June 1999
![]()

| Matt Pietrek does advanced research for the NuMega Labs of Compuware Corporation, and is the author of several books. His Web site at http://www.tiac.net/users/mpietrek has a FAQ page and information on previous columns and articles. |
|
As the Windows® programming paradigm shifts from
standalone applications toward client-server, n-
tier, and distributed computing, programmers are pushed into learning technologies completely new to them. For instance, a year ago technologies such as ActiveX® Data Objects (ADO) and Microsoft® Transaction Server (MTS) didn't have much relevance to me. Being a system-level hacker, I figured I could leave those things to the app people. In hindsight, I realize that I've been ignoring these technologies at my own risk since they're becoming an integral part of the operating system.
When I first jumped into n-tier development technology, I noticed that almost all applications access a database of one sort or another. In particular, these programs communicate with what I call enterprise-level databases. These databases aren't a typical copy of Microsoft Access running on your local machine. Rather, enterprise databases such as SQL Server™ 7.0, Oracle 8i, and IBM DB/2 are practically operating systems in their own right. In a production environment, they run on dedicated server machines with tons of memory and superfast disk and network I/O. Besides huge enterprise databases, the other pervasive element of n-tier systems is that the clients connecting to these databases use quite a collection of APIs and COM interfaces to communicate with the database. As a newcomer to database programming, I was completely befuddled by ODBC, DAO, RDO, OLE DB, ADO, JDBC, and so on. Nowhere could I find a good, comprehensive overview of all the client-side database technologies and how they played together. In addition, the documentation for these technologies often assumes a deep knowledge of databases—something I certainly didn't have. Making matters even worse, different programming languages seem to prefer different database technologies. Visual Basic® 5.0 was oriented towards Remote Data Objects (RDO), while Visual Basic 6.0 pushes ADO. I can't use ODBC from Visual Basic, but I can use something called ODBCDirect, which looks suspiciously like Data Access Objects (DAO). Meanwhile, Active Server Pages (ASP) embrace ADO. Using MFC, I found classes for using DAO and ODBC, but nothing for RDO. I haven't even touched on languages and technologies from non-Microsoft vendors such as Oracle's Developer 2000 and Sybase's PowerBuilder. Eventually, I prowled around under the hood to the point where I'm reasonably familiar with how these client-side database technologies play together and what lies underneath them. This month's column is a semi-technical overview of the various technologies I mentioned that make up client-side database code. I refer to all of these technologies as the database access layers, since you usually end up using multiple technologies (even if you're not explicitly aware of it). If you're familiar with Windows-based programming and concepts, but new to databases, then this column is for you. What you'll find here is my own personal take on how things fit together. You won't find introductions to programming in ADO, OLE DB, and so on here; there's enough of those available elsewhere—even an article in this month's issue. Just because I use the term "client-side" doesn't mean that what I'm describing doesn't apply to middle-tier development. In the Windows DNA architecture, database access is usually done from ASP scripts, or more robustly, from within components running in the MTS environment. In this scenario, the client-side database layers are still there. The only difference is that the client program is now the Web server (Microsoft Internet Information Server) or MTS components running in the context of MTX.EXE.
