|
SQL BY
DESIGN Occasionally, when you're designing a database schema, you need to go to fifth normal form (5NF). (For a discussion of data normalization, see SQL by Design, "Why You Need Data Normalization," Premiere Issue.) Tables implemented in 5NF are often severely decomposed into many small tables to minimize redundancy and assist in day-to-day management (as I'll demonstrate in a moment). Complex multitable joins are necessary to recombine fragmented data into the consolidated information that most end users expect to see. For situations that require a 5NF database, you can minimize the performance impact of multitable joins by creating views of your data. What Is a View?
Normal Is Relative
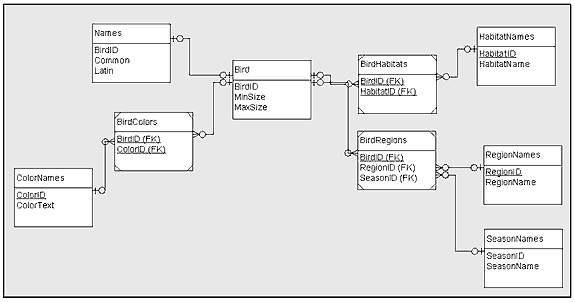
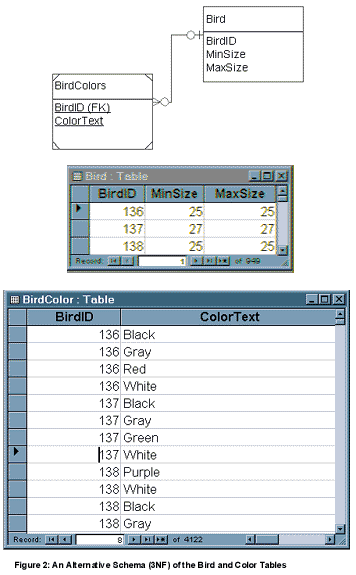
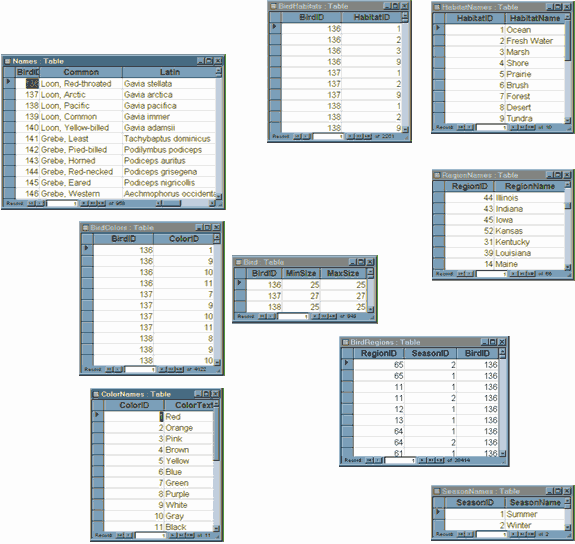
The normal form of each of these tables goes beyond 3NF, however. Within each table, each determinant is also a candidate key or else no candidates exist other than the primary key. (A determinant is a column that describes, identifies, limits, or otherwise determines the values of the other columns in a table. Each table has at least one determinant, the column or columns that make up the primary key.) This condition qualifies the entire set of tables for an advanced level of 3NF called Boyce-Codd Normal Form (BCNF). BCNF simply removes some modification anomalies that might result if a determinant is not a candidate key. For instance, Figure 1 includes the many-to-many (M:N) relationship of Bird to ColorNames, with the relation BirdColors associating these two tables. If you had just a one-to-many (1:M) relation, Bird to BirdColors, and if BirdColors contained the color text instead of the color identifiers, as in Figure 2, this version of BirdColors would be subject to a modification anomaly. For example, if you want to change the color text red to scarlet in the 3NF arrangement that Figure 2 represents, you have to update many rows. In a 5NF database schema such as in Figure 1, you simply update one row in one table. BCNF removes the modification anomaly of having to make a change in many places in the database when you want to change one value. Figure 3, a logical representation of the ERD with sample data, demonstrates how fragmented this data is. This bird-watchers' reference database is available in four languages, so for maintenance and installation reasons, text and number data types are segregated into separate tables. Text data (colors, habitat descriptions, etc.) must be available in any language the installer selects (English, French, German, or Spanish), but number data (identifier, minimum and maximum size) looks the same in all these language selections. The installation package has to include a set of text tables for each of the languages supported. Storing the text data in separate base tables (for example, SeasonNames-two rows) rather than as part of the associative tables (for example, BirdRegions-28,400 rows) significantly reduces the amount of data in the installation package. Thus, the decision to decompose this database into 5NF results in ease of data maintenance and simplicity of installation. Formulating Views
You can call the view directly with a SELECT statement, as in Listing 1, or you can write a stored procedure that calls the view, as in Listing 2, page 74. These two techniques are somewhat restrictive; the output of each is limited to birds you can see in Iowa in the summertime. To maximize your options (or your users' options), you can write a stored procedure like the one in Listing 3, page 74. This approach lets you retrieve the bird list from any season and any region, simply by feeding different arguments to the stored procedure when you execute it. This stored procedure has a query plan that is evaluated, compiled, and stored. Each time the stored procedure is called, the query plan is referenced and executed for optimal performance. In SQL Server 7.0, when the structure of a table that is used by a stored procedure changes, the stored procedure automatically recompiles. Also, according to my findings on totally unindexed tables, all three of these code options run in about the same amount of time, after the data is in cache. In SQL Server 6.5, the view and stored procedure names and code are stored in sysobjects; the query trees are stored in sysprocedures. SQL Server 7.0 treats the stored procedures more like views, and only the code is stored in sysobjects; each time SQL Server starts, the query plan is recalculated and kept in procedure cache. Column information is stored in syscolumns, and any dependencies are stored in sysdepends. Text documenting the views is stored in syscomments along with the stored procedures. Get It All Together
|
Copyright Duke Communications Intl, Inc. All rights reserved.
{kind=link}
{kind=link}
{kind=link}