February 1999
![]()
With Further ADO: Coding Active Data Objects 2.0 with Visual Studio 6.0
Dino Esposito
Code for this article: ADO20.exe (15KB)
This article assumes you're familiar with Visual Basic, Visual J++
Active Data Objects combines the universal nature of OLE DB with the ease of use found in models such as RDO and DAO. ADO encompasses all the data types that can be represented by the OLE DB standard interfaces. In other words, ADO is extensible without any effort on your part.
Dino Esposito is a senior consultant based in Rome. He works for Andersen Consulting, specializing in COM and scripting. He authored Visual C++ Windows Shell Programming (WROX, 1999). Reach Dino at desposito@infomedia.it.
Data access and manipulation is an intrinsic part of any real-world application. Whether it's relational or not, whether a DBMS is present or not, and no matter the storage platform, data is just data-not necessarily a file in a given binary format.
The developer community needs modern development tools with simplified interfaces to rapidly access data. Microsoft's answer to this problem lies in the Universal Data Access (UDA) architecture, featured in Stephen Rauch's article, "Manage Data from Myriad Sources with the Universal Data Access Interfaces" (MSJ, September 1997). In a nutshell, UDA is the theory that OLE DB puts into practice. Everything that is specific to a data source-a spreadsheet, an email message, or an AS/400 archive-is filtered by the OLE DB interface and represented in a universal format that the applications can always access in the same fashion (see Figure 1). The intermediate layer that sits atop OLE DB and handles calls from the applications is called Active Data Objects (ADO). It is the proposed standard for programming any kind of data source for which an OLE DB-compliant provider exists.

Figure 1 OLE DB
Let's go over the new features of ADO 2.0 that comes with Visual Studio 6.0®. I'll show you how to program ADO with the Visual Studio 6.0 suite. I'll concentrate on the ADO support built in the Java language Windows® Foundation Classes (WFC) and Visual Basic 6.0, with a quick look at Visual C++® and Visual InterDev.
An Overview of ADOADO is an object model meant to combine the universal nature of OLE DB with the ease of use and comfort found in models such as Remote Data Objects (RDO) and Data Access Objects (DAO). ADO is a COM automation server accessible either through IDispatch or vtable functions. More importantly, ADO encompasses all the data types that can be represented by the OLE DB standard interfaces. In other words, the ADO object model is extensible without any effort on your part. Through the usual ADO programming interface you can handle virtually everything, even information you'd never thought to see formatted as a recordset.
ADO gets high marks when it comes to performance, memory footprint, thread-safety, freethreading, distributed transaction support, and remote data access over the Web. As part of the Microsoft UDA strategy, ADO is intended to become the standard model to access data across different platforms and sources. Over time, it is slated to replace all other models. ADO collects all the best features of RDO and DAO and reorganizes them in a slightly different object model that also provides full support for events. If you want to delve into the differences among the various Microsoft data access technologies, read "Data Access Technologies," by Robert Green in the Technical Articles area of MSDN.
Moving your current RDO-based systems to ADO doesn't require a complete reengineering of the system, but it is not a trivial task either. The complexity of the system stems from the difficulty of porting rather than the differences between RDO and ADO. Moving to ADO has its rewards, but I don't recommend that you do it if it is not an absolute necessity.
ADO from an Enterprise Point of ViewUDA gives the Windows DNA (Distributed Internet Applications) architecture a mechanism for data access and storage. For a closer look at UDA, see "Say UDA for All Your Data Access Needs," by Aaron Skonnard (Microsoft® Interactive Developer, April 1998).
Any distributed enterprise system normally spans multiple data sources, even across different hardware platforms, including mainframe and Microsoft Access databases, spreadsheets, and SQL Server tables. Recently, I was involved in a case study of a heterogeneous image databank where the content included SQL Server tables (including images and descriptions), separate images indexed by name-related ASCII and Word documents, and proprietary files with a mix of images and text. When you have to cope with a project like this, you start to appreciate the importance of a uniform approach and a common set of objects.
I've seen teams working on related projects use different approaches to access data. Often this happens because one team starts out developing a subproject considerably in advance, or because they inherit some legacy code, or, more simply, because the projects are only partially related
and the only thing they have in common is the underlying data, and possibly the buyer. So it happens that one team uses RDO for data manipulation, while another one uses ADO. In many cases, similar code blocks are developed twice (or more): once for RDO and once for ADO. The common layer between the projects is the physical data storage (see Figure 2).
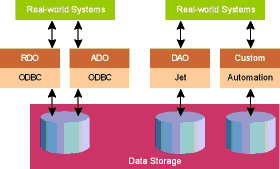
Figure 2 Data Access Technologies
RDO, which preceded ADO, is a natural way to add client/server capability to DAO while improving its performance and scalability going straight to ODBC drivers. Basically, RDO is a lightweight wrapper that sits on top of the
ODBC API. It exposes much of the same object model as DAO but it lacks the Jet engine to perform data access. While this gives RDO greater speed, RDO doesn't benefit from some of the Jet-specific features and it can only access relational databases.
