![]()
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
Find Recombinant Success with Windows DNA
Bruce Shankle |
| As monolithic programs evolve into multilayered Internet applications, Windows DNA is your blueprint to better-functioning apps. |
|
Are you in tears over n-tier? Making a bad move in the distributed application game can certainly lead to that. Fear not, my friend. Microsoft has a strategy in place for a broad range of technologies that will help you architect the best solution for your distributed computing needs: the Microsoft® Windows® Distributed interNet Applications Architecture (Windows DNA).
As you know, a well-thought-out architecture is critical to the success of any computing system. Unfortunately, many developers rush through the design in order to get down to coding—or to have an answer for the managerial query, "Why aren't you coding yet?" While immediate coding feels more productive (and more fun), taking shortcuts with design issues can cost you dearly in the long run. This is where having a model to follow—like Windows DNA—can be a real plus. Merit in the Model So what is Windows DNA? It has a dual nature: it's part marketing, part architecture. Microsoft has been talking about Windows DNA for over a year now (see http://www.microsoft.com/dna). You'll find no shortage of white papers on the topic. Sadly, most of the available materials are of the marketing variety and begin with some type of pun on genetic engineering. At first glance, it looks like a lot of what you've been doing for years now is Windows DNA. As a colleague recently asserted, "Many have tried, and most have failed, to explain Windows DNA in a way that will make people think it's a benefit to them instead of just a new bag for the same old groceries." Well, that certainly sounds like a challenge to me. Is there merit in Windows DNA besides its all-encompassing marketing shroud? Windows DNA is not a product per se; it's an architecture model for developing distributed applications with Microsoft technology. What is Software? To fully understand and appreciate the Windows DNA model from a software development perspective, you have to step back and look at the evolution of PC-based distributed computing. Software is just a bunch of 1s and 0s, right? It's not very often that you stop to think about the fundamentals of a program: input, processing, and output (see Figure 1). These are the building blocks of all applications. The word "application" was coined to identify various ways of applying computers to useful tasks. For example, Microsoft Word is an application of computing for creating documents. It's easy to identify examples of input, processing, and output within that application. It's not always convenient to think in such low-level terms about an application because there could be many parts of an application or system doing these three tasks. |
 |
|
Figure 1: Building Blocks |
This is surely a justification for larger-scale architectures. If you think in terms of input, processing, and output, you'll design better applications and better components. But when thinking on a larger scale, what you need are some less granular terms—bigger building blocks with which to design larger applications. It would be nice if the building blocks allowed you to include services from places other than the local operating system. Where do you start? Let's think in terms of layers.
Thinking in Layers
Since many applications involve a user, a real flesh-and-blood person, it makes sense to group programs and devices that communicate with the user into a logical layer. This layer is called the presentation layer because it presents information to the user. Things you might find in a presentation layer include a Web browser, a terminal, a custom-designed GUI, or even a character-based user interface.
Besides communicating with the user, most applications must process data. Almost all data-processing applications have a stringent set of rules that govern exactly how data is handled. A typical example is an application that processes a credit card number at the point of sale, and needs a second form of ID for purchases over $5000. Failing to provide this would break a rule, a business rule. Since many applications have business rules, they're grouped into a layer called the business logic layer. If you do a good job of designing this layer, you just might be able to use it in more than one place in the presentation layer.
The business logic layer processes logic on data. Where does it store and retrieve this data? Well, that really depends on the application. It could be a file or a database on the local machine, a remote database, or an application running on another computer. Since there are so many possibilities, it makes sense to group them into the data layer (see Figure 2).
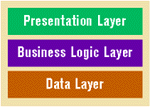 |
| Figure 2: App Layers |
Large application building blocks are grouped by similar concepts into three layers:
These are the same application building blocks defined by Windows DNA. But wait—there's more. Windows DNA has the word Internet in it (or interNet to be exact), which implies it's for building networked applications. While it's true that Windows DNA is an excellent architecture for modeling networked systems, you can reap many benefits of its layering approach in other applications. What differentiates standalone versus networked versus distributed applications is where, when, and how each of the three layers is implemented. You can think of almost any application in terms of these layers. Let's look at the three major types of software applications—standalone, client-server, and distributed—in terms of layers.
