![]()
 Download the code (5KB) |
| Aaron Skonnard |
| XML Patterns in Internet Explorer 5.0 |
Microsoft® Internet Explorer 4.0 introduced two XML parsers: an ActiveX® control and a Java-language applet. The ActiveX version provides an interface for interacting with the XML document object model (DOM), while the applet version is implemented as a data source object (DSO). Because it's a DSO, you can bind the applet (and any data it contains) to any data consumer, such as an HTML table. Being able to use someone else's standard XML parser is one of the primary benefits of using XML in your design; as a developer, you should never have to implement your own XML parser. Although at first it may appear that the XML parsers in Internet Explorer 4.0 do everything that you need them to do, they have some serious limitations. First, there is no way to query the XML data store for a given piece of data. To find data that you're interested in, you have to traverse the entire XML data tree and manually compare values. Second, these preliminary parsers don't provide any filtering mechanisms. Again, you would have to manually traverse the tree to filter the data. As you can imagine, hand-rolling this type of functionality is cumbersome and inefficient at the application level. Once you start using XML extensively to solve real business problems, its limitations become painfully obvious. The good news is that Internet Explorer 5.0 provides enhanced XML support that addresses these issues. Internet Explorer 5.0 integrates the XML parser into the browser and no longer requires two separate components. The integrated parser has all the capabilities of the previous ActiveX and Java-language applet versions, plus more. This in itself greatly simplifies the programming model for XML developers. Even more important to developers is the new query language support that allows you to query and filter XML data. There are several working draft documents on XML query language support available on the W3C site at >http://www.w3.org/. In Internet Explorer 5.0, this query language support is expressed through what Microsoft refers to as XSL patterns. Throughout the remainder of this column, I'll show you how to build your own powerful XSL patterns that allow you to fully manipulate your XML data stores.
New XML Query Language
|
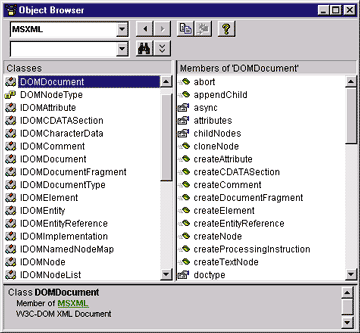 |
| Figure 1: XML-Related Interfaces |
| Here's how you can traverse all the child nodes in an XML data island (assuming that you have an XML data island embedded in the Web page with ID=xmlData): |
|
|
selectNodes and selectSingleNode
|
|
|
The //item string passed to selectNodes is an example of a pattern. You can call selectNodes or selectSingleNode on any IXMLDOMNode object to cause the parser to apply the pattern against the given node's context. (This depends somewhat on the given pattern string as well.) Once you appreciate the power of patterns, you'll wonder how you ever got by without these two methods, which give you a pretty big bang for the buck.
XSL Transformations
XSL Patterns
|
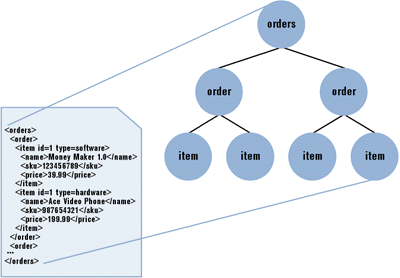 |
| Figure 3: The XML Tree Structure |
|
The XSL pattern language provides the syntax for traversing the tree structure of an XML file. Figure 4 contains special characters and operators that are part of the pattern syntax.
The XSL pattern language looks a lot like the syntax used to traverse the file system from a command shell. If you're at the root of the C drive and you type |
|
|
the current directory will change to c:\windows\system32. The XSL pattern language works the same way for describing how to traverse the XML data tree.
