![]()
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|

| Download the code (54KB) |
| Dino Esposito |
| Pluggable Protocols |
Together with http:, there are a couple of other magic strings that we use frequently—not as often as with http:, but often enough. The mailto: URL prefix helps us send email. News: lets us browse newsgroups. And let's not forget the ftp: and gopher: protocols. But how many of us actually know what exactly http: or mailto: are? First of all, they represent protocols—systems of rules that define the proper behavior in various situations. On the Internet, a protocol is a set of rules that determines how a certain resource is accessed. When you type http://www.microsoft.com in the address bar of your browser, you're actually telling it to use the rules of the HTTP protocol to get in touch with the server at www.microsoft.com. Each protocol has its own set of rules and provides a certain behavior to the user. Depending on what the protocol is designed to do, it might also need a transport mechanism. In the case of HTTP this mechanism is TCP/IP, another group of protocols that is designed to control data transmission across a network. If you're thinking that http: is just a magic word like abracadabra, you're only partially wrong. There's nothing magic behind HTTP or any other protocol. But you could name your own custom protocol abracadabra, and specify how it should access remote and hidden resources. Let's examine exactly what an Internet protocol is. I'll review the fundamentals of HTTP and the minimal set of functionality that characterizes an Internet protocol. With this in mind, I'll show how to code a custom URL protocol. Custom protocols provide highly specialized behavior, particularly within an intranet or in a local application based on the WebBrowser engine. If the idea of custom URL protocols sounds a bit odd to you, consider that you're probably already using them. The MSDN™ InfoViewer module uses the ivt: protocol Microsoft® Internet Explorer accesses resources in executable modules with res:, and displays help pages or raw text with about:.
A Quick Tour of the HTTP Protocol
A Definition for a URL
|
|
|
The protocol is http:. The host computer is msdn.microsoft.com. The directory is scripting Default.asp is the file. This URL can be reconstructed to indicate one specific resource on the Internet, which can be accessed through HTTP. In general, a URL has two parts that must be specified: the protocol and the resource. Here's another example of a valid URL: |
|
|
The protocol is res:, and there's no explicit mention of the host computer. More importantly, the resource's specification isn't limited to a fully qualified path name. In fact, this line contains a file name plus additional information that refers to a specific item in the file's resources by name. In this case, "resource" is admittedly a bit misleading. The resource addressed by the URL evaluates to a given item in the file's user interface resources (bitmaps, icons, dialogs, and the like). The res: protocol was introduced to allow access to embedded HTML pages as special custom resources. For more information about the standard definition of URLs, check out RFC 1738 at http://www.isi.edu/in-notes/rfc1738.txt.
Browsers and Protocols
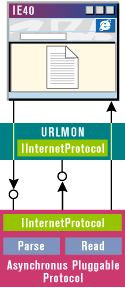
Pluggable Protocols
The res: Protocol
|
|
|
where resource file is the name of the executable module. If the file is in the search path (for instance, in the Windows directory), it may be specified by file name alone. The second chunk of information, resource type, is optional. The res: protocol supports numbers for each of its predefined resource types, and allows you to use literal strings to identify custom resources. The complete list of the resource types is declared in winuser.h. Figure 2 lists the entries most commonly used via the res: protocol. Those are the same IDs required by some API functions like FindResource. If you don't provide a resource type, it defaults to HTML (type 23). This means that |
|
| and |
|
| are equivalent and will access the same page in the specified executable. If you want to refer a custom resource, namely one whose type is not defined in winuser.h, then you have to use the name of the type. For example, if you have a file called resProt.dll with this line in its .rc file |
|
| then |
|
|
