![]()
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
|
| XML Languages |
|
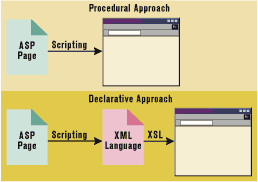 |
| Figure 1: Procedural Versus Declarative Approach |
|
Data Retrieval and Data Display In the procedural scenario, various business objects are glued together in the ASP page, and the ASP code is responsible for both the retrieval and the display of the content. The VBScript or JScript® code must supply the logic to access the data and the formatting objects that will render the data through HTML. As an example, an ASP page may exploit Microsoft® Transaction Server (MTS) components to return a recordset, then use some boilerplate script code to straighten it out to a <TABLE> block. Alternatively, it might include a more direct design-time ActiveX® control to access data and automatically format it to be HTML-compliant. Either way, you fuse together retrieval and display, and blur the distinction between data access and presentation. Worse, you don't write a language-neutral description of the object you're rendering. If you need to change some attribute of this object, you have no choice but to modify the logic to change the display! At this point, you probably agree on the need for a new approach. Whatever you're rendering through HTML can be considered an object, with its own set of attributes and actions. In the simplest case, you have an object that's just an HTML page. Attributes—panels, title, footer, navigational bar, page menu, and actual content—can be the object's constituent blocks. In other cases, you're rendering an object that depends upon the domain of the specific problem, and thus exposes other attributes and possibly another model. In both cases, you describe the object in terms of its structural architecture and provide a display engine for each constituent component. How the object will be rendered is a task accomplished by a separate and independent layer that simply reads in a description, interprets a few keywords, and expands them in pure HTML. This layer is provided in the Extensible Stylesheet Language (XSL). The XML Metalanguage XML (Extensible Markup Language) is an HTML-like language primarily used to describe data. XML and HTML share a common tag-based structure, but HTML has a fixed vocabulary of tags with standardized meanings. XML tags, on the other hand, have no predefined meanings. You define your own syntax for describing data. Let's look at this concept from a completely different point of view. In C++ (or Visual Basic®), you can have abstract classes that contain only virtual methods. These constitute a kind of metaclass—a class that lets you set general rules such as the number of methods supported, which prototypes are used, and maybe the expected behaviors. Such a class, however, isn't usable by itself, and always requires you to derive a new class from it. All this is similar, if not identical, to what happens with XML. To use XML to describe your own objects, you must derive a specific XML-based language. This language will follow the general syntax rules of XML, but will define the tags that can be used to describe those objects. Moreover, it establishes the dependency rules that apply to tags, the order in which they can appear, the attribute list of each tag, whether a certain attribute is required, the range of values (optional or fixed), and so forth. To continue with the parallel to C++ classes, an XML language can be described with the following pseudocode: |
|
|
In practice, a new XML-based language is a particular instance of the XML metalanguage, and is defined in a file that contains the list of valid tags and their syntax rules. This is known as the Document Type Definition (DTD) file.
Figure 2 gives an overview of how Microsoft Internet Explorer 5.0 renders an XML document through HTML. The original source file is checked for compliance against both pure XML and the grammar and the vocabulary of the specified DTD, if any. (Later I'll describe what happens if no DTD is specified; since they slow the parser, some people choose not to use them outside the design stages.) |
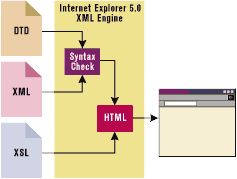 |
| Figure 2: Rendering XML |
|
If the XML document is considered well-formed (more on this below), then it is submitted to the XSL processor, which outputs an HTML representation for it. If you don't provide your own XSL converter, then Internet Explorer uses a default converter that displays the tree of the tags (see Figure 3). In this column, I'll focus on the DTD and the definition of an XML language. In my next column, I'll look at XSL and the XML-to-HTML conversion process. |
 |
| Figure 3: XSL Tag Tree |
|
Document Type Definition A DTD is an ASCII file that's normally saved with a .dtd extension. It constitutes the grammar of the language being used at the moment and provides its vocabulary. A language vocabulary is a collection of the tags it recognizes and accepts. A DTD follows a syntax that is not XML-based. Any XML file may include a line like this at the top |
|
|
meaning that the XML parser must look at the DocTypeDef.dtd file to get and check the file's grammar. If the check passes, then the document is said to be well-formed. Of course, DocumentName is a string that denotes the name of the language, whereas DocTypeDef.dtd is the name of the actual DTD file you're using. Don't forget to put this name between quotes.
