![]()
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
|
| Dino Esposito |
| XML Server Pages |
The beauty of XML is that it lets you concentrate on the data and create tags that suit the problem domain. An XML-derived language includes only the tags you listed in your definition file. This gives you a specialized language to describe your data, but what about when you want to display the data? An XML document only describes the data and must be rendered to become usable by the user. To date, most XML articles and applications had emphasized the role of the markup language to store and analyze pieces of data, either on the client or the server. You can embed XML code in regular HTML pages (through data islands) and then read and manipulate XML strings from within, say, an ASP page. This is a useful and cutting-edge solution, but there's much more you can do with XML and Microsoft Internet Explorer 5.0. In this article, I'll look at how an XSL (extensible stylesheet language) document can take an XML source file and transform it into a viewable HTML page. After I look at XSL, I'll demonstrate how this machinery can be moved to the server side and used with ASP pages. Taking Advantage of XSL Suppose you have a complex and strongly structured data type you want to publish through the Web. You decide to describe it using XML, and create a specific language for it—similar to what I showed you in the June installment of Cutting Edge. At this point you must find a reliable and flexible way to make this document available to users. Basically, you need a tool that automatically converts XML to HTML. Last month, I showed how to achieve this by using scripting code and implementing the XML object model. With Internet Explorer 5.0, there's a more elegant and direct approach: using XSL. This will let you automatically display a collection of XML-based documents through Internet Explorer. By using ASP to embed script blocks within the XML tags, you can prepare dynamic and active XML documents. Such documents will only be visible through an XML-enabled browser, but this doesn't have to be a showstopper. It's easy to write code that detects the calling browser and provides a regular HTML page if the browser isn't Internet Explorer 5.0. Extensible Stylesheets
Basically, an XSL file does with an XML file what ASP does with an HTML page: it analyzes the source code to dynamically create an HTML page. But this comparison holds only at the highest level of abstraction. They differ in that XML doesn't rely on Microsoft Internet Information Server (IIS) and Microsoft Transaction Server as the ASP engine does; XSL scripts are processed on the client while ASP works on the server. In both cases, however, you have a kind of processor that takes input and outputs a dynamic HTML page. |
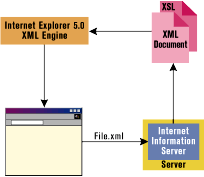 |
| Figure 1: XSL and the Web |
|
Figure 1 shows the role of XSL documents in a Web scenario. The user navigates to an XML file using Internet Explorer 5.0, and gets an XML file with an embedded stylesheet document from IIS. When Internet Explorer renders the XML document, it automatically processes any embedded XSL. The result is an HTML page.
Basically, an XSL file provides a replaceable layout manager to render the XML tags into HTML. This parallels the Windows document/view model; the XML file functions as the document and the XSL file functions as one of its views. Last month I showed you how to define a language to describe a magazine's content. In this issue I'll create an HTML-based view for it. Direct Browsing with Internet Explorer 5.0
Internet Explorer 4.0 was XML-aware, but Internet Explorer 5.0 offers enhanced XML support. The coolest feature is Direct Browsing, which lets Internet Explorer 5.0 automatically display XML files, just as it does with HTML or GIF files. This capability requires the use of XSL, since XML tags have no predefined visual behavior. The Direct Browsing feature includes a default and hidden XSL schema that provides a simple, tree-based view of the content (see Figure 2). |
 |
| Figure 2: The Direct Browsing Feature |
|
To produce the Direct Browsing feature, a client-side processor scans the XML source code and expands any tag with the corresponding HTML code. You can use loops and conditional statements, create attributes, and add script code to the final HTML page. If needed, you could also execute some script code during XML processing.
