![]()
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
cutting@microsoft.com |
| Dino Esposito |
| New Features in OLE DB 2.5 |
The components that make up MDAC include ActiveX®Data Objects (ADO), OLE DB, and that old favorite ODBC. MDAC contains the key technologies that enable Universal Data Access (UDA) which, in turn, is central to the Windows®DNA architecture. Check out my article, "Exposing Your Custom Data In a Standardized Way Through ADO and OLE DB" (Microsoft Systems Journal, June 1999) for more information about OLE DB and the various MDAC components. I'll begin this column by providing an overview of the OLE DB architecture and design. Next, I'll analyze what's new in the upcoming version 2.5 of MDAC, much of which involves XML and custom URL schemes. My emphasis will be on the basic principles of OLE DB because it necessitates a significant change in the way you plan and devise the data access strategy in your applications. Developers new to ADO and OLE DB typically ask: Why do we need OLE DB? Don't we already have ODBC? Why should we use ADO? Don't we already have DAO and RDO? At the highest level of abstraction, OLE DB and ODBC have a similar structure. However, OLE DB has a more general architecture and facilitates access to any data through specific modules. In addition, OLE DB provides an abstraction layer over the underlying data source, while ODBC is bound to the physical structure of the data because of its SQL underpinnings. With OLE DB, you can integrate heterogeneous data sources without moving a single byte of data from its original location. Instead, you build an intermediate component that publishes data in a standardized way. Reflections on OLE DB
Many people like being able to access data from different stores, regardless of the storage media or internal structure. In an enterprise-wide scenario, a company's data store is not restricted to tables, indexes, stored procedures, and triggers that are embedded in a relational DBMS. Data also includes Word documents with content such as company-wide policies, faxes, spreadsheets, email messages, graphics, Web pages, and anything else that can be expressed in digital form. This is a fundamental point to understand if you want to provide good service to your customers. You need to think of data more in terms of a universal access strategy than a universal storage medium. It's better to have your code access data wherever it resides than to migrate the company's data store to a new system in order to meet your code. |
 |
| Figure 1: The MDAC Architecture |
|
There are providers that let you access the most common DBMS and legacy archives on mainframes, but you have to write your own providers to do the rest, and often you don't have the right tools to render the data properly. Let's say, for example, that you want to expose a Microsoft Excel worksheet through OLE DB. The cells of a document can be treated as a table of records. However, a Microsoft Excel document may contain multiple pages. This makes it a semi-structured document that OLE DB 2.1 doesn't let you manage properly. The situation is even worse with Word documents. You can't express an entire Word file as a table. You must expose it as a collection of tables (paragraphs, comments, favorites, and styles) or
as a tree. Once again, you are working with semi-structured data. There are a few characteristics of OLE DB 2.1 that need improvement before they can be used with any type of data. First of all, OLE DB 2.1 rowsets (called recordsets in ADO jargon) must be tabular, with the same number and type of columns in each row. You can't have row-specific columns. This creates a problem when modeling hierarchical data. A solution is to append an additional field to hold a child rowset that must be repeated for each row. This gives a somewhat hierarchical structure, but it's not a real tree or a collection of nodes. Another limitation is that with MDAC 2.1 a consumer app must know many details about the providers to which it wants to connect. It must know the name (progID) or the CLSID, as well as the syntax of the supported query language. OLE DB 2.5 removes the two limitations just described, providing support for semi-structured data and direct URL binding. It lets you manage data in either tabular or nontabular forms, and provides a URL-based alternative to connection strings and command texts. This feature, called direct binding, brings an immediate advantage: you don't need to know the details about the provider. Just use a URL-based description of the data source you want to access and a new OLE DB service will do the rest. I'll show you how this works later on. The new features in version 2.5 don't require you to rewrite existing consumers or providers. They come in the form of new interfaces to implement. If you don't implement them they won't be available, but the resulting provider will continue working as always. Changes to the OLE DB Object Model