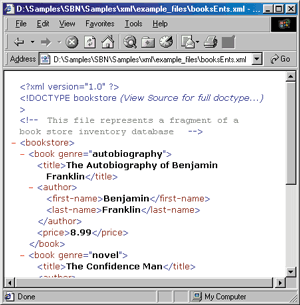
A DTD is important for at least two reasons: it lets you identify and describe the structure of the objects, and it assigns a context and a meaning to a subset of tags. Without a DTD you could use virtually any tag in any XML document, provided that you are respectful of the general XML syntax rules (always close tags, do not overlap tags, use case-sensitive tags, always put attributes between quotes, and so on). But no tag would have a defined set of attributes, a position, or a dependency in the document. The same XML file could be interpreted differently by different parsers. A DTD doesn't prevent two programs from producing different output from the same input, but at least it ensures that both the parsers understand that a common tag is valid. A typical example of an XML language is one that's used to describe books. The following is well-formed XML code: |
|
| The same information could have been presented in the following, equally well-formed fashion: |
|
|
XML, by itself, does not define unique languages for specific applications. However, it can be useful to do this, which suggests the need for a namespace in which precise rules and names describe and identify the same logical object. The
concept is similar to identifying a point in space by using (x,y,z) coordinates.
Namespaces are also useful if two sources define two different DTDs using the same tags. The browser evaluates each tag in its own namespace, just like a C++ variable. Thus, if you want to reference tags and attributes from multiple namespaces in the same document, you should prefix the names with the namespace to which they belong using the xmlns keyword. |
|
| You can then reference that namespace using a prefix. Namespaces should be globally unique and unchanging. Here's how to associate the tag <TITLE> to the namespace MyNS located at a fictitious URL: |
|
|
Throughout the code, MyNS:TITLE will always refer unequivocally to the tag defined by MyNS. The same holds true for attributes. Namespaces are defined on elements and inherited by any descendants of that element. You don't need to redefine the namespace every time you use it. The W3C working draft for namespaces is available at http://www.w3.org/TR/WD-xml-names.
Turning back to DTDs, let's look at the key instructions for defining an XML grammar. Figure 4 presents the main DTD keywords. The most important keywords are !ELEMENT and !ATTLIST. The former defines a tag with its subtags, while the latter indicates the list of attributes for the given tag. In addition, you can create a kind of text macro to be expanded at runtime using the !ENTITY keyword. Each attribute has a type that is either CDATA (raw, unparsed text) or a collection item. The keyword PCDATA refers to leaf elements that have neither tags nor attributes. They are the textual and parsable content of a tag: |
|
|
Each tag supports a number of structural attributes. It can be repeatable or optional. Likewise, an attribute can be required, have a default value, or have a value read from the source document. A MIND Magazine Language Let's look at a concrete example of a DTD to see the syntax in action. The goal is to provide an XML grammar that describes an issue of MIND. Analyzing what you want to describe is always the first step. You have a cover, a number of columns, and some feature articles, along with general information such as the issue, the volume, and the date of publication. Each article has its own authors, text, and figures. Here is a sample of the outputted code: |
|
|
This document is well-formed and Internet Explorer 5.0 displays it without problems (see Figure 5). Now let's try to code the essence of this document into a DTD layout. Figure 6 presents the final result, which is stored in the file msmag.dtd. |
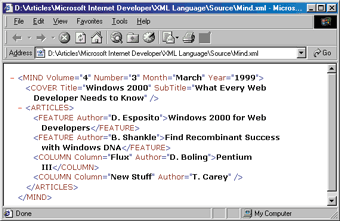 |
| Figure 5: A Well-formed Document |
| To reference the DTD specification in an XML document, I'll use the following syntax: |
|
| Note that the name that follows !DOCTYPE must be exactly the same as the document's root tag. This means that a valid MSMAG document must be in the form of |
|
|
Notice also that all the tags and the attributes are case-sensitive, and must match in the DTD and the XML document.
