October 1999
![]()
| Writing MTS-style Transactions with Visual Basic and SQL Server 7.0 |
| If you plan to run Microsoft Transaction Server-style transactions, you should know how SQL Server works with the MTS runtime and the Windows NT Distributed Transaction Coordinator. Understanding how all these pieces fit together will improve your ability to optimize your application. |
| This article assumes you're familiar with SQL Server, MTS, and Visual Basic |
|
Ted Pattison is an instructor and researcher at DevelopMentor
(http://www.develop.com), where he manages the Visual Basic curriculum. Ted is the author of Programming Distributed Applications with COM and Visual Basic 6.0 (Microsoft Press, 1998). |
|
Let's say that you're planning to create an online transaction processing (OLTP) application using Microsoft® SQL Server 7.0, Microsoft Transaction Server (MTS), and Visual Basic®. Maybe you're creating a forms-based desktop application that will connect to MTS objects from across a LAN. Maybe you're creating a browser-based application where you'll be instantiating MTS objects from ASP scripts. Whatever you have in mind, if you plan to run MTS-style transactions, you should know how SQL Server works with the MTS runtime and the Windows NT Distributed Transaction Coordinator (DTC). Understanding how all these pieces fit together will improve your ability to optimize your application.
I'll examine the most significant aspects of controlling SQL Server transactions from a set of middle-tier MTS objects. You'll see a few new features of SQL Server 7.0 that provide you with better control and the potential for greater scalability. My objective is to arm you with the knowledge required to effectively tune your applications between concurrency and consistency. I'll start out by reviewing a little transaction processing theory and explaining the motivation for the SQL Server lock manager. Next, I will lay out the various isolation levels supported by SQL Server and discuss when each is appropriate. Finally, I'll dive into the murky waters of MTS and the DTC and discuss how to control a distributed transaction from an MTS application. The discussion will include various other topics, such as SQL Server hints and how to avoid deadlocks. A Quick Flashback: ACID Rules
Atomic A transaction must be an all-or-nothing proposition. Everything must be updated successfully or nothing should be updated.Take a moment to consider what the I in ACID really means. The system needs to isolate a transaction's uncommitted changes from other transactions because uncommitted changes may be rolled back. Let's look at an example of a system that doesn't provide isolation. When transaction A makes a change, there is an interval of time before the change is committed. If transaction B is able to see and use the uncommitted changes from transaction A, problems can occur. What happens if transaction A is rolled back? Transaction B can be infected with data that never really existed. As you can see, if a system runs transactions concurrently, it must isolate uncommitted changes to enforce data consistency. Programmers rely on the underlying system to provide this isolation through locking. SQL Server incorporates a built-in lock manager that provides isolation by acting as a blocking agent. If transaction A modifies a data item, all other transactions that attempt to read this data item will be blocked until transaction A is released. Once transaction A is committed, the lock manager allows transaction B to read the data item in its new state. Once transaction A is aborted, transaction B can read the data item in its initial state. You should note that in both cases the lock manager prevents transaction B from seeing uncommitted changes. Transaction B must wait until transaction A has been released. At this point, it's important to make a few observations. Data consistency requires isolation, and isolation requires locking. Locking decreases concurrency because it results in blocking. Blocking reduces the system's overall responsiveness and throughput. From this you can formulate two important rules for optimizing an OLTP application. First, don't acquire locks on data items that aren't necessary. Second, try to minimize the time that any lock is held. Locking and Granularity
|
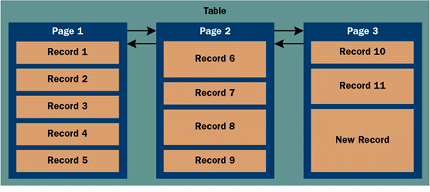 |
| Figure 1: SQL Server Record Pages |
|