Overview of Database Server Concepts Before describing the client access layers, let's first look at a few things from the database server perspective. For starters, what exactly is a database server? (Here, I mean products such as Microsoft SQL Server or Oracle 8i rather than the machines they run on.) Within the Windows NT® environment, a database server is just a process. The server process can be started, stopped, and restarted. Microsoft SQL Server typically runs as a service, but it can also be started from the command line. Database servers are usually limited to a single instance of the process running on a given machine. For instance, Microsoft SQL Server won't allow a second instance to run if SQLSERVR.EXE is already executing. The database server process listens for and responds to requests from clients. Servers are highly multithreaded, and are optimized to handle hundreds or thousands of requests concurrently. They have elaborate mechanisms to ensure the consistency of data while keeping locked data to a minimum. There are a number of low-level options that can be tweaked to optimize the server process for a particular scenario. Conceptually, an enterprise database is similar to a Web server. A Web server listens for a connection from a client (that is, a browser). When a connection is made, the browser client sends a request (typically a URL for an HTML page), and the server returns the designated page. A database server listens for connections from a client (perhaps VBScript in an ASP page). After establishing the connection, the client sends some sort of request using the SQL language. The database server takes the request, parses it, formulates the appropriate response, and sends it to the client. What sort of information flows between a client and the database server? The most well-known item is a query. In the SQL language, queries are formulated using the SELECT keyword. For example, |
|
| asks the database server to scan through all the records in the MSJ_Authors table, and return just the name and preferred_language fields in each record. The information that the server returns is known by a variety of names, such as results, recordsets, and rowsets. The important thing is that the format of the results coming back from the server depends entirely on the query. For example, using the previous query, the resultset would look like this: |
|
| When the server sends back results, it has to first describe to the client how to interpret the data that follows. Much of the complexity in the client-side access layer comes from managing and exposing results returned by a server in a manner easy for your code to work with.
Besides queries, other requests that flow between the client and database server are requests to insert, delete, or modify the data in a table. If successful, the server returns something along the lines of "Roger. Ten-four, good buddy." However, if you request something incorrect (for example, to modify a record that doesn't exist), the server responds with an error code or message. The job of percolating the error information up to your code again falls to the client access layers. Something I've learned the hard way is that server warnings and errors can sometimes get lost on the way back to your code. Stored procedure invocations are also passed between the client and database server. Calling a stored procedure is conceptually similar to using a remote procedure call (RPC). The client sends the name of the procedure, along with any in and out parameters. The server then executes the stored procedure code (usually written in some form of SQL), and returns the results. A stored procedure might return simple out parameter values, or it could return a resultset similar to what a query would return. Implicit in any communication between the client and server is the notion of a connection. Opening a database connection is conceptually similar to opening a TCP/IP socket. In both cases the client gets a handle, which is used for writing to the server and reading back the results. A client application can have multiple connections to the same server and can connect to multiple servers. Likewise, the database server is designed to handle many connections at the same time, up to some limit. A database connection handle hides the underlying transport technology used to communicate between the client and server processes. These processes are probably on different machines. Common transport layers include named pipes, TCP/IP, and IPX/SPX. The default transport used for SQL Server clients on Windows NT is named pipes. I'll have more to say about the transport layer used by clients later.
The Evolution of Client Database Layers In the beginning, communicating with a database server meant using an API specific to the database. Even today, most databases support some native API. For example, Oracle's native API is known as OCI (Oracle Call Interface). The SQL Server API is known as DBLIB. Both of these native APIs are implemented as DLLs, and the vendors supply .H and .LIB files for them. Using the native API allows you to employ specialized features specific to the database—and there's relatively little overhead in the client-server communication. However, there are problems with using a native API that make application coders shy away from them. First, native APIs aren't portable to other databases, so you effectively tie yourself to one vendor. Second, if you upgrade to a newer version of the server, you run the risk