Looking at Figure 6, the first things you notice are entities. |
|
|
As already mentioned, an entity is a macro that the parser expands. In the previous example, MIND becomes "Microsoft Internet Developer" throughout the XML file. The declaration of the entity comprises two elements: the shortcut name and its actual content.
To refer to an entity in XML documents or further down in the DTD, you must use the following notation: |
|
|
The ampersand tells the parser that the name preceding the semicolon is an entity to be searched and expanded. If the entity isn't found, you'll get an error.
You can also declare an entity as a collection of values and define this as the type of an attribute. The entity declaration must be prefixed by a %, and the possible values must be separated by a |. The Binary entity described earlier is an example of this. When assigned as a type to an attribute, the attribute can then assume only yes or no as its values. Once more, the case is important. Notice also that the syntax required this time is %name; |
|
| A valid XML tag for the language is called an element in DTD jargon. This line describes an MSMAG tag that is composed of four child tags: |
|
|
The trailing * means that the specified tag can appear zero or more times. The ? indicates that the tag is optional. If the tags can appear more than once, add a trailing + to the name. If no suffix is present, the tag must be specified exactly once.
A tag that is declared as a child of another can appear only before the closing tag of its parent. Furthermore, in the XML document the child tags must be specified in the same order in which they were declared. For example, you can't have ARTICLES before EDITORIAL (see Figure 7). |
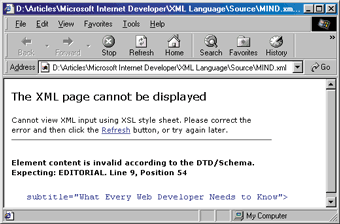 |
| Figure 7: Bad Use of Tags |
| An element without child attributes can be declared as |
|
| if it can contain text to parse between the tags, otherwise the element should be described as: |
|
| Even if a tag is empty, it can still hold attributes. An attribute list follows a syntax like this: |
|
|
You indicate the name of the holder tag, and then the sequence of the attributes in a triplet tag <name, type, value>. The DTD doesn't allow strongly typed languages, so you have two options: CDATA for raw text or an enumerated type previously defined. The value is determined by the keywords listed in Figure 8.
Once you've defined a DTD, you can write XML documents that are compliant with it and automatically validated by the parser. Figure 9 presents an XML document—or rather, an MSMAG document—that describes the March 1999 issue of MIND. Some questions may arise at this point. What can you do with this new XML language? How can you render the data it describes? And what if you need more features than DTD can offer? For example, what if you need to define attributes that contain dates, times, or numbers? Giving XML a User Interface One of the coolest innovations of Internet Explorer 5.0 is its native support for a feature called direct browsing—the ability to read an XSL file and apply its transformations on the XML source code. As a result, Internet Explorer 5.0 can automatically provide a representation of the objects in the language domain. But as I said earlier, I won't be discussing the powerful features in XSL until my next column. In the meantime, let's use a functionally identical approach that also works under Internet Explorer 4.0. XML code has to be targeted for a specific version of Internet Explorer. Internet Explorer 4.0 and 5.0 use different XML object models, and you must take this into account when parsing a document via a script. (Microsoft will soon release an XML update that brings the XML features of Internet Explorer 5.0 to version 4.0.) The code for this column is not portable, but the approach, which is based on direct calls to the XML object model, is portable. To represent the MIND issue in HTML, you must provide a skeleton HTML page with all the needed elements (tables, DIVs, and images). You give each element an ID, and then fill the placeholders with the actual text taken from the XML file. You can use script code to do this; an example of this method is shown in Figure 10. The idea is to load the XML document from within the HTML page during the initialization phase, extract the various pieces of information, and finalize the process by creating HTML text. All this occurs during the page's onload event. |
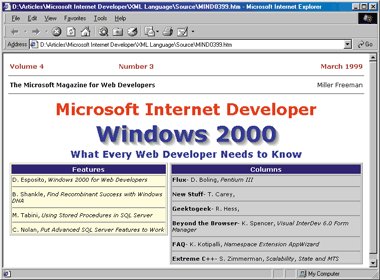 |
| Figure 10: Rendering XML through a Script |
| Figure 11 shows the JScript code needed to display the output. The first step is to create an instance of an XML document object and load the file: |
|
|
With Internet Explorer 5.0 you can also load an XML-compliant string instead of a file. In this case, you'd use the loadXML method. The document object is returned by the documentElement property, while getAttribute lets you access any single attribute of the object.
