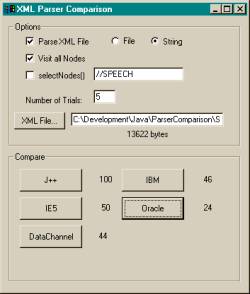
Figure 1: The sample application can compare XML parsers under a variety of conditions.
It seems everyone is working with XML. The good news for Java developers is that you have a vast array of options when it comes to XML parsers. This article compares five, free XML parsers from DataChannel, IBM, Microsoft, and Oracle. It also demonstrates basic XML parsing for each parser, as well as some Java programming techniques.
In addition, an associated example application provides a framework that allows you to easily add custom tests and XML parsers. All source code, a Microsoft Visual J++ 6.0 (VJ6) project, and sample XML files are available for download; see end of article.
MotivationA colleague recently asked me which XML parser I use. Being an avid fan of Microsoft's Visual J++, I told him that I use the parser in the com.ms.xml package. I had no answer when he asked me how it performed compared to other Java parsers. To be honest, I had few complaints with the VJ6 parser, and hadn't given it much thought.
With the recent release of Microsoft's MSXML parser (now available as a separate download from IE5), I decided it was time to compare parsers and make an informed decision. I was surprised by the results, and I think you will be too.
DescriptionThis article makes no attempt to explain what XML is, or why you would use it in your solutions. If you haven't been following XML technology, check out JavaWorld's XML for the absolute beginner at http://www.javaworld.com/javaworld/jw-04-1999/jw-04-xml.html, or the XML section of MSDN at http://msdn.microsoft.com/xml/def ault.asp, for a quick introduction.
This article will provide a brief overview of the application we'll build, followed by complete instructions on the installation and basic use of each of the XML parsers, and finally a detailed comparison of them.
The application (see Figure 1) provides the ability to easily compare XML parsers under a variety of conditions.
Figure 1: The sample application can compare
XML parsers under a variety of conditions.
Through selection of options, you can test each parser's speed in parsing XML from a file or string, visiting each node of the XML document, and performing a selectNodes method from the root node. Additionally, you can change the XML file to parse to determine how the parsers compare on various XML sources.
Installing the ParsersBefore we get into the code, let's first review how to install each of the parsers that we will compare. Note that the installations are fairly mechanical and add little value to the parser comparisons. You can skip reading this section if you don't intend to compile the included Parser Comparison project.
Due to possible licensing restrictions, I don't include the parser libraries with the project, but I do provide instructions on downloading and installing each of the parsers.
Microsoft Visual VJ6 ParserIf you have VJ6 installed, the parser is already installed. If not, you can install the latest Microsoft Java SDK, currently version 3.2 (build 5.00.3182) at http://www.microsoft.com/java/.
Microsoft MSXML ParserIf you have the final release of Microsoft Internet Explorer 5 (IE5) on your computer, this parser should already be installed on your system. If not, go to Microsoft's site and download the parser from http://ms dn.microsoft.com/downloads/tools/xmlparser/xmlparser.asp. The documentation on the site also indicates that you need an updated OLEAUT32.DLL, such as the one that accompanies Microsoft Visual Studio 6.0. Install the parser.
You'll need to add a COM wrapper to your VJ6 project to use the parser. To do this, right click on the project in the VJ6 IDE, and select Add | Add COM Wrapper. The dialog box shown in Figure 2 will appear. Check Microsoft XML, version 2.0 (the 1.0 version was shipped with IE4). Click OK.
Figure 2: The VJ6 COM Wrappers dialog
box.
The wrapper classes are generated and added to your project, as shown in Figure 3 (in the msxmlr folder). These are the classes you'll use to employ the MSXML COM-based parser.
Figure 3: The wrapper classes are
generated and added to your project.
To install the DataChannel XJParser, download it from the DataChannel site at http://xdev.datachannel.com /downloads/xjparser/. Follow the installation directions at the site. They're quite painless; you essentially download and run the installer. This is a pure-Java parser, so no COM wrappers are required.
IBM XML4J ParserTo install the IBM parser, go to the IBM alphaWorks site and download the parser from http://www.alphaworks.ibm.com/tech /xml4j. Unzip the archive and add the xml4j.jar file to your class path. For my project, I simply right-clicked on the project's properties, clicked the Classpath tab, then clicked the New button to add this file to the project's classpath, as shown in Figure 4. Note that you must manually type the path to the file, as there is currently no method to browse for the file.
Figure 4: Click the New
button to add this file to the project's classpath.