The idea behind ADO 2.0 is to create a higher common layer among different applications accessing the same data sources. If you compare Figures 1 and 2, you should see what I mean. Despite the differences in data structures and the physical location across the enterprise, the programming interface will be the same. To find out more about the differences between RDO and ADO, I suggest you read Bill Vaughn's excellent article, "Exploring ActiveX® Data Objects from an RDO Point of View," which you can find in the Technical Articles section of MSDN. The advent of ADO doesn't mean the end of RDO. In fact, Microsoft is committed to continue supporting RDO for the foreseeable future.
What's New with ADO 2.0?Up to and including version 1.5 of ADO, RDO and ADO were not completely equivalent from a functional point of view. Being equivalent just means that you can solve the same problems via both approaches; it doesn't mean that there are renamed or optimized functionally identical objects. Thus, migrating to ADO is definitely not a trivial task. On the other hand, learning ADO may be considered relatively easy once you have a consolidated grasp of the RDO or DAO technology.
The new features of ADO 2.0 include event handling, persistence of recordsets, hierarchical cursors and data shaping, distributed transactions, multidimensional data, Remote data services (RDS), and improved support for C++ and Java. I'll be looking at all of these features while delving deeply into some Visual Basic code. When using Visual J++, I'll demonstrate how the new Windows Foundation Classes support ADO. The most exciting aspect of ADO is the full support you can find for it in any of the development tools in Visual Studio 6.0.
A Quick Tour of ADO ObjectsThe ADO object model is composed of a relatively small number of objects. Unlike the RDO object model, each of the major ADO objects can be created separately. This means, for example, that you don't necessarily have to create a connection before creating a valid Recordset object.
Dim cn As New ADODB.Connection
Dim rs As New ADODB.Recordset
cn.Open "Biblio"
rs.Open "select * from titles where title like '%h'", cnThe ADO 2.0 objects are Connection, Command, Parameter, Recordset, Field, Error, and Property. The ADO object model also includes four collections that gather a set of related Error, Parameter, Property, and Field objects. Let's look at the main features of each object.
The Connection object renders the link a program holds with the data source it is accessing. The properties let you define the connection string, the timeout for both command execution and connection setup, the data provider, whether the cursor location should be on the client or the server side, and available
permissions on the data. Methods are for executing commands, opening and closing a connection, and managing transactions.
There are many places where you can specify which provider you want to use: via the Provider property, within the connection string, or even through the Open method. Choose the approach you like best, but make sure you don't specify multiple providers for the same connection. The default provider (in case you don't specify your own) is MSDASQL, the Microsoft OLE DB provider for ODBC.
The Command object defines a SQL statement, a stored procedure, or anything else you might want the provider to execute against data. Command's attributes are the active connection, the maximum time of allowed execution, and the collection of parameters. A parameter is a value you pass as an argument to the command. Among the attributes that feature a parameter are direction (input, output, or both), type, and of course value.
The Recordset object is perhaps the most typical ADO object, yet it's one of the more complex ones. It denotes the result of a command execution, and is mostly given by a collection of database records. A recordset is composed of information expressed in terms of rows and fields. It doesn't necessarily map to the records of a relational database. In fact, as I explained earlier, ADO is based on OLE DB and can be used to get data from virtually any source, including a nonrelational database. A recordset provides buffering capability, accepts changes to the data, and it can send these changes to the server in a batch mode. You can browse and sort a recordset's content, as well as enumerate and extract rows. You're also able to modify the data in any way through deletion, addition, and update operations. Recordsets have a strict relationship with connections, but this doesn't mean that you always need an open connection to get a recordset. You can also proceed this way:
Dim RS As New ADODB.Recordset
sql = "select * from authors"
RS.Open sql, "Pubs"The Connection object is still created, since it is actually the channel through which data and commands are transmitted. Other than the Recordset.ActiveConnection property, it lives invisibly and works behind the scenes.
The Field object is a column of homogeneous data. It exposes a programming interface to let you read and write the values of single cells, as well as basic characteristics such as type and size. All the Field objects for a given recordset form a Fields collection. As I'll show you later, the Fields collection hides a compelling feature that once again proves the flexibility of the Recordset object.
Last is the Property object. Every object has properties. An object rendered using ADO might be anything. There is no one right set of static properties that encompasses all the possible OLE DB providers. Thus, any ADO object possesses both static and dynamic properties. The first set of attributes, Name, Type, Value, and Attributes, are accessed via a syntax that looks like the following:
obj.PropertyName
The first three attributes are self-explanatory. Attributes is a type of numeric descriptor given by the bitwise combination of some predefined attributes relating to the provider's capability. (It's similar to component categories for COM servers.)
Dynamic properties vary quite a bit depending on the nature of the underlying provider. They are gathered into the Properties collection and can be queried by name.
obj.Properties("propName") ADO 2.0 includes some new functions (see Figure 3). A recordset can now be flattened out to a string using the GetString method. The syntax is:
Set Variant = recordset.GetString(
StringFormat,
NumRows,
ColumnDelimiter,
RowDelimiter,
NullExpr
)All the arguments are optional, as the following code snippet demonstrates:
Dim RS As ADODB.Recordset
Dim CONN As ADODB.Connection
Set CONN = CreateObject("ADODB.Connection")
CONN.Open "PUBS"
sql = "select * from authors"
Set RS = CONN.Execute(sql)
MsgBox RS.GetString(, 10)
RS.MoveFirstThis sample connects to the familiar SQL Server PUBS database, extracts all the authors' names to a recordset, and finally straightens its first 10 lines out to a string. Except in Visual Basic, the value returned by GetString is a Variant structure of type BSTR.
