![]()
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|

| Download the code (27KB) |
| Dino Esposito |
| The Microsoft Speech SDK |
Today, things are different. Writing a voice-enabled Win32® or Web application is a fairly routine task. The key to this change is the effort made in the last few years to produce the plumbing for speech synthesis and voice recognition, as well as high-level development tools. In this article, I'll examine some features of the Microsoft® Speech SDK 4.0, which is available with the most recent Platform SDK. I'll concentrate on the Text-to-Speech (TTS) engine, demonstrating how to employ it in Win32 applications and Web pages. I'll also provide a sample app based on an enhanced version of the Win32 MessageBox function, which can—using the same syntax as the original—repeat out loud the message shown on the screen. TTS is not the only type of voice-based software you can design and build with the Microsoft Speech SDK 4.0. There's also voice recognition, dictation, and telephony. Check out the SDK documentation to learn more. What's New in Microsoft Speech SDK 4.0?
This new release (in beta 2 at the time of this writing) includes support for telephony applications. This means you can mix the Telephony API (TAPI) and speech capability to program answering machines, voice mail, call routing systems, and in general any kind of application that works through a telephone. Speech SDK Components
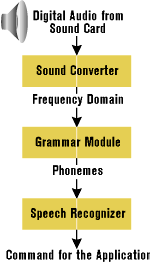
The SDK is split into four basic engines: Speech Recognition (SR), Dictation Speech Recognition (DSR), Telephony (TEL), and Text-to-Speech (TTS). I'll briefly discuss the first three, and then turn to the TTS subsystem, building an example in C++.
DSR is the process that converts sounds into strings while the user is speaking. DSR needs a large vocabulary that exists in context. A context-free grammar defines a specific set of words, while an in-context grammar involves a virtually endless list of words. Therefore, DSR needs more processing power than SR. Recognizing speech involves many variables, from the speaker's voice and accent to the type application. There are two types of dictation-based recognition: discrete and continuous. The Speech SDK 4.0 supports continuous dictation, the more sophisticated form. In discrete dictation, the application has a defined vocabulary of recognizable words, and the user must pause for a few milliseconds between words when speaking. This limitation doesn't exist in continuous dictation, where the end of a word need not be clearly indicated by a pause. This means much more work for the engine, necessitating high optimization and computing power for good results. TEL applications use objects called "telephony controls" that work like the constituent controls of a dialog box. A telephony application is composed of questions and answers exchanged between the application and its users. Each of these fragments of conversation occurs under the supervision of a telephony control. Another way to look at telephony controls is to view the conversation as a multiple-step wizard, where each stage presents a standardized question for the user, such as: "You have three new messages. Do you want to listen to them?" Since the answers to these questions can take many forms, controls can expect yes or no answers as well as dates, times, or numbers. Hardware and Software
The great news about speech support is that it no longer requires special hardware. You just need a 16-bit sound card, a microphone, and (for TEL applications) a fax/modem with speech support. (The SDK documentation warns that not all sound card drivers work well with the various engines.) A Pentium-class processor usually provides sufficient speed. The Text-to-Speech Engine
The TTS engine does basically the reverse of what the SR and the DSR engines do. Its input is plain ASCII text, and its output is a mono, 8-bit, 11 kHz audio format described as Pulse Code Modulation (PCM). PCM is a commonly used method to obtain a digital representation of an analog voice signal. A PCM bit stream is composed of a sequence of numbers that are samples of the voice amplitude.