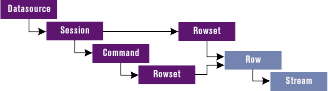
The current OLE DB object model revolves around four main objects: Datasource, Session, Command, and Rowset. The datasource is the logical link between the location and the data. An application specifies the connection parameters through a Datasource object. |
 |
| Figure 2: The OLE DB 2.5 Object Model |
|
Semi-structured data is data expressed in a nonrectangular and somewhat homogeneous way—for example, through trees, collections of collections, or row-specific properties. Typical examples of such data are directories and files in a file system or folders and messages in an email system. Probably the best example is an XML document. An XML document can be seen as a set of rows (tags), but each tag can have its own set of attributes resulting in an irregularly shaped rowset, where only a few groups of records have the same number of columns. The Row object lets you manage this type of a semi-structured data. It's an OLE DB object that contains a set of columns of data. A Row object can represent a row in a rowset, the result of a single SQL query, or a node in a tree-structured namespace, such as a file in a directory or a message in a mail folder. This object endows finer granularity to the OLE DB object. With OLE DB 2.1 you stopped at rowsets; now you can go down to row level. Note that rows can exist independently from rowsets. A row can be either a row in a rowset, or an object that includes a rowset as one of its column values. It also can come from a single select statement such as SELECT INTO, where you retrieve a single row of data and copy it to variables. In this case, you can have a row with as many columns as the number of retrieved variables. Rowsets were designed for high-volume access, and use accessors to bind the provider's columns to a return buffer provided by the consumer. Since all the rows in a rowset are supposed to have the same format, the accessor caches information for better performance. Row objects were designed to model three types of data: hierarchies, rows of a rowset, and single objects containing a traditional rowset. They are fast, efficient, and modifiable, so you can add and delete columns. Figure 3 lists the interfaces, both mandatory and optional, that form a Row object. The IColumnsInfo interface provides information about the columns of the Row object. IConvertType provides information about the data type conversions supported by the Row object. IGetSession returns an interface pointer on the Session object within whose context the Row object was created. Finally, IRow contains methods for reading column data from a Row object and for obtaining the source rowset of the Row object, if one exists. These methods allow easy navigation between the subtrees of the semi-structured data. To retrieve and set the values of one or more columns from a Row object, the consumer calls IRow::GetColumns or IRowChange::SetColumns. These methods do not require an accessor object. Instead, the consumer passes an array of special structures called DBCOLUMNACCESS (see the Platform SDK documentation). In general, the consumer must allocate and supply buffers and the provider takes care of all necessary type conversions. A column also can contain interface pointers to IDispatch or IUnknown. An interface pointer will be returned to you through the method for accessing columns that I discussed previously. A Stream is the object used to manipulate the content of a row column, which can be a binary object, a COM object, or a compound document. In ADO 2.5, the Stream object can be seen as a powerful replacement for the GetChunk and AppendChunk methods. It is required to implement the ISequentialStream interface, which is a stripped-down version of the IStream interface typically used to work with OLE-structured storage. ISequentialStream works much the same way as IStream, but provides forward-only reading and writing of data. Direct URL Binding
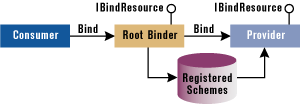
The rationale behind direct URL binding is to eliminate all intermediate objects needed to access a resource (for example, Rowsets and Rows). In truth, these intermediate objects don't disappear; they're just hidden by a direct binding core service that maps a URL to a resource. The result is that a consumer doesn't need to know about the details of the provider. There are no more complicated connection strings or command syntaxes to remember. A consumer application connects to a URL and gets back a rowset. All the OLE DB procedures required to produce that rowset are hidden and executed in the background. |