While calling into GetString, you can specify arguments to format data with a certain margin of freedom. For example, you can change the default row and column delimiters and choose to fetch only a given number of rows. At present, the StringFormat argument can only be adClipString, the unique member of the StringFormatEnum enumeration. adClipString evaluates to 2, which means that the successive arguments are valid and the library should take them into account. NumRows is the number of rows to be extracted starting from the current position. The default delimiters are for fields and the newline (CR) characters for rows. The NullExpr parameter provides an alternative string to display instead of the empty string when a NULL value is encountered through the recordset.
The GetString method is the ADO counterpart of GetClipString in RDO. Keep a couple of things in mind when using GetString. First, the function just returns flat data. No information about the structure or descriptive tags are exported or anything fancy like data stylesheets. As a result, GetString can be used for one-way data transfer, and there is no way this type of string can be read back. Second, GetString moves the record pointer forward, so move it back if you need to do further processing. Also, remember that by default the method exports the entire recordset. This means you don't have to worry that your current record is an invalid record.
There are other slight changes in the Recordset object with ADO 2.0. One is the ActiveCommand property that returns the Command object that originated the given recordset if any. The ADO type library defines ActiveCommand as a generic object, not a Command object, so the IntelliSense® module (included with all the Visual Studio 6.0 products) can't help you when it comes to writing some code that uses the property. If you add the following line
MsgBox RS.ActiveCommand.CommandTextto the previous fragment, you should get the text of the SQL statement that produced the recordset.
select * from authorsA bookmark is any value that uniquely identifies a row in a recordset. You normally use bookmarks when you need to store a reference to a certain record. As you probably guessed, bookmarks are duplicated if you clone a recordset through the standard Clone method. There's a subtlety with bookmarks that stems from the heterogeneous nature of the data that ADO renders. If a recordset's row was always a database record, then a bookmark would likely be the line number of the record. This definition would be absolutely consistent, and consequently you could compare bookmarks through a simple arithmetic operation.
However, a recordset can originate from anywhere, and the data it contains can address different objects. Moreover, the ADO programmer does not necessarily know about the inner structure of the data. He or she just utilizes it through an interface made up of rows and fields. Let's look at an example.
The Microsoft Active Directory Service Interfaces (ADSI) works as an OLE DB provider. Consequently, it exposes ADO heterogeneous objects from the Windows NT® or Novell directory services to any Lightweight Directory Access Protocol (LDAP)-compliant directory service. In addition, the whole ADSI architecture works as a silent consumer against any provider giving access to another directory. Aside from the fact that such objects implement a well-known and predefined programming interface, this means that ADSI itself is exposing objects that it doesn't know in detail to any ADO application.
A bookmark identifies one of these objects. Neither the ADO application nor a possible intermediate provider like ADSI would know about it. The bookmark must be defined and managed entirely and directly by the provider. ADO handles bookmarks through the OLE DB IRowsetLocate interface. If the provider supports bookmarks, it must implement this interface properly.
Dim vBookmark As Variant
RS.CursorLocation = adUseClient
vBookmark = RS.Bookmark
.
.
.
RS.Bookmark = vBookmarkThis code shows the correct way to use bookmarks in code. It is important that you use a cursor type that supports bookmarks. Bookmark is a read/write property, and you can assign it any value, including continuation character
RS.Bookmark = "Hello, world"
if you want a gentle message from the Visual Basic 6.0 runtime informing you that something went wrong with the arguments used by the application bookmarks. After all, the bookmark's actual value should always remain invisible to user applications.
If you need to compare bookmarks, you must use the CompareBookmark function exposed by the Recordset object in ADO 2.0. Both this function and the Bookmark property itself map straight to the functions of IRowsetLocate. In particular, the interface aligns methods like Compare, GetRowsAt, and GetRowsByBookmark, whose names are self-explanatory. "a href="ado20textfigs.htm">Figure 4 shows the world's simplest Visual Basic code using all the new features of the Recordset object.
Recordsets already had filtering capability prior to ADO 2.0, but version 2.0 adds searching and sorting features as well. Basically, the Sort property affects the way the recordset's tree is visited and the order of the traversed rows. The Filter property determines which rows are visible to the user. The mask used may be given by a sequence of boolean clauses or an array of bookmarks. You can use wildcards, too. Finally, the Find method retrieves a row based on a search indexed field. The Find method's syntax isFind (criteria, SkipRows, searchDirection, start)
where the search criteria is a string with the following layout:
<Field Name> <operator> <Value>
All the boolean operators are possible operators in addition to Like. Examples of criteria strings are
City = 'Redmond'and
Name Like 'Bill*'
There are also some strict syntax requirements. Date values must be enclosed in a couple of # characters, and single quotes must surround string literals.
