FEATURE
Advanced Join Techniques
Save time and improve
performance
The SQL Server query optimizer uses a variety of algorithms and new join techniques to find the best available plan for your queries. In most cases, you can rely on its decisions. This article delves into SQL Server 7.0's new internal mechanisms for processing joins. Understanding the new algorithms available to the query processor will help you understand how the query processor works, and help you to see why you don't have to create indexes for one-time ad hoc queries. We also cover join hints, which let you take control from the query optimizer and force a certain join algorithm or table order. Join hints can be useful in the rare scenarios in which the query optimizer doesn't make the best decision. You can also use join hints to test any join algorithm's efficiency. For tips on maximizing the optimizer's performance, see "Performance Considerations," page 40.
Join Strategies
By choosing effective indexes and join strategies,
the query optimizer builds an efficient plan to retrieve data. The
number of logical reads and the amount of CPU time required
generally determine the cost of a query plan. The fewer logical
reads and the less CPU use, the lower the cost of the query plan.
Three join strategies are available to the query processor: nested
loops, merge joins, and hash joins. Nested-loop join was the only
strategy available in previous releases of SQL Server. Microsoft
introduced merge and hash joins primarily to accommodate very large
databases (VLDBs) and the special needs of data warehouses. These
join types can exploit large amounts of memory and the increased
processing power of modern servers.
Every join operation involves two inputs, each of which is a table or a subset of data in a table. An input might not be an entire table, because you can use a WHERE clause to filter the rows in the table, or use GROUP BY to summarize them. In that case, the result of the filtering or summarizing is the input to the join operation.
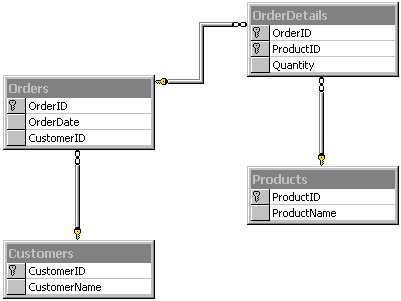
Most examples in this article use a database that contains information about products, orders, and customers. The schema in Screen 1 shows the relationships of four tables we refer to.
Nested-Loop Joins
If the optimizer determines that a nested-loop join
is the optimal join, it selects one table as the outer (first) table
and the other as the inner table. When executing a nested-loop join,
SQL Server scans the outer table row by row. For each row, it also
scans the inner table, looking for matching rows. This join type is
very efficient if one of the tables is small (or has been filtered
so that it has only a few qualifying rows) and if the other table
has an index on the column that joins the tables. The optimizer
typically chooses the small table as its first input because this is
the fastest method of executing the nest-loop algorithm.
For the nested-loop strategy to be effective, the inner table needs an index on the join column. This index means SQL Server doesn't need to scan the entire inner table; after accessing a row in the outer table, SQL Server can use the index on the join column to quickly find all matching rows in the inner table.
If the inner table doesn't have a useful index on the join column, the optimizer usually chooses a hash join strategy. However, if the join between the tables isn't based on equality, the optimizer chooses a nested-loop join, regardless of the tables' sizes and indexing schema.
Listing 1 contains the code to create and populate four tables. Let's look at the following query on the tables:
SELECT C.CustomerName, O.OrderDate
FROM Customers C INNER JOIN
Orders O
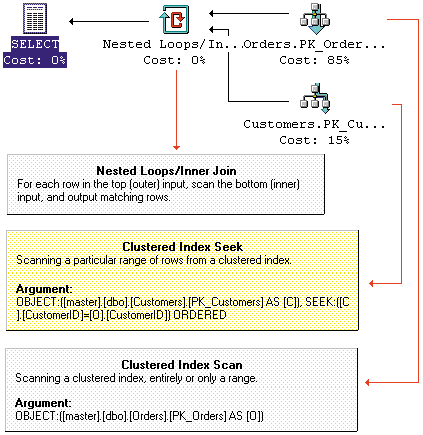
ON C.CustomerID = O.CustomerIDScreen 2 shows the nested-loop query execution plan. The outer loop iterates through the rows in the Orders table. Note that because a clustered index contains the data, when the execution plan calls for a clustered index scan, the query processor scans the entire table. In the absence of a clustered index, this scan is called a table scan. For each row in the Orders table, the query processor uses clustered index seek, which scans a particular range of rows from a clustered index to seek a matching row in the Customers table because the join column CustomerID has a clustered index.
The query optimizer distinguishes among three variants of nested-loop joins, according to Books Online (BOL). A search that scans an entire table or index is a naïve nested-loop join. A search that performs lookups in an index to fetch rows is an index nested-loop join (which Screen 2 shows). When SQL Server builds an index as part of the query plan and destroys it when the query completes, you have a temporary index nested-loop join. If you notice the Query Analyzer using a temporary index nested-loop join for a common join, you might want to consider running the Index Tuning Wizard to determine whether you could benefit from adding an index to the base table.