To install the Oracle parser, go to Oracle's technet site and download the parser from http://technet.oracle.com/. It's a bit hard to find at first, but click xml under the Technology toolbar on the left to find the parser download page. (I used version 2 for this article.) Unzip the archive and add the xmlparser.jar file to your class path, as shown for the IBM parser.
Now that we've installed the parsers, let's get on to writing some code that will allow us to compare them.
Design and ImplementationThe primary purpose of this article is to compare XML parsers; a secondary goal is to demonstrate some Java programming techniques. As such, I concentrated on creating a flexible design that would allow my test application to treat all the parsers generically. I wrote a ParserInterface interface that defined all my test methods, then created MSJavaParser, MSxmlparser, DCParser, IBMParser, and OracleParser classes that each implemented the ParserInterface.
Each class implementing the ParserInterface deals with its XML parsing specifics. This allows my test application's logic to generically treat all parsers in the same manner via ParserInterface. Another benefit is that additional parsers can easily be plugged in for comparison; you simply create a new class implementing ParserInterface, and you're done. Adding methods to ParserInterface and then implementing them in each of your parser classes allows you to add your own test cases.
Compare Parsers FormThe GUI for the test application (shown in Figure 1) was created by dropping the desired items from the WFC Controls toolbox onto the form. This was all pretty standard WFC stuff, and required little effort on my part, so I won't cover it here.
The application waits until a parser button is clicked, then runs the indicated tests. Various parser options will be performed, and the required milliseconds for execution will be displayed (again, see Figure 1).
I will now briefly describe each input control on the form.
The Parse XML File check box indicates that the time required for the parser to parse is included in the trial. Two radio buttons allow you to choose between parsing from a file, or parsing the file contents from a string.
The Visit all Nodes check box indicates that all nodes within the document should be traversed during the trial.
The selectNodes() check box indicates that the XQL query string in the edit box to the right of the check box should be applied with the document's selectNodes method during the trial. This allows an easy way to select a list of nodes within a document. When using the supplied Hamlet.xml file as a source with the default XQL query of //SPEECH, all nodes within the document that have a tag of SPEECH will be returned. For Hamlet.xml, this is 1,138 nodes. Note that not all parsers support this functionality because the W3C standard for it has not yet been endorsed. (You may want to be cautious in heavily relying on any parser's current implementation of this functionality because the standard may change, which could drastically impact your code.)
To change the file to be parsed, click the XML File button and select a new file.
I've included two sample XML files for testing purposes. The Hamlet.xml file (containing the classic in XML form) is roughly 280KB, and the SmallSample.xml file is roughly 14KB. These files are provided for testing the parsers with XML files of different sizes.
To run the test, set your options, then click the desired parser button. When the Number of Trials is greater than 1, the average milliseconds per trial is displayed next to the button when the test is executed.
The event handling code for each of the buttons is similar, so I'll only discuss the DataChannel button:
private void DCBtn_click(Object source, Event e)
{
try
{
// Run the time trial for the DataChannel parser.
runTimeTrial(DCLabel, new DCParser());
}
catch(Exception ex)
{
showExceptionError(ex);
}
}The runTimeTrial method is called with the appropriate parameters, depending on the button that was clicked. In this example, the time display label for the DataChannel parser and a new DCParser is created and passed to the method. We also catch and display any exceptions that may be thrown.
Depending on which button is clicked, the appropriate parser object is created and passed. For example, when the IBM button is clicked, an IBMParser object is created and passed in as the parser. The event handling code for each of the remaining parsers is essentially the same, so it has been omitted.
The source code for runTimeTrial is shown in Figure 5.
private void runTimeTrial(Control timeDisplay,
ParserInterface theParser)
throws Exception
{
// Run the
time trial for parser theParser, display the
// time
results in control timeDisplay. The ParserInterface
//
interface allows us to treat all parsers generically.
m_StatusLabel.setText("); // Clear status and time display.
timeDisplay.setText(");
// Set
options for the trial.
int numTests =
new
Integer(m_NumberOfTrialsEdit.getText()).intValue();
String xslPatternString =
m_XSLText.getText();
String xmlFileName =
m_FileNameEdit.getText();
//
Pre-load the parser if we aren't parsing.
if
(!m_ParseFileCheckBox.getChecked())
theParser.loadFromFileName(xmlFileName);
// Start
timer.
m_Stopwatch.resetTimer(); &nbs p;
for (int i=0; i<numTests;
i++)
{
if (m_ParseFileCheckBox.getChecked())
{
if (m_FileParseRB.getChecked())
theParser.loadFromFileN ame(xmlFileName);
else
theParser.loadFromStrin g(m_XMLText);
}
if
(m_VisitAllNodesCheckBox.getChecked())
theParser.visitAllNodes();
if (m_SelectNodesCheckBox.getChecked())
{
int n = theParser.selectNodes(xslPatternString);
if (i==numTests-1)
m_StatusLabel.setText(< /SPAN>
"selectNode s()
found " + n + " nodes");
}
}
// Report
the total time.
timeDisplay.setText(
" " +
m_Stopwatch.getAvgMillis(numTests));
}Figure 5: Code for runTimeTrial.