The syntax to associate an XML document with its stylesheet is: |
|
| If you're using XML to manage your own data types (for example, magazine publication information), the following would be a good heading for all files: |
|
|
The XSL Syntax
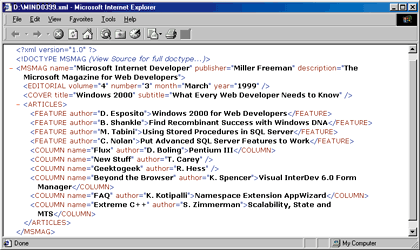
As I showed you last month, you don't need XSL to display an XML document. Figure 3 shows some XML source code, while Figure 4 displays the result. To display the data,
I defined an HTML page with script code to parse and import the content of a separate XML file. Figure 5 is the DTD (Document Type Definition) of the language used in the XML document. |
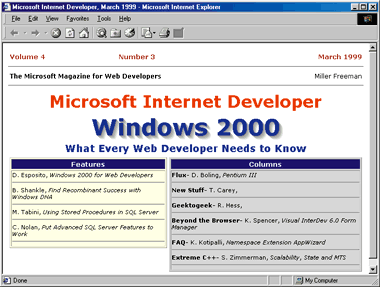 |
| Figure 4: The Resulting Dialog |
| With XSL, the source XML is interpreted by Internet Explorer 5.0 and rendered as the XSL file suggests. Figure 6 describes the main XSL keywords. The following is typical startup code for an XSL document: |
|
|
The first line is optional; it declares that the document follows the XML 1.0 standard and employs the specified character set. Compliance with the 1.0 standard is recommended, but imposes minor inconveniences: you must enclose names in quotes and enclose script code within special delimiters.
The next block of code declares which namespace must be used to identify the tags in the document. Here, the tags prefixed by xsl and html refer to the related URLs for their meaning and role. The line |
|
|
makes the latter namespace the default. This means that <TABLE> and <html:TABLE> are equivalent in this XSL context. As a result, the HTML tags won't be processed, but just outputted. XSL tags, in contrast, will be parsed and expanded. Last, the language attribute defines the default script language for the document.
As mentioned earlier, the link between the XML and XSL files is established when the XML file includes a reference to the XSL file with a line like this: |
|
|
Normally, an XSL file works by applying templates to the XML source code. An XSL document is a sequence of templates, each of which applies to one or more XML tags.
This is a schema you'll frequently see in XSL files: |
|
| It means that the code between the initial and the closing tags must be processed for all tags whose names match the value of the attribute match. For example, the following tag applies to the entire document and defines a virtual tag that is the parent of the actual root tag: |
|
| In other cases, you give the name of a specific tag. For example, this tag applies those rules to the tag COLUMN. |
|
|
Normally, you would define and apply templates for the whole document, and for any tags that are repeated in the document. This is the case with COLUMN, which renders an article for any of MIND's columns.
Templates are processed in much the same way as ASP code. The ASP parser leaves the HTML code unchanged and expands what is between <% and %>. Here, the HTML tags, which are recognized via the namespace, are simply copied, while <xsl:xxx> tags are processed to produce raw text or HTML code. This code defines the header section of the HTML page: |
|
| With the XML file shown in Figure 3 and the DTD in Figure 5, it produces this HTML: |
|
|
For clarity, I omitted the line that links the Cascading Style Sheet (CSS) file. Notice that the MSMAG name evaluates to a shortcut defined in the DTD, and that year has a default value.
The tag <xsl:value-of> returns the content of the specified tag. For instance, the following code returns the value of the month attribute in the EDITORIAL node: |
|
|
Notice that you must specify the full path to the node using a notation like a file path. Whether you specify a full or a relative path depends upon which node in the template is selected. This fragment is taken from the template that applies to the root document, so the full path is necessary. If the template applied to EDITORIAL, just specifying @month would have worked.
Notice also that an attribute name must be prefixed by @, and that you need to respect the case of the tag names. The following tag isn't meaningful and will be silently discarded: |
|
|
There will be no output, but no error messages either. So be sure to check the case of the tag names.
