is left open for high-bit control codes in ISO 8859. In Windows, useful typesetting characters are stuck in this range.
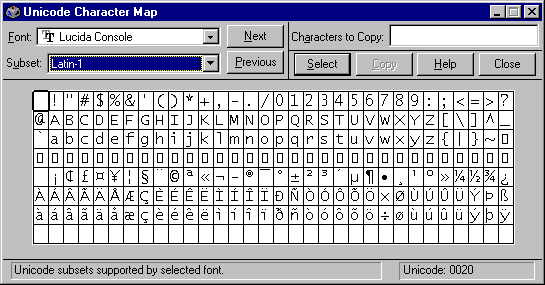
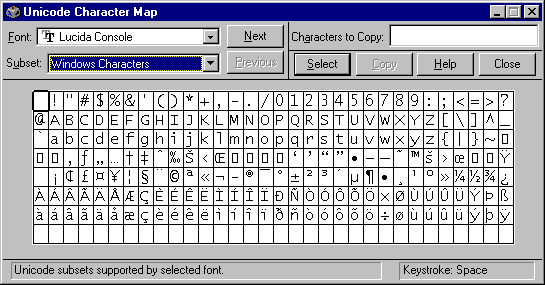
If you’re using NT, you can see the difference easily using the Unicode Character Map accessory. Compare the Latin-1 (see Figure 1) and Windows Characters (see Figure 2) subsets. Latin-1 is commonly used to refer to ISO 8859-1 or to MS’s ANSI 1242, depending on the context.
Microsoft’s Latin-2, code page 1241, is based on ISO 8859-2. The ISO 8859 set of standards extends the old ASCII to eight bits, adding a right-hand-side to the table, with different possibilities for different regions of the world. Many of the ANSI code pages map directly to them.
Unicode
Unicode is based on 16-bit characters. If you define an array of wchar_t, you get 16-bit elements that can hold Unicode strings. While an ASCII chart contains 96 characters, and an ANSI single-byte code table contains 224, the Unicode chart contains around 38,000 characters and fills a book.
A related standard, ISO/IEC 10646, defines exactly the same character tables. The difference is that ISO/IEC 10646 defines a 31-bit character (wow!), so it could hold more than two billion characters. The Unicode standard defines not just the character positions, but also semantics and conformance requirements for programs.
Unicode can be encoded in several different flavors. Once we’ve agreed on what code numbers map to what characters, you still have several ways of representing these values in variables or in a saved file. If you use 32-bit words and save a file such that each group of four bytes represents one character, then you’re using UCS-4. If you write two bytes per character, you’re using UCS-2. More complex variable length encoding schemes, described in more detail later in the article, are UTF-8 and UTF-16.
Beyond 16 bits
Normally, Unicode characters are uniformly 16 bits per code point. I didn’t say 16 bits per character because some codes aren’t characters but are control codes, and in Unicode the accent marks and modifiers all have their own code values, which are suffixed after the base character.
More intriguing is the use of surrogate pairs. A block of 1,024 codes is defined that represent the high half of a pair, and there’s another block of 1,024 that represent the low half. Using a pair of these characters, one from each block, allows you to specify 1,048,576 characters beyond the 64K range of 16 bits! As I write, the only official use for characters beyond 64K are language tags, originally described in UTR #7 and adopted as Internet RFC 2482. But other scripts being added to Unicode will certainly be assigned codes greater than 64K.
If you’re treating every wchar_t element as one position, with no special awareness of surrogate pairs, then you’re using UCS-2. If you recognize these pairs and treat them as single values, then you’re using UTF-16.
Back to 8 bits again
The first 128 positions of Unicode are exactly the same as ASCII, and the first 256 positions are exactly the same as Latin-1. So for many uses, seven or eight bits is sufficient. With this in mind, variable-length encoding schemes can cut the size of storage down by half.
A common scheme is UTF-8. This is used by Web pages and the Perl programming language, and it’s the encoding form of choice when size or compatibility with 8-bit editing or processing tools is an issue.
In UTF-8, a byte that has the high bit cleared is a character having a value less than 0x80. In other words, ASCII letters are directly readable, and pure ASCII text is unchanged if encoded in UTF-8. A sequence of bytes having their high bits set are used to encode characters beyond that range. So text having mostly ASCII characters and an occasional exotic character will be mostly readable in an 8-bit editor, and files like .INI files or source code can contain UTF-8 encoding in ways that don’t bother the tools that process these files.
Another scheme, UTF-7, was designed to cram everything into seven bits and produce encoded values that are safe for old 7-bit mail systems. It’s about as readable as UU-encoding.
Finally, a useful way of compressing Unicode–cutting the size in half for non-Asian languages (UTF-8 cuts the size in half only for Latin-1 languages)–is called UTR #6. This provides for windowing the range of characters actually needed for most of the text, so most of the text takes one byte per character.
Combining characters
In general, various accents and marks are supplied as non-spacing combining characters that are added to a base character. For example, "ê" is coded as U+0065 Latin Small Letter E followed by U+0302 Combining Circumflex Accent. This means that any base character can be given any kind of accent mark, or a combination of marks. This is much more general and flexible than having a unique code for every accented character.
However, there’s also code U+00EA Latin Small Letter E with Circumflex, which has exactly the same meaning. This precomposed character exists because ISO 8859-1 contains such a character, and Unicode intentionally contains single code values to match everything in all common national standards. This facilitates easy round-trip conversion between 8-bit character sets and Unicode, and it means that you can write code that doesn’t deal with combining characters if it doesn’t need more characters than are defined in these other standards (which were presumably enough accented combinations to get by).
However, it means that there might be more than one representation for a given character. It can be a fully precomposed character, or make use of only combining characters, or combine another mark on top of a precomposed character, and the non-spacing marks can be in different orders.
So two strings may be equal in semantic value even though they have different binary representations. To cope with this, the Unicode standard defines a canonical decomposition, or canonical form. This form doesn’t use precomposed characters, and the modifiers are in a specific well-defined order. By converting both strings to canonical form, they can be tested for equality by comparing the bits.
With that introduction to common character sets, you’re ready to start tackling Unicode and international programming issues. Watch for more articles on just those topics in the months to come.
John Dlugosz is a senior software engineer with Kodak Health Imaging in Dallas. In addition to programming and writing, he enjoys computer art, photography, and science fiction.
http://www.dlugosz.com , john@dlugosz.com.
{kind=link}
{kind=link}