When the normalizer finishes, the original text has been transformed into the collection of words that will be spoken. This set may be ambiguous since words can have different meanings and pronunciations depending upon the context. For example, the word "read" can be pronounced "reed" or "red." The second step, therefore, is to disambiguate words. Once the engine has an unambiguous set of words, it passes control to the module that associates each word with its constituent phonemes. This step can be accomplished in one of two ways. First, the module attempts to find the word in a pronunciation database. If the search is unsuccessful, it then tries to figure out phonemes by applying letter-to-sound rules. At this stage, the behavior of engines can differ. An enhanced engine like the Microsoft Speech SDK will try to tune and adjust the final sound by guessing the proper speed, timing, pitch, and volume of the voice. The final step in the process is the creation of a WAV file by converting phonemes and additional information into numbers representing voice amplitude samples. There are three techniques to convert a phoneme into an audible sound: word concatenation, synthesis, and subword concatenation. They are described in Figure 3. The Microsoft Speech SDK uses a synthesized voice. TTS has many possible applications. If you use it to vocalize online help, you can get rid of all the large sound files you may have used previously. Since the Speech SDK lets you vocalize text that's determined at runtime, you can employ TTS to enhance the user interface of an application. Using TTS, voice recognition and dictation is as easy as using an ActiveX control, a C++ class, or a COM object. The effort is minimal, but the payoff is high. Developing with the Speech SDK
The Speech SDK is available in three forms: ActiveX controls, C++ classes, and COM objects. My sample uses C++. For Visual Basic examples, refer to the Speech SDK documentation or the MSDN™ link provided at the end of this article. There is also a low-level API that lets you gain more control over the entire process. The SDK documentation
provides complete information on
the DirectTextToSpeech and DirectSpeechRecognition APIs. A Speech-enabled MessageBox Now let's see how to turn all this theory into practice. The sample program (see Figure 6) is a dialog-based application that tests the main TTS characteristics of the Speech SDK. It employs a speech-enabled MessageBox function that you can easily add to any other Win32 application. The new routine is called SAPIMessageBox and uses exactly the same prototype as the original. The only difference is that SAPIMessageBox recognizes a new flag |
|
|
that causes the speech engine to play the text of the message upon dialog activation. |
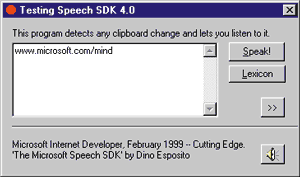 |
| Figure 6: Speech Message Box |
|
MessageBox is a modal dialog that's impossible to subclass unless you enter its internal code through a WH_CBT hook. I've chosen the MB_ENABLESPEAK constant so that it does not conflict with the other MessageBox flags. To support this new flag, the program must hook into the system code and detect when the MessageBox's window will be displayed. Figure 7 shows the source code for the SAPIMessageBox routine, which is defined as follows: |
|
|
The structure of the function is simple. If MB_ENABLESPEAK is not specified, then the code defaults to MessageBox. Otherwise, it installs a WH_CBT hook on the current thread and is notified of all the principal events concerning the windows that belong to that thread. Among others, the HCBT_ACTIVATE event is fired when the message box window is drawn to the screen. At this point, the code hooks the event and ask the TTS engine to play the message.
Playing Text with the TTS Engine At a certain point, SAPIMessageBox needs to play text. As shown in Figure 7, this is done via a function called TellMe, which is a wrapper for the Speech API. Let's look at this more closely. First of all, it includes the following header: |
|
| This defines all the classes that wrap the TTS COM components. To play text, I need CVoiceText. Since it actually manipulates COM objects under the hood, the COM engine must be initialized for the current apartment. The initialization also requires a further step: registering the current application with the TTS engine. This is done through the Init method. The specified name, which must be unique, is just for a record. This code snippet illustrates how to prepare the TTS engine to play text: |
|
| Once the engine is ready, all I have to do is issue calls to the method Speak. |
|
|
The pszTags argument lets you apply tags to text to modify how it's pronounced. The text to speak must be a Unicode string that contains only the raw text. If you need to apply some tags to change pronunciation, use the pszTags argument. The Speak function supports a number of flags to indicate type and priority for the text. When you send text, it is queued and played back as soon as possible. To speed this up, you can assign it a priority. To improve the prosody (versification) of the text, you can specify tags that qualify the word or the words in their range. The tags come from a predefined database and apply to single words or sentences within the text. Examples of tags are shown in Figure 8. The syntax of a tag is as follows |
|
| where tagName is the name of the tag and value is its content, whether it's a number, a string, or whatever. More importantly, a tag must be enclosed by slashes. For example, the tags |
|
| play the name Microsoft Internet Developer with a progressively louder voice. As you can see, tags work on single words or strings throughout the text, so they must be embedded in the text to be spoken. This contrasts with the requirements of the Speak method where, unless you use the DirectTextToSpeech API, you can only specify general tags that apply to the text as a whole. The code needed to play text is: |
|
| When an application submits its text, the engine might be busy serving a previous request. You can accelerate the schedule for your text by using priorities, but this won't cancel the text that is currently playing. You can cancel the playback explicitly with the method StopSpeaking. Before doing so, you should use the method IsSpeaking to determine whether the engine is speaking or not: |
|
|
A similar tactic also is useful for the SAPIMessageBox.