The Find command line lets you skip a given number of rows before starting the search. The initial position (and the position from which you begin skipping) is the Start argument. searchDirection determines whether the search should be bottom-up or top-down. There are a couple of things you could do to speed up the search process. First, set the adUseClient cursor for the recordset. Second, set the Optimize dynamic property to True for the field you want
to index.
FieldName.Properties("Optimize") = TrueThis way, the content of the field is indexed and results in quicker access. Notice that Optimize is not a provider's property. It is defined and used only internally in ADO. This property gets added to the Properties collection just when the adUseClient cursor is set.
Recordset Persistence and BufferingA few months ago, a reader sent me email containing an odd question. He said, "I enjoy structures like recordsets, and I use them all the time. Can ADO recordsets be used to bufferize data without dealing with database connections or, worse yet, OLE DB providers?" I answered hastily: "No, I don't think you can. Recordsets need a connection, anyway."
Upon further thought, I felt that he had hit on an important point. ADO recordsets are a flexible and optimized data structure. They work well with OLE DB databases, but it's a shame that you can't use them wherever you need a powerful and comfortable data structure. But there's good news. ADO 2.0 provides you with a new feature that addresses this particular issue. The Fields collection comes with a brand new Append method that creates a recordset from scratch!
Dim RS As New ADODB.Recordset
RS.CursorLocation = adUseClient
RS.Fields.Append "Name", adBSTR
RS.Fields.Append "City", adBSTR
RS.Open
RS.AddNew
RS!Name = "DinoE"
RS!City = "Redmond"
Here's an ADO recordset that has no notion of database connection or OLE DB. The ADO recordset is by all means an independent object. What matters is that you choose a client cursor and append your new fields to the original recordset's Fields collection. The Append method requires two nonoptional arguments: field name and type. Use adBSTR if you want strings.
Given this, it's really straightforward to imagine applications that use it. For example, you can write code to read your old proprietary files and convert their data to recordsets.
This is just one way to create recordsets from disk files. ADO 2.0 adds persistence support to recordsets. In practice, you have a new method called Save with two parameters: the output file name and the data format.
Dim rs As New ADODB.Recordset
rs.adUseClient
rs.Save "c:\demo.rst", adPersistADTGAt present, only adPersistADTG (namely, 0) is allowed. Save can be invoked only on open recordsets. The data saved can also be affected by any filters you've applied. Note that the method doesn't close the file until the recordset is closed. In the interim, the file is accessible as read-only. This makes it easier for ADO applications to use the Save method to create parallel and persistent buffers. The Save method returns an error if the file already exists, so be ready to implement a workaround. Moreover, the method moves the current row position up to the first record. It saves everything that relates to the recordset to disk, including data and schema. However, it does not save connection or command information. This differentiates Save from GetString and enables applications to load a previously saved recordset. The method to use is
rs.Open "c:\demo.rst"Again, it's important that you use the client cursor.
Asynchronous Fetch and Event HandlingADO 2.0 also lets you execute commands to retrieve data in an asynchronous way. This occurs in the folds of the Open method's syntax.
recordset.Open Source, ActiveConnection, CursorType,
LockType, Options
As usual, the Source parameter can specify a valid SQL string (even a stored procedure name), a previously saved file name, or a Command object. The Options argument qualifies the command, and may affect the way the provider processes it. In particular, it can also assume the values adExecuteAsync or adFetchAsync. adExecuteAsync means that the Source command must execute asynchronously; namely, the method returns immediately and the provider fires an event when the operation completes. On the other hand, adFetchAsync only causes the first block of rows to be fetched synchronously (as usual). The size of this set depends upon the value stored in the recordset's CacheSize property. The remaining rows are loaded asynchronously.
When a piece of software works asynchronously, the platform should provide a way for the user to know when it is completed. There are different approaches to this, from the synchronization objects used in the Platform SDK to the callback functions employed in Microsoft Internet Explorer Remote Scripting. ADO chooses a third way, probably the most comfortable for RAD programmers: events.
There are two categories of events: those that relate to the Connection object (the ConnectionEvent interface) and those that pertain to the Recordset object (the RecordsetEvent interface) (see Figure 5). In many cases your code is notified before and after a certain operation occurs. In particular, the events raised after an operation occurs always come with an Error object that describes the result of the operation. Events fired before an operation let you control the parameters of the upcoming command. There are events that can reach your application too frequently. By properly setting an event's Status parameter, you can prevent further
notifications.
Set adStatus = adStatusUnwantedEventif you don't want any more of these notifications.
Handling ADO events can be easy, depending on the language you use. As you probably guessed, with Visual C++ you should get the connection point from the library and issue a call to its Advise method. This requires a lot of code creation on your part, but it provides a lot of flexibility. In fact, you can define a single handler to take care of events raised by multiple objects. On the other hand, all the methods defined in the outgoing event interface must be implemented, even with the simplest
return S_OK;In contrast to Visual C++, Visual Basic and Visual J++ save you some work. In particular, Visual Basic requires you to write event handlers for each object, since the handler procedure is name-based. Using the WithEvents keyword is the best way of getting events in Visual Basic. (WithEvents does more or less what you'd do if using Visual C++.)
Visual J++ follows a slightly different approach that comes from the Java language listener-based event model. Basically, you need to define a class implementing the outgoing interface and attach this class to the instance of the object that fires the events. This is what's needed at the lowest level. The WFC greatly simplifies this thanks to its built-in support for ADO 2.0. It's as easy as using Visual Basic, but still far simpler than Visual C++.