is the correct way to reference the image. The final piece of information in the URL is the resource name. A resource name can be a number or a string. You can use any string to identify a resource, but if it evaluates to an external file name that's been embedded in the executable file, using the file name as an identifier makes sense. For example, if you have the following line in your .rc file |
|
| you can invoke it within an HTML page like this: |
|
|
The res: protocol allows you to compile HTML pages within your application so that there's just one file to distribute: the EXE. Figures 3 and 4 show the contents of an .rc file that includes very simple HTML pages. Notice that all the internal references are based on the res: protocol. This lets you embed an entire HTML-based application within
a compiled module. Figure 5 illustrates a sample that was written with Visual Basic®. The key is adding a resource script file (.res) to the project. The one I used was generated with Visual C++®. Though the sample is written with Visual Basic 6.0, it works with any 32-bit version of Visual Basic provided that you have the Internet Explorer 4.0 WebBrowser control! The version of MFC that ships with Microsoft Visual Studio® 6.0 contains a cool feature to let you obtain the same result. As you may know, MFC includes a new class, CHtmlView, that is just a wrapper around the WebBrowser component. This class exposes a method called Navigate that lets you open the specified URL. Interestingly, CHtmlView also defines a method, LoadFromResource, that navigates to a page that's embedded in the application's resources. Here's how the method is declared: |
|
| As you can guess, LoadFromResource makes internal use of the res: protocol. The function's pseudocode looks like this: |
|
|
The res: protocol addresses an issue to which many developers are sensitive. It's not the only possible solution for embedding HTML resources into an application. A lower-level approach might be to embed your resources as shown above, then extract and recreate them as separate files at startup using FindResource and other related APIs. This solution might be worth consideration if your target browser isn't Internet Explorer. The res: protocol is the most elegant solution, but browsers other than Internet Explorer 4.0 don't support it.
The about: Protocol
|
|
| The text portion can be raw HTML text or a kind of pointer to an HTML page. The browser first tries to find a matching page for the specified text. If it fails, it next considers the text portion to be plain text to display. The about: protocol is implemented in shdocvw.dll. Under the hood, the protocol's implementation ends up writing text in the document body. If you type the following in the Internet Explorer 4.0 address bar |
|
| the string "Hello, MIND" will appear on a blank page as if you'd loaded a page with this source code: |
|
| You can also enter more complex text such as: |
|
|
The result is shown in Figure 6. |
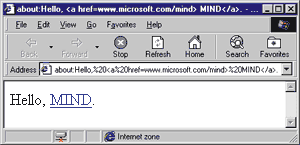 |
| Figure 6: Using about: |
| What's cool with about: is that you can define monikers to address specific HTML pages instead of plain text. For example, the content displayed by about:NavigationCanceled actually comes from an HTML resource, res://shdocvw.dll/navcancl.htm, that's stored in shdocvw.dll, as shown in Figure 7. But how does the browser know how to associate the NavigationCanceled moniker with the resource navcancl.htm? It's all stored in a table within the system registry, under this easy-to-remember key: |
|
|
Adding a new moniker is as easy as writing a new entry in the registry. If you have resprot.dll installed in your system directory and add this association to the table, then about:mind will be a command that'll be recognized by Internet Explorer 4.0. |
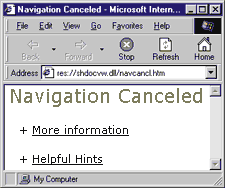 |
| Figure 7: about: Navigation Canceled |
|
The about: protocol is also supported by Netscape Communicator 4.05, but it doesn't support any conversion tables in its implementation, and it's limited to outputting text in the document's body.
Invoking Protocols from the Shell
|
|
| The third parameter can be any string that the browser can parse as a complete URL. This particular call uses the interface of your standard mail program to drop me a line. Likewise, |
|
|
displays the specified page from the DLL, just as the URL about:mind would.