 |
| Figure 4: Direct URL Binding |
|
Figure 4 illustrates the architecture of direct URL binding. The main interface is IBindResource. A consumer connects to the global Root Binder object and requests the interface. It calls a method called Bind, specifying the URL, the type of the object required, and the interface it wants. The prototype of the Bind method looks like this: |
|
|
The REFGUID parameter lets you use constants to specify the type of the required object. Once the Root Binder object holds the URL, it immediately looks at the registry node where the registered URLs are mapped. If the passed URL matches one of the registered URLs, then the specified provider is loaded and queried for the same IBindResource interface. If all goes well, the Bind method on the provider is silently called by the Root Binder, passing the same arguments it received. The provider that supports direct URL binding must expose IBindResource and define its data in a Web-compliant way. It must partition the URL namespace into components that are specific to the data owned. For example, if you have an OLE DB provider that returns a recordset of email messages from any of your message folders, then you might want to use a URL like one of these: |
|
|
In the first case, the provider is supposed to return a recordset with all the email sent by a particular sender. In the second case, it's asked to retrieve all the messages sent from a certain date onward. Interpreting the URL-specific syntax is up to the provider, and takes place from within the provider's Bind method. IRegisterProvider manages registration and unregistration of URL schemes to specific providers. You use the IRegisterProvider's SetURLMapping method to register a provider as a direct URL binding data source. You are only required to pass in the URL scheme and the CLSID of the COM module that contains the provider itself. Direct binding offers quicker and more direct access to resources, and simplified hierarchy navigation. You can also identify a row with a URL name or embed commands in the URL. It is up to you to define the URL scheme of your provider. ICreateRow is a mandatory interface on the OLE DB Root Binder object and on all provider binder objects. Use ICreateRow's CreateRow to create a new URL-named object. A Row object can optionally implement the IScopedOperations interface. This interface lets you execute operations in the context of the subtree rooted in the row. A row, in fact, can be the root of a tree in OLE DB 2.5 nontabular rowsets. You can bind or open descendant rowsets or copy/move/delete child elements (identified via a URL) from the row down. Basically, IScopedOperations brings together the management operations that you can execute on a Row object. The OLE DB Provider for Internet Publishing
The OLE DB Provider for Internet Publishing is a tool that comes with both Microsoft Office 2000 and Microsoft Internet Explorer 5.0. Clients can use the OLE DB Provider for Internet Publishing to access data residing on HTTP
servers that support the FrontPage®Web Extender Client (WEC) or Web Distributed Authoring and Versioning (WebDAV) protocol extensions. It contains modules called protocol drivers that can produce and parse both WEC and WebDAV, and it maintains a cache of associations between URLs and the required protocol. With this tool, users can access documents stored on HTTP servers from within an OLE-aware application. Microsoft Office 2000 uses it to simplify the publishing of Office documents on a local intranet or external Internet site. The use of File Open and File Save dialog boxes makes saving documents to a Web server as easy as saving them to a hard disk or to a file server. About ADO 2.5
OLE DB 2.5 is the underpinning for ADO 2.5, the companion technology scheduled to ship with Windows 2000. While OLE DB is very powerful, its complexity and surfeit of little-used features make it awkward to use. For this reason, when ADO was introduced it gained a lot of success. Unfortunately, though ADO is easy to code, it is far slower than OLE DB. To simplify OLE DB development you can
use the ATL classes that shipped with Visual C++®6.0. However, these classes won't provide the OLE DB 2.5 features until the next release of Visual C++. In the meantime, the only way to program OLE DB 2.5 is through the raw API or the ADO 2.5 wrapper. Summary
OLE DB 2.5 and ADO 2.5 were still in beta testing as of this writing. I suggest that you check out the OLE DB and ADO Web sites at http://www.microsoft.com/data/oledb for up-to-the-minute information. Also, the Microsoft Platform SDK that comes with Windows 2000 contains structured documentation you can use to extend your knowledge on this topic. |
From the October 1999 issue of Microsoft Internet Developer.