SQL Server 6.0 and earlier supported only page and table-level locking. SQL Server 6.5 introduced a scheme where record-level locks could be used at the last page in a table when inserting rows. However, this feature was not turned on by default in SQL Server 6.5 and had to be explicitly enabled on a table-by-table basis. Version 7.0 is the first version of SQL Server to offer true record-level locking. SQL Server 7.0 has a built-in optimizer that determines which locking granularity to use for each read and write operation. If you are running an INSERT or an UPDATE that involves a single row, the optimizer will typically elect to use record-level locking. If you have an update that involves many rows, the locking optimizer may decide to escalate to page locks or possibly a table lock. In most cases you can rely on the SQL Server optimization to choose a locking granularity for you. In rare situations you may want to explicitly tell SQL Server to use row-level locking or a table lock. SQL Server includes a set of locking hints that influence locking granularity (see Figure 2). You can place one of these hints into your SQL code, like this: A write lock conflicts with other write locks and with read locks. A transaction that has a write lock blocks all other transactions from reading or writing to the data item in question. The data item remains locked until the transaction is committed or rolled back. This makes sense because the system must isolate uncommitted changes to ensure data consistency. But this isolation has a price: the blocking reduces overall system concurrency and throughput. Read locks don't conflict with other read locks. Many transactions can obtain a read lock on the same data item concurrently. A transaction can't obtain a write lock on a data item that has outstanding read locks. This ensures that a transaction doesn't overwrite a data item while another transaction is reading it. Understanding Isolation Levels
Running Distributed Transactions with MTS
|
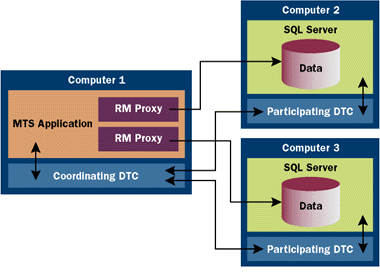 |
| Figure 3: Using the Distributed Transaction Coordinator |
|
While it's possible to write a DTC-based transaction without the help of MTS, such an undertaking involves quite a bit of system-level coding. Furthermore, some of the DTC interfaces are inaccessible to higher-level languages such as Visual Basic. MTS adds value by making it possible to run distributed transactions without having to get involved with the low-level details of the DTC. MTS hides all DTC interaction by providing a programming model based on declarative transactions. You are responsible for creating one or more objects inside the scope of an MTS transaction. When you invoke a method on transactional objects, MTS interacts with the DTC on your behalf to run distributed transactions. What you as a programmer are responsible for is not overly complicated. After you create your objects inside an MTS transaction, you use a handful of methods supplied by the ObjectContext interface. This allows you to control the flow of the transaction and to make sure the transaction is released as soon as possible. Let's examine how you create one or more objects inside an MTS transaction. Every MTS component has a transaction support attribute. The MTS Explorer allows you to read and modify this setting on a component-by-component basis. Visual Basic 6.0 added the MTSTransactionMode setting to the property sheet of each public class module inside an ActiveX DLL project. When you set this property, Visual Basic publishes the corresponding MTS transaction support attribute in your server's type library. When installing (not importing) your DLL with the MTS Explorer, MTS automatically configures your components with the appropriate transaction support attributes. The person installing a DLL into an MTS package doesn't have to set these attributes by hand, as is the case with DLLs created with Visual Basic 5.0 or when importing components. You might notice that there is a difference between the transaction support setting in MTS and the MTSTransactionMode setting for a Visual Basic class module. Don't let this bother you; it's just a slight inconsistency in the wording used by the MTS team and the Visual Basic team. Every transaction support property has a corresponding MTSTransactionMode setting. Creating Objects Inside a Transaction
How Does MTS Interact with the DTC?