This method takes two parameters: a control and an object that supports the Parser interface. It does the following:
1) Resets display items such as the execution time control and the status display label, which is used to provide messages during the tests.
2) Sets the options for the time trial, such as the number of times to execute the test(s).
3) Pre-loads the XML document if necessary. Pre-loading is necessary when the parsing itself is not included in the test.
4) Loops for the following:
5) Reports the total execution time.
To facilitate calculating the execution time in milliseconds, I created a simple StopWatch class. The source is shown in Figure 6. To use it, I create an instance of the class, call resetTimer before the test, and getAvgMillis at the end of the test.
public class StopWatch
{
protected long m_MarkedMillis;
public StopWatch()
{
resetTimer();
}
public void resetTimer()
{
m_MarkedMillis =
System.currentTimeMillis();
}
public long
getElapsedMillis()
{
long ElapsedMillis =
System.currentTimeMillis()
- m_MarkedMillis;
return ElapsedMillis;
}
public long getAvgMillis(long divisor)
{
return (getElapsedMillis() / divisor);
}
}Figure 6: The StopWatch class.
Now that we've reviewed the code that executes the trials, let's focus on the classes that represent each parser.
The ParserInterface InterfaceJava interfaces are somewhat similar to abstract classes in Java. A key difference, however, is that you cannot specify method implementations or non-static data members in Java interfaces. Because I require no common base class members, I chose to use an interface rather than an abstract class. In general, I prefer using interfaces to abstract classes because interfaces allow you to treat different classes (that do not have a common base class) in the same manner.
The ParserInterface interface defines the methods that all implementing classes must specify:
public interface ParserInterface
{
public void loadFromFileName(String
fileName)
throws Exception;
public void loadFromString(String
xmlString)
throws Exception;
public void visitAllNodes()throws Exception;
public int selectNodes(String
xslString)
throws Exception;
}Each parser works slightly differently, as you'll see when we look at the code for each parser class. This interface allows them to all be treated in exactly the same way by talking to their ParserInterface.
There are two methods used to load the XML document. LoadFromFileName loads from a fully qualified file name, and loadFromString loads from the supplied String parameter. The visitAllNodes method traverses to each node in the XML document. Finally, the selectNodes method performs a XQL query on the XML document, and returns the total number of nodes that were selected.
Now that we've defined an interface, let's create some classes that implement that interface.
VJ6 ParserThe source listing in Figure 7 shows the basic use of the parser that comes with the standard Microsoft VJ6 libraries. Notice that MSJavaParser implements ParserInterface, and all methods from this interface. If you don't implement all the methods, a compilation error will result.
import
java.io.*;
import
com.ms.xml.om.*;
public class MSJavaParser implements ParserInterface
{
protected com.ms.xml.om.Document m_Doc =
new com.ms.xml.om.Document();
public void loadFromFileName(String
fileName)
throws Exception
{
m_Doc.load("file:"+fileName);
}
public void loadFromString(String
xmlStr)
throws Exception
{
// Note that getBytes() converts to the
platform's
// default character encoding which
may not be
// generally acceptable.
m_Doc.load(new BufferedInputStream(
new
ByteArrayInputStream(xmlStr.getBytes())));
}
public void visitAllNodes()throws Exception
{
walkChildren(m_Doc.getRoot().getParent());
}
public int selectNodes(String
xslString) throws Exception
{
throw new
Exception("The J++ Parser does not " +
"directly support a method
that implements XSL " +
"(like
selectNodes()).");
}
protected void walkChildren(
com.ms.xml.om.Element startNode)
{
com.ms.xml.om.Element e = null;
com.ms.xml.om.ElementCollection ec
=
startNode.getChildren();
int numItems = ec.getLength();
for (int i=0;
i<numItems; i++)
{
e =
ec.getChild(i);
// Do something with e.
walkChildren(e);
// Recurse.
}
}
}Figure 7: The basic use of the parser that comes with the Microsoft VJ6 libraries.
I've listed the full class name, com.ms.xml.om.Document, in all the source code to underscore which library the particular class comes from. Most of the parsers are nice enough to use the standard W3C interface types, for example, org.w3c.dom.NodeList. This is advantageous because it allows you to write parser-independent code.