ConnectionEventHandler handler = new
ConnectionEventHandler(this,"onConnectComplete");The previous snippet defines a class implementing the onConnectComplete event from the ConnectionEvent interface. Then you need to add the following "listener" function to the list of the object's event handlers.
Connection conn = new Connection();
conn.addOnConnectComplete(handler); Therefore, you can easily have multiple handlers for the same event.
Hierarchical Cursors and Data ShapingIf you work with data, then it's very likely that you need to extract it from multiple tables. In most cases, you utilize JOIN commands to merge data from related tables, especially if you access relational databases. Any recordset that originates from a JOIN command always contains redundant information. For example, if you're interested in all the books written by an author, you can join the Authors and the Title Author tables (I'm referring to the Biblio and PUBS databases here). In the returned record-set, the information about the author is uselessly repeated for each row.
Eliminating redundant information becomes more important the more you work with complex and nested JOINs, where hierarchical cursors allow you to organize the recordsets with a tree-based logic. This process is also called data shaping, and it can be accomplished in two ways. You can use a shape language similar to SQL, or you can shape data through high-level Visual Studio 6.0 companion tools. I'll provide an example later on. For now let's have a look at the shape language.
In some respects, the shape language appears to be akin to the SQL language.
SHAPE {select au_ID, Author from authors}
APPEND ( {select ISBN from [title author]}
AS chapter RELATE au_id TO au_id)
Basically, the SHAPE command defines a recordset, and the APPEND clause adds a child recordset to it. In other words, a recordset can be used as any other data type for a field (see Figure 6). Parent and child recordsets are linked through a field-to-field relationship that needs a name as well.

Figure 6 APPEND Recordset
As a result of data shaping, the parent recordset appends a new column. Row after row, this new field points to the recordset defined inside the APPEND clause. The child recordset enumerates only the records whose au_id value matches the same field in the parent recordset. In the previous code snippet, given an author ID, there is a record-set with an additional field called chapter whose Value attribute points to the child recordset with all the requested fields from the Title Author table-in this case, only ISBN. Figure 7 illustrates some Visual Basic source code that navigates a hierarchical recordset. Notice how I need to access the chapter field by name. To get the actual child recordset, an additional step is needed: calling the Value attribute.
SHAPE commands can also be nested. This means that you can use another SHAPE command as the APPEND's internal command. Dealing with the SHAPE syntax can be as bothersome as writing complex SQL queries manually. Fortunately, Visual Studio 6.0 provides you with high-level tools that dramatically simplify the definition of a SHAPE query. I'll demonstrate this shortly.APPEND is not the only clause you can attach to a SHAPE command. A COMPUTE clause can be used instead. COMPUTE lets you execute a statistical function on the existing rows, grouping them by one or more fields. Predefined functions include SUM, AVG, MAX, and MIN. The final recordset is given by the results of such operations on the parent's rows. Moreover, this recordset also contains a reference field that points to the actual list of the original rows processed by COMPUTE. Sounds confusing? Let's look at an example.
Suppose you have a table with customer orders. One day, you want to know the total amount of the orders issued by each customer whose last name begins with A.
SHAPE {select custID, last name
from orders where last name
like 'A%''}
COMPUTE (SUM(amount)) AS
chapter
BY custID
Figure 8 illustrates the resulting recordset. You have the customer ID, the last name, and the amount of orders, plus a reference to the list of orders made by that customer-all in a single shot!
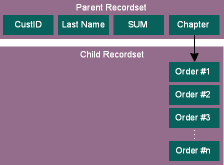
Figure 8 COMPUTE Recordset
To access data shaping functionality at the lowest level (namely, without the shield of a specialized tool), you need to specify that your provider is MSDataShape.
Dim cnn As New ADODB.Connection
cnn.Provider = "MSDataShape"
cnn.Open "Biblio"One of the most compelling new features of Visual Basic 6.0 is the Data Environment Designer (see Figure 9). It is a generic, design-time environment that lets you visually arrange three types of data tools: connections, commands, and recordsets. The Data Environment is also an object. You can include it in your own Visual Basic projects and refer to it in your code (see Figure 10).
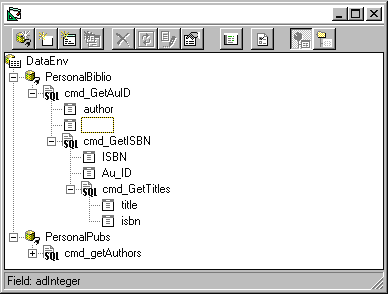
Figure 9 Data Environment Designer

Figure 10 Data Environment Object Model
To add a Data Environment instance to a project, just select Project|Add Data Environment. From then on, you can handle it as you would any other object. The only difference is that it is a projectwide object, not specifically targeted to a given form.
The Data Environment object model is composed of three collections: Commands, Connections, and Recordsets, plus some generic properties such as Object and Name. You can embed an object into your project group and use it to prepare any data connection or query you may need at runtime. The Data Environment blurs the distinction between the SQL query language and the SHAPE language. You simply define commands, and can do so graphically (see Figure 11). That's it. It's up to the underlying environment to do the right thing.

