![]()
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
| Ted Pattison |
| Managing ADO Connections |
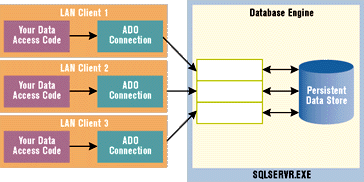
There are many excellent references available to get up to speed on ADO programming. Two popular books are William Vaughn's The Hitchhiker's Guide to Visual Basic and SQL Server (Microsoft Press, 1998) and ADO 2.0 Programmer's Reference, by David Sussman and Alex Homer (Wrox, 1998). Either of these books can give you a thorough overview of the ADO programming model and show you how to execute stored procedures and program with recordset objects. I will assume you have read one of these books or that you have used ADO enough to have intermediate or advanced skills. I want to move beyond ADO basics to look at a few advanced design concepts and programming techniques. A few things make writing data access code for the middle tier very different from writing data access code for a desktop application in a two-tier app. You should know what connection pooling is, how it works, and how it changes the way you're supposed to write your data access code. This month I'll discuss the best way to design and write your ADO code when deploying middle-tier objects in the presence of OLE DB connection pooling. Why You Need Connection Pooling The chore of establishing a database connection usually requires effort on the part of two computers. The client must pass the user's credentials to the DBMS and, in turn, the DBMS must verify the user's identity and return a handle to the client. Establishing connections requires network round-trips and processing cycles on both computers. The idea behind connection pooling is simple. Connections are relatively expensive to open, so an application will perform faster and can scale to accommodate more users if it can share these connections across multiple clients. In a two-tier application, each client must establish its own connection to the DBMS, as shown in Figure 1. The fact that each client application runs in a separate process on a different machine makes it impossible to share many types of resources. In this type of system, a database connection is often established when the user launches the client application, and the connection is held open until the application terminates. |
 |
| Figure 1: Code Creation Settings |
In an attempt to conserve server-side resources, the designer of a two-tier application may decide to close a client's connection whenever the user allows 10 minutes to pass without any activity requiring access to the database. After the connection is closed, the user may issue a command to access the database. In such a case, the client application can reestablish another connection transparently. This approach allows the system as a whole to accommodate more users, but each user experiences a delay every time a new connection must be established with the DBMS.
The architecture for a three-tier application offers several advantages over that of a two-tier application. One significant benefit is the ability to share middle-tier resources such as memory and database connections. As users submit requests from the client tier, objects running on behalf of many different users all run within the same process. This lets you share database connections in a manner that isn't possible in a two-tier application.
Figure 2 shows the high-level architecture of a three-tier application such as those you can build with Visual Basic, ADO, and IIS. When you are building this kind of application, the use of connection pooling will make your code run faster, and it will also allow more users to get by on far fewer database connections. Best of all, you don't have to write the code to share and manage connections across users; it's already built into OLE DB and ODBC. As long as your OLE DB providers and ODBC drivers support this feature, your ADO code will be able to benefit from it automatically whenever it's running inside a middle-tier environment such as MTS and IIS.
How it Works
Automatic connection pooling has been part of ODBC for a while, but it was not until the release of Microsoft Data Access Components 2.0 that connection pooling was added to OLE DB as well. Connection pooling in OLE DB is enabled by an OLE DB service component that works with the OLE DB provider that you are using to talk to the DBMS. You simply open and close ADO connections and the connection pooling is conducted behind the scenes.
Let's look at an example. Suppose you are working with the native OLE DB provider for SQL Server (SQLOLEDB). If all your data access code is accessing a single database inside one computer running SQL Server, OLE DB can place and manage all your connections in a single pool. The first time one of your middle-tier objects creates a new ADO connection object and invokes the Open method, OLE DB must establish an actual connection to the DBMS. However, when you invoke the Close method, OLE DB does not drop the connection to the DBMS. Instead, the connection is placed in a pool so it can be reused by other objects that need it.
When the code running on behalf of another user invokes the Open method on a second ADO Connection object, OLE DB will look in the pool to see if an existing connection is available. If there's already an established connection, your application doesn't need to contact the DBMS. Instead, it can perform its work using the first connection. This speeds things up considerably.
The connection pooling scheme used by OLE DB does have some limitations. A connection pool can only be used by objects inside the same process. As long as all your objects run inside InetInfo.exe or inside a single MTS server package, they can all share the same pool. However, if your objects are split across several processes, there will be a separate pool for each one. You should also note that every connection in a pool must be associated with the same OLE DB provider, server, database, user ID, and password. If your application is connecting to both SQL Server and Oracle, OLE DB will maintain a separate pool for each DBMS. Likewise, you must use the same user ID and password to place all your connections in the same pool. It's important to use the same connect string for every object running inside an application.
When all the connections from the pool are in use and the code for another user attempts to open an additional connection, OLE DB will establish a new connection with the DBMS. This allows the pool to grow dynamically. OLE DB also places a timeout interval on each connection in the pool; OLE DB will automatically close a connection if it remains idle for more than 60 seconds. This allows the pool to shrink to a more efficient size when a peak traffic time is followed by a time with lower activity.
You should also be aware that trappable ADO errors can occur when the DBMS has reached its maximum number of configured connections. You're on your own because neither OLE DB nor ADO will help you handle the errors that are raised from this problem. For instance, if SQL Server is configured to allow 50 connections and the connection pooling scheme attempts to open the 51st connection, your ADO code will experience an error in the call to Open. You must write contingency code to deal with this. The ultimate solution usually involves getting the database administrator to reconfigure the DBMS to allow for a larger number of connections. Note that SQL Server 7.0 is much more forgiving than SQL Server 6.5 when the administrator doesn't expect the number of requested connections to get so high.
