|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.

This article assumes you're familiar with SQL
Download the code (5KB)
|
Put Advanced SQL Server Features To Work
Carl Nolan
|
SQL is the lingua franca of server-side Web data apps. Some of the advanced features of SQL joins, views, rankings, and computed columns can drastically simplify your code.
| Most browser-centric applications rely on a backend information source, usually in the form of a relational database system. So most developers are very comfortable creating the basic SQL SELECT, INSERT, UPDATE, and DELETE statements. Those of you who need more advanced SQL features would do well to investigate the Microsoft® SQL Server™ implementation of SQL, called Transact-SQL.
I'm going to discuss those advanced SQL features that I have found useful. I will present some common problems and solve them using Transact-SQL. I'll conclude by giving a brief description of the new features of Transact-SQL found in SQL Server 7.0. So that readers can follow along with my examples, I've tried to use the sample Pubs database wherever possible (see Figure 1). (Unless otherwise stated, you can assume that the samples in this article utilize Pubs.)
SQL-92 Join Syntax
One of the most underutilized tools in performing data queries is the SQL-92 join syntax. Joining tables to create new virtual tables is the main advantage of using a relational database system. Most of the time table joining is accomplished by using the WHERE clause in the SELECT statement. Using the join syntax allows you to perform operations that would be otherwise impossible to achieve in a single statement.
|
 |
|
Figure 1: Pubs Database
|
There are three types of joins: inner, outer, and cross. The outer join has three variations: left, right, and full. The results of a left outer join will include all rows from the left side of the join association and all material rows from the table on the right. Similarly, the right outer join will include all rows from the right side of the join association and material rows from the left. The full outer join will include all rows from both sides of the join association. If you use the ANSI join syntax, you can segregate the join operations from the underlying data selection criteria. Although this makes the statement a bit more verbose, it also makes it much easier to understand the join operations. For a clearer picture of what a join can do, see the sidebar, "Joins in 750 Words or Less."
Let's start with a simple example of an inner join. This statement will extract from the Pubs database the names of all the authors in California, along with their titles, sorted by the author's name. To do so, you need to relate the authors to their titles through an intermediate table, titleauthor:
SELECT 'Author Name' = au_lname + ', ' + au_fname, city, state, title
FROM authors AS A, titleauthor AS TA, titles AS T
WHERE A.au_id = TA.au_id -- Join Condition
AND TA.title_id = T.title_id -- Join Condition
AND state = 'CA'
ORDER BY au_lname, au_fname
|
| Looks quite complex, doesn't it? If you explicitly formulate this query using the inner join syntax, it is much simpler to see what the join considerations are:
|
SELECT 'Author Name' = au_lname + ', ' + au_fname, city, state, title
FROM authors AS A
INNER JOIN titleauthor AS TA ON (A.au_id = TA.au_id)
INNER JOIN titles AS T ON (TA.title_id = T.title_id)
WHERE state = 'CA'
ORDER BY au_lname, au_fname
|
| Now let's look at an outer join. Suppose you want to select all authors in California, whether or not they have written any books, and list the titles, if any. Using the explicit join syntax, it is easy to achieve with the following statement:
|
SELECT 'Author Name' = au_lname + ', ' + au_fname, city, state, title
FROM authors AS A
LEFT JOIN titleauthor AS TA ON (A.au_id = TA.au_id)
LEFT JOIN titles AS T ON (TA.title_id = T.title_id)
WHERE state = 'CA'
ORDER BY au_lname, au_fname
|
| The left join is a form of the outer join. Since only outer joins have left, right, and full joins, the word OUTER is optional in the statement, and is usually omitted. The statement says, "give me all authors and their associated titles, even those authors for which there are no titles." Both the left associations are required to carry over the case where there is no title. In this case, omitting either left association will produce a result equivalent to an inner join.
In this case, it is simple to further expand this concept to include all authors and titles regardless of whether the author has any titles or the title has an associated author. By making the join from titleauthor to title a full join, all records from both sides will be included:
|
SELECT 'Author Name' = CASE WHEN au_lname IS NULL THEN NULL
ELSE au_lname + ', ' + au_fname
END,
city, state, title
FROM authors AS A
LEFT JOIN titleauthor AS TA ON (A.au_id = TA.au_id)
FULL JOIN titles AS T ON (TA.title_id = T.title_id)
WHERE state = 'CA' OR state IS NULL
ORDER BY au_lname, au_fname
|
| Whenever you're doing any filtering with a WHERE clause, you must remember to include the possibility of a null resultset (see Figure 2 for the output results).