In fact, if the text to speak is long and the user dismisses the dialog before the engine completes, you should stop playback upon the window's destruction. Similarly, if the dialog must appear while the engine is speaking, it should take
precedence, interrupting the current task. Figure 9 shows
the source code from the sample program that deals directly with speech. Modifying the Lexicon Database
As you can see in Figure 5, there are a few system dialogs used to configure the TTS engine. The most important is the Lexicon dialog shown in Figure 10 that lets you modify the dictionary by adding new words, changing the pronunciation of words, and removing words. |
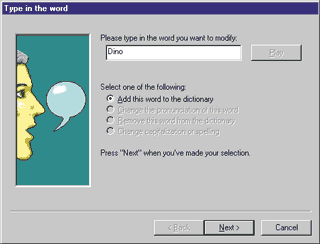 |
| Figure 10: The Lexicon of Dino |
|
Adding a new word is a two-step process.
First you type in the word, then you define its
phonemes. Let's use an example to see how this works. The very first words I asked the TTS to speak were "Dino Esposito." While the last name was spoken correctly, the first name was not. The engine pronounced it "Dy-no" as in "dinosaur." The correct pronunciation, of course, is "Dee-no" (see Figure 11). |
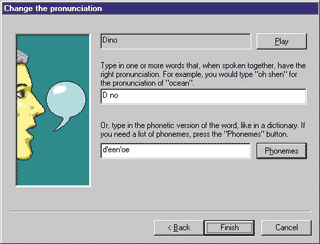 |
| Figure 11: Say it right, damn you! |
|
When you type in syllables to describe how
the word should be pronounced, the phonemes edit box is updated automatically. Moreover, the dialog
pronounces the text so you have immediate feedback. If
you want a list of the available phonemes (English only),
just click the button. The dialog shown in Figure 12 will appear. When you're finished, close the dialog and the new word will be stored
for future use. Microsoft requests that you email new pronunciations to the development team for future releases
of the engine. |
 |
| Figure 12: Phonemes |
|
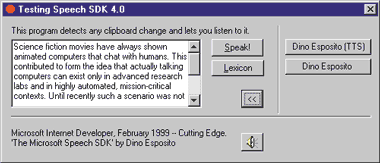
The Sample Program
The sample program shown in Figure 6 lets you test all the features discussed so far. It displays a text box where the user can enter text and play it back by clicking on the Speak button. The text box is filled automatically each time the user saves something to the clipboard. As shown in Figure 13, when the user presses Ctrl+C to copy text to the clipboard, the caption on the program's taskbar button changes, and it flashes for a few seconds. If you click to bring the application to the top, the window caption reverts back to the original title, and the text box displays the text you just copied. |
|
|
| Figure 13: Clipboard's Content Changed |
|
To obtain notification when the clipboard's content changes, the program must define a clipboard viewer window that will be notified on any change, whatever the format of the data. The key message to handle is WM_DRAWCLIPBOARD. Figure 14 illustrates how to check whether the data copied to the clipboard is text data, and if so, how to access the text and fill the text box with it. Note that the effect shown in Figure 13 occurs only under Windows® 98 and Windows 2000. These two operating systems provide a slightly different implementation of the SetForegroundWindow API function. Rather than bringing the window to the foreground, the user is notified by flashing the program's taskbar button. Under Windows 95 and Windows NT® 4.0, the window is simply brought to the foreground. |
 |
| Figure 15: The Demo Program |
|
The sample program also lets you compare the difference between the synthesis voice of the TTS engine and a recorded sound. By expanding the dialog as shown in Figure 15, you can listen to TTS speaking my name and then hear a WAV file I recorded. (The WAV file is a resource embedded in the executable.) Notice how the human voice, as you might expect, is more fluent and less mechanical. For the program to work properly, TTS speech must be installed on the target computer. If not, the program will load normally, but the user won't be able to play any text. For a better UI, you should gray out the appropriate buttons. The InitSpeech function defined in Figure 9 returns a Boolean value that indicates whether a TTS engine is present and working properly. Figure 16 summarizes five important considerations when designing speech-enabled applications. Localized Engines
A TTS engine is a separate component for a speech-enabled application. If you download and test the Microsoft Speech SDK 4.0, you'll get a TTS engine based on the English language. This poses a number of problems when it comes to localizing your software or developing speech-based software in non-English-speaking countries. Speech-enabled Web Pages
So far I've talked about how to use the TTS component to enhance the user interface of a Win32-based application. But is there a way to speech-enable Web pages? To vocalize messages and help files, use the HTML <OBJECT> tag and embed the ActiveX control provided with the SDK. Summary
The Speech SDK I've discussed in this article is under development at Microsoft. Late-breaking news can be found at http://research.microsoft.com. If you're an MSDN subscriber, the Speech SDK 4.0 is already in your hands on the additional SDK CD. Try it out. It can give you lots of fresh ideas for writing new applications or updating existing ones. |
 |
|
http://research.microsoft.com/stg
|
From the February 1999 issue of Microsoft Internet Developer.