Single-Stoned
Many PC programs are contained in one binary executable. In other words, a single program is the entity the user interacts with in a relatively small input-processing-output cycle. Input comes from devices attached to the PC. Chips inside the PC do the processing, and output goes to devices directly attached to the PC.
Self-contained applications of this nature are called monolithic, which comes from the Latin word monolithous, meaning single-stone. A monolithic application contains everything necessary for a computing task in one unit. On the PC this means the logic necessary to communicate with the user, process data, and manage data storage and retrieval. Figure 3 shows the layers of a monolithic application.
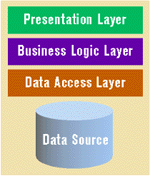 |
| Figure 3: Monolithic App |
Although monolithic applications are easy to develop, they are hard to scale. In the context of modern businesses, the data-processing scope of monolithic applications is implicitly limited to what can be done on a lone PC. But you'll find that many small businesses use one or two PCs this way, and most are quite happy with what they have. The ability to operate in this fashion is one of the PC's strengths.
There are three lessons you can learn from monolithic applications:
Two-tier Architecture
Affordable networking allows PC software to assume roles in multiuser systems where data can be centralized and accessed by many users. You can easily form two tiers; the first tier is the user's application, while the second tier is the data source. When it comes to business applications, there are two fundamental two-tier approaches: LAN-enabled monolithic applications that simply share access to data files (like Microsoft Access MDB files) and client-server applications that share access to a database management system (like SQL Server™).
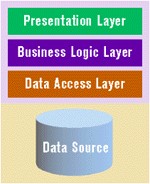 |
| Figure 4: Monolithic App + LAN |
Monolithic applications on a LAN (see Figure 4) are implemented by running a copy of the application on each machine and using a network drive as the storage location for the database. While systems like this are affordable and work well in small workgroup settings, they can be frustrating. One major disadvantage is that the database is not protected—a misbehaving client can easily corrupt it. Another potential problem area (depending on the implementation) is the intimacy the application must have with the physical database structure. If the database format is modified, a user's application could suddenly be rendered useless. Furthermore, complicated OS-specific locking issues are always a problem.
A true client-server architecture addresses these weaknesses because the database server process acts as a guard for the data (see Figure 5). Client-server applications also require less knowledge of data physics, and can use one or more levels of indirection when requesting data. An example is coding to the ODBC API, itself a level of indirection to native database drivers.
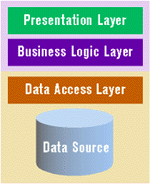 |
| Figure 5: True Client-Server |
Two-tier architecture is a logical step on the way to multi-user collaborative computing systems. However, it is not without its share of pitfalls, especially when the number of clients grows to absurdity. Two-tier requires some or all of the business rules regarding data processing to be in the first tier. Sure, stored procedures and triggers on a DBMS help, but having lots of business logic in the first tier makes for fat applications that are hard to maintain and upgrade. Also, this doesn't scale well because invariably every client wants a live connection to the database.
Here are the key characteristics of two-tier applications:
Does the layered approach of Windows DNA have merit for two-tier architecture? Yes. Thinking in terms of layers when building two-tier systems gives you an easier path to growth. Again, encapsulating logic into COM components makes it easier to maintain applications. So where do you grow from client-server? Simple. Add another tier.
Three-tier Architecture
One of the problems with client-server is that the first tier generally implements two layers, the presentation layer and the business logic layer. To address maintenance and scalability problems you must move the business logic layer out of the first tier.