The third type of join operation is a CROSS join. This is a Cartesian product, containing all the possible combinations of the rows from each of the tables involved in the operation. The number of rows in a Cartesian product of two tables is equal to the number of rows in the first table multiplied by the number of rows in the second table. This result can also be achieved by omitting any join operators. This join usually doesn't produce a valid result, but it can be useful.
In data conversion or scrubbing applications, multiple entries have to be inserted into a table based on the entries in another table. Take, for example, the migration of employee records to a new company. Once the employee table is complete, suppose you want to set up default tax accumulators for each employee. This can be achieved by inserting into the employee tax accumulator table a Cartesian product of the employee table and a temporary table holding all the default tax accumulators (see Figure 3 ).
Basic Subqueries
Transact-SQL has the ability to nest queries, which means you can express WHERE clauses in terms of other SELECT statements. Note that most join operations can be expressed in terms of subqueries, but are usually not as efficient. A simple example would be to select a list of employees whose job description is Editor. Using the join syntax, this query would be formulated like this:
|
SELECT *
FROM employee AS E JOIN jobs AS J ON (E.job_id = J.job_id)
WHERE job_desc = 'Editor'
|
| Using a subquery, you could rephrase the statement like this:
|
SELECT *
FROM employee
WHERE job_id IN (SELECT job_id FROM jobs WHERE job_desc = 'Editor')
|
| Subqueries are usually used in conjunction with the IN, ANY, ALL, and NOT operators. I have omitted the EXISTS statement here since it's almost exclusively used with correlated subqueries. A simple use of the IN operator was shown previously. Instead of using IN, this could have be stated using the operator = ANY. This is important to note because the operator NOT IN is equivalent to <> ALL, not <> ANY (as you might expect).
Take, for example, a query that selects all jobs for which there is no employee. This can be achieved by stating
|
SELECT * FROM jobs
WHERE job_id NOT IN (SELECT job_id FROM employee)
|
| or using the ALL operator as:
|
SELECT * FROM jobs
WHERE job_id <> ALL (SELECT job_id FROM employee)
|
| If you replace the <> ALL with <> ANY, all the jobs in the database would be returned. Why does this happen? The reason is simple: as soon as an employee is found with a different job ID value, the expression will evaluate to TRUE and that row will be selected.
Subqueries can also be used in equality comparisons and assignments. In these cases it is important for the subquery to return a single value. If multiple values are returned, a runtime error will occur. This unique return value can be achieved by using aggregate functions, so
you can request something like, "give me all the titles that earn the maximum royalty."
|
SELECT * FROM titles WHERE
royalty = (SELECT MAX(royalty)
FROM titles)
Correlated Subqueries
Correlated subqueries differ from regular subqueries in that the subquery is evaluated using a row value it receives from the main query. In other words, a correlated subquery is evaluated once for each row found in the outer subquery. In programming terms this is like a nested loop, whereas the basic subquery is a simple loop.
The following example shows how to obtain a list of the authors who have at least one title where they get 100 percent of the royalties:
|
SELECT author = au_lname + ', ' + au_fname
FROM authors AS A
WHERE EXISTS ( SELECT *
FROM titles AS T
INNER JOIN titleauthor AS TA
ON T.title_id = TA.title_id
WHERE TA.au_id = A.au_id -- correlated subquery
AND TA.royaltyper = 100 -- selected criteria
)
|
| As with a lot of correlated subqueries, this query can be expressed as a join:
|
SELECT DISTINCT author = au_lname + ', ' + au_fname
FROM authors AS A
INNER JOIN titleauthor AS TA ON A.au_id = TA.au_id
INNER JOIN titles AS T ON TA.title_id = T.title_id
WHERE TA.royaltyper = 100
|
| The EXISTS statement in the correlated subquery example checks for a non-empty result set, returning a value of TRUE or NOT TRUE. That's why the first statement above uses
SELECT * instead of specifying a column name. This correlated subquery can also be expressed using an IN statement:
|
SELECT author = au_lname + ', ' + au_fname
FROM authors AS A
WHERE au_id IN ( SELECT TA.au_id
FROM titles AS T
INNER JOIN titleauthor AS TA
ON T.title_id = TA.title_id
WHERE TA.au_id = A.au_id -- correlated subquery
AND TA.royaltyper = 100 -- selected criteria
)
|
| As you can see from this example, there is always more than one way to create a subquery. The actual method you use depends on the individual query and data used. In general, if a subquery can be expressed in the form of a join operation, the join form will achieve the best performance.
