April 1999
![]()
| Design a Single Unicode App that Runs on Both Windows 98 and Windows 2000 |
| Windows 2000 is planned to include support for new scripts through Unicode only, new multilingual user interface APIs, a multilanguage version of Windows 2000 Professional, and the ability to give Arabic and Hebrew apps a right-to-left orientation on any variation of Windows 2000. |
| This article assumes you're familiar with International Windows |
|
Code for this article: MulitLingualUI.exe (672KB) F. Avery Bishop works in the Windows Operating System division International group at Microsoft as an evangelist for international software development.
|
|
Editor's note: This article is based on the beta 2 release of Windows 2000. As this article went to press, it was learned that beta 2 would no longer be available after February 15. The next beta release of Windows 2000 is expected in the Spring of 1999. In the November 1998 issue of MSJ, my article, "Supporting Multilanguage Text Layout and Complex Scripts with Windows NT 5.0," concentrated mainly on multilanguage document content. In this article, I'll continue the theme of multilanguage support in Win32-based applications, this time with an emphasis on the user interface. I'll start by addressing an issue that has vexed developers since the first beta of Windows 95: how should you design an application that uses Unicode to represent text, but runs as one executable file on both Windows 9x and Windows NT®? Since this topic applies to all text in an application, not just the UI, I outlined several options to use Unicode in applications in my November 1998 article. I'll explore the recommended approach in much more detail because it is useful in a multilanguage user interface design. The approach I'll discuss here runs as a pure Unicode application on Windows NT, but as an ANSI application with conversion as appropriate on Windows 9x. The design uses the same binary files for both platforms, except for an extra conversion DLL required on Windows 9x only. I'll also discuss some of the issues encountered when implementing Unicode wrapper libraries. I'll explain my recommended design for selecting and switching the user interface language at runtime based on satellite DLLs. In addition to guidelines for designing a multilanguage user interface, I'll consider issues that you're likely to face in your own implementation. Finally, I'll introduce a technology to display user interface elements that are localized for RTL languages such as Arabic and Hebrew. In most cases, the APIs for RTL layout allow you to display application windows (including child windows), dialog boxes, and message boxes using the proper RTL orientation with only minor changes to your existing application code. Other than the RTL layout technology, these techniques are not new. I discuss them here because of the new international emphasis in Windows 2000, which is planned to include support for new scripts through Unicode only, new multilingual user interface APIs, a multilanguage version of Windows 2000 Professional, and the ability to give Arabic and Hebrew applications an RTL orientation on any variation of Windows 2000. Developing a Unicode-based App I'm going to dive into the rat's nest of Unicode support on Windows 9x, and I'll look at sample code to produce a Unicode application that runs fine on Windows 9x (and even better on Windows NT). But first, why would you want to do this? Will the payoff be worth the extra engineering effort involved? The most obvious reason to use Unicode is its ability to represent multiple languages without tedious switches in character encoding. As you'll see in the sample code, this Unicode benefit is most evident in applications supporting multilingual user interfaces. Another important motivation is that all new script support on Windows NT will be based on Unicode only—there will be no new ANSI code page support except in rare circumstances. The first scripts that are planned to fall under this strategy in Windows 2000 will be Indic (Devanagari and Tamil) as well as Armenian and Georgian. Access to the large Indic native language population requires using Unicode to represent text in applications. Now let's review the strategies outlined in the November 1998 article for using Unicode in Win32 programs, and then look at the preferred approach in detail. The simplest approach is to use conditional compilation to produce an ANSI version of the binary to run on Windows 9x (defaulting to the A versions of the Win32 entry points), and a Unicode version to run on Windows NT (using -DUNICODE and -D_UNICODE in the compiler command line to select the W routines). This is clearly unacceptable to many developers because it does not use Unicode at all on Windows 9x, and uses different binary files for both platforms. The intermediate approach is to always develop the application as an ANSI app, using the system-provided A routines, but converting to and from Unicode as necessary. The CSSamp sample program that accompanied the November 1998 article uses this approach to take advantage of Unicode while running on both platforms. As shown in Figure 1, there are a handful of W routines supported on Windows 9x, and such an implementation should use them as appropriate. In addition to these routines, the Script APIs (Uniscribe) discussed in that article also run on Windows 9x, but in Unicode versions only. Of course, this kind of application receives characters via WM_CHAR or an edit control encoded as ANSI, so it will not allow input of any new scripts that are supported through Unicode only—even when running on Windows NT. This brings me to the recommended approach for those who can or must spend the engineering effort