Being a bit older than the others, this parser is not as feature-rich. That aside, it's a nice parser to use due to its simplicity. I like the way it works by chunking nodes into element collections, rather than node lists.
An item to note here concerns the loadFromString method. The load method of the parser wants an InputStream, but we have a String. So, the task is to create an object from the String parameter derived from InputStream. In the days before Java 1.1, this could easily be accomplished by using a StringBufferInputStream. This class, however, has been deprecated with the release of Java 1.1, and the parser hasn't been updated to use a Reader instead of a Stream. In this case, you should just go ahead and use the deprecated StringBufferInputStream class, or you can do what I did and hack together a solution by creating a BufferedInputStream from a ByteArrayInputStream from String's getBytes method (see the code). The downside of this is that getBytes returns a byte array representation of the String according to the platform's default character encoding. For the purposes of this parser comparison, this is fine, but if the String was created using a character encoding incompatible with the system's default, the resulting byte array may be invalid.
This walkChildren method takes an Element parameter, which indicates what node in the document to start walking from. All nodes from startNode down are visited. To do this, we start by getting the collection of child nodes of startNode. We recurse for each item in this collection. This continues in a depth-first manner until all nodes are visited.
Things that I like about this parser are that it seems more Java-like than some of the others, particularly the MSXML parser, and that it's included with the Microsoft JVM installation. It's also simpler to use than the other parsers. It's much more limited, but if your parsing needs are basic, its capabilities may meet them.
The major downside to this parser is that it doesn't implement the latest W3C standards. In fact, Microsoft's Web site indicates that the parser is deprecated and won't be upgraded (http://msdn.microsoft.com/xml /IE4/jparser.asp). They recommend using the DataChannel parser, which has the same functionality as the latest Microsoft MSXML parser.
The online documentation for this parser gets you started, but is incomplete and - in some cases - inaccurate. Fortunately, this parser is easy to implement just using IntelliSense. Another online documentation source is at http://www.microsoft.com/java/sdk/32/start.htm.
Microsoft MSXMLR ParserThe Microsoft XML Parser is implemented as a COM component, so if you're not doing Windows-only development, you cannot use it. If you're using VJ6, though, you probably work in a Windows shop, so this parser makes sense. Thanks to COM, it can easily be used from VC++, VB, VJ6, and script. Because all your developers would be using the same parser, everyone is in the same boat. It allows you to rely on any parser-specific features (such as early XSL implementations), and parsing will be exactly the same for all environments.
The code listing in Figure 8 shows the basic use of the MSXML parser that comes with IE5, which is also now available as a separate installation.
import
msxmlr.*;
import
com.ms.com.*;
public class MSxmlparser implements ParserInterface
{
protected msxmlr.DOMDocument m_Doc =
new msxmlr.DOMDocument();
public void loadFromFileName(String
fileName)
throws Exception
{
// This parser doesn't throw for bad loads,
// so throw for it.
boolean bLoaded =
m_Doc.load(new Variant("file:" + fileName));
if (!bLoaded)
throw new
Exception(m_Doc.getParseError().getReason());
}
public void loadFromString(String
xmlStr) throws Exception
{
// This parser doesn't throw for bad loads,
// so throw for it.
boolean bLoaded = m_Doc.loadXML(xmlStr);
if (!bLoaded)
throw new
Exception(m_Doc.getParseError().getReason());
}
public void visitAllNodes()throws Exception
{
walkChildren((msxmlr.IXMLDOMNode)m_Doc);
}
public int selectNodes(String
xslString) throws Exception
{
msxmlr.IXMLDOMNodeList nl =
m_Doc.selectNodes(xslString);
int numNodes = nl.getLength();
ComLib.release(nl);
return numNodes;
}
protected void
walkChildren(msxmlr.IXMLDOMNode startNode)
{
msxmlr.IXMLDOMNode
n = startNode.getFirstChild();
msxmlr.IXMLDOMNode
sibling = null;
while (n != null)
{
// Do something with n.
walkChildren(n);
sibling
= n.getNextSibling();
ComLib.release(n);
n =
sibling;
}
}
public void releaseDoc()
{
ComLib.release(m_Doc);
}
}Figure 8: The basic use of the MSXML parser that comes with IE5.
A key difference between this parser and the others is that it's a COM object. Throughout the code, you'll notice calls to ComLib.release. My tests revealed that if I didn't manually release the COM object, memory was not reliably reclaimed. For example, I could not parse Hamlet.xml 150 times successively due to memory-related exceptions (each iteration resulted in the loss of 800KB of RAM). Microsoft's COM samples frequently (but not always) call release on their COM objects.