Merge Joins
If the optimizer decides that a merge join is
optimal, the query execution scans two sorted inputs and merges
them. For a merge join, the query processor sorts both inputs on the
join column; if the two inputs to the join are already sorted on the
join column (for example, if each has a clustered index on the join
column), merge join is a logical choice. In other cases, if adequate
memory is available, the optimizer might determine that sorting one
input before joining inputs results in the most efficient join
strategy.
If a one-to-many relationship exists between the inputs, SQL Server follows a series of steps for an inner join executed with a merge join strategy. First, it gets a row from each input, then compares the join columns of the rows. If the join columns match, SQL Server returns the requested columns from each row. If the columns don't match, SQL Server discards the row with the lower value and gets the next row from that input. SQL Server repeats these steps until it has processed all rows in both inputs, scanning both inputs only once.
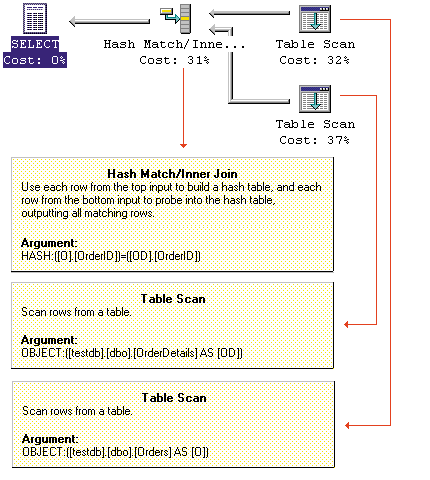
To demonstrate a situation in which the optimizer will choose merge join, we inserted 10,000 rows into the Orders table. For each Order, we inserted five products into the OrderDetails table, resulting in 50,000 rows. Both Orders and OrderDetails have clustered indexes on the OrderID column. Then we executed the following query against the tables:
SELECT O.OrderID,
O.OrderDate,
OD.ProductID,
OD.Quantity
FROM Orders O INNER JOIN
OrderDetails OD
ON O.OrderID =
OD.OrderID
Screen 3 shows the execution plan: SQL Server scans both the Orders table and the OrderDetails table. For each row in Orders, the matching rows in OrderDetails are merged.
Another case of merge join might occur if a many-to-many relationship exists between the inputs. If duplicate values exist in both inputs, the second input must be positioned to the point in the database where the first duplicate was found before the query processor can process the next duplicate from the first input. A temporary table stores the rows instead of discarding them. We can best explain this approach with a simple example:
SELECT Table1.Col1, Table1.Col2, Table2.Col3
FROM Table1 INNER MERGE JOIN Table2
ON Table1.Col1 = Table2.Col1Note that in this example, we used a join hint (which we'll explain later) to force a merge join. With these small tables, the optimizer probably won't choose merge join. Figure 1 shows an illustration of the process.
Hash Joins
The third type of join is a hash join. The main
reason why the SQL Server optimizer chooses the hash join algorithm
is a lack of adequate indexes on the join columns. If the optimizer
chooses a hash join, the execution plan involves building a hash
table, which is like building a special index on the fly. The hash
join strategy has two phases: build and probe. During
the build phase, the query processor builds a hash table by scanning
each value in the build input (usually the smaller table) and
applying the hashing algorithm to the key. The hash table consists
of linked lists called hash buckets. The hash function
applied to each hash key in the build input determines the relevant
hash bucket. During the probe phase, the query processor scans each
row from the probe input (the second table) and computes the same
hash value on the hash key to find any matches in the corresponding
hash bucket.
Hash joins perform most efficiently when the tables differ significantly in size. While processing the query, SQL Server might determine that it chose the wrong table for the build input. In that case, a role reversal occurs, and the build input becomes the probe input and vice versa.
An example of a hash function is adding the ASCII values of the characters in the key field and extracting only the last few digits of the result. Another example is computing the modulo (percentage) of the key and a prime number. An important aspect of the hash algorithm is that, unlike regular index keys, the hash function can produce significantly shortened versions of the original keys. The hash function chosen generates an even distribution of the input rows in the hash buckets. These special hash indexes are efficient for finding exact matches (because the two join keys generate the same hash function result), but are useless for joining tables based on inequalities.