The power of subqueries comes when using them with aggregate functions. With a correlated subquery, you can locate rows that meet an aggregate expression, an operation that can become very cumbersome using a conventional join syntax. Consider writing a query to select the monthly revenue for each store and title combination where sales are lagging for that title. This question can be broken down into two separate queries. One query would select monthly revenue for each store and title combination, while a second query would calculate the lagging sales metric to be used in filtering the final title's selection. The first part of the query can be expressed as an aggregate expression:
|
SELECT T.title_id, ST.stor_id, DATENAME(mm, SA.ord_date), SUM(T.price * SA.qty)
FROM titles AS T
INNER JOIN sales AS SA ON T.title_id = SA.title_id
INNER JOIN stores AS ST ON SA.stor_id = ST.stor_id
GROUP BY T.title_id, ST.stor_id, DATENAME(mm, SA.ord_date)
|
| Before I can address the second part of the query, I must define what lagging sales means. For this example, I'll define it as a title sold in a store where the revenue for that title across all stores is less than the average. The metric to be calculated is the average revenue, which can be expressed in an aggregate expression:
|
SELECT T.title_id, DATEPART(mm, S.ord_date), AVG(T.price * S.qty)
FROM titles AS T
INNER JOIN sales AS S ON T.title_id = S.title_id
GROUP BY T.title_id, DATEPART(mm, S.ord_date)
|
| When I combine these two queries into a single function, certain things have to happen. Since the outer query is already an aggregate, it will be combined with the correlated subquery with a HAVING relation, not the usual WHERE statement. The subquery's SELECT will consist solely of the AVG function, and the GROUP BY clause will be replaced with a WHERE clause. Since this subquery will return a single value when it's correlated with a WHERE statement, the GROUP BY clause would be redundant:
|
SELECT T.title_id, ST.stor_id,
sale_month = DATENAME(mm, SA.ord_date),
sale_revenue = SUM(T.price * SA.qty)
FROM titles AS T
INNER JOIN sales AS SA ON T.title_id = SA.title_id
INNER JOIN stores AS ST ON SA.stor_id = ST.stor_id
GROUP BY T.title_id, ST.stor_id, DATENAME(mm, SA.ord_date)
HAVING SUM(T.price * SA.qty) < (
SELECT AVG(T_IN.price * S_IN.qty)
FROM titles AS T_IN
INNER JOIN sales AS S_IN ON T_IN.title_id = S_IN.title_id
WHERE T.title_id = T_IN.title_id
AND DATEPART(mm, S_IN.ord_date) = DATEPART(mm, S_IN.ord_date)
)
|
|
Techniques for Updating Data
I assume you're familiar with the basic statements for modifying data: INSERT, DELETE, and UPDATE. Let's look at each statement in turn, focusing on those features that extend their core functionality.
The basic form of INSERT is:
|
INSERT INTO table-name (column-list) VALUES (value-list)
|
| The feature of note here is the value list. The values can be a noncomputed column name, constant, function, variable, or any combination of these values connected by operators. The value cannot be a subquery. It can be expressed by the values NULL or DEFAULT. If, for instance, you want to insert a new order into the sales table for today's date, and the order is a duplicate of the order "X999" called order "X999DUP", the statement would read:
|
DECLARE @qty SMALLINT
SELECT @qty = (SELECT qty FROM sales WHERE ord_num = 'X999')
INSERT INTO sales
VALUES ('7896', 'X999DUP', GETDATE(), @qty, 'Net 30', 'BU2075')
|
| The INSERT operation also lets you replace the VALUES statement with a SELECT statement. This allows much more complicated expressions to be expressed easily, and it also allows multiple inserts within a single expression. Expanding on the previous example, if you want to duplicate all the orders for 1992 with the order number prefixed by "1992", the statement would read:
|
INSERT INTO sales
SELECT stor_id, '1992-' + ord_num, GETDATE(), qty, payterms, title_id
FROM sales
WHERE DATEPART(yy, ord_date) = 1992
|
| In this case the SELECT statement can take any form including joins, subqueries, correlated subqueries, UNION, aggregates, and so on.