Figure 11 Creating Queries
There are wizards, insightful dialog boxes, and toolbar buttons to help you rapidly build any kind of recordset. In Figure 9, for example, you can see two different connections, to a Microsoft Access database (through the OLE Provider for ODBC) and a SQL Server table. The commands depending on such connections refer to a hierarchical recordset in the former case (PersonalBiblio connection), and to a conventional, flat recordset in the latter (PersonalPubs connection). From the designer's standpoint both recordsets have been created exactly the same way. The presence of nested command objects makes a hierarchical recordset here. You can add child commands via the context menu, as shown in Figure 12. Defining a new connection is as easy as following the instructions of the dialog in Figure 13.
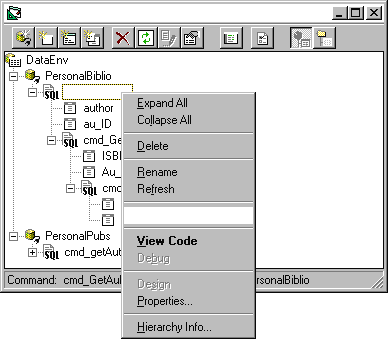
Figure 12 Adding a Child Command
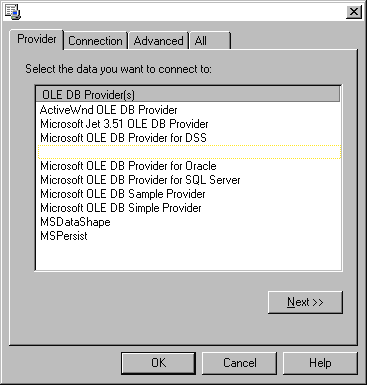
Figure 13 Creating a New Connection
You can use the objects created with the Data Environment Designer in a couple of ways. For example, you can set the DataSource property of any data-aware control, from the new ADODC control to the MSFlexGrid component. Second, you can exploit its object model and directly access any predefined connection, command, or recordset. You can also add some code that responds to both ADO events and DataEnvironment initialization and termination. To do this, just select the DataEnvironment object in the Project View window, and switch to the code view (see Figure 14).
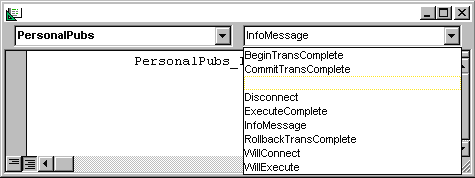
Figure 14 Handling ADO Events
In Visual Basic 6.0, the Data Environment Designer works together with the DataView window, an IDE tool that allows you to browse the internal structure of any data source as well as create new data links.
Programming ADO in Various EnvironmentsWhen it comes to programming ADO with Visual Basic 6.0, you can't ignore the new Hierarchical FlexGrid (HFlexGrid) control, shown in Figure 15. It's significantly better than the FlexGrid control that came with the previous version of Visual Basic. What's new is exactly what the name suggests: built-in support for hierarchical recordsets. Figure 16 shows a simple Visual Basic 6.0-based program that uses the HFlexGrid control and summarizes all the ADO features I covered so far. In this sample, I've defined a DataEnvironment object and used it to get a recordset from Biblio containing all the books of an author. The missing link between the Data Environment button and the HFlexGrid control can be found in this snippet:
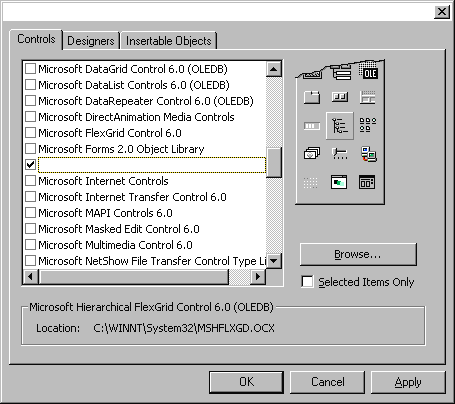
Figure 15 The Hierchical FlexGrid
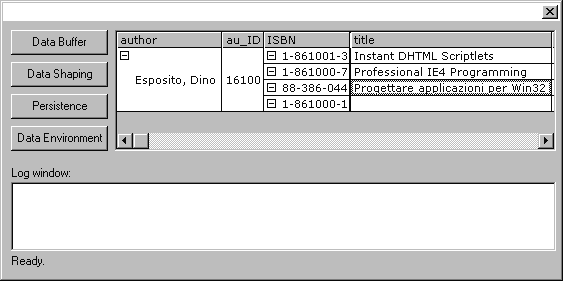
Figure 16 The Demo Program
Private Sub cmdDataEnv_Click()
Set hflex.DataSource =
DataEnv
Set hflex.DataMember =
DataEnv.RecordsetName
End Sub
This code automatically defines the DataEnvironment object that I defined earlier as the data source for the HFlexGrid control. HFlexGrid can also be successfully used to display flat recordsets and is functional with the previous version of Visual Basic.