For example, a pattern of orders/order/item identifies the item elements within order elements within orders elements. This pattern is interpreted within the current node's context. A period also identifies the context of the current node. Therefore, a pattern of ./orders/order/item is equivalent to orders/order/item. Using a forward slash at the beginning of a pattern causes the pattern matching to begin from the root node, while using a period-forward slash combination causes the matching to begin from the current node. The node that calls selectNodes or selectSingleNode becomes the current node. Whether you use root or relative patterns, embedded forward slash characters always select the immediate children of the left-side collection. If you want to match a pattern recursively against multiple levels in the hierarchy, you can use a double forward slash combination in your pattern just like you can use the single forward slash. Using // at the beginning of the pattern specifies that you should match against all levels within the tree, while using .// specifies to match against any level below the current context. Embedding // within a pattern specifies that the pattern should match against any level below the left-side collection. You can also use the node wildcard character (*) for matching all elements at a given context regardless of name. When you combine all of these special characters and operators in your patterns, you can precisely identify any node or set of nodes within an XML document. Take a look at Figure 5 for some pattern examples. You can use the @ character to identify attributes that belong to a given element. For example, to identify the type attribute on the item element, use the following pattern: |
|
| Basically, you can treat attributes just like child nodes of an element, except you must prefix the name with an @ character.
Collections
|
|
| Taking it further, the following string illustrates how to use the element method to identify the first item element within the collection of items for the first order in the document: |
|
| Everything I've shown you up to this point allows you to efficiently query for elements within a data tree based on their hierarchical relationship to one another. In other words, the patterns above exploited the structure of the tree to identify the matching collection of elements. What I still haven't shown you is how to filter the data tree using pattern operators and information methods.
Pattern Filters
|
|
| The previous statements also illustrate how filters are applied to a given collection. All elements that match the filter remain in the resulting collection while all elements that don't match are removed. You can apply filters at any level in the pattern and you can have more than one in the pattern. For example, here's a more complex filter expression: |
|
| This complex pattern identifies the first 10 items from the entire collection of items that have a price greater than 20 dollars and are within an order where the customer's last name is Skonnard and there is more than one item in the order. As you can see from this example, the pattern syntax is flexible enough to define very precise queries.
To help you get started learning the pattern syntax, I've provided a simple DHTML page (see Figure 9) that allows you to load an XML file, enter a pattern, and call selectNodes or selectSingleNode. The nodes that match the pattern are displayed in the output area on the right (see Figures 10, 11, and 12). The best way to get familiar with patterns is to start building queries and analyzing the results. You can download the demo code from the link at the top of this article. |
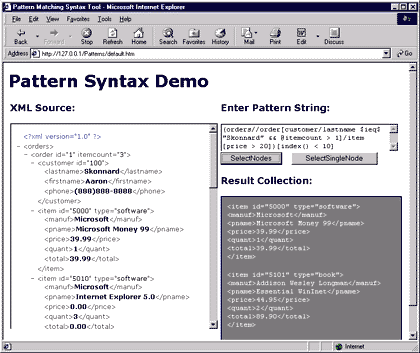 |
| Figure 10: A Complex Filter Expression |
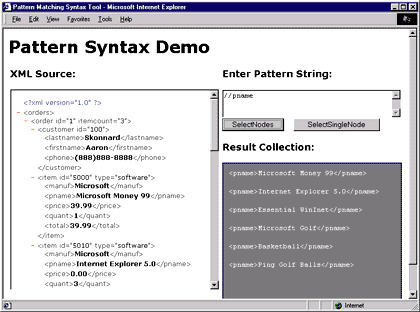 |
| Figure 11: A Simple Filter Expression |
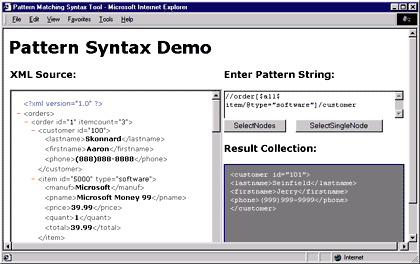 |
| Figure 12: Yet Another Filter Expression |
|
Conclusion
Internet Explorer is one of the first browsers to offer advanced XML support. While the XML parsers in Internet Explorer 4.0 had many features, they lacked basic query and filter capabilities. Internet Explorer 5.0 now adds this functionality by including support for XSL patterns. To fully take advantage of this new functionality, you must become familiar with XSL pattern language syntax and how it's used to perform advanced querying and filtering operations. |
|
From the November 1999 issue of Microsoft Internet Developer.
|
