July 1999
![]()

Code for this article: July99HOC.exe (2KB)
|
Don Box is a co-founder of DevelopMentor, a COM think tank that educates the software industry in COM, MTS, and ATL. Don wrote Essential COM and coauthored the follow-up Effective COM (Addison-Wesley). Reach Don at http://www.develop.com/dbox. |
|
Matt Pietrek's February 1998 column was one of
his most inspirational in recent memory. Matt
tackled assembly language, a topic that most programmers consider overwhelmingly complex, and made it digestible and approachable. Matt's column was effective because it demystified some of the associated mythology and partitioned the topic's surface area into something bite-sized and understandable for most developers. Because I've been spending the last 12 months with OLE DB—which, at least culturally, is the assembly language of COM—I thought it might be fun to pay homage to Matt's work and distill the OLE DB story into 10 pages or less.
My own journey into the world of OLE DB may have been similar to yours. Three years ago, I only knew enough SQL to write the following simple statement: |
|
|
The only reason I even knew this much was from reading (and abandoning) several SQL texts earlier in my career. As a system programmer type, I was able to live a full and rich life without knowing the first thing about SQL or databases. Even after I made the transition to COM, I was able to live in blissful ignorance of all things database. And then Microsoft® Transaction Server (MTS) shipped.
MTS forced me to get into transactional programming. Unfortunately, when MTS first shipped, there weren't tons of resources to work with. Fortunately, there was one resource that came with my MSDN™ subscription that would allow me to do interesting things with MTS. After a few hours, I was able to locate the correct CD and some spare disk space and, once the setup program was complete (and a service pack was applied, naturally), I had SQL Server™ 6.5 up and running on my machine. That's when the fun began. My first challenge was to learn SQL. Between the ISQLW.EXE application, the online T-SQL docs, and some excellent Joe Celko books, my SQL vocabulary grew by a factor of four practically overnight. (OK, so I also got help from some of my programmer friends who use Visual Basic.) I was able to write statements as interesting as |
|
| or the more useful: |
|
| I even found that you could modify records in place with statements like this: |
|
|
Armed with the basic four statements of SQL, off I went to build MTS-based transactions that actually did something.
Unfortunately, the ISQLW application doesn't participate in MTS transactions. (Even if ISQLW supported OLE Automation, your MTS components probably couldn't get it to enlist.) This meant that I would need to learn how to squirt my four SQL statements into the database programmatically. By this time, I was pretty tired of learning new technology, so I temporarily reverted to using a development tool with fairly low cognitive overhead: Visual Basic. Of course, I found that using Visual Basic to emit my SQL statements was fairly simple. By the time I started doing it, most of the weaker data access technologies (Data Access Objects, RDO, ODBCDirect) had either been deprecated or had so much negative baggage associated with them that no one starting from scratch would ever entertain using them. The only data access technology that looked like it had a future in Visual Basic-land was ActiveX® Data Objects (ADO). So, armed with a type library and the Visual Basic interactive debugger, I quickly figured out how to do the following: |
|
|
By bracketing this code fragment with calls to SetAbort and SetComplete, I pretty much had the whole data access world down—or so I thought.
Once I mastered ADO programming in Visual Basic, my desire to mix SQL code and semicolons became too strong to resist, so I moved back to C++. At first, I used that technology of the devil, known as #import, to import the ADO type library into my C++ programs. (The Platform SDK I had installed at the time had no up-to-date C++ header files for ADO, so I had no choice.) As someone who had pretty much switched to the Active Template Library (ATL), I found that the intrusiveness that #import represented was too much to bear, so I used the following attributes to emit a real C++ header from the type library: |
|
|
Armed with a sane-looking header file, off I went to port my Visual Basic code to C++.
It turned out that as long as I wasn't performing select statements, the Visual Basic-to-C++ translation was fairly painless (although the upcoming Paste Special feature in Visual C++® 9.0 that converts Visual Basic and Java language code on the fly would have been quite handy). The previous ADO code fragment can be replaced by the following C++ code: |
|
|
Getting this one-to-one correspondence between a line of Visual Basic code and a line of C++ code made me feel more productive than you can imagine.
