March 1999
![]()

Code for this article: Mar99hood.exe (31KB)
| Matt Pietrek does advanced research for the NuMega Labs of Compuware Corporation, and is the author of several books. His Web site at http://www.tiac.net/users/mpietrek has a FAQ page and information on previous columns and articles. |
|
In this month's MSJ article, "Improve Your Debugging
by Generating Symbols from COM Type Libraries," I
wrote about the CoClassSyms program that uses a COM component's type library to create debug symbols. The output from the article's code is a .MAP file. By itself, a .MAP file containing symbol information is somewhat interesting, but ultimately not terribly useful. You're really cooking with gas when you get a debugger to load and use the symbols. In this column, I'll describe a DLL that CoClassSyms hooks up with to generate a .DBG file.
The generated .DBG file is the bare minimum required to get symbol information that is usable by a Microsoft® debugger. Nonetheless, creating a .DBG file requires a deep understanding of symbol tables and provides a good opportunity to delve under the hood of
.DBG files. Deciding to store the debug symbol output from CoClassSyms in a .DBG file is a no-brainer. After all, Microsoft supplies .DBG files for just about every Windows NT® component. I'm simply following Microsoft's lead. The primary advantage to .DBG files is that they allow debug information to reside in a file separate from the executable. The alternative is to append the symbol information to the executable, something I am loathe to do. If something's working, don't mess with it! Both WinDbg and the Visual Studio® 6.0 debugger can use .DBG files, but I didn't have much luck with Visual Studio 5.0. The Scoop on .DBG Files
Contrary to popular belief, .DBG files aren't a distinct type of debug information à la COFF or CodeView®. Rather, a .DBG file is merely a container for various types of debug information. Here's a snippet from WINNT.H that lists the types of debug information commonly found in .DBG files: |
#define IMAGE_DEBUG_TYPE_COFF 1
#define IMAGE_DEBUG_TYPE_CodeView 2
#define IMAGE_DEBUG_TYPE_FPO 3
#define IMAGE_DEBUG_TYPE_MISC 4
#define IMAGE_DEBUG_TYPE_EXCEPTION 5
#define IMAGE_DEBUG_TYPE_FIXUP 6
#define IMAGE_DEBUG_TYPE_OMAP_TO_SRC 7
#define IMAGE_DEBUG_TYPE_OMAP_FROM_SRC 8
Most .DBG files contain several different types of debug information. You can see this in Figure 1, which is an excerpt from running DUMPBIN /HEADERS ADVAPI32.DBG. The misc and fpo information is outside the scope of this discussion. The interesting thing here is that the .DBG file contains both COFF and CodeView (labeled "cv") information. More on this later.
Moving to the bits and bytes level, what does a .DBG file look like? As it turns out, WINNT.H is unusually verbose on the subject, having this to say:
"The beginning of the .DBG file contains the following structure which captures certain information from the image file. This allows a debug to proceed even if the original image file is not accessible. This header is followed by zero or more IMAGE_SECTION_HEADER structures, followed by zero or more IMAGE_DEBUG_DIRECTORY structures. The latter structures and those in the image file contain file offsets relative to the beginning of the .DBG file."
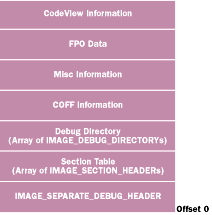
To be more succinct, a .DBG file begins with a standard header called an IMAGE_SEPARATE_DEBUG_HEADER. Following this is a copy of the executable's section table. After that comes an array of IMAGE_DEBUG_DIRECTORY structures, each structure describing one type of debug information in the file. At the end of the .DBG file is the raw debug information. Figure 2 shows the structure of the .DBG file for the aforementioned ADVAPI32.DBG.
 |
|
Figure 2 ADVAPI32.DBG File Structure |
The IMAGE_SEPARATE_DEBUG_HEADER is a condensed version of the fields found in an executable file. Figure 3 shows the fields of an IMAGE_SEPARATE_
DEBUG_HEADER and how they map to the executable's fields. The first field (Signature) must contain the value 0x4944 to indicate that the file is a .DBG file. If you translate 0x4944 into ASCII, you will end up with DI (Debug Information).
Following the IMAGE_SEPARATE_DEBUG_HEADER is an exact copy of the executable's section table. This is just an array of IMAGE_SECTION_HEADER structures, with one structure for each code and data section in the executable. Between the information in the .DBG file's section table and the IMAGE_SEPARATE_DEBUG_HEADER, most debuggers have everything they require without needing to locate and read the executable file.