of the native API changing. Finally, the native APIs aren't easily usable by languages other than C or C++. As you can no doubt imagine, the profusion of different native APIs lent itself to some sort of standardization effort. As the book Inside ODBC, by Kyle Geiger (Microsoft Press), describes, the standardization effort was quite a long road. Today we know the fruits of this effort as ODBC. While ODBC was originally developed by a consortium of companies, including Microsoft, its specification is now pervasive across all types of machines and databases. Just as SQL is the universal language for talking to the database, ODBC is a de facto standard for transmitting SQL to the database server and receiving the responses. The ODBC architecture has two main components. The first piece is the driver manager. Under Win32®, the driver manager is ODBC32.DLL. It exports all of the traditional ODBC APIs, such as SQLAllocHandle. The driver manager has no knowledge of specific databases. Applications that use ODBC usually implicitly link against the functions in ODBC32.DLL. The close association between ODBC and the SQL language is evidenced in the fact that all ODBC API names are prefixed by "SQL," and are prototyped in SQL.H. The second component to ODBC is the driver. Each database server has its own specific driver, and drivers are usually updated when the database is upgraded to a newer version. The ODBC manager DLL is an abstraction layer between the application and the driver. It allows a program to keep working even if the underlying drivers change. The indirection provided by the ODBC manager allows a client application to communicate with multiple different database servers simultaneously. Each ODBC connection is implicitly associated with a specific driver. ODBC drivers export most of the same functions as the ODBC manager. The ODBC manager connects to the drivers via LoadLibrary and GetProcAddress. In most cases, the ODBC manager's implementation of an API is simply to forward the call to the matching API in the applicable driver. The driver takes care of encoding, decoding, and communicating the data between the client process and the database server. I have heard of cases where applications have bypassed the ODBC manager DLL and linked directly to the driver DLL (after all, they're the same APIs). In experimenting with ODBC and ODBC drivers, I've learned a few surprising things. For instance, the ODBC driver for SQL Server (SQLSRV32.DLL) can cache the results returned by the server. When a query that returns multiple rows finishes, the driver doesn't just read the first row of data from the server. Instead, the driver reads up to the first 4KB of result data from the server. When the application calls SQLFetch in a loop to read each row in succession, the driver gets the data out of its cache. Only when the data in the cache is exhausted will the driver hit the server to read the next block of result data. The upshot is less network traffic. Another interesting tidbit I learned about ODBC drivers is that some drivers are just layers on top of the native API. The two ODBC drivers for Oracle that I encountered use the OCI functions in the Oracle native API DLL. Thus, using ODBC to communicate with an Oracle server isn't as efficient as using the native API. ODBC has gone through significant revisions in its lifetime. In the beginning, ODBC drivers were 16-bit-only affairs, with a pretty bare-bones set of APIs. As I write this, the most recent revision to ODBC is version 3.5, which is exclusively 32-bit, supports Unicode, and can enlist in MTS transactions if the underlying driver supports it. To most users, ODBC is embodied by the ODBC applet in the Windows control panel. If you're not a database expert, it's pretty easy to become flummoxed by terms like User DSN, System DSN, and File DSN. The idea behind a DSN (data source name) is actually pretty simple. In order to make a connection to a database, ODBC needs some basic information. Depending on the database server, this might include the server name, the user name to log in as, a password, the default table, and so on. More recent versions of the ODBC applet have wizards that guide you step by step to collect the relevant information. A DSN represents a shortcut to all the information for connecting to the database server. User and System DSNs keep this information in the registry. User DSNs are kept in the registry hive of the logged-on user, while system DSNs keep the data in a registry area accessible by any account. A file DSN stores the data in a text file that looks something like the following: |
|
| While ODBC is a widely used standard, it's not perfect. For starters, the ODBC API is complex. ODBC was designed to support diverse databases, and as such it might take several steps in ODBC to do something that might be accomplished in a single step otherwise. This can make some ODBC implementations slower than the equivalent code using native calls, since the ODBC driver may not be able to take advantage of specific features of the native call interface.
Another effect of ODBC's granular approach to database access is that it becomes somewhat like assembly language programming. A seemingly simple task can take numerous steps that must be performed in exactly the correct order. In addition, the ODBC APIs use pointers, structures, and other C-isms that make it problematic to use from other languages. Microsoft responded to these issues by adding yet another layer atop ODBC.