It then came time to perform a select statement. I had written a simple Visual Basic method that returned a comma-delimited list of fields: |
|
|
The code was fairly simple due to the automatic handling of VARIANTs and default properties in Visual Basic.
However, porting this simple code fragment to C++ was less than pretty: |
|
|
Even with the ATL wrapper classes, the code was unnecessarily cumbersome (note that this code excerpt doesn't even check HRESULTs). Between the rumors I kept hearing about the relative sluggishness of ADO and the grotesqueness of mixing ADO recordsets and C++, I decided to dedicate the resources to figuring out how all of this worked, which in my case meant digesting the OLE DB SDK.
The OLE DB SDK is vast. When I started using OLE DB, the primary reference available was the OLE DB 1.1 Programmer's Reference. This book had a lot in common with the original OLE2 Programmer's Reference. Both had tons of surface area and presented all topics as equally important. Both documented scores of new COM interfaces and contained code fragments that seemed to have been ruined by the translation into documentation. The OLE DB 2.0 version is somewhat better, but it was only after writing tons of code that any of it made sense. The remainder of this column documents some of the more relevant observations I came across through experimentation and talking to other OLE DB users. Observation 1: Providers are Just COM Classes An OLE DB provider is just a named implementation of some well-known interfaces. Providers get loaded using COM, just like any COM class. OLE DB providers are named by CLSIDs and ProgIDs and, as of OLE DB 2.1, can be loaded in-process or out-of-process. There are two characteristics that distinguish an OLE DB provider from other COM classes. First, OLE DB providers must have an OLE DB provider subkey: |
|
|
More importantly, providers are expected to support a standard object model mandated by the OLE DB designers. This object model is shown in Figure 1. |
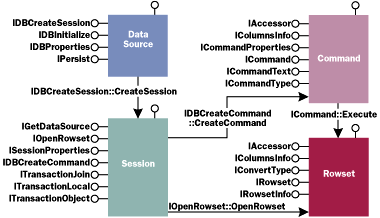 |
| Figure 1 OLE DB Object Model |
| The OLE DB object model assumes that the object returned from CoCreateInstance will implement the set of interfaces that comprise the DataSource cotype: |
|
|
While the cotype syntax looks like something MIDL.EXE might happily chew on, it is just a documentation convention and not consumed by any SDK tools I know of. Note that the DataSource object only needs to implement four core interfaces. If you consult the documentation, this adds up to only seven methods total (and only four of these get called in the common scenarios).
The DataSource object is used for two primary functions: initializing the provider once CoCreateInstance loads it and creating Session objects which act as the central point of focus in the OLE DB object model. Session objects are returned by IDBCreateSession::CreateSession and adhere to the cotype description in Figure 2. According to the documentation, Session objects exist to scope transactions. While technically this is true, their primary function is to create new Command and Rowset objects. At the physical level, the Session object represents a connection to the database (at least when used with SQL Server). In fact, the code in Figure 3 establishes a live connection to a running SQL Server database. This code can be somewhat simplified using the ATL database templates: |
|
|
Once the Session is opened, it can be used either to access raw tables (by calling IOpenRowset::OpenRowset) or for squirting SQL statements into the database (by calling IDBCreateCommand::CreateCommand and friends).
The simplest way to get things to happen in SQL Server is to emit SQL statements using the Command object. The Command object is an optional feature of an OLE DB provider, but the SQL Server OLE DB provider will happily cruft one up when you call the IDBCreateCommand::CreateCommand method on its Session object. The resultant Command object can be used to send SQL statements to the database, and it adheres to the following cotype definition: |
|
| The primary interface you should care about is ICommandText |
|
| which extends the ICommand interface: |
|
| Assuming that you are just sending inserts, deletes, and updates, the code in Figure 4 will do the trick. Again, this code could be rewritten using ATL: |
|
|
Despite the drastic reduction in line count when using ATL, both code fragments translate to roughly the same executable statements.