Following the .DBG file header and section table is the debug directory. This consists of an array of IMAGE_
DEBUG_DIRECTORY structures, which is the same layout used to describe debug information in
executable files. Some of the fields are meaningful, while some don't seem to be used. Figure 4 shows my interpretation of the IMAGE_DEBUG_ DIRECTORY fields.
This ends my whirlwind tour of .DBG files. Generating a .DBG file shouldn't be terribly hard, at least as far as creating the .DBG file infrastructure goes. Creating the IMAGE_SEPARATE_
DEBUG_HEADER and the section table is really just a matter of copying data out of the corresponding executable. I'll be generating only one type of debug information, so I'll need to create and write only a single IMAGE_DEBUG_DIRECTORY.
Things start to get messy when you create the debug information representing symbol names and their associated addresses. Up to this point, I've deferred deciding what debug format to generate. However, it can't be avoided any longer, so let's look at the issues and decide.
Which Debug Format?
Recall that ADVAPI32.DBG had both COFF and CodeView symbols. Why two overlapping forms of debug information? Some Microsoft tools such as the Working Set Tuner (WST) require COFF symbols, while other tools require CodeView symbols. In the prehistory of Win32, COFF was the only game in town, since the early tools were written by the Windows NT team. Eventually, the Microsoft language folks turned their focus away from 16-bit products and the CodeView format was extended for 32-bit programming.
Of the three possible debug formats (COFF, CodeView, and PDB), the PDB format can be eliminated immediately. There's no documented interface to read .PDB files directly, much less write one. For the very basic symbol table I want to generate from CoClassSyms.EXE, it would be easiest to generate COFF symbols since the format is relatively simple as compared to the CodeView format.
As I began writing CoClassSyms, my intention was to generate COFF symbols. However, I quickly learned that the Microsoft debuggers (WinDbg and the Visual Studio debugger) require CodeView format symbols. I briefly flirted with the idea of writing COFF symbols and then converting them to CodeView symbols. The Platform SDK contains the source code for a DLL called SYMCVT.DLL, which reads COFF symbols and writes an equivalent CodeView symbol table. (If you're curious, it's in the \Examples\Sdktools\
Image\Symcvt directory.) However, I didn't want to rely on SYMCVT.DLL being present on the user's system. Facing this self-imposed restriction, my only option was to create CodeView symbols.
If you just want to read symbols and don't care what format they're in, consider using IMAGEHLP.DLL. It can read COFF, CodeView, and .PDB format information. The IMAGEHLP APIs such as SymGetSymFromAddr provide a common, abstracted layer over the different symbol table formats.
For those of you seeking enlightenment about the .PDB format, you won't find it here. Microsoft doesn't document the format, and it has changed over time. The IMAGEHLP APIs are the only supported means of accessing .PDB information.
However, it is interesting to note that .PDB information appears in the IMAGE_DEBUG_ DIRECTORY as CodeView information, but with the NB10 signature. Unlike regular CodeView symbols, an NB10 CodeView symbol table in an executable is simply a string containing a path to the .PDB file. Conceptually, this is similar to .LNK shortcuts.
The CodeView Way
As a rich symbol table format, CodeView symbols convey quite a bit of information. Besides associating symbol names with addresses, CodeView symbols also convey details such as user-defined types and source line to address mappings. When pushed to its full capabilities, the CodeView information produced by a compiler and linker is complex (to put it mildly).
Part of the format's complexity is because CodeView information was originally supposed to be as small as possible. (Remember the carefree days of the 640KB MS-DOS® address space?) Cramming information into every spare bit means more complexity. CodeView information is also cumbersome because the format has evolved over many iterations of compilers and linkers. Various tables and records are no longer generated by today's tools, yet they remain part of the specification and need to be dealt with properly when encountered.
Under the Specifications\Technologies and Languages node of the MSDN™ documentation, you'll find relatively up-to-date information on the CodeView format published with recent editions of Visual C++®. However, it's so full of details that it's hard to separate the basics from the esoteric stuff. I'll go over just the basic pieces needed to generate a minimal CodeView symbol table.