If the HTML code you want to produce depends upon the values stored in some attributes or needs to be calculated on the fly, you have two options: use a conditional XSL statement or run a script procedure. Your choice will depend upon the context. In either case, here's how to proceed: |
|
| This code checks whether the COVER tag exists, and if so, displays its contents. In contrast, the following code compares an attribute against a specific value: |
|
| To embed a piece of script code, you must use the <xsl:eval> tag. For example, to check for the existence of the COVER tag you could also employ a JScript® function that reads in the source code and branches accordingly. The <xsl:if> tag doesn't support an else branch, so the script approach lets you specify an alternative text. |
|
| The XSL processor supports more flexible constructs. For example the statements <xsl:when>, <xsl:choose>, and <xsl:otherwise> together act like a Select Case or a switch statement. Another frequently used XSL statement is <xsl:for-each>, which you can use to loop through all the tags of a certain type. The following is the typical way to use a for-each tag: |
|
|
Note that once you select a node, the iteration will work only on its child nodes. The previous code demonstrates how to apply a template to all the FEATURE tags inside the ARTICLES node. Here, the XSL template is like a subroutine that works on a subset of tags. Creating HTML Tags on the Fly I'll conclude this overview of XSL tags with a few words on creating HTML elements and attributes on the fly. In most cases, an XSL document is an HTML template. The processor writes out the various tags by reading the XML source code and applying the rules. Sometimes, however, you may need to create an HTML element or a simple attribute during processing. A subtle problem you'll encounter is that the final HTML code must be XML-compliant, whether or not you use the version directive. This means that you must use quotes for attribute values, and closing tags for even basic tags. For example, for the horizontal line tag you must use <HR /> instead of <HR>. If you want the value of a XML attribute to become the value of an HTML attribute, you must know how to manage quotes. Let's say you have the following XML code |
|
| and want the GIF file to become the source image of an <IMG> tag in the final HTML code. You may think to use a similar pattern in the XSL file: |
|
|
But this doesn't work because the processor expects to find an opening quote after src=. If you enclose the <xsl:value-of> tag in quotes, then you'll be warned that a < character can't be part of an attribute value.
A possible solution is to force the XSL file to add a bit of script code to execute at startup (the onload event) that will set the src tag of the specified element: |
|
| Since you aren't specifying the content of an attribute, you can put quotes around the tag <xsl:value-of>. This approach works, but it requires Internet Explorer 4.0 or higher because it exploits the Dynamic HTML object model. A solution that will work with any browser is to create the needed element or attribute at runtime: |
|
| The output is just what you were waiting for: |
|
|
The XML Object Model XSL can contain script code written in any language that supports Active Scripting. In virtually every case, the script code must work on the node that the processor is dealing with. More generally, it may need to get information from the XML source code. By using the this keyword, any function may access the current node and manipulate it through the methods of the Internet Explorer 5.0 XML object model. Let's take an in-depth look at the source code I mentioned earlier. This code returns the cover title of the magazine: |
|
|
This function is invoked in the main template, so the this keyword points to the parent of the root node. By calling selectNodes, you can select the node you need and access its collection of attributes. Notice that the XML object model in Internet Explorer 5.0 is significantly different from the one in Internet Explorer 4.0.
Figure 7 shows the complete XSL code that transforms an XML page written according to the language rules in Figure 5 into an HTML page like the one shown in Figure 4. Moving to ASP
So far I've written an XML file to describe magazine data and display it (under Internet Explorer 5.0) using the XSL information exposed within the file. To change the way the data is presented, you only need to replace the XSL file, which constitutes the HTML presentation layer for the XML source code. In principle, an XSL file could be used to convert the XML code (the data layer) into other renderable formats such as RTF.
Put this way, it seems that XML files replace HTML files in the development process. However, XML files are static objects, just as HTML pages were before the advent of ASP. Don't be fooled by the fact that you can embed script code and some logic into XSL. An XSL document is a general set of transformation rules that apply at the level of the XML language you're working with. If you need to create an XML file whose content must be decided at runtime, you can't rely on XSL unless you maintain separate XSL files for each XML document. |
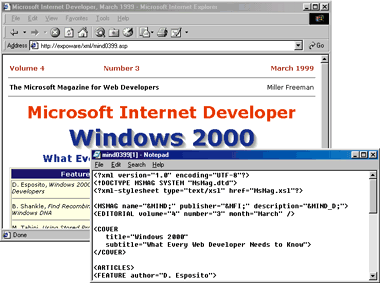 |
| Figure 9: An ASP Page that uses XML |
| But there is another solution: you can write ASP pages using XML instead of HTML tags. To do this seamlessly, just rename the XML file so it has an ASP file type, and put it in a directory on your Web server. In Figure 9 you can see that the source code of the ASP page is pure XML code. Since the XML source code is an ASP page, you can add a <% %> block within it. Of course, make sure that the final output is XML-compliant. For example, this is perfectly valid code: |
|
| And nothing prevents you from navigating to a URL like this: |
|
|
Supporting Other Browsers DTD validation and Direct Browsing are supported features on the client side, so dynamic XML files still require a browser capable of XSL processing. At press time, only Internet Explorer 5.0 supports XSL. However, the use of ASP code with the powerful XML object model can be of some help. The idea is to write your XML-based ASP pages with a special heading that can work around the browser's differences, like this: |
|
|
If the name of the calling browser contains the substring "MSIE 5.0", then the browser is Internet Explorer 5.0 and you don't need any special processing. The XML source code can be
sent as-is to the browser, which will then perform the required transformation. Otherwise, the XML-to-HTML transformation must take place on the server side so that the browser will receive pure HTML code.