The ADO functionality has also been made available through a new ActiveX control called MsAdoDC.ocx (see Figure 17). It looks like the old but still supported Data control. ADODC is supposed to replace the Data control you've grown to love. As you can guess, ADODC has features not found in the Data control. It's based on OLE DB and exposes the ADO 2.0 programming interface.

Figure 17 The ADODC Control
Visual InterDev is the main Web development tool in Visual Studio 6.0. It has two special features: the same Data Environment object found in Visual Basic 6.0 and the Recordset design-time control. The idea is simple; add the Data Environment object to the project, define your data connections, queries, and everything else you need. When you're finished, insert the Recordset design-time control in your Active Server Pages and extract the data objects (recordsets, commands, and connections) you need from the Data Environment collections: Recordsets, Commands, Connections.
<script language="JavaScript" runat="server">
function InitRS()
{
thisPage.createDE();
var rsTemp = DE.Recordsets('authors');
rsAuthors.setRecordSource(rsTemp);
rsAuthors.open();
·
·
·
}
The previous code snippet shows a JavaScript procedure that recovers a recordset and opens it for further use in the page.
Using ADO with C++, and in general using a high-level object model from C++, frequently poses the problem of converting Variant types returned by the methods to language native types. For this reason, ADO 2.0 exposes an additional interface called IADORecordBinding that lets you bind a specific field of a recordset to a C++ type. This is accomplished via the following steps:
BEGIN_ADO_BINDING
.
.
.
END_ADO_BINDINGNow, do what you need to do with the recordset. What's important is that from now on you can handle your own data member instead of the recordset's original data. Each time you move the current position, data will automatically be extracted and placed in the C++ class instance variables.
This same problem also arises in the Java language and has been solved in Visual J++ 6.0 by introducing accessor methods in the Field object.
With Visual J++ 6.0, data access in the Java language using ADO has been made simpler. WFC, on which the new Visual J++ is based, include a handful of specialized classes to cope with data management. As a result, writing a database application in the Java language is now easier than ever before.
Let's review how things are going with Visual J++ 1.1. You can make calls into, say, the ADO 1.5 object model, but you must do it through COM. Due to the Java/COM integration model, you need a set of interface classes between your Java-based program and the desired COM server. In this way, the Microsoft Java Virtual Machine can hook and redirect these interfaces to the actual server. You also need a tool like the Java Type Library Wizard (javatlb.exe or jcom.exe) to help you generate all the necessary wrapper classes. The final step is invoking the Visual J++ Database Wizard to complete the job.
With Visual J++ 6.0 and WFC, it's a completely different story. The class library now exposes three objects called Connection, Command, and Recordset. Their methods and properties have a one-to-one correspondence with the ADO object model I discussed earlier. The ADO events are also handled following the typical listener JDK model.
More importantly, the programmer's work is just writing Java code-no hassle with tools, wizards, and intermediate classes. Here's an example of how to establish a connection and open a recordset:
void openDataConnection() {
m_con = new Connection();
m_rs = new Recordset();
m_con.setConnectionString(
"Provider=MSDASQL.1;UID=sa;
PWD=;DATABASE=pubs;DSN=SQLS;SERVER=(local);" );
m_con.setCursorLocation(
AdoEnums.CursorLocation.CLIENT );
m_con.open();
m_rs.setActiveConnection( m_con );
m_rs.setSource( "select * from authors" );
m_rs.setCursorType( AdoEnums.CursorType.STATIC );
m_rs.setCursorLocation(
AdoEnums.CursorLocation.CLIENT );
m_rs.setLockType( AdoEnums.LockType.OPTIMISTIC );
m_rs.open();
}Visual J++ also provides you with four data-oriented components: DataSource, DataBinder, DataNavigator, and DataGrid. The DataSource renders a database connection, while the DataBinder works more or less as a binder for a group of UI controls. These components get updated automatically as soon as the current row position changes. The DataBinder is linked to a certain DataSource. The DataNavigator resembles the Visual Basic Data control (even in the user interface), while DataGrid is a typical grid based on a data source.
This is a summary of what you can get from the Java language-based WFC classes when it comes to data access via ADO 2.0. Visual J++ also uses wizards to make the development of a skeleton database application with Java even easier.
The Web Side of ADOLast year when Internet Explorer 4.0 shipped, very few programmers grasped the importance of the data binding feature. This feature seemed cool, but it was dependent on Internet Explorer 4.0 and lacked proper examples and applications. Data binding is the Web-based technology that lets you access a remote data source without leaving the current page. In other words, data binding is the Web counterpart of data-aware controls. If you use it, you can have data-bound HTML tags. For example, you can link a <TABLE> to a certain source and have rows and columns added asynchronously as soon as records actually come in. Once you establish the binding, there's nothing else you (and your users) have to do!
Data binding is implemented through a module, actually an ActiveX control, called Data Source Object (DSO) that roughly acts as a proxy between the database and Web pages. Microsoft provided a couple of DSOs with Internet Explorer 4.0: the Tabular Data Control (TDC) and the Advanced Data Control (ADC). The TDC can handle only text-based data, while the ADC control is able to connect to any ODBC-compliant source. For a primer see "Data Binding in Dynamic HTML," by Rich Rollmann (MIND, July 1997). Today, the ADC has evolved into RDS-the Web side of the UDA and the portion of ADO specifically thought to work across the Internet.