This concept can also be extended with the SQL Server command INSERT
EXEC. This operates in the same fashion as INSERT
SELECT, but allows the execution of a stored procedure. This means you can use already created stored procedures, which can encapsulate business rules for the mass inserts. This becomes even more powerful if the stored procedure is located on a remote server. To import all sales information from a remote server called myserver into a local copy of the table, the statement would read:
|
INSERT INTO sales
EXEC myserver.pubs.dbo.sp_sqlexec 'SELECT * FROM sales'
|
| The EXEC statement is calling a standard procedure called sp_sqlexec. This stored procedure expects a SQL statement as a parameter. Since sp_sqlexec resides in the master database, it can be called from any database. For this concept to work the remote server must be defined previously.
When performing data transformation routines, an
important insert option is the SELECT INTO statement. This allows a current table to be selected directly into an as yet undefined table. If you want to create a copy of the sales table,
it can easily be created and populated with a single SQL
statement, like this:
|
SELECT * INTO #sales
FROM sales
|
| The basic form of an UPDATE statement is UPDATE
SET
WHERE. Like the INSERT statement, the SET statement's value can be a noncomputed column name, constant, function, variable, or any combination of these connected by operators. The value can also be a subquery that returns
a single row. This enables row values from one table to be used to update values from another table. To update the discounts table to set the low quantity to be the average of the sales for that store, if the current value is NULL, the statement would read:
|
UPDATE discounts
SET lowqty = (
SELECT AVG(SA.qty)
FROM sales SA, stores ST
WHERE SA.stor_id = discounts.stor_id
AND ST.stor_id = discounts.stor_id
)
WHERE lowqty IS NULL
|
| Expanding on this example, how could you reduce the low quantity by 50 percent for stores in Oregon? This could be performed in the usual way by using a WHERE clause and the IN statement. Transact-SQL, however, provides a better option. The table being updated can be joined to other
tables, for both the selection of rows or the actual values of the update:
|
UPDATE discounts
SET lowqty = lowqty / 2
FROM stores S
WHERE discounts.stor_id = S.stor_id
AND S.state = 'OR'
|
| This same principal can be applied to the DELETE statement. If you wanted to delete the row from the discounts table using the same selection criteria, the statement would read:
|
DELETE FROM discounts
FROM stores S
WHERE discounts.stor_id = S.stor_id
AND S.state = 'OR'
|
| In this example I have deviated from the new join syntax, purely for simplicity. The newer syntax could have been used, but the FROM clause would have to list the original discounts table.
Views and Updateable Views
What is a view? It can be thought of as a SELECT statement that is expressed to the user as a virtual table. Views can greatly simplify data access by reducing the need for a complicated join syntax. If an application always selects information about titles and authors, creating a view for this data can significantly reduce the app's complexity. Such a view could be defined as:
|
CREATE VIEW titleauthorview
AS
SELECT A.*, TA.au_ord, TA.royaltyper, T.*
FROM authors AS A
JOIN titleauthor AS TA ON (A.au_id = TA.au_id)
JOIN titles AS T ON (TA.title_id = T.title_id)
|
| An important thing to note about views is that they are updateable. For a view that is based on a single table, all three types of data modifications work easily. For multiple table views, as in the previous example, things are not so easy. When issuing an UPDATE on a view, all the columns being modified must reside in the same base tables. An INSERT statement also carries this rule, so values on the second table are forced to allow all NULL columns. Finally, a DELETE cannot be issued on a multiple table view.
INSERT statements are not allowed if a computed column exists within the view. Also, UPDATE statements cannot change any column in a view that is a computation, nor can they change a view that includes aggregate functions, built-in functions, a GROUP BY clause, or the DISTINCT statement.
In addition to simplifying data access, views can provide custom views of a single base table based on predefined selection criteria. If an application requires a means for viewing all author details for those authors in California, a simple select statement would suffice. But why not provide this functionality in a view to make things easier for the programmer?
There might be one problem with this approach. What is to stop someone from updating the base information and modifying the state to something other than California? This may not seem a problem at first, but if the data is modified, the row being updated will no longer be part of the selection for the view.