A CodeView symbol table always begins with a DWORD-sized signature, which is interpreted as ASCII text. These days, you'll usually see signatures of either NB09 or NB11. (An NB10 signature indicates that the symbol table is just a path to a .PDB file containing the actual symbols. I'm not concerned with .PDB files or the NB10 signature here.) The location of this DWORD signature in the file is known as the lfaBase. All offsets in the CodeView information are relative to the lfaBase value. This makes it easy to move the CodeView information to another file entirely (such as a .DBG file), without needing to recalculate all the file offsets stored throughout the CodeView information.
Following the initial DWORD NBxx signature is another DWORD containing the offset to the subsection directory. The subsection directory is a table of contents for all the subsections found in the symbol table. A subsection contains data such as source line information and public symbols. The subsection directory is an array of OMFDirEntry structures, one per subsection.
The OMFDirEntry structure is defined in CVEXEFMT.H (along with most of the other structures I'll mention from here on). You won't find CVEXEFMT.H in any of the standard C++ compiler include directories. Rather, on the most recent Platform SDK I found CVEXEFMT.H in the \Samples\Sdktools\Image\Include directory. What's more interesting is that the file is dated 9/7/1994. There are several other .H files in that directory that relate to CodeView symbols. Be forewarned that these .H files are old enough that they're missing many things described in the MSDN documentation.
Returning to CodeView subsections, a variety of subsection types are defined. Subsections define information such as compilation units (sstModule), source line to address mappings (sstSrcModule), public symbols (sstGlobalSym and sstGlobalPub), and user-defined types (sstGlobalTypes). The subsections have a variety of formats, some of which can be pretty contorted. Luckily, for the purpose of CoClassSyms, you need just a few of the relatively simple sections. Even within the few subsections my code writes, it takes some shortcuts to keep things as simple as possible.
When I first set out to write a symbol table, my thought was to create just one CodeView subsection, an sstGlobalPub. This subsection would contain nothing more than symbol names and their addresses. In other words, the same thing you'd find in a .MAP file, albeit encoded in the proper CodeView binary format. As it turned out, it was necessary to create two other supporting subsections. However, the sstGlobalPub subsection is at the heart of the bare-bones symbol table. The key point is that I escaped the need to create complex subsections such as the types and source line information.
In the sstGlobalPub subsection, the code writes a series of simple records representing the symbol to address mappings created by CoClassSyms.EXE. For each symbol name and address pair, the code emits an S_PUB32 record. The simple sstGlobalPub subsection created is just the header (an OMFSymHash structure), followed by a bunch of S_PUB32 records.
The S_PUB32 record is interpreted as a PUBSYM32 struct defined in CVINFO.H. (CVINFO.H is buried in the same sample directory as CVEXEFMT.H). Here's the layout of a PUBSYM32 record:
struct PUBSYM32 {
unsigned short reclen; // Record length
unsigned short rectyp // S_PUB32
unsigned long off; // Symbol offset
unsigned short seg; // Symbol segment (section)
unsigned short typind; // Type index
unsigned char name[1];// Length-prefixed name
};
Next in the PUBSYM32 record is the type index. Describing the CodeView type system could easily fill up an article in its own right. I'll sidestep that whole mess, since the
code cheats and uses 0 as the type index. This means that the type of the symbol isn't known, which just happens to
be true. The final field of the PUBSYM32 is a length-prefixed string (a byte length, followed by a non-null-terminated string).
Besides the sstGlobalPub, the two additional sections necessary for a minimal CodeView symbol table are sstModule and sstSegMap. An sstModule normally corresponds to a single .OBJ file, and usually there are multiple sstModule subsections in a CodeView symbol table. However, for the purpose of synthesizing a .DBG file, I can get away with a single sstModule that represents the entire executable file.
The sstSegMap subsection is an anachronism in a
Win32 symbol table. In Win32 there's really no need to translate between symbol table segment values and executable module segment values—they're one and the same. Nonetheless, the Microsoft debuggers insist on seeing an sstSegMap. My code creates a minimalist sstSegMap, using 0 and -1 for most of the fields. After all, they'll be ignored by the debugger.
The CoClassSymsDbgFile Code
Now that I've described some of the top-level characteristics of a minimal CodeView symbol table that conveys symbol names and their addresses, let's take a look at the code for the implementation DLL. This DLL, CoClassSymsDbgFile.DLL, creates a .DBG file containing the minimal CodeView symbols. By placing this DLL in the same directory as CoClassSyms.EXE, you'll get a .DBG file rather than a .MAP file when running CoClassSyms against an appropriate executable file.