Finally, to get a reference to a specific node use this syntax: |
|
| The getElementByTagName method returns the collection of all the nodes with a given name. The collection can be of any size, empty or with one or more elements. All collections depend upon the DTD schema, so you should check the size of the collection before accessing any element. In the sample code above, articles is a required node, so any DTD-compliant document always includes at least one. The code, therefore, is safe. You should be careful, however, with the cover tag because it can be missing: |
|
|
Now you can use Cascading Style Sheets to customize the look of the page, and a handful of Dynamic HTML statements to update the content according to the XML document.
Note that although I've given the XML document a user interface, I still have two separate files and a lot of script code. With XSL, the job is done for you by Internet Explorer 5.0, since the browser implements the Direct Browsing recommendation of the W3C. You don't need a separate HTML file, and your XML document is immediately browsable with Internet Explorer 5.0 or any other XML-enabled browser. Data Schema While DTDs are an important piece in the XML jigsaw, admittedly they aren't very powerful. A DTD looks like a grammar file, and doesn't let you give the language all the particular features you might want to give it. For example, you can't define typed attributes. To resolve this problem, Microsoft proposed a new way to specify a DTD called data schemas that enhance the original specification. A data schema is an XML file, and it provides all the features of DTDs plus some extras. The main differences between a data schema and a DTD include:
When you're declaring an attribute for a node, you're required to specify its attribute type, as in this example: |
|
| An element type is similar, but applies to elements or nodes: |
|
|
An element type defines the name of the tag and its content. It can contain only elements (eltOnly), only text (textOnly), or both (mixed). In addition, it can be empty and contain just attributes. The minOccurs and maxOccurs properties denote how many times the element can appear. The internal <ELEMENT> tag refers to a previously declared element type. The code shown above says that ARTICLES has two children, FEATURE and COLUMN, each of which can appear one or more times.
With a data schema, you can also specify whether the model is closed or open to tags in addition to the ones listed. The keyword seq means that the child elements must be found in the sequence in which they're declared: |
|
| Figure 12 gives an example of a data schema that is equivalent to the DTD shown in Figure 6. To force an XML file to adopt a data schema instead of a DTD to qualify its language, you need to add an xmlns attribute to the root element. For the example I presented earlier, you'd use the following syntax: |
|
|
In this example, I've used the x-schema qualifier. Looking up a schema requires a net hit, so to avoid slowing down performance, the call across the net is only made when x-schema is specified. XML Languages in Practice
An XML language is useful when you need to formalize a way to exchange specific types of information with other people. There are a few languages already available out there that leverage XML. Most notable are the Channel Definition Format and the Open Software Distribution languages that were covered in the November and December 1997 issues of MIND. The former is for linking to Web sites through Internet Explorer channels. The latter provides a way to arrange for the automatic download of updated software packages from the Web. Many other projects are currently in progress. |
From the June 1999 issue of Microsoft Internet Developer.