There are many posts on Microsoft's Java-COM newsgroup (http://discuss.microsoft.com/archives/java-com.html) concerning this with the upshot that the JVM should handle the release, but that it doesn't always appear to do so. In any case, manually releasing the COM object allows the JVM to work reliably. Microsoft's technical support indicates that their VM's heuristic for determining when to garbage collect (GC) doesn't take into account the non-GC memory allocated by the COM object and that, in cases like this, it's best to use ComLib.release for timely release of the object.
Another difference I noticed between this and the other parsers is that it doesn't throw an error in the event that the document load fails. To make it behave in a more Java-like manner, I throw for it in this case.
You'll also notice that the walkChildren method differs from the VJ6 parser. This is primarily due to this parser being compliant with the W3C recommendation, which defines the standard methods that this version of walkChildren uses to fully walk the DOM.
Finally, note that you should use the classes named IXMLDOMxyz (versus IXMLxyz, such as IXMLElementCollection) because they are the W3C DOM-compliant classes. It seems logical that Microsoft may, at some point, deprecate the non-compliant interfaces.
Installing MSXMLR leaves you with no documentation. A good documentation source where I have found many specifics on this parser (and XML in general) is http://msdn.microsoft.com/xml/default.asp, although I find it scant on specific examples of using the parser for various tasks. The examples you do find will most likely be in script (JavaScript or VBScript) or VB. In general, I found the documentation included with the other parsers to be more useful. They assume I want to do Java and am at least casually familiar with XML. Additionally, with the others I could very quickly find meaningful examples (code!) of their parser in action.
DataChannel XJParserDataChannel's XJParser was created in partnership with Microsoft, so it works similarly to the MSXML parser. This parser supports Microsoft's standard IXMLDOMxyz interfaces (in addition to the standard W3C interfaces), although I haven't used them specifically. It also supports the same subset of the XSL 1.0 Working Draft that Microsoft IE5 (MSXML) does.
The code listing in Figure 9 shows the basic use of the DataChannel parser.
import
java.io.*;
import
com.datachannel.xml.om.*;
public class DCParser implements ParserInterface
{
protected com.datachannel.xml.om.Document m_Doc =
new com.datachannel.xml.om.Document();
public void loadFromFileName(String
fileName)
throws Exception
{
// Load from file. This seems to work best (the fastest)
// with this parser.
m_Doc.load(fileName);
}
public void loadFromString(String
xmlStr) throws Exception
{
// Note that getBytes() converts to the
platform's
// default character encoding, which
may not be
// generally acceptable.
m_Doc.loadFromInputStream(new BufferedInputStream(
new
ByteArrayInputStream(xmlStr.getBytes())));
// This parser directly supports loading from a String,
// but it is slow, the code above
works much faster. I
// posted to DataChannels newsgroup
for an explanation,
// but have had no response.
// doc.loadXML(xmlStr);
}
public void visitAllNodes()throws Exception
{
walkChildren((org.w3c.dom.Node)m_Doc);
}
public int selectNodes(String
xslString) throws Exception
{
org.w3c.dom.NodeList nl =
m_Doc.selectNodes(xslString);
return nl.getLength();
}
protected void
walkChildren(org.w3c.dom.Node startNode)
{
org.w3c.dom.Node n
= startNode.getFirstChild();
while (n != null)
{
walkChildren(n);
n =
n.getNextSibling();
}
}
}Figure 9: The basic use of the DataChannel parser.
A noteworthy item to mention about this source concerns the loadFromString method. As you can see from the comments, the parser has a method that can load the XML document from a String, but it performs very slowly (taking nearly twice as long) in comparison with loading from an InputStream or file. I posted to DataChannel's newsgroup for an explanation, but have had no response, nor does the parser have a method that can read from a Reader object, so the work-around is to read from an old-fashioned InputStream, which results in near-from file document loads.
Related to this, I wanted to use the XMLInputStream class to load the document, but cannot find it in the DataChannel packages, although DataChannel's samples use it. I also posted concerning this.
Also, note the changes in walkChildren between this parser and the MSXML parser, specifically the use of the org.w3c.dom interfaces. These interfaces enable me to use the same method implementation for any parser supporting these standard W3C interfaces, such as the remaining parsers in this article. Open standards such as this make all our programming lives much easier.
This parser comes with decent documentation and many samples that help get you started right away. DataChannel's Web site (http://www.datachannel.com/) is also an excellent XML information source.