Note that with just a handful of lines of code, it is possible to send arbitrarily complex statements to a database using OLE DB, provided no information needs to be sent back to the client. I'll discuss how data transfer works when I get to the third observation. Observation 2: Properties Are a Pain One of the most intimidating aspects of OLE DB programming is its extensive use of properties. Every object in the model supports a variable number of runtime properties that can be examined and modified to influence the behavior of the provider. OLE DB defines a standard collection of properties for each cotype. Providers can define their own provider-specific collections of properties to expose extended functionality or control. Programmatically, a property is just a tagged VARIANT, and is represented using the DBPROP data structure: |
|
|
Because properties by themselves are identified by DWORDs and not GUIDs, some technique is needed to ensure that provider-specific IDs don't clash with system-defined IDs. OLE DB solves this problem by always requiring properties to be passed inside a property set.
A property set is a tagged array of DBPROPs. The tag is a GUID that identifies the scope and meaning of the properties (and their identifiers). Property sets are represented programmatically using the DBPROPSET structure: |
|
|
Because this structure is always used to pass properties between providers and clients, an individual property is always identified by its PROPSETID (a GUID) and its DBPROPID (a DWORD).
OLE DB defines several standard property sets, as shown in Figure 5. The primary property set that everyone encounters right away is DBINIT. This controls the ODBC-esque properties of a provider such as the user ID, the password, and the initial catalog. The code in Figure 6 sets up SQL Server to use the pubs database. Fortunately, ATL makes this somewhat easier through its CDBPropSet class. CDBPropSet extends the DBPROPSET structure by adding convenience methods that append tagged properties to an ATL-managed vector of DBPROPs. Using ATL, the code in Figure 6 becomes much simpler: |
|
|
Note that because CDBPropSet extends the DBPROPSET structure, a CDBPropSet pointer can be passed any place a DBPROPSET pointer is expected.
The discussion so far has avoided the term property group. Recall that for each scenario that uses properties, OLE DB defines a standard property set. In each of these scenarios, however, a provider can define provider-specific property sets to augment what is already defined by OLE DB. A property group is simply the collection of property sets used in a given scenario (that is, the OLE DB standard property set plus any provider-specific property sets used in that scenario). For example, OLE DB defines a standard property set for initializing a provider's DataSource object called DBPROPSET_DBINIT. SQL Server also defines a property set for initializing the DataSource object (DBPROPSET_SQLSERVERDBINIT) that contains SQL Server-specific properties such as which network library to use and the workstation and application IDs used by SQLTRACE.EXE. Because both the DBPROPSET_DBINIT and DBPROPSET_SQLSERVERDBINIT property sets are only used in the context of initializing a DataSource via IDBPProperties::SetProperties, they both belong to the Initialization property group. One downside of using properties to initialize a provider is that you are hardcoding aspects of the initialization into your source code. It is often useful to allow system administrators to parameterize your data access configuration without recompiling your code. ODBC used Data Source Names (DSNs) and connection strings. OLE DB has its own equivalents that are exposed by the MSDAINITIALIZE component. MSDAINITIALIZE is a COM class that is provided by OLE DB. This class can parse OLE DB connection strings and load/initialize the provider based on property values in the connection string. MSDAINITIALIZE implements the IDataInitialize interface, as shown in Figure 7. Given this interface, the code in Figure 8 loads the SQL class, which implies the following usage: |
|
|
Again, both ways are functionally identical and yield the same executable code modulo error handling, which I won't get into here. |
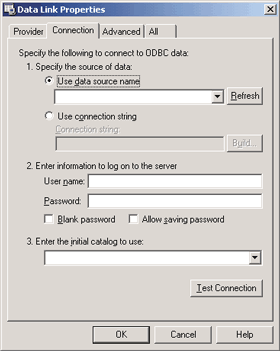 |
| Figure 9 Data Links Editor |
|