Views provide an easy mechanism to prevent this type of situation: the WITH CHECK OPTION statement. This
direction indicates that the view can be updated, but after the update the row must still be part of the view. The California authors view can be defined by the statement:
|
CREATE View authors_ca
AS
SELECT * FROM authors
WHERE state = 'CA'
WITH CHECK OPTION
|
| Using this view to maintain the authors base table would prevent the state code from being modified. The statement
|
UPDATE authors SET state = 'NY' WHERE state = 'CA'
|
| would be valid, but the statement
|
UPDATE authors_ca SET state = 'NY'
|
| would cause an exception.
Because views are treated as virtual tables that cannot have an ORDER BY clause, a view that needs to be ordered must get this functionality through the SELECT statement that uses the view. For example,
|
SELECT * FROM authors_ca ORDER BY au_lname, au_fname
|
| would sort the California authors by name, since you can't do this in the CREATE VIEW statement.
Another helpful use of views is through the concept of computed columns. Here the view exposes a virtual table consisting of all the columns from a single table, in addition to the computed columns. I'll discuss computed columns in
more detail later. But first, let's work through some examples.
Top Values and Rankings
A common problem in presenting data is obtaining a "best of" listing. By this I mean solving queries such as, "the three most expensive titles we sell" or "the top 5 percent of the best selling stores." Here's how to create a view that retrieves the titles based on a ranking calculated on each title's price:
|
CREATE VIEW titles_rank
AS
SELECT title_id, title, price,
rank = ( SELECT COUNT(DISTINCT ISNULL(T_IN.price, 0))
FROM titles AS T_IN
WHERE ISNULL(T.price, 0) <= ISNULL(T_IN.price, 0)
)
FROM titles AS T
GO
|
| This view calculates a ranking field based on the number of titles that have a price greater than or equal to the current item. As you can see, the rank column is actually a computed column based upon a correlated subquery from the same table. Since the price can be null, the ISNULL statement is used to convert any null values to a zero price.
Using this view, you can answer the question "what are the three most expensive books we sell?" with a very simple expression:
|
SELECT title, price FROM titles_rank WHERE rank <=3
ORDER BY price DESC
|
| Provided the actual ranking number is not required, here's another way to approach this using stored procedures:
|
CREATE PROCEDURE usp_ranking
@ranking INTEGER
AS
SET ROWCOUNT @ranking
SELECT title_id, title, price
FROM titles AS T
ORDER BY price DESC
SET ROWCOUNT 0
GO
|
| Based on query cost, this method of using the SET ROWCOUNT statement is a lot more efficient than the view that calculates the actual ranking. Another benefit of the stored procedure is that it also takes care of the ordering, whereas using a view requires that the requestor formulate the order.
If rankings or a request such as "the top 5 percent of the best selling stores" are required, stored procedures offer another method: utilizing a temporary table. Figure 4 shows a stored procedure that can be used in calculating such a request. In this stored procedure the actual ranking of a store's sales are calculated based on an identity column. Thus the order in which the rows are inserted into the table is important. The procedure also restricts the number of rows returned using the SET ROWCOUNT statement. The number of rows to be returned is calculated based on the number of rows inserted into the temporary table. The globally defined @@ROWCOUNT variable is used for this purpose.
As this stored procedure is primarily designed for applications, it's important to use the SET NOCOUNT statement to ensure that the stored procedure's only output is that of the required SELECT statement. In this example the ranking shown and hence the rows returned is different for items with the same total sales; ties are not considered. Figure 5 shows how this stored procedure could be modified to show the absolute ranking with ties. Here the ranking is calculated in a correlated subquery using the MIN function. The ranking is the minimum of the original ranking for all those rows where the total sales are the same. The number of rows returned is also based on the total sales of the expected last record. Ties will then be included, as they will have the same total sales.
Presenting Tabular Data
A common problem when using relational data is how to present good summary information. The most common way is the cross-tab or pivoting of the data. You can use cross-tabbed tables to answer requests such as "show me the revenue of each store by quarter" or "show me the revenue of each book title by quarter."
Figure 6 shows how the revenue of each book title by quarter can be achieved with a stored procedure by creating an aggregate SUM of a calculated column. The calculated column includes a CASE statement to set the revenue for the returned row to zero when the sale record is not in the required quarterly time frame.