One piece of RDS is an ActiveX control called RDS.DataControl that you put into HTML pages. By using the data binding technology, you can efficiently manage recordsets on the client side. You can navigate, sort, and update the rows without any further contact with the server. You'll only get back to the server when it's time to flush the pending changes. RDS caches the data on the client side and dramatically reduces the need for round-trips. The following lines of code show how to use RDS in an HTML page to fill a table:
<object id="rds"
classid="clsid:BD96C556-65A3-11D0-983A-00C04FC29E33">
</object>
.
.
.
<table datasrc="#rds">
<thead><tr>
<th>First Column</th>
<th>Second Column</th>
</tr></thead>
<td><span datafld="FieldName1"></span></td>
<td><span datafld="FieldName2"></span></td>
</table>RDS is not all on the client side. When you call the methods of the RDS ActiveX control through VBScript or JScript®, you actually end up calling into the RDS Data Factory Server (RDSServer.DataFactory object), which lies in the Web server space. For this reason, data binding "binds" you to have either a compatible browser or an RDS-enabled server.
The RDS Data Factory gets requests and fulfills them by accessing the underlying data source through the ADO interface (see Figure 18). It only does queries and updates.
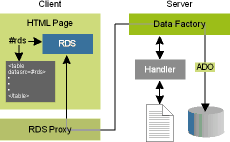
Figure 18 The RDS Architecture
Today, RDS is definitely a part of ADO and a basic component in the overall UDA architecture. ADO 2.0 offers important enhancements on the RDS side. The RDSServer.DataFactory object has now been improved to support a layer of custom code specifically aimed to add validation capability and access rights control. This new module, called Handler, can be employed to modify both command strings and connection parameters upon execution time. A Handler may be driven by an initialization file and is invoked by adding a string like
Handler=progID,arg1,arg2,
, argn
in the recordset's connection string. ProgID is needed to identify the Handler, which is a COM server implementing the IDataFactoryHandler interface.
Microsoft provides a default handler called MSDFMAP.Handler, based on msdfmap.ini. You can write your own handler if you want. Let's take a look at a possible use of such a handler. The following is an excerpt from msdfmap.ini that can be found in your Windows directory:
[connect AuthorDatabase]
Access=ReadOnly
Connect="DSN=Mylibraryinfo;UID=MyUserID;PWD=MyPassword"
[userlist AuthorDatabase]
Administrator=ReadWrite
[sql AuthorById]
Sql="SELECT * FROM Authors WHERE au_id = ?"
This means that any connection to AuthorDatabase must always have read-only rights and always happen through the specified string. The user called Administrator has read/write access, and this setting partially overrides the previous one. All the other users still have read-only rights. The sql section refers to a procedure called AuthorById. Each time it gets called it must be replaced with the specified statement, and the ? character must be replaced by the first procedure's argument.
rds.Handler = "MSDFMAP.Handler"
rds.Server = "
"
rds.Connect = "Data Source=AuthorDatabase"
rds.SQL = "AuthorById(16100)"
This code shows how you can invoke RDS via the Handler with VBScript. The RDS control can also be seamlessly employed in desktop applications. It's primarily aimed at the Web, though. RDS and Dynamic HTML, for example, form a really interesting pair. In particular, you can write a self-contained HTML component (scriptlet) to present a recordset within a <TABLE> element. An example of this is shown in my Cutting Edge column in the October 1998 issue of MIND.
Multidimensional ADOADO 2.0 also extends the principles of OLE DB and Universal Data Access to the world of On-Line Analytical Processing (OLAP). It does this by introducing MultiDimensional ADO (ADO MD), a set of COM objects written to make the multidimensional data management easier.
ADO MD goes beyond the ADO object model and includes objects specific to multidimensional data, such as the cube. Under the hood of ADO MD works an OLE DB provider compatible with the OLE DB for OLAP specification. ADO and ADO MD are related but different. Both work with recordsets, even if they are tabular, bidimensional arrays for ADO, or n-dimensional objects for ADO MD.
The ADO MD counterpart of a recordset is called a cellset. It gets extracted from a cube of data created starting from relational tables. You can use both ADO and ADO MD in the same project, provided that you really need it. Look at the MSDN documentation for some examples.
SummaryThis article did not even attempt to provide an exhaustive description of all the methods and properties of all the ADO objects. There's documentation and good books for that. My primary goal here was to introduce you to the new features of ADO in enterprise and distributed real-world systems. ADO 2.0 goes far beyond RDO and DAO. By adopting ADO, you get data transmission over the Web for free via RDS, and more importantly you have an open architecture easily extensible with new and custom data sources.
If you're concerned about ADO development tools, there's nothing to worry about. ADO 2.0 is well-integrated into Visual Studio 6.0. All the components of Visual Studio 6.0 provide advanced UI tools to make data integration as smooth as possible. With Visual Studio 6.0, ADO really installed the DNA of the Windows-based systems.

For related information see: What's New in ADO 2.0 at http://msdn.microsoft.com/library/techart/msdn_newado20.htm. Also check http://msdn.microsoft.com for daily updates on developer programs, resources, and events.
From the February 1999 issue of Microsoft Systems Journal.