To demonstrate a situation in which the optimizer usually chooses a hash join, drop the constraints and both clustered indexes from the Orders and OrderDetails tables. Now execute the same query we ran in the merge join example:
SELECT O.OrderID, O.OrderDate,
OD.ProductID, OD.Quantity
FROM Orders O INNER JOIN OrderDetails OD
ON O.OrderID = OD.OrderID
The Orders table is the best candidate for the build input because it's considerably smaller. The linked lists start with the function's possible results; in this case, there are only five. Linked to each bucket are records containing all the values the query will return from the build input table that correspond to the bucket. Applying the hash function to the join column of each build input record determines the correspondence. OrderID and OrderDate are the only columns you need from the build input (the Orders table), so these values are the only ones that stay in each record of the hash table. Screen 4, page 38, shows the query execution plan.
SQL Server performs a table scan on the smaller table, Orders, which is the build input. Then it builds a hash table with the values that result from applying the hash function to each scanned row. SQL Server also performs a table scan on the probe-the OrderDetails table-and looks for the matching values in the hash table by applying to each scanned row the same formula that it used to build the hash table.
In some cases, your server might not have enough memory to hold the entire build input. In that case, SQL Server divides the hash table into multiple partitions and performs the join in separate steps, loading the relevant partition as needed. The hash join algorithm is very fast and efficient when proper indexes don't exist. This efficiency is an advantage when you want to run ad hoc queries without incurring the overhead of creating and dropping new indexes for only these queries.
Internal Joins (Index
Intersection)
Joins are usually explicitly external
operations, but with the new join strategies available in SQL Server
7.0, the query processor might decide to use these techniques even
for a query involving one table. This technique is usually
beneficial when the columns you request in the output appear in
separate indexes on the same table. Previous releases of SQL Server
let you use only one index from each table in an execution plan.
Now, because you can exploit more than one index from one table,
intersecting those indexes might be faster than accessing the data
pages. This case involves covering indexes, which are indexes
that hold all the data that a query needs, so the query doesn't have
to access data pages. To illustrate this technique, create a table
with the code in Listing 2. Now run the following query, and look at
the execution plan in Screen
5.
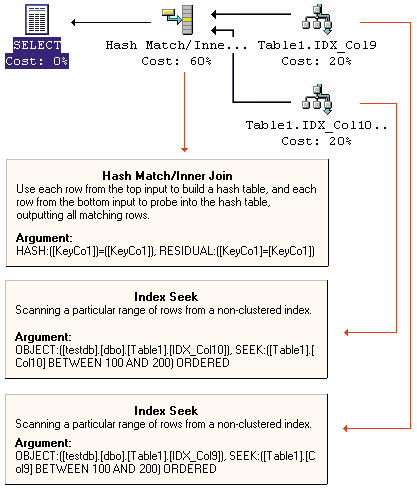
SELECT Col9, Col10
FROM table1
WHERE Col9 BETWEEN 100 AND 200 AND
Col10 BETWEEN 100 AND 200
The script requested two columns from the same table, but the query optimizer looked for the relevant rows from the indexes on Col9 and Col10, then built a hash table by using the index IDX_Col9 as the build input and IDX_Col10 as the probe input, as if joining two tables.
How does the optimizer know how to join these two result sets? In other words, which join column does the hash function operate on? In this case, the hash function operates on KeyCo1, which is the clustering key the hash join created. In SQL Server 7.0, the index rows for nonclustered indexes on a table with a clustered index contain the clustering key for the referenced data row. Because both nonclustered indexes contain the clustering key as a column in the index rows, this clustering key can be the join column.
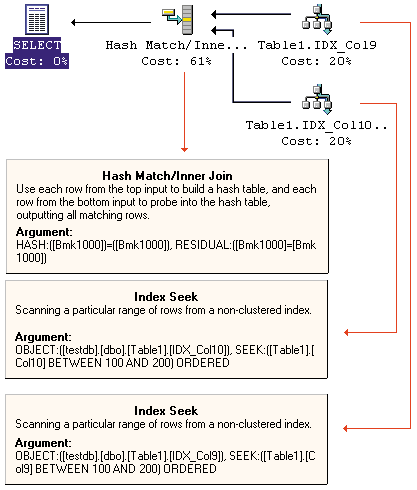
Now drop the clustered index that exists on col1, by dropping the primary key constraint:
ALTER TABLE table1 DROP CONSTRAINT PK_Col1
A table that has no clustered index is called a heap. Every nonclustered index has the key value and a pointer to the data page and row. Now run the previous query. The execution plan is in Screen 6. The optimizer still decided to implement an internal hash join! Because each index now has a key and a pointer to the data page and row, the row pointer can be used as the join key.
Joining multiple indexes from one table isn't only for covering queries. SQL Server can take the resulting rows from the index join and, because it has the clustering key or the row pointer, it can access the rows in the base table. To illustrate this technique, run the following query, and look at the execution plan in Screen 7:
SELECT *
FROM table1
WHERE Col9 BETWEEN 100 AND 150 AND
Col10 BETWEEN 100 AND 150In this example, the query processor uses the hash join strategy to join the indexes on Col9 and Col10. The query processor then uses the row pointer from the result to look up the relevant rows from the base table because you dropped the clustered index from the table. If a clustered index had existed, the query processor would have used the clustering key instead.