IBM XML4J ParserThe IBM XML4J parser is a pure-Java parser produced by the IBM alphaWorks project. (If you haven't already, you should check out IBM's alphaWorks Web site at http://www.alphaworks.ibm.com/alph aBeans; It's fairly rich in Java content.)
The code listing in Figure 10 shows the basic use of the IBM XML4J parser.
import
java.io.*;
public class IBMParser implements ParserInterface
{
protected com.ibm.xml.parsers.DOMParser m_Parser =
new com.ibm.xml.parsers.DOMParser();
public void loadFromFileName(String
fileName)
throws Exception
{
m_Parser.parse("file:"+fileName);
}
public void loadFromString(String
xmlStr) throws Exception
{
m_Parser.parse(new org.xml.sax.InputSource(
new StringReader(xmlStr)));
}
public void visitAllNodes()throws Exception
{
walkChildren(m_Parser.getDocument());
}
public int selectNodes(String
xslString) throws Exception
{
throw new
Exception("The IBM Parser does not directly" +
"
support a method that implements XSL (like " +
"
selectNodes()).");
}
protected void
walkChildren(org.w3c.dom.Node startNode)
{
// With this parser, nodes of unwanted whitespace
are
// parsed into a TEXT_NODE of whitespace.
It's
// debatable whether this is
correct. There is some
// discussion concerning this on
IBM's Web site. I see
// no way to turn this off, so it
forces you to check
// for these within your code.
org.w3c.dom.Node n
= startNode.getFirstChild();
while (n != null)
{
// Do something with n.
walkChildren(n);
n =
n.getNextSibling();
}
}
}Figure 10: The basic use of the IBM XML4J parser.
The major item of note here is the walkChildren method. With this parser, nodes of whitespace are parsed into a TEXT_NODE of whitespace. It's debatable whether this is the correct behavior. There is some discussion concerning this on IBM's Web site. I see no way to tell the parser to ignore the whitespace, so it forces you to check for these within your code. Some of the other parsers allow you to specify if whitespace should be ignored.
Another item concerns the LoadFromString method. Thanks goes to IBM for supporting parsing from an InputSource, which can easily and safely be created from a StringReader. This allowed me to abandon my hack of creating an InputStream from a String.
As far as eccentricities with this parser, I ran into an issue in using the getChildNodes method. I found cases where getChildNodes would return a list greater than size 0. However, upon accessing the list, a .item call for a valid item would then return null. I reported this bug to IBM, complete with my sample XML file and code. According to IBM's technical support, when the parent node is a text node, the getChildNodes call returns the number of characters of the text node (versus the number of child nodes). A work-around is to check hasChildNodes before calling getChildNodes. If hasChildNodes returns false, don't call getChildNodes.
This parser comes with excellent documentation and samples to help get you started. It's well-organized and allows you to quickly locate resources. Of all the parsers, I felt this one had the best documentation.
Oracle ParserThe Oracle XML v2 parser is an early beta release and is written in Java. Oracle seems to be serious about XML, as a quick visit to their technet site at http: //technet.oracle.com/ demonstrates.
The code in Figure 11 shows the basic use of the Oracle parser.
import
java.io.*;
public class OracleParser implements ParserInterface
{
protected oracle.xml.parser.v2.DOMParser m_Parser =
new oracle.xml.parser.v2.DOMParser();
public void loadFromFileName(String
fileName) throws Exception
{
m_Parser.parse("file:"+fileName);
}
public void loadFromString(String
xmlStr) throws Exception
{
m_Parser.parse(new org.xml.sax.InputSource(
new StringReader(xmlStr)));
}
public void visitAllNodes()throws Exception
{
walkChildren(m_Parser.getDocument());
}
public int selectNodes(String
xslString) throws Exception
{
throw new
Exception("The Oracle Parser DOES provide a " +
"mechanism similar to
selectNodes(), but I did not " +
"implement it.");
}
protected void
walkChildren(org.w3c.dom.Node startNode)
{
org.w3c.dom.Node n
= startNode.getFirstChild();
while (n != null)
{
// Do something with n.
walkChildren(n);
n =
n.getNextSibling();
}
}
}Figure 11: The basic use of the Oracle parser.
I didn't implement the selectNodes test for this parser, although it supports XSL functionality. There was no convenient method such as selectNodes, so I didn't bother. The accompanying documentation includes a sample that demonstrates how to apply XSL style sheets.
The source here is similar to combinations of previous parsers, so I won't discuss it further here. The documentation that comes with this parser is very good and includes numerous meaningful code samples.
With all the code out of the way, it's time to have some fun! How do these parsers compare?