Understanding Commit/Abort Behavior
|
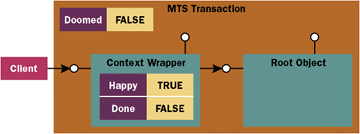 |
| Figure 4: The Root Object and its Context Wrapper |
|
The transaction as a whole maintains a Boolean value that indicates whether the transaction should be aborted. I'll call this the doomed flag. This value is initially set to False when the MTS transaction is created. When this flag is set to True, the MTS runtime knows to abort the transaction. Now, when does the MTS runtime inspect the doomed flag? And how can you change the value of the doomed flag? To answer these questions you must understand that the root object plays a very important role in every MTS transaction. There are two cases when the MTS runtime inspects the doomed flag: when the root objects returns control to its caller and when the root object is deactivated. Let's look at these two cases and see what the MTS runtime does after inspecting the doomed flag. The first case is when the root object returns control to its caller. The flow of execution always passes through the context wrapper first. When control passes through the context wrapper, the MTS runtime inspects the doomed flag. If the doomed flag is False, the MTS runtime doesn't do anything. If the MTS runtime finds that the doomed flag has been set to True by one of the objects inside the transaction, it aborts the transaction and deactivates all of its objects except for the root object. As you will see, this situation is undesirable. The transaction has been aborted, but the root object remains activated in a futile state. You can avoid this by following the rules I'll outline later. The second case when the MTS runtime inspects the doomed flag is when the root object is deactivated. When the root object is deactivated during an active transaction, the MTS runtime inspects the doomed flag and releases the transaction by calling either Commit or Abort. If the doomed flag is set to False, the MTS runtime calls Commit; if the flag is set to True, the MTS runtime calls Abort. Note that the deactivation of the root object should always cause the end of the transaction's life cycle. When the root is deactivated, the transaction will always be released. As long as the root object remains activated, the transaction can stay alive and hold onto its locks. Remember, you want to minimize the amount of time that any lock is held. There are two flags maintained inside the context wrapper for every MTS transactional object. The first one is the happy flag. It has an initial value of True when the context wrapper is created. When an object running inside an MTS transaction is deactivated, the MTS runtime examines its happy flag. If the happy flag is set to False, the MTS runtime sets the transaction's doomed flag to True. Once the transaction's doomed flag is set to True, it can't be reversed. This has a powerful implication: if the root object or any other object inside a transaction is deactivated in an unhappy state, the transaction is doomed to failure. Let's look at a few scenarios to see how all this works. First, imagine that a base client creates an object from a component marked as Requires a Transaction and invokes a method call. This results in the creation of an MTS transaction and triggers the MTS runtime to call the DTC to create the physical transaction as well. What happens if the base client simply releases its reference to the MTS object? When the MTS object is deactivated, the MTS runtime inspects its happy flag. The happy flag still has its initial value of True. Therefore, the MTS runtime doesn't change the doomed flag. The doomed flag remains False and the MTS runtime calls Commit on the transaction. You can run a simple example and confirm these results by examining the Transaction Statistics in the MTS Explorer. So that's pretty easy. You create an object inside a transaction, activate it, and then release it. All it takes is three steps to successfully begin and commit a transaction with the DTC. Even though you haven't done anything interesting yet, such as writing to a database, this example shows how and when the MTS runtime interacts with the DTC. You didn't write any code to explicitly begin or commit the transaction; the MTS model of declarative transaction does all of that for you. To abort a transaction all you do is set the happy flag inside the root object's context wrapper to False. One way to do this is by calling DisableCommit in a method of the root object: DisableCommit is complemented by another method named EnableCommit, which simply returns the happy flag to True. You can call each of these methods repeatedly. The happy flag is just a Boolean value, so whichever method is called last before the object is deactivated determines how the MTS runtime handles the transaction. When you call one of these methods, you're simply voting on whether you think the transaction should succeed. Note that because MTS only looks at these bits after your method has returned control to the context wrapper, you can call EnableCommit and DisableCommit as many times as you like within a given method. Only the last call prior to returning from your object's method will actually matter. Calling SetComplete and SetAbort