Join Hints
The query optimizer is very sophisticated, and in
most cases, it chooses the best join strategy. However, in some
situations, perhaps because of a lack of statistics or uneven data
distributions, it might not make the right choice. When tuning query
performance, experiment with different strategies on the same query
to try to find a better strategy than the optimizer's choice. If you
think that a better strategy is available, you can use join hints.
Keep in mind, though, that after you add a join hint to the query,
the query becomes static. You lose SQL Server's ability to process
queries dynamically as a result of adding a new index, dropping an
existing index, updating statistics, or modifying data in the
tables.
The syntax for supplying join hints is
SELECT <select_list>
FROM <left_table_name>
<join_type> <join_hint>
JOIN <right_table_name>
The <join_type> can be LOOP, MERGE, or HASH. (A fourth hint, REMOTE, doesn't really control the join strategy as we discuss in this article, so we won't go into detail about it.) Note that you must use the ANSI join syntax to use a join hint. For example, to force a certain join strategy on a query that selects all orders and their details, use the process in Listing 3, page 40. To test the efficiency of a certain query, you can use SET STATISTICS TIME ON to show execution times, SET STATISTICS IO ON to show I/O costs, and SET SHOWPLAN_TEXT ON to show the execution plan.
Let's look at an example in which forcing a strategy that is different from the one the query processor chose might yield better performance. Suppose the Orders table has 10,000 orders and the OrderDetails table has five entries for each of those orders. Run the following query, which selects all orders, their products, and quantities:
SET SHOWPLAN_TEXT ON
GO
SELECT O.OrderID, O.OrderDate, OD.ProductID,
OD.Quantity
FROM Orders O INNER JOIN OrderDetails OD
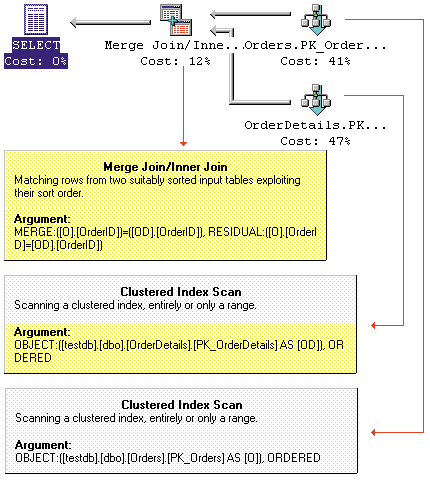
ON O.OrderID = OD.OrderIDThe execution plan
-Merge Join(Inner Join,
MERGE:([O].[OrderID])=([OD].[OrderID]),
RESIDUAL:([OD].[OrderID]=[O].[OrderID]))
-Clustered Index Scan
(OBJECT:([testdb].[dbo].[Orders].
[PK_Orders] AS [O]), ORDERED)
-Clustered Index Scan
(OBJECT:([testdb].[dbo].[OrderDetails].
[PK_OrderDetails] AS [OD]), ORDERED)
shows that the query processor chose a merge join. Forcing different join strategies with join hints shows that merge join is the best choice for this case.
If you run the following query
SELECT O.OrderID, O.OrderDate, OD.ProductID,
OD.Quantity
FROM Orders O INNER JOIN OrderDetails OD
ON O.OrderID = OD.OrderID
WHERE O.OrderID > 9900the query processor chooses merge join again. But if you try a nested-loop join, you'll see that it yields considerably better performance:
SELECT O.OrderID, O.OrderDate, OD.ProductID,
OD.Quantity
FROM Orders O INNER LOOP JOIN OrderDetails OD
ON O.OrderID = OD.OrderID
WHERE O.OrderID > 9900You might use another hint to force the query processor to join tables in the order in which they're listed in the FROM clause. With no hint, the query optimizer decides the order of the joins on a cost-based estimation, regardless of their order in the SQL statement. To force the join order for a certain query, use the FORCE ORDER query hint. FORCE ORDER isn't a JOIN hint because it doesn't appear in the FROM clause. Alternatively, you can force the query processor to use your specified join order for all queries in the session level by using SET FORCEPLAN ON.
As a rule, avoid interfering with the query optimizer's decisions. The optimizer uses a variety of algorithms and in most cases, it comes up with the best plan. The new join techniques we discussed in this article are some of the improvements in SQL Server 7.0 that let you keep a normalized data model, accommodate VLDBs, and get your desired results faster.
SQL Server MagazineCopyright Duke Communications Intl, Inc. All rights reserved.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}