Connection Pooling and You
So maybe writing data access code isn't as straightforward as you might have suspected. A call to the Close method doesn't really mean close. Instead, it means release the connection back into the pool. Moreover, a call to Open doesn't really mean open. Rather, it means acquire a connection from the pool. As you have seen, a call to Open may result in growing the pool by one if all the existing connections are already in use.
The most important habit to get into is acquiring connections late and releasing them early. Your objects should never be selfish with a database connection; the sooner your objects release a database connection, the better the chance that each object can acquire a preexisting connection in the pool. However, if your objects are holding on to connections longer than necessary, your application might be establishing connections that it doesn't need. As a result, performance and resource usage will suffer.
Begin your design by acquiring and releasing connections on a per-method basis. Here is a good starting point for a method that contains data access code:
Sub MyMethod()
Dim conn As ADODB.Connection
Set conn = New ADODB.Connection
conn.Open sConnect ' (1) establish connection
'*** your code here (2) conduct read/write operations
conn.Close ' (3) close connection
Set conn = Nothing
End SubLook at the following class definition for the component CCustomerManager.
' class CCustomerManager
Private conn As ADODB.Connection
Sub Class_Initialize()
Set conn = New ADODB.Connection
conn.Open sConnect
End Sub
Sub AddCustomer(ByVal Customer As String)
' code to add new customer record using conn
End Sub
Sub Class_Terminate()
conn.Open sConnect
Set conn = Nothing
End Sub
Dim CustMgr As CCustomerManager
Set CustMgr = New CCustomerManager
CustMgr.AddCustomer "BobbyD"
Set CustMgr = Nothing
To make things worse, imagine what would happen if you had a second component, CProductManager, that was similar to the CCustomerManager component and the client wrote code that looked like this:
Dim CustMgr As CCustomerManager
Set CustMgr = New CCustomerManager
CustMgr.AddCustomer "BobbyD"
Dim ProdMgr As CProductManager
Set ProdMgr = New CProductManager
ProdMgr.AddProduct "Boomerang"Occasionally, during the design phase you might find an acceptable situation to declare an ADO connection object in the declaration section of a class module. This might be the case if you need to call multiple data access methods on one object inside a single request. For example, the client might need to call the AddCustomer method multiple times and you don't want to keep releasing and reacquiring a connection from the pool in a single request. Look at the following class definition of the CCustomerManager class and note the addition of two new methods.
' class CCustomerManager
Private conn As ADODB.Connection
Sub AcquireConnection()
Set conn = New ADODB.Connection
conn.Open sConnect
End Sub
Sub AddCustomer(ByVal Customer As String)
' assume AcquireConnection has been called
' code to add new customer record using conn
End Sub
Sub ReleaseConnection()
conn.Open sConnect
Set conn = Nothing
End Sub Dim CustMgr As CCustomerManager
Set CustMgr = New CCustomerManager
CustMgr.AcquireConnection
CustMgr.AddCustomer "John"
CustMgr.AddCustomer "Paul"
CustMgr.AddCustomer "George"
CustMgr.AddCustomer "Ringo"
CustMgr.ReleaseConnection
Set CustMgr = NothingAs you move into a more complex design, it's up to you to share resources as efficiently as possible once you've acquired them from the pool. This usually requires more attention to detail and well-thought-out collaboration between the objects inside your application.
Doctor, it Hurts when I Do This
Many programmers believe anything that they see in a published article or in sample code downloaded from http://www.microsoft.com must be something worthy of using in their production code. Unfortunately, one ADO programming technique for sharing ADO connections has crept into lots of production ASP sites for the wrong reason. I'd like to describe this technique and why you should avoid it in your designs.
The technique makes use of an ASP Application variable to store an ADO Connection object with an established connection. The idea is that an application-level variable can be used to share an open connection across all the users of an application. Once the connection has been put into an application-level variable, it can be handed out to various users over the lifetime of the application. As long as the programmer is careful to lock and unlock the Application object, all users can get by on a single connection to the DBMS.
However, there are several problems with this approach. First, this technique is trying to repair a problem that has already been solved. The connection pooling built into both OLE DB and ODBC is more sophisticated and faster than any algorithm created by even an advanced Visual Basic programmer. Second, this technique only allows a single user at a time to access the DBMS. When one user is using the shared connection, other users are blocked; they must wait for the connection to become unlocked. You could make your code more sophisticated by managing a collection of application-level connection objects, but you're never going to code up a scheme that's as good as the one that's been provided. Don't reinvent the wheel with another, bumpier wheel. If you see someone else using this technique, suggest that they would be much better off without it.
You should also avoid placing preopened ADO Connection objects inside ASP Session variables. While this will not result in the same blocking problems, it also won't result in sharing connections across different users. Each ASP Session variable is private to a single user. This means there's no way to share these connections across users. What's more, you'll need one connection per user, so it will not scale when you are dealing with hundreds of users. You're much better off using OLE DB connection pooling.
The bottom line is that you should always explicitly acquire and release your connections inside the scope of a single request. Whether you take the simplistic one-connection-per-method approach or something more sophisticated, now you know how to make the most of what's there. The system provides code to manage connection pooling, and as long as you write your code to take advantage of what's already in place, your applications will be as scalable as the underlying infrastructure allows.
|
From the May 1999 issue of Microsoft Internet Developer.
|