required. The basic idea is to detect the system at startup and use the W routines with full Unicode support when running on Windows NT, but use the A routines when running on Windows 9x, converting between the local code page and Unicode as necessary. Depending on how you implement this, you could end up with a lot of runtime platform checking and extra conversion code that's never used on Windows NT. The approach I use here avoids this by declaring a function pointer for each Win32 API entry point needed in the application. (I call this the U API.) During initialization, each of these function pointers is set to the corresponding W routine when running on Windows NT, and to a handwritten wrapper routine over the A routine when running on Windows 9x. For the remainder of this section, I'll mainly discuss these wrapper functions and related code required when running on Windows 9x. Keep in mind that when running on Windows NT, the program either uses the standard W routine or, in some cases, a stub that simply returns immediately. The wrapper functions for use on Windows 9x are in a DLL that is not needed (and therefore should not be installed) on Windows NT. One of the goals of developing the sample code for this article was to create the U API so that developers could adopt it with minimal changes to a traditional Win32 program written in standard ANSI C. As I go through the sample implementation, you'll see that there is significant work in writing the wrapper functions and other components required on Windows 9x, but the changes to the WinMain and WndProc functions are minor. This allows you to separate creation of the U APIs into a module independently developed and maintained for use by all applications within a company. Now that you've seen the basic idea behind the U API, let's look at a sample implementation of the U version of RegisterClassEx: |
|
| Note that I give the pointer RegisterClassExU exactly the same prototype as RegisterClassExW, so there is no ambiguity about whether its arguments are Unicode or ANSI.
If you're running on Windows NT, leave RegisterClassExU pointing to RegisterClassExW. In fact, I chose this particular entry point for a specific reason: on Windows NT, your application will register its windows using RegisterClassExW, so it will be a pure Unicode application. All Windows messages that pass text to your application, such as WM_ CHAR and WM_SETTEXT, will do so in Unicode. On Windows 9x, I cannot leave RegisterClassExU pointing to RegisterClassExW since it is just a stub that sets the last error to E_NOTIMPL and returns FALSE. Instead, I execute code that is equivalent to the following: |
|
| The sample implementation varies from this in that it uses an initialization routine in the DLL itself to avoid multiple GetProcAddress calls. In the previous code snippet, RegisterClassExAU has the same prototype as RegisterClassExW; it accepts Unicode input through a single parameter, which is a pointer to a WNDCLASSEXW structure. Internally, RegisterClassExAU converts the Unicode fields in the structure to ANSI and then calls RegisterClassExA, the ANSI version of RegisterClassEx, as shown in Figure 2.
Incidentally, some applications link a few of the Win32 entry points dynamically using GetProcAddress to allow the application to also run on downlevel platforms that don't support these entry points. These applications may need to assign the U function pointer to a dynamically linked W routine on Windows NT, or dynamically link the A routine inside the corresponding AU wrapper for Windows 9x. They will also need a strategy to recover when the entry point is not available on the current platform. Figure 2 reveals some important considerations in implementing this approach. First, let's state the obvious: since RegisterClassExAU eventually calls RegisterClassExA to register window classes, the application runs as an ANSI application. This is necessary, of course, since the Unicode version RegisterClassExW will fail on Windows 9x. The implication is that your WndProc function will receive all text in messages from the system encoded in the system code page. Again, this is not a big surprise, but it implies that your program must convert between Unicode and the ANSI code page not only inside the AU wrapper routines, but also when sending or receiving Windows messages. I'll look at one way to handle this later. Second, note that the lpszMenuName field in the WNDCLASSEXW structure is ostensibly a pointer to the Unicode string identifier of the menu resource. In reality, many developers use constants rather than strings as resource identifiers, casting them as appropriate with the MAKEINTRESOURCE macro. In the sample code, I assume that resource identifiers are really constants and simply cast them to convert between LPSTR and LPWSTR. Clearly, if you use string identifiers, you must convert to and from Unicode using MultiByteToWideChar and WideCharToMultiByte. Since casting is easier and less error-prone than conversion, this might finally provide the motivation to convert all of your resource IDs to constants, as recommended in the MSDN entry on FindResource. In the previous example, I only required one conversion, from Unicode to ANSI, before calling the A version of the API. Other APIs will have different requirements, such as converting output from the A routine from ANSI to Unicode before passing it back as output to the caller of the AU routine. In implementing the sample code in UNIANSI.CPP, I found a range of complexity in implementing an AU entry point. Here are five levels of complexity in the wrapper functions, from easiest to most difficult.
|
|
|
|
Others with a similar implementation are LoadMenuAU and DialogBoxParamAU.