This example could have been implemented utilizing a view. The only downside would have been the inability to perform an ORDER BY on the resulting data. Utilizing a stored procedure also enables you to customize the requested data through the use of parameters to filter the data returned by the use of a WHERE clause on the SELECT statement.
Computed Columns
Looking at Figure 6, you can see that if the sales table contained a column for the year of the sale, the stored procedure's SELECT statement would be simpler to create. Another major benefit would be that the new column could be used as part of an index, which would greatly increase the information retrieval speed. If a clustered index were defined, consisting of the new sales year as the first column, data analysis of the sales information by year would also be improved. This improvement would stem from the information on the sales table being physically grouped by the new sales year column.
The first problem is the maintenance of such a column's value. This is easily solved with triggers. A trigger could be generated to fire upon row insertions and updates and correctly calculate the value of the computed column based on the sales date. Here's how this would be achieved for a new column named ord_year:
|
CREATE TRIGGER sales_maint_year ON sales
FOR INSERT, UPDATE
AS
UPDATE sales
SET ord_year = DATEPART(yy, inserted.ord_date)
FROM inserted
WHERE sales.stor_id = inserted.stor_id
AND sales.ord_num = inserted.ord_num
AND sales.title_id = inserted.title_id
GO
|
| Triggers in SQL Server are fired after the requested operation, but before the changes are committed. Two virtual tables are available for reviewing the modifications. The deleted table contains the rows before the modifications, and the inserted table contains the rows after the modifications. It's important to remember that trigger events are fired after any table constraints are enforced. If an update violates a constraint, the trigger will never actually be performed. Triggers are important when used to enforce referential integrity. Although SQL Server allows the use of FOREIGN KEY constraints, triggers provide a means of implementing other referential actions such as cascading updates, null and default updates, in addition to the basic no action constraint.
Bear in mind that calculating computed columns takes up disk storage. If a computed column is required in very few operations, it may be better presented in a view. In this scenario, a view that includes the computed column could be created on the table. Although the benefits of having the column information persisted are lost, an updateable virtual table is still exposed, supplying the computed columns. This is how such a view would be defined:
|
CREATE VIEW sales_year
AS
SELECT stor_id, ord_num, ord_date, qty, payterms, title_id,
ord_year = DATEPART(yy, ord_date)
FROM sales
GO
|
| Although this view can be used to UPDATE column data, it cannot be used for INSERT operations.
Expanding Hierarchy
An expanding hierarchy (which is often used to display information in a form known as a bill of materials) is a recursive relationship, where a row relates to another row on the same table. This concept is more common than you might expect, and it does not lend itself very easily to SQL-based operations. Any data that
naturally takes the form of a tree structure (like organization charts
or manufacturing bills of materials) can be expressed in an expanding hierarchy.
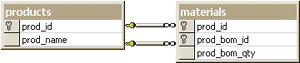
I'll have to leave the safety of the Pubs database to represent this concept. A procedure that delivers this type of information is expected to provide output that shows the implied hierarchy. Taking the scenario of the manufacturing bill of materials, Figure 7 shows what a hierarchical output should look like. This information was derived from two tables: products and materials (see Figure 8). In this situation, a product is defined as a composite of products on the materials table. In turn, each of these products is also similarly defined.
|
 |
|
Figure 8: Products and Materials
|
The output in Figure 7 was requested for product number 10, "Microsoft Press® Visual C++® Team Publications," defined as the level 1 product. This in turn consists of the level 2 products, the last of which is defined by four level 3 products. Finally, the "MFC Reference Library" product is further defined by the reference volumes part 1 and 2. In this output, the quantity represents the number of products that is required to make the parent product, a common scenario in a bill of materials.
The stored procedure that derived the output (see Figure 9) accepts a product number from which to start the expansion. A temporary table of the expansion is derived using a stack concept, onto which the current items to be processed are placed. To start the process, the item to be expanded is placed onto the stack. After this item is processed, it is added into the temporary table and removed from the stack. The stack is then populated with the items directly below the previously processed item in the expansion. This process is repeated for each of these stack items. This process works because, although the stack can contain items from many levels, the highest-level item will always be for a single parent product. The retrieval from the stack is always a single row and is one of the highest-level products. This is ensured by the use of SET ROWCOUNT 1 and the ORDER BY stack_nbr DESC statements.