Comparing the ParsersThe table in Figure 12 summarizes the capabilities of these parsers at the time of this writing. Things move quickly, so please check the given URLs to verify that features (or bug fixes) have not been added. You should also note that, for standards that have not yet been endorsed, the implementations may vary and are certainly subject to change.
|
Parser |
|||||
|
Feature |
VJ6 |
MSXML |
DataChannel |
IBM |
Oracle |
|
W3C XML 1.0 (endorsed) |
Yes |
Yes |
Yes |
Yes | |
|
W3C DOM Level 1.0 (endorsed) |
Yes |
Yes |
Yes |
Yes | |
|
W3C XSLT 1.0 (working draft) |
Yes |
Yes |
Yes | ||
|
W3C Namespaces (undergoing review) |
Yes |
Yes |
Yes |
Yes | |
|
Simple API for XML or SAX 1.0 |
Yes |
Yes |
Yes | ||
|
DTDs and validation |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Pure Java |
Yes |
Yes |
Yes |
Yes | |
|
W3C Interfaces |
Yes |
Yes |
Yes | ||
|
Version |
Microsoft JDK 3.2 |
5.00.2314.1000 |
V.1 |
2.0.11 |
2.0.0.0.0 |
Figure 12: Parser features.
The first four rows deal with published W3C standards. "Simple API for XML" is an additional standard that many parsers support. "Pure Java" indicates if the parser is written in Java. "W3C Interfaces" indicates that the parser uses the standard org.w3c.dom.* interfaces in implementing its classes (you can find the Java language binding interfaces for the DOM Level 1 at http://www. w3.org/TR/REC-DOM-Level-1/java-language-binding.html). Finally, "Version" indicates the version of the parser used for these comparisons.
Now that we have the feature comparison out of the way, let's move on to the results of the time trials. Note that, as a developer, I ran all trials with the Microsoft JVM 3.2 debugger enabled. Microsoft's Web site indicates that with Java debugging enabled, performance of all Java applications, applets, and COM objects will be slower. Further details on these registry settings can be found at http://www.microsoft.com/java/sdk/32/start.htm. I didn't spend any time attempting to disable Java debugging, but would be interested to see the effect.
The table in Figure 13 summarizes the test results on my computer (a 266MHz Pentium II with 128MB RAM running Windows NT 4.0 and MS JVM build 5.00.3182) with an XML file that was ~14,000 bytes and contained ~500 nodes (SmallSample.xml). All times are shown in milliseconds.
|
Parser |
|||||
|
Activity |
VJ6 |
MSXML |
DataChannel |
IBM |
Oracle |
|
Parse from File |
95 |
18 |
35 |
44 |
18 |
|
Parse from String |
93 |
13 |
40 |
36 |
18 |
|
Visit Each Node |
6 |
38 |
1 |
3 |
1 |
|
SelectNodes |
- |
3 |
3 |
- |
- |
Figure 13: Moderately sized file parsing.
You can see that for XML files of moderate size, the time required to parse and traverse them is in the same ballpark - 15ms one way or the other is probably not going to make much of a difference in most applications. If you didn't programmatically time-test them, you'd probably have difficulty detecting any speed difference. There is also no significant speed difference in parsing from a String versus from a file.
Parsing larger files, however, revealed more obvious differences in the parsers. Figure 14 summarizes the test results seen on my computer with an XML file of 280KB containing 12,000 nodes (Hamlet.xml). All times are shown in milliseconds.
|
Parser |
|||||
|
Activity |
VJ6 |
MSXML |
DataChannel |
IBM |
Oracle |
|
Parse from File |
1893 |
200 |
900 |
572 |
500 |
|
Parse from String |
1990 |
246 |
960 |
556 |
440 |
|
Visit Each Node |
154 |
913 |
30 |
55 |
16 |
|
SelectNodes |
- |
56 |
110 |
- |
- |
Figure 14: Large-file parsing.
The VJ6 parser is by far the slowest of the bunch, which becomes obvious when working with larger XML streams. While its performance is acceptable for general use, you may want to choose another parser for higher-volume, time-critical XML processing.
When I began this project, I expected the Microsoft COM-based MSXML parser to trounce the pure-Java parsers in all departments, but this was not the case. I actually found that, depending on what you intend to do with your XML, it can actually be slower than a pure-Java parser.
In terms of pure parsing speed, the MSXML parser is definitely the fastest (although the IBM and Oracle parsers are reasonably close behind). However, once you've parsed the document, the lines quickly blur. While the MSXML parser shines in many areas, document traversal is not one of them. It literally takes more than an order of magnitude longer than all other parsers except for the VJ6 parser. In fact, it took four times longer to walk the DOM than it did to parse it.