Programming Multi-object Transactions
|
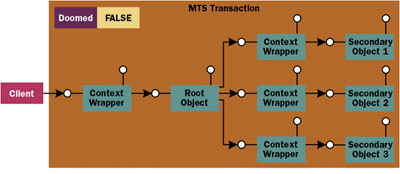 |
| Figure 5: Root and Secondary Objects |
|
An MTS transaction is a democratic community in which each object gets to vote on whether the transaction should succeed. A secondary object follows the same rules as the root object. When it is deactivated, the MTS runtime inspects its happy flag. If the happy flag is set to False, the MTS runtime sets the transaction's doomed flag to True. When this happens, the transaction is doomed to failure. There is nothing that any other object can do to set the doomed flag back to True. As you can see, any object inside a transaction can prevent the transaction from committing. You'll often write methods in the root object to create secondary objects. Once the secondary objects have been created, the root object can call their methods to complete the work for the transaction. It's important to understand how things work inside a transaction so you can coordinate communication between all these objects. Let's look at the case in which the root object makes several successful method calls on a secondary object. As long as the secondary object doesn't call SetComplete or SetAbort, it remains activated until it is released by the root object. The root object can make several successful calls on the secondary object and then call SetComplete to commit the transaction. When the root calls SetComplete, both objects are deactivated. The secondary object is deactivated first, followed by the root object. As long as neither object sets its happy flag to False by calling SetAbort or DisableCommit, the transaction is committed. What happens if the secondary object wants to abort the transaction? If the secondary object calls SetAbort and returns, the MTS runtime deactivates the object and sets the doomed flag to True. At this point, the root object regains control and must decide how to deal with the situation. Since the doomed flag is set to True, the root object can't save the transaction. Once a secondary object has been deactivated and sets the doomed flag to True, the root object shouldn't call SetComplete. If it does, the base client receives an mtsErrCtxAborted error from the MTS runtime. Moreover, if the root object tries to activate another object inside the transaction after the doomed flag is set to True, it experiences an mtsErrCtxAborting error. If the root object simply returns control to its caller at this point without calling SetComplete or SetAbort, the MTS runtime sees that the doomed flag has been set to True and it releases the transaction and deactivates all the secondary objects. This results in an unfortunate situation. The root object is left activated in a crippled state. Future method calls on the root object will more than likely result in mtsErrCtxAborted and mtsErrCtxAborting errors raised by the MTS runtime. These problems should lead you to one conclusion. When a secondary object calls SetAbort, the root object should also call SetAbort and halt any attempt to complete additional work. However, there's one small hitch: the root object cannot examine the doomed flag—it can't ask the MTS runtime whether a secondary object has called SetAbort. Therefore, your secondary objects must communicate with the root object when they call SetAbort. You can use the return value or output parameters in the methods of your secondary objects to indicate whether they called SetAbort, or you can raise errors from the secondary objects back to the root object. For example, if a secondary object decides to roll back the entire transaction in Method1, it can use the following sequence of calls: Enlisting Connections to SQL Server
|
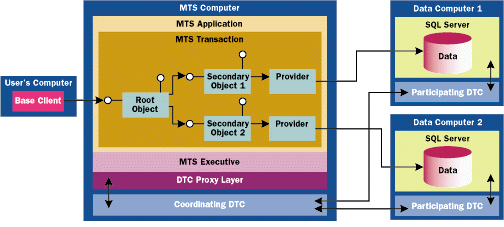 |
| Figure 6: Coordinating DTC Sessions |
|
MTS and Isolation Levels
|
|
|
Watch out for Deadlocks
Creating an OLTP application typically requires balancing two antagonistic forces. On one hand, you want the highest possible levels of concurrency; on the other hand, you must have isolation to guarantee the consistency of your data. As you know, this means the system must place locks on data items to block certain transactions while other transactions perform their work. Unfortunately, in an OLTP application concurrency and consistency are always in conflict. An MTS application runs its transactions with a default isolation level of Serializable. This means that the integrity of the system's data is the primary concern. As long as you do your part and write your business logic and data access code correctly, MTS and the DTC will make sure that your data stays in a consistent form. Most of the time when a transaction is