If the order of the items in the expansion level is important, the materials table could contain a sequence number. Products could then be selected from the materials table ordered on this sequence number. Each stack item also contains a column for the parent product. This parent value is used to calculate the quantity field in the temporary table. It is calculated by reading the material table where the current product is the child of the parent product.
Once the expansion is complete, the temporary table is selected. The order specified in the select statement on the identity column ensures that the order of the selection is the same as the order into which rows were placed into this table. This concept of an expanding hierarchy on a given product number can also be taken in reverse. This would answer the question, "where was this component used?" Given an item, you may want to list all the items that utilize it, again in an expanding hierarchy.
Distributed Queries
In the section on techniques for updating data, I gave
an example of how information could be inserted into a table from a remote server. This idea can be extended in many
ways. A sales summary can be calculated from sales information residing on several remote servers. Using a stored
procedure, an update can be distributed across several servers, and a query can be constructed that combines data from remote servers.
These and many other possibilities lie in the ability of SQL Server to define remote servers and to execute stored procedures on those servers by using the execute syntax:
EXEC ServerName.DatabaseName.DatabaseOwner.StoredProcedureName
|
| An important SQL Server-defined stored procedure is called sp_sqlexec. It allows a dynamically constructed SQL statement to be executed on a remote server. Although this stored procedure is very convenient, it may be better to create a stored procedure on the remote server that represents the required SQL operation.
Let's look at an example. Figure 10 shows how you could report on all authors with a fully qualified state name, where the correct state names are on a table called StateCodes in a database called Common on a central database server. Figure 10 shows how this seemingly complex task could be achieved within a stored procedure. Although this example is trivial, it does outline how heterogeneous queries can be performed utilizing Transact-SQL.
This concept of obtaining data from a remote server and placing it into a temporary table is not just limited to heterogeneous joins. The newly created temporary could just as easily have been used in a UNION statement to create a SELECT that represented composite information from several remote servers.
What's New in SQL Server 7.0?
Everything I've presented so far will work using SQL Server 6.5. You may be wondering what SQL Server 7.0 brings to the table. The new features in SQL Server 7.0 are so numerous that this section can't do justice to even a small portion of them. So I'll just touch on some of the items that can give developers immediate benefits, such as extensions to the SELECT statement, the ability to create computed columns, and how OLE DB extends the heterogeneous environment. First, though, I'll expand on some of the previous topics.
One new feature that's useful in the creation of stored procedures is the ability to use the SET statement for setting local variables:
|
| This brings Transact-SQL more in line with other SQL programming languages, where the SET statement is used for local assignments and the SELECT is used for the selection of rowsets.
I discussed top values and rankings earlier in this article. Although ranking calculations have not changed, the ability to select the top values has been greatly enhanced in SQL Server 7.0 with SELECT extensions for TOP values:
|
SELECT [TOP n [PERCENT] [WITH TIES] ]
|
| Remember the stored procedure that selected titles based on a ranking calculated on title price? Selecting the top three titles is easily achieved in SQL Server 7.0 with the statement:
|
SELECT TOP 3 title_id, title, price
FROM titles AS T
ORDER BY price DESC
|
| Even the more complicated process of selecting the top five percent of the best-selling stores can be expressed as a single SELECT statement:
|
SELECT TOP 5 PERCENT ST.stor_id, ST.stor_name, SUM(SA.qty * T.price) AS tot_sales
FROM stores AS ST
INNER JOIN sales AS SA ON ST.stor_id = SA.stor_id
INNER JOIN titles AS T ON SA.title_id = T.title_id
GROUP BY ST.stor_id, ST.stor_name
ORDER BY tot_sales DESC
|
| If ties are possible, you can account for them by adding the WITH TIES statement. This new SELECT statement is also useful for returning a single row from a table. I often need to set the ROWCOUNT to 1, then back to 0 to select a single row of data. This can now easily be done using the SELECT TOP 1 statement.
SQL Server 7.0 now provides native support for computed columns. To define a computed column, the column name must be followed by an expression defining the column's value:
|
columnname AS computedcolumnexpression
|
| A computed column is a virtual column that's not physically stored in the table, making its implementation analogous to that of a view. Taking the previous example of the order year, the ord_year column may be defined as:
|
ord_year AS DATEPART(yy, ord_date)
|
| The expression can be a noncomputed column name,
constant, function, variable, or any combination of these
connected by operators. The expression cannot, however, be a subquery.