The DataChannel parser is reasonably fast and very reliable (no longer in beta testing). If you like the MSXML parser functionality, but require a cross-platform solution, this parser could be just what you're looking for.
IBM's XML4J parser is a top-notch all-around performer. It easily out-performed the other production-level (non-beta) parsers.
The Oracle parser is the fastest pure-Java parser of the bunch, although IBM's parser isn't far behind. In terms of performance, the v2 version is a significant improvement over the initial 1.0 release. It's currently in early beta, but looks good so far.
I found it surprising that many of the parsers take longer to parse from a String than they do from a file; I expected the reverse to be true. It's arguable in some cases that this is due to my having to create an InputStream or InputSource from the String, but this doesn't explain the parsers that can directly parse from a String. In many scenarios, I would imagine that Java developers would be parsing from an InputStream, so perhaps parsing from Strings isn't so important. (Related to this, note that the MSXML parser doesn't directly support parsing from an InputStream.)
I included the selectNodes test just for kicks. The XSL recommendation has not yet been endorsed, so I haven't spent much time relying on parsers that have jumped the gun with implementations. In this example, both the DataChannel and MSXML parsers selected ~1300 nodes in respectable time.
In summary, there's no single parser among these five that clearly stands out above the rest. To make the best XML parser selection, you really need to evaluate them based upon your specific needs. For instance, I didn't use a DTD with my XML samples because I didn't need it for my purposes. Other factors influencing your decision may include some of the following:
I would recommend modifying this project and doing an evaluation based upon your specific needs. I've made it easy to add additional tests, parsers, and XML files to the project. Have fun with it!
Which Parser Did I Choose?In my current development effort, I typically parse the XML document once, then traverse it perhaps many times. I also may need the ability to support DTDs and create my own classes using the library classes as base classes.
I like to create my own BaseParser class so I can separate the functionality I need from any vendor's specific implementation. This way, I can easily plug any XML parser into my application with no side effects. In doing this, I often need to expose nodes to the clients of my class. Having a parser that supports the use of the W3C interfaces (org.w3c.dom.*) simplifies this task. For example, I can deal with all nodes as org.w3c.dom.Node instead of having to create a node wrapper class for parsers that don't support the standard interfaces.
I want reasonable performance, but am not concerned over a few milliseconds. I would not sacrifice extensibility or the use of standard interfaces (such as org.w3c.dom.*) for speed unless it were critical to my application, or the speed difference were an order of magnitude. For most of these parsers, the most expensive operation in these tests is to initially parse the file. In my current project, this is a small part of the total processing. For this reason, the performance of any of these parsers is adequate.
As an aside, I always adhere to the 80/20 rule concerning performance (I first saw this in print in Scott Meyers' Effective C++). In general, your code spends 80 percent of its time executing 20 percent of the code. So, if you want to make tangible performance improvements, your only hope is to optimize the 20 percent used most of the time. The only way to accurately target these areas is to profile your code. I can't tell you how many developers I've seen wasting time sweating over the performance of some method when their efforts will most likely make no difference (other than to obfuscate the code, possibly causing bugs). In a nutshell: Profile before optimizing. Then concentrate on changing the code that will make a difference.
Weighing all the facts and considering my current parser requirements, I felt the DataChannel XJParser was the best for my purposes. Its performance is more than adequate at both parsing and document traversal. It's full-featured, well-supported, supports the standard W3C interfaces, and I can extend its classes. Additionally, as other programmers on my team are VC++ and VB programmers, I like having the same functionality as the MSXML parser that they use. My only major complaint is that the source code is not included.
I discounted the other parsers for the following reasons:
All in all, it's nice to have choices and, with Java XML parsers, there are many. In this article, I've given you all the tools you need to make head-to-head comparisons of the most popular parsers available. Determine your parsing requirements, alter my comparison application to test candidate parsers against your requirements, and make an informed decision.
ResourcesYou may find the following URLs useful when dealing with XML:
The code and sample application referenced in this article are available for download.
Tom has been programming professionally for the last 10 years on a variety of platforms (Windows95/NT, Macintosh, and Solaris), languages (Java, C++, C, Pascal ), and development environments. He has also developed three commercially available educational software titles. He lives in the Pacific Northwest and works for SAFECO, where his current duties have him creating an application framework for Web-based applications. Feel free to e-mail Tom at mailto:tpatter@telisphere.com with praise or constructive criticism. If you modify the comparison application to add tests or additional parsers, please send them along as well.
Copyright © 1999 Informant Communications Group. All Rights Reserved. • Site Use Agreement • Send feedback to the Webmaster • Important information about privacy