It is also possible to read initialization strings from files a là the ODBC File DSNs. OLE DB provides an easy-to-use editor called the Data Links component. To use it, simply create a new Microsoft Data Links file in the file system and double-click it in the Explorer. You will get a dialog similar to the one shown in Figure 9. Note that the second property page is selected by default. This is because the Data Links component defaults to the OLE DB provider for ODBC data sources. To select the native SQL Server provider, select the first property page and change the selected item, as shown in Figure 10. |
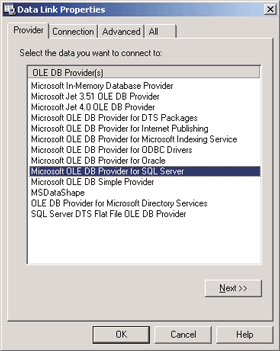 |
| Figure 10 Provider Page |
|
Once you select the SQLOLEDB provider, you will see the SQL Server-specific property page shown in Figure 11. The Data Links Editor allows you to easily set both standard and provider-specific property sets. When you apply the changes, the Data Links Editor simply translates your settings into an initialization string and stores the string in the underlying .UDL file. The string in this file is in the correct form for use with IDataInitialize::GetDataSource. You can either move the string manually into a registry key or other configuration store, or you can ask the MSDAINITIALIZE component to load the file at runtime using IDataInitialize::
LoadStringFromStorage. |
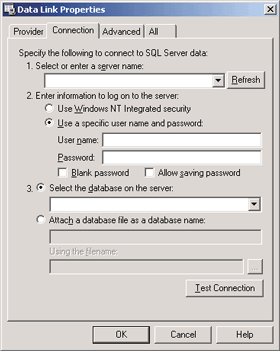 |
| Figure 11 Provider-specific Page |
|
Observation 3: OLEDB is About Memory Management
One thing that distinguishes OLE DB from other COM frameworks is its rather unorthodox use of pointers and memory. Since the primary goal of OLE DB is to give you access to a provider's data, the data transfer interfaces break away from the standard rules of COM memory management to give you complete control over how memory is allocated, converted, and copied. Consider the simple select statement. The provider has an internal representation of each row that it uses to buffer the read operations from the database. The client has its own idea about how each row should be manipulated in memory. The ADO approach is to simply force every column value into a VARIANT. The OLE DB approach is to allow the client to use whatever type it wants as long as it provides a description of its data type to the provider. This description is called an accessor. Accessors are opaque descriptions of column-to-memory mappings. Accessors are used by rowsets (a cotype that represents tabular data) and by commands. Providers allow clients to create accessors by implementing the IAccessor interface (see Figure 12) on their Command and Rowset objects. To use an accessor, the client builds a description of its expected data representation by initializing an array of DBBINDING structures. Each DBBINDING structure describes the data type and buffer offset for a particular column. Once this array is in place, the client calls the provider's IAccessor:: CreateAccessor method. This tells the provider to internalize the description and to return an HACCESSOR handle for future use. All method calls to the provider that do data transfer expect an HACCESSOR to describe the expected data representation. Albeit verbose, using accessors is fairly straightforward (see Figure 13). This code can be dramatically simplified by using the ATL CCommand and CTable classes. These classes take an ATL accessor class as a template parameter, which in turn takes a user-provided schema class as a template parameter. A schema class is simply a structure that contains a column map (which is a simplified version of a DBBINDING array in ATL). Given the following schema class |
|
| only the following is needed to print all records to the console: |
|
|
As you can see, the ATL schema infrastructure dramatically reduces the amount of code you need to write to deal with accessors. Observation 4: Avoid MSDASQL When you start using OLE DB from an ADO mindset, it is very tempting to use ODBC-style initialization strings like this one: |
|
| Note that this string does not contain a PROVIDER element. OLE DB and ADO interpret strings that do not specify a provider as legacy ODBC-style strings and silently insert the following prefix: |
|
|
MSDASQL is the OLE DB provider that wraps legacy ODBC data sources. It is deemed the default provider simply to ease the transition from ODBC to OLE DB. However, you are encouraged to transition to the native providers both for performance and flexibility.