RDO: A COM-based ODBC If you were to skim through the ODBC APIs, you'd find that many of the APIs can be grouped into object-oriented classes. A few years ago, Microsoft took this step and came up with RDO. RDO is a set of COM objects, such as rdoEnvironment, rdoConnection, rdoQuery, rdoTable, rdoColumn, and so on. The primary advantage of RDO is that it's easily used by Visual Basic. Connecting to an ODBC-accessible database using RDO is as simple as declaring an rdoConnection object, setting some properties, and calling the ::OpenConnection method. Besides making it easy to access ODBC data sources via RDO, Microsoft also created the RemoteData control, which uses RDO. The RemoteData control was designed to easily connect data-aware bound controls to a data source. The properties of the RemoteData control are the same things found in a DSN (that is, the driver name, user name, password, and so on). Another popular COM object library for accessing databases is DAO. DAO is also known as the Jet engine, which is the core of Microsoft Access. The object hierarchies and method names of RDO and DAO are similar, but not close enough to make switching between the two easy. DAO was originally intended for accessing local Microsoft Access databases. At some point DAO gained the ability to use ODBC and connect to remote databases. However, using DAO to communicate through ODBC isn't as efficient as using RDO. A simple way to keep RDO and DAO straight is to remember that the R in RDO stands for remote. RDO is best used for connecting to enterprise databases, while DAO is optimized for connecting to a Microsoft Access database on a local machine. But wait, there's more! To further confuse things, DAO eventually added an alternative mode of operation, known as ODBCDirect. To quote the Microsoft documentation: "ODBCDirect is really just Remote Data Objects (RDO) with DAO object names. When ODBCDirect is enabled, DAO does not load the Microsoft Jet database engine—it loads RDO 2.0 instead." The primary benefit of ODBCDirect is that you can write DAO code to run against a local Microsoft Access database. Microsoft Access has an easy-to-use UI for setting up database tables and relationships. After your application is up and running, you can then enable ODBCDirect to use a larger enterprise class database server.
Database Access: The Next Generation For a long time, Microsoft has stressed that future technologies would use COM rather than plain APIs. OLE DB is just such a technology. OLE DB allows uniform data access to diverse data sources through a library of powerful data manipulation interfaces. In many ways, OLE DB is a COM version of ODBC. Like ODBC, OLE DB uses data providers that implement a predefined interface. OLE DB data providers are roughly analogous to ODBC drivers, and are typically implemented as in-process server DLLs. Unlike ODBC, OLE DB isn't confined to just databases. OLE DB data providers can be written to access text files, email, spreadsheets, or just about anything that can be represented as a set of records. Another difference between ODBC and OLE DB is that there's no "driver manager" component that applications link directly against. Instead, a data provider exposes the appropriate interface that a consumer (client) needs. How does an application locate the correct data provider? OLE DB has an Enumerator class, and Microsoft provides a default enumerator implementation which reads the registry to find available data providers. Microsoft currently provides four OLE DB data providers. The first three are optimized for popular database engines: SQL Server, Jet (Microsoft Access), and Oracle. However, the fourth data provider, the ODBC provider, makes OLE DB a universal access layer for any database that has a Windows ODBC driver. An important point about the available data providers: if a native OLE DB provider exists for your database server, use it rather than the ODBC provider. Currently, this means SQL Server, Jet, and Oracle. Using the OLE DB ODBC provider only inserts an extra layer of unnecessary ODBC code. For example, the OLE DB provider for Oracle communicates with the OCI DLL. If you use the OLE DB ODBC driver, the provider calls into ODBC, which in turn calls the OCI DLL. Any extra layers between your code and the wire is an opportunity for inefficiencies to creep in. Earlier, I mentioned how OLE DB was somewhat like ODBC. This similarity extends to the complexity of the OLE DB interfaces. I personally have a hard time keeping all the various interfaces straight. Another similarity is the use of C++ features that are not easily accessed from Visual Basic. Indeed, it's not practical to use OLE DB or ODBC from Visual Basic or VBScript in ASP pages. This impracticality nicely foreshadows the final client data access layer I'll explain later.