Traditional three-tier systems abstract business logic into a separate layer commonly called the middle tier (see Figure 6). There are a variety of approaches for implementing middle tiers depending on the data layer, the types of clients, the developer's choice of tools and technology, and the communication mechanism between layers. Although some developers invent their own tier-to-tier communication mechanisms when implementing a middle tier, it's not something I'd recommend. In the long run, it's better to choose a mechanism that you don't have to maintain. Windows DNA recommends the programming language-independent Distributed Component Object Model (DCOM), which provides proxies to clients for business logic components running on other servers.
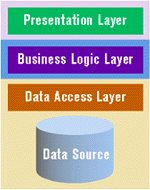 |
| Figure 6: Traditional Three-Tier |
Whatever the implementation mechanism, the fundamental purpose of the middle tier is to provide a level of indirection to business logic that allows it to be executed and resource-managed elsewhere. This opens the door for building more scalable, easier to manage systems. Such systems are more scalable because the resources, like connections to a database, can be pooled in the middle tier and just-in-time (JIT) activation can be employed to instantiate objects and components as clients request them. They are easier to manage because, if properly implemented, middle-tier logic can be upgraded without affecting client installations.
Here are the key characteristics of traditional three-tier applications:
Ready for the Internet? While the traditional three-tier model addresses the shortcomings of client-server for high numbers of users, there are a few problems to be aware of when moving to the Internet.
Internet and Tiers
Traditional three-tier approaches, depending on their implementation, can have a few problems when introduced to the Internet. The most common headaches stem from two areas: security and noncontinuous communication. This forces you to consider communication between tiers and where to store state information, things you probably didn't think too much about when you designed your traditional three-tier application (see Figure 7).
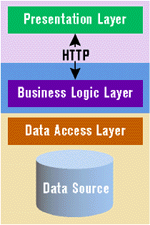 |
| Figure 7: Internet Three-Tier |
Because the Internet is open to the public, you have to implement security mechanisms to keep out the bad guys. The ever-present firewall monitors network traffic between systems and either allows or disallows communication based on some authentication protocol. I've worked on several low-level communication problems where firewalls were remapping IP addresses and port numbers between systems. Ouch!
The most popular Internet protocol, HTTP, does not provide a continuous connection to a server, something you might have relied on in your traditional three-tier application. This does not mean three-tier systems cannot be used effectively in Internet scenarios, it just means you have to take into account the nuances of Internet security mechanisms, TCP/IP and HTTP, cookies, browsers, and Web servers. Once you understand these requirements, you can safely use the Internet as the transport for your multitiered applications.
So what are the unique considerations when developing three-tier Internet applications?
Wrap-up
The white paper at http://www.microsoft.com/dna/solutions.asp does a good job of explaining the goals of Windows DNA, but you might come away scratching your head. While they have some nice pictures to put it all in perspective, at first glance it seems like Windows DNA is an all-encompassing architecture that features every available Microsoft product. Pretty pictures aside, I can sum it up in one sentence: Windows DNA is a distributed computing model for the masses based on COM that allows you to utilize current investments and take advantage of existing and new Microsoft technologies.
Look beyond its role in marketing and you'll find that the Windows DNA application partitioning scheme will help you manage the design, development, maintenance, and growth of a computing system. If you use COM (on which much of Windows DNA is based) as your foundation, you'll end up with a set of language-independent components flexible enough to play a role in any level of your enterprise.
Windows DNA takes into account the evolution of software from monolithic beginnings to multitier applications. It provides developers with high-level building blocks for constructing large-scale applications by grouping concepts and technologies into three layers: presentation, business logic, and data. It promotes COM as a
language-independent model for developing components that can be flexibly plugged into any of those layers and offers a roadmap for utilizing Microsoft technologies to bring distributed computing to the masses.
|
|
|
http://www.microsoft.com/dna/default.asp
http://msdn.microsoft.com/developer/news/feature/fmcorp/default.htm
|
From the March 1999 issue of Microsoft Internet Developer.