OLE DB 2.0 shipped with SQLOLEDB, a native provider for SQL Server. Because this release more or less coincided with the release of SQL Server 7.0, there is some confusion as to whether SQLOLEDB is compatible with SQL Server 6.5. The answer is, it's compatible provided you download the updated catalog stored procedures to your SQL Server 6.5 installation. These stored procedures ship with SQLOLEDB in a file named INSTCAT.SQL. Simply use ISQLW to install these stored procedures to SQL Server 6.5. SQL Server 7.0 doesn't require any special preparation. Observation 5: There is a Runtime After All, Dorothy
One of the big advantages of OLE DB over ODBC was the inherent superiority of COM over WOSA. ODBC (like MAPI and TAPI) was based on the WOSA model, where Microsoft defined an API for client programmers and a Service Provider Interface (SPI) for driver writers. This architecture had three major weaknesses:
OLE DB does not define an SPI or an API. Rather, OLE DB is a suite of interfaces that providers implement and clients use. If you are familiar with the client side of OLE DB, you also are familiar with its provider side. As for exposing extended functionality, QueryInterface is a proven technique for discovery and access to extended functionality that developers are widely familiar with. On these two fronts, OLE DB successfully broke away from the ways of ODBC in a rather elegant manner. As for the third weakness, OLE DB started out with no runtime. Clients simply called CoCreateInstance against the CLSID of the provider and no Microsoft-controlled code was involved. Your code snuggled up against your provider's vptrs, and it was just straight inproc COM. Two important innovations happened over time. The first one doesn't really apply to developers using C++ . That one, of course, is ADO. To a programmer who uses ADO, the OLE DB interfaces (such as IDBCreateSession) are simply the SPI of ADO, with ADO itself representing the true API. However, given the advent of ATL, it is hard to imagine developers using C++ doing the bulk of their data access using ADO, so this worldview doesn't apply (at least not in this column). The innovation that touches every programmer who uses OLE DB and ADO is the advent of service components. Taking a lesson from MTS, OLE DB 2.0 introduces the notion of service components, which are lightweight interceptors that sit between a client and an object/provider. Service components are injected at creation time, based on declarative attributes. Each OLE DB provider is expected to have the following registry entry: |
|
|
The value of the OLEDB_SERVICES entry is a bitmask indicating which service components the provider wants to be injected. ffffffff obviously means insert everything that is available.
Service components take advantage of the fact that the OLE DB object model was designed with aggregation in mind. Each method that can create a new object accepts a pUnkOuter parameter. This allows the service components to aggregate the provider's object model into their own. Some service components add additional interfaces that the provider didn't anticipate or implement. Other service components simply perform specific operations at creation and destruction of provider objects. Service components typically offer some generic service to all providers. The two most commonly used service components are the connection pooler and the auto-enlist service component used to integrate with MTS/COM+ transactional objects. These services can be disabled declaratively by clearing the low-order two bits in the registry (for example, changing 0xFFFFFFFF to 0xFFFFFFFC). Note that MSDASQL disables these, since the ODBC layer already performs these two services. However, SQLOLEDB enables them, since it speaks Tabular Data Stream to the database directly without using ODBC as an intermediate layer. The OLEDB_SERVICES attribute in the registry can be overridden by using the |
|
|
element in a connection string. Additionally, the DBPROPSET_DBINIT property set has a well-known property (DBPROP_INIT_OLEDBSERVICES) that can be used with IDBProperties::SetProperties.
It is important to note that for service components to be injected, something other than CoCreateInstance must be used to load the provider code, since CoCreateInstance doesn't know to look at the OLEDB_SERVICES registry attribute. Calling GetDataSource on the MSDAINITIALIZE component will do the right thing provided you have an initialization string. If you want to load the provider just using a CLSID, you must call the CreateDSInstance[Ex] method on the MSDAINITIALIZE component: |
|
|
Going through the MSDAINITIALIZE component ensures that any configured service components will be inserted.
There is a defect in the ATL Object wizard that bypasses service components. Because the wizard-generated code simply uses CoCreateInstance, wizard-generated consumers don't get the benefits of service components (this means you don't get pooling and auto-enlistment if you use SQLOLEDB with unmodified wizard code). To fix this, simply edit the wizard-generated code to call CDataSource::OpenWithServiceComponents instead of CDataSource::Open. This is an easy modification that hopefully will become unnecessary in a future version of Visual C++. Observation 6: OLEDB is Actually Simple
OLE DB, like COM, has a vast surface area. Both OLE DB and COM only require you to master a small subset of this surface area to become productive. The easiest way to get started is to write simple programs using a small number of OLE DB interfaces. While the ATL wrappers around properties and accessors are extremely convenient, the basics of OLE DB are pretty straightforward once you've written the code a few times. |
|
Have a question about programming with COM? Send your questions via email to Don Box: dbox@develop.com or http://www.develop.com/dbox. |
|
From the July 1999 issue of Microsoft Systems Journal.
|