The source code for CoClassSymsDbgFile.DLL can be found in Figure 5. The public interface to CoClassSymsDbgFile.DLL is the three exported CoClassSymsCallouts APIs described in ";Improve Your Debugging by Generating Symbols from COM Type Libraries." The first API, CoClassSymsBeginSymbolCallouts, begins by mapping the specified executable into memory so that various fields and structures can be read from it. Next, the API synthesizes the name of the .DBG file and opens it for writing. Finally, the code invokes the CalculateCVInfoOffsets function.
CalculateCVInfoOffsets is a small but essential function. The size and location of every portion of the CodeView symbols and encompassing .DBG file can be calculated at this early point, with one exception: the missing piece is the size of the sstGlobalPub section, which can't be calculated in advance. Another API will later be called an indeterminate number of times, once for each symbol. Rather than caching all the symbol names and addresses for writing later, I chose instead to write out each symbol in S_PUB32 format incrementally.
To write each symbol as it's encountered requires the DLL to know in advance where the sstGlobalPub subsection will be. The CalculateCVInfoOffsets function calculates the total size of each item that precedes the sstGlobalPub in the file. This includes the IMAGE_SEPARATE_DEBUG_HEADER, the executable section table, the debug directory, the CodeView symbol table header, and an sstModule subsection. All of these items will
be written later, after the sstGlobalPub subsection has been completed.
The second API exported by CoClassSymsDbgFile.DLL is CoClassSymsAddSymbol. This API delegates the workload to AddPublicSymbol32. AddPublicSymbol32 initializes a PUBSYM32 record with the passed information, seeks to the appropriate file offset, and writes out the record. Back in CoClassSymsAddSymbol, the code keeps a running tally of how big the sstGlobalPub section
has become, storing the value in the g_cbPublicSymbols global variable.
The final API exported by CoClassSymsDbgFile.DLL is CoClassSymsSymbolsFinished. This high-level routine calls down to several more specialized functions to handle the grungy details of finishing off the CodeView symbol table and .DBG file constructs. The first order of business is to write the CodeView header, the subsection directory, and the remaining subsections (sstModule and sstSegMap). All this is accomplished inside the aptly named WriteRemainingCVInfo function.
 |
|
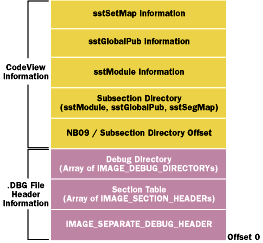
Figure 6 CoClassSyms.DBG File |
After completing the CodeView symbol table, CoClassSymsSymbolsFinished turns its attention to writing the .DBG file structures that precede the symbol table. To review, these are the .DBG file header, the section table, and the debug directory. There are suitably named functions for writing out each element. Finally, the API closes the .DBG file and unmaps the executable file from memory. If all went well, there should be a healthy, happy baby .DBG file ready to be placed alongside its parent executable and usable by a debugger. Figure 6 shows the layout of a CoClassSymsDbgFile-generated .DBG file.
Some Final Notes
To use CoClassSymsDbgFile.DLL successfully, you'll need to do a few things. First, make sure that CoClassSymsDbgFile.DLL is in the same directory as CoClassSyms.EXE, or in the path. After running CoClassSyms on the target executable, you should have a corresponding .DBG file in the current directory. You can poke at the .DBG file by running DUMPBIN /HEADERS on it. At the end of DUMPBIN's output should be a reference to cv information of format NB09. If you don't get a .DBG file, first try removing CoClassSymsDbgFile.DLL temporarily and see if CoClassSyms creates a reasonable-looking .MAP file.
Once you have a .DBG file, it's important to copy it to the same directory as the target executable. If you follow these steps, the Visual C++ 6.0 debugger should load the .DBG file automatically when the associated executable loads. When using WinDBG, you may have to tell WinDBG explicitly to load the symbol table.
This column definitely isn't the definitive description of CodeView symbols or .DBG files. However, I've touched upon many of the key concepts necessary to work with this type of symbolic debug information. You may never have the need to write your own symbol tables, but many readers have asked about reading symbols in their own code. The code here is rather simplistic, but provides a starting point for more detailed exploration.
Have a suggestion for Under the Hood? Send it to Matt at mpietrek@tiac.com or http://www.tiac.com/users/mpietrek.
|
From the March 1999 issue of Microsoft Systems Journal
|