blocked, it simply waits its turn and then gets to do its work. However, sometimes the locks acquired by a transaction don't have the desired effect. In some situations, the locks held by two or more transactions conflict in such a way that things can't be resolved by waiting. This is known as a deadlock. For example, suppose transaction A has acquired a write lock on data item X and is attempting to acquire a write lock on data item Y to complete its work. If transaction B has acquired a write lock on data item Y and is blocking on the write lock held on data item X, the two transactions have hit a stalemate. Without intervention, both transactions will wait indefinitely for the other to release its locks. A single DBMS such as SQL Server can detect a deadlock situation. SQL Server resolves a deadlock by terminating one of the transactions and sending an error message to the victim. When the locks of the victim are released, the other transaction can complete its work. In a distributed transaction, some deadlock situations cannot be detected by a single DBMS. This is why MTS transactions have a timeout of 60 seconds. If a transaction cannot be completed within that time, the DTC assumes that a deadlock situation has occurred. In either case, your code must be ready to deal with deadlock errors when they arise. You can employ a few techniques to prevent deadlocks in your MTS applications. For example, a cyclic deadlock can occur when two programmers have written separate transactions for the same system. Say a programmer writes a transaction that modifies the Products table and then the Customers table. If another programmer writes a second transaction that accesses the same tables in the reverse order, the chance of a deadlock is greater. This is especially true in a distributed environment when two tables can live in different databases on different computers. You can reduce the chances of cyclic deadlocks by maintaining a consistent flow of data access across all the transactions that run in a single system. Deadlocks resulting from lock conversion are also common and require your attention. Say you're writing a transaction that removes a specific quantity of a product from inventory. Your transaction starts by running a SELECT statement against the Products table to find out whether the requested quantity is in stock. If the inventory quantity is equal to or greater than the requested quantity, you then run an UPDATE statement to remove the quantity from inventory. Let's assume that the SELECT statement and the UPDATE statement are both run against the same record in the Products table. In a high-volume OLTP application, there's a good chance that two separate transactions will both run the SELECT statement and acquire read locks before either can acquire the write lock needed for the UPDATE statement. This results in a deadlock. Each transaction waits for the other to remove its read lock so that it can acquire a write lock. The problem is the transaction initially acquires a read lock on a data item and then tries to convert the lock to a write lock. If two transactions acquire the read lock at the same time, neither party can convert the lock to a write lock. SQL Server supports read locks and write locks, as well as another type of lock called an update lock, which solves the problem of deadlocks due to lock conversion. You should use an update lock whenever you need to escalate a read lock to a write lock during a transaction. An update lock conflicts with write locks and with other update locks. A transaction will block while trying to acquire an update lock if another transaction has already acquired a write lock or an update lock. However, unlike a write lock, an update lock doesn't conflict with read locks. If a transaction holds a read lock on a data item, another transaction can acquire an update lock. Likewise, if one transaction holds an update lock, other transactions can acquire read locks. You can explicitly ask for an update lock by using the (UPDLOCK) hint in a SELECT statement. While you can write your applications to eliminate some types of deadlocks, other types are unavoidable in a large OLTP system. Some deadlocks will be caught by the DBMS; others will occur when an MTS transaction reaches its timeout value. You must plan to trap deadlock errors when they occur and handle them as gracefully as possible. Sometimes you can handle a deadlock by resubmitting the transaction. This can hide a deadlock situation from the user of the application. At other times, you might be forced to return an error to the caller, along with instructions to "try again later." Summary
|
|
For related information see: Getting Started with SQL Server 7.0 at: http://msdn.microsoft.com/library/psdk/sql/8_gs_00.htm. Also check http://msdn.microsoft.com for daily updates on developer programs, resources and events. |
|
From the October 1999 issue of Microsoft Systems Journal.
|