Computed columns can be used in select lists, WHERE clauses, ORDER BY clauses, or any other locations where you can use expressions. You can't use a computed column as a key column in an index or as part of any PRIMARY KEY, UNIQUE, FOREIGN KEY, or DEFAULT constraint definition. You also can't use a computed column as the target of an INSERT or UPDATE statement.
One of my favorite new features in SQL Server 7.0 is the ability to perform heterogeneous queries and updates—functionality previously restricted to Jet database developers. SQL Server now supports the concept of linking servers to OLE DB data sources. After linking to an OLE DB data source, you can reference any rowsets it contains as tables in SQL statements, or pass commands to the OLE DB data sources and include the resulting rowsets as tables in SQL statements.
The distributed queries introduced with SQL Server 7.0 are more powerful and flexible than the earlier methods because tables and views in linked external data sources can be referenced directly in SELECT, INSERT, UPDATE, and DELETE SQL statements. Because distributed queries use OLE DB as their underlying interface, they can access not only traditional relational DBMS systems, but also data managed by data sources of varying types. As long as the software owning the data exposes it in a tabular format through an OLE DB provider, you can get to it through a distributed query. Nontraditional data sources that become available to you include Microsoft Excel, Active Directory Services, and Index Server. Currently SQL Server and Oracle are natively supported via OLE DB, but any ODBC-compliant database is supported through the OLE DB driver for ODBC.
Taking my previous distributed query example, state codes being joined with author information, the entire stored procedure can be expressed as a single Transact-SQL statement:
|
SELECT author = A.au_lname + ', ' + A.au_fname,
A.address, A.city, state = S.state_name, A.exe
FROM authors AS A
INNER JOIN myserver.common.dbo.statecodes AS S ON A.state = S.state
ORDER BY author
|
| Here it assumes that the server myserver is defined as a linked server; previously, it was a remote server. If a linked server has not been defined previously, the new function OPENROWSET can be used to include all connection information necessary to access remote data. The OPENROWSET function can be referenced in the FROM clause of a query as though it's a table name. The OPENROWSET function can also be referenced as the target table of an INSERT, UPDATE, or DELETE statement.
The statement used to select author details can still be
expressed as a single expression, although not in such a simple format:
|
SELECT author = A.au_lname + ', ' + A.au_fname,
A.address, A.city, state = S.state_name, A.zip
FROM authors AS A
INNER JOIN OPENROWSET('SQLOLEDB','myserver';'sa';'password',
'SELECT * FROM common.dbo.statecodes') AS S ON A.state = S.state
ORDER BY author
|
| This example uses the native SQL Server OLE DB driver to create a table of all state codes, which is then joined with the author information.
The OPENQUERY function works a lot like a linked server, except that it executes the specified pass-through query on the given linked server. Once again, the OPENQUERY function can be referenced in the FROM clause of a query as though it is a table name. The OPENQUERY function can also be referenced as the target table of an INSERT, UPDATE, or DELETE statement. Once again, using the authors/state codes example, the statement would read:
|
SELECT author = A.au_lname + ', ' + A.au_fname,
A.address, A.city, state = S.state_name, A.zip
FROM authors AS A
INNER JOIN OPENQUERY(MYSERVER, 'SELECT * FROM common.dbo.statecodes')
AS S ON A.state = S.state
ORDER BY author
|
| Whenever possible, the preferred method of performing these distributed queries should be via a previously defined linked server. The OPENROWSET function should only be used to satisfy ad hoc data retrieval requirements. The power behind OPENQUERY is the ability to pass the query in native format directly to the OLE DB data provider.
Conclusion
If you are fortunate enough to already be using the new features of SQL Server 7.0, great. For everyone else, knowing how to use some of the lesser-known features in Transact-SQL can open up many development options. Many of these features are best implemented with stored procedures, so the ability to create these is a must for any developer.
When you use some of the sample stored procedures through an application interface such as ADO, there is an important point to remember. As some of the stored procedures return a temporary table, which is immediately dropped, the application must use client-side cursors. Finally, remember that many data request requirements cannot be met with a single SQL statement, but stored procedures returning rowsets offer you a vast variety of options in presenting data.

|
From the March 1999 issue of Microsoft Internet Developer.