The IUrlSearchHook Interface
|
|
|
Each CLSID listed under this key has an empty string as its value. By default, the only entry under this key points to the Microsoft URL Search Hook, which is implemented in shdocvw.dll. A search hook is an in-process COM object that exposes the IUrlSearchHook interface. This interface has a very simple structure with a single method, Translate, with the following prototype: |
|
|
The lpwszSearchURL argument contains the URL the browser is unable to resolve. If the function is successful, it'll be replaced with the translated URL. The string is Unicode; cchBufferSize denotes its length. Figure 8 contains a simple ATL-based COM object that implements the IURLSearchHook interface. When it's loaded by Internet Explorer 4.0, it tries to verify whether the URL is an email address. If so, it prefixes the URL with "mailto:". The algorithm to determine whether the URL evaluates to an email address is the world's simplest: it checks for an @ character. If the hook receives |
|
| it returns |
|
| Once you've installed this extension, you'll be able to type an email address in the Windows Explorer or Internet Explorer address bar and have a new message generated automatically by your default mail program. The ATL project, which was generated with Visual C++ 6.0 and ATL 3.0, is included in the source code for this article. The object makes all the necessary changes to your system registry during the registration process, which you can start manually with this call: |
|
|
How Pluggable Protocols Work
Pluggable protocols are built on top of asynchronous URL monikers. A moniker is a system object that encapsulates a particular instance of a COM object, along with all its persistent data. It has the ability to locate and load the object into memory, starting from a file name. Monikers were introduced with the OLE 2 specification, and they were originally synchronous objects. The increasing prominence of the Internet and the need to access objects further away than a local-area network brought about a double evolution: asynchronous components with the ability to locate objects via a URL. URL monikers are a concrete implementation of the asynchronous moniker specification. |
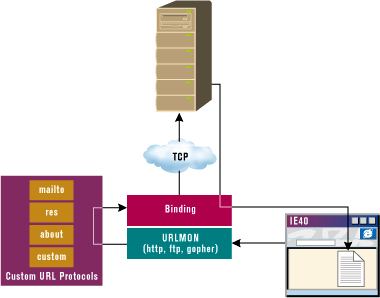 |
| Figure 9: URL Monikers and Pluggable Protocols |
|
URL monikers are a COM-based technology that extends the original concept of the OLE moniker to provide a uniform interface to the download process. URL monikers are coded into the urlmon.dll module. Figure 9 illustrates
how URL monikers and pluggable protocols fit in with the global picture. The power of urlmon.dll has been enhanced in Internet Explorer 4.0. It now can use external modules to implement and support new asynchronous protocols. In practice, urlmon.dll knows how to handle URLs that use the HTTP, FTP, and Gopher protocols. It delegates this to an internal COM module that utilizes WinInet calls to do the job. For any other required protocol, urlmon.dll passes the control to the specified pluggable object. Internet Explorer 4.0 itself comes with about a dozen asynchronous pluggable protocols. There are mailto:, res:, and about:, as well as lesser-known ones like javascript: and vbscript:. The javascript: protocol lets you execute JavaScript code directly from the address bar. The URL |
|
|
displays a message box with the current year. An asynchronous pluggable protocol (APP) is required to implement a few COM interfaces to offer the basic functionality required by urlmon.dll. In general, an APP is expected to receive a string with an unknown URL protocol, parse it, analyze the various elements, and produce a stream of bytes as the output.
An interesting example of an asynchronous pluggable protocol is available for download from http://support.microsoft.com. It's a Visual C++ 5.0 project that uses ATL to create the COM object. When I tried to compile this project, I found that it had some missing files. But creating a new ATL project and adding the downloaded files worked fine. Modifying this code to implement any other kind of custom protocol is a matter of replacing the behavior of a couple of functions. In particular, you should look at DoParse, which analyzes the URL composition, and Read, which returns the stream of bytes to urlmon.dll. Figures 11 and 12 list the functions to take into account when coding a pluggable protocol. An APP must be registered to the system registry under |
|
|
where <protocol> is the name before the colon. Each such key has a CLSID value that represents the module that implements IInternetProtocol.
Application-based Protocols
|
|
| This information is stored in the registry under |
|
|
where protocol is the name of the protocol in question (like mailto: or outlook:).
Further Reading
|
From the January 1999 issue of Microsoft Internet Developer.