There are two main steps in implementing this solution. First, the XML source code is converted to HTML using the XSL stylesheet information. Second, the final string is sent back to the browser using the ASP Response object. The conversion from XML to HTML requires you to install a translation component on the server. This component may not support XSL. The Internet Explorer 5.0 XML object model is one such component, but you are free to use another. You could even write your own. Simple XML parsers exist in many forms, including Java language applets and COM objects. In last month's column I wrote one by embedding script code to parse XML code and output HTML text. Most XML parsers require that you initialize the engine by passing it a file name. This is the case with the Internet Explorer 4.0 XML object model. If you want to pass an XML string, write it to a temporary text file before proceeding. In this article, I assume that you have Internet Explorer 5.0 or at least its XML modules on the server, so that the following code can be used to create an instance of the Internet Explorer 5.0 XML parser: |
|
|
Figure 10 shows the full source code for an ASP page that detects the browser and returns a translated HTML page.
Two instances of the parser are needed because I'll be working with two separate XML documents: the XML file itself and the XSL file. Each document needs separate parsing. The ASP page is converted into HTML code and the result is returned to the browser. The conversion assumes the presence of the original XML file in the same folder as the ASP page. (Of course, the XSL, DTD, and CSS files must also be there.) The XML file has the same path and name as the ASP file, but a different extension. If you don't want duplicate XML and ASP documents, you can extract the XML code from the ASP page. The assumption is that any XML-derived ASP page is identified by a heading of script code and the body of the XML document. This means that the XML code can be found after the first closing %> (see Figure 11). Notice this is specified as |
|
|
to prevent confusion while parsing.
The code reads the ASP code into a variable, then strips off the characters until the closing %>. What remains is assumed to be the XML body, and is written to a temporary file. This file is used to initialize the XML parser, and is deleted before the final call to Response.End. In this way, you deal only with ASP pages and can manage the XML portion of the process behind the scenes.
Figure 12 lists the full ASP code for an XML page that any browser can access and display. It requires only that the ASP page have a special code heading, and that an XML parser resides on the server. (The parser doesn't necessarily have to be Microsoft.XMLDOM.) Figure 13 lists a JScript batch file for offline conversions between XML and HTML. Finally, Figure 14 demonstrates how Netscape Communicator works with the code in Figure 12. |
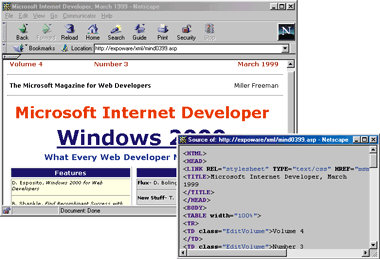 |
| Figure 14: Netscape does XML |
|
New XML Server Pages?
Let me summarize what I've discussed so far. The starting point is that Internet Explorer 5.0 supports Direct Browsing of XML files. In other words, it can provide an HTML-based view of any XML content. The translation takes place on the client side, based on an XSL stylesheet document that's embedded in the XML body. As of this writing, no other browser provides a similar capability. If you have to work with pages that render data, you will find it easier to describe the data with XML than to immerse yourself in the graphical details of the traditional HTML approach. However, by replacing the raw HTML with XML and XSL, you'll lose the features of dynamic ASP pages. I've shown you how to rename XML files using an .asp extension to gain the benefits of ASP. Under Internet Explorer 5.0, the browser will transform the XML to HTML via XSL. With other browsers, if you have an XML parser on the server, you can use ASP to detect the browser, translate the XML to HTML, and send back pure HTML code. Since the browser refers to an ASP page, you must extract the XML code to process it. You can maintain separate XML files with the same name as the ASP files, or you can dynamically extract the XML code from the ASP page and create a temporary file. XSL is a powerful technology that you will want to try, but currently it can only be used with Internet Explorer 5.0. Combining XML with ASP enables you to offer compatibility with other browsers today. |
From the July 1999 issue of Microsoft Internet Developer.