Active Data Objects The current flagship data access technology from Microsoft is ADO. ADO is designed as an application-level interface to OLE DB. The ADO object model is similar to RDO, albeit with far fewer objects to remember. ADO uses OLE automation, so it's easily used by Visual Basic and scripts in ASP pages. The ADO model has superseded RDO, and Microsoft says that RDO won't be the target of future development. In the new world order, ADO layered over OLE DB has replaced the old model of RDO layered over ODBC. ADO has a less hierarchical object model than RDO, meaning that it contains fewer distinct objects, but each object has more properties and methods. Unlike RDO and DAO, ADO objects are createable outside the scope of the hierarchy. For instance, the ADO Command object is a child of the ADO Connection object, but you can create a Command object without having first created a Connection object. This flexibility gives you a number of ways to write ADO code in the most intuitive manner. Besides the Connection and Command objects, the only other types of ADO objects that you'll typically encounter are the Recordset and Field objects.
Below the Drivers and Providers No matter what collection of database access layers is used, at some point the client app and database server need to communicate. Typically, a database server defines a protocol that encodes the information passing between it and the client program. In the case of SQL Server, this protocol is known as Tabular Data Stream (TDS). The TDS format isn't documented, but it's relatively straightforward in how things like logins, queries, result definitions, and row data are encoded. At the lowest level, an ODBC driver or OLE DB provider has to read and write data in the designated protocol. However, the protocol stream can travel between the client and server using just about any valid interprocess communication mechanism. Common mechanisms include named pipes, TCP/IP, IPX/SPX, AppleTalk, and RPC. As you can imagine, it makes sense to abstract the protocol from the underlying transport mechanism. In the case of SQL Server, the ODBC driver, OLE DB provider, and native-call DLL all use the same transport API, albeit implemented in different DLLs. For instance, when using named pipes, the DLL is DBNMPNTW.DLL; while using TCP/IP, the DLL is DBMSSOCN.DLL. These DLLs are known as NetLib DLLs, and they all export the same set of functions (see Figure 1). When the ODBC driver or OLE DB provider loads, it checks to see which transport layer it's supposed to use and loads the appropriate DLL. It then uses GetProcAddress to look up the address of the APIs it needs. In a simple scenario, the SQL Server ODBC driver would use the NetLib DLL by calling ConnectionObjectSize, followed by ConnectionObject, which returns a connection handle. The ODBC driver then issues a query by passing the connection handle and the TDS-encoded query string to ConnectionWrite. To read the results from the server, the driver would call ConnectionRead, which would fill in a buffer with the TDS-encoded results. Finally, the driver would call ConnectionClose. Like SQL Server, Oracle uses a similar scheme to separate the driver from the underlying communication mechanisms. The Oracle equivalent of a NetLib DLL is known as an Oracle Protocol Adapter. The encoded data passed between the client and database server is in Transparent Network Substrate (TNS) format. Like TDS, the TNS format isn't publicly documented, although some network packet sniffing programs can break these protocols apart.
Some Sample Scenarios As I've shown, the multitude of database access layers can become confusing, especially since there are often multiple
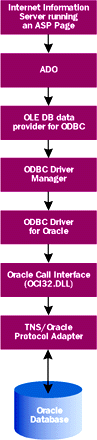
The simplest end-to-end scenario I can think of is a C++ client using OLE DB to communicate with SQL Server. In this setup, the layers look like Figure 2. For the complex scenario, consider an ASP page using ADO to communicate with an Oracle database via ODBC. In this scenario, the layers look like Figure 3. As I've shown, there's been a dizzying array of database access technologies unleashed over the years. When I first started learning about databases, if I had known that ODBC and RDO were going to be supplanted by OLE DB and ADO, my learning curve would have been much simpler. Moving forward, OLE DB and ADO represent the primary data access models for Windows DNA. OLE DB is primarily used by database providers while ADO is for database consumers. |
Have a suggestion for Under the Hood? Send it to Matt at mpietrek@tiac.com or http://www.tiac.com/users/mpietrek.
|
From the June 1999 issue of Microsoft Systems Journal.
|