The sample code doesn't address the problem of hidden Unicode/ANSI dependencies in common controls and other functions. Many of the common controls have macros defined in COMMCTRL.H; for example, list view macros are of the form ListView_Message. ListView_GetISearchString is documented as: |
|
| However, for a pure Win32-based application, this macro resolves to: |
|
| LVM_GETISEARCHSTRING further resolves to either LVM_GETISEARCHSTRINGW or LVM_GETISEARCHSTRINGA, depending on whether the symbol UNICODE
is defined.
If you use these macros with Unicode strings, you'll need to rewrite them to call SendMessageW when on Windows NT and to convert Unicode to ANSI and call SendMessageA on Windows 9x, using the appropriate W or A message, respectively. And even if you don't use the macros—that is, you call SendMessageU directly when communicating with common controls—you'll need to send the message (W or A) appropriate to the platform. One approach is to rewrite the macros to call SendMessageU and to always use the Unicode message in your call to SendMessageU. Inside the SendMessageAU wrapper, check for any of these Unicode messages and convert them to the corresponding ANSI message before calling SendMessageA. This will work whether or not you use the macros if you always use the Unicode version of the message identifier. Some notification messages pass arguments via wParam or lParam that have Unicode and ANSI versions: |
|
| In this code segment, TVN_SELCHANGED resolves to TVN_SELCHANGEDW or TVN_SELCHANGEDA. You will get one or the other, depending on whether the tree view is Unicode or ANSI. You can usually handle this by simply replacing the last case statement to handle both cases as follows: |
|
|
Many functions that take a pointer to a callback function as an argument have Unicode and ANSI versions as well, in which case there are two corresponding data types for the callback function. For example, the third argument of the function EnumFontFamiliesEx is of type FONTENUMPROC. In reality, EnumFontFamiliesEx resolves to either EnumFontFamiliesExW or EnumFontFamiliesExA, and FONTENUMPROC resolves to FONTENUMPROCW or FONTENUMPROCA, depending on whether UNICODE is defined. The difference in the callback function definitions is only in the first parameter; the W version takes a LOGFONTW structure and the A version takes a LOGFONTA structure. As usual, your wrapper for a function that takes a callback function will eventually call the ANSI version. (That is, EnumFontFamiliesExAU would convert Unicode to ANSI in the LOGFONT parameter and call EnumFontFamiliesExA.) However, your wrapper (EnumFontFamiliesExAU) will take a Unicode callback function as input, so you'll need to write an ANSI callback function that is basically a wrapper over this Unicode callback function to pass to EnumFontFamiliesExA. I also found it necessary to implement some special- purpose functions in the UniAnsi module. (On Windows NT these are stubs that simply return TRUE.) ConvertMessage is of particular interest because it solves the problem mentioned earlier of ANSI-based messages on Windows 9x. ConvertMessage converts the parameters passed in messages from ANSI to Unicode so that the message handlers in the application can deal only in Unicode (see Figure 3). WndProc calls ConvertMessage before the main message-switch statement, as follows: |
|
| Note that WndProc simply returns 0 if ConvertMessage returns FALSE. In the sample, this can happen in one of two cases. First, for some messages ConvertMessage cannot finish the conversion from ANSI to Unicode in one call, so it must save state and wait for another call with more data. This is the case for WM_CHAR with a DBCS input locale, where the lead byte and trail byte for the DBCS character are passed in two successive WM_CHAR messages. (As mentioned in the comments, you're better off processing WM_IME_CHAR messages because you get both bytes at once.)
A second reason for returning FALSE from ConvertMessage is when a message arrives that cannot be handled in an ANSI application. For example, if the message is WM_ INPUTLANGCHANGEREQUEST with an Indian language as the requested input locale language, I reject the request by returning FALSE. I included code for this in ConvertMessage to illustrate the concept, but in real life this is not a likely scenario because no Windows 9x version will support Indian-language input. In implementing the wrapper functions, I encountered several problems whose solutions required judgment calls. Your solutions may differ considerably, depending on the nature of your application and your expected environment when running on Windows 9x. For example, the conversions to and from Unicode require a code page, the choice of which is not obvious. The sample code deals with a user interface language, an input locale language, and a system default locale, each with potentially different code pages. However, even if you were careful to keep track of these values and use the appropriate code page, the effort would be wasted in many cases on Windows 9x, which only supports multiple code pages to a limited degree. When looking at the sample source code, you'll notice that I simply used CP_ACP, which is the code page corresponding to the system default locale in most situations. The one exception is the use of the code page corresponding to the current input locale in conversions involving input. This is one area where Windows 9x does support multiple code pages. Another issue that does not have a clear-cut solution is when to implement a U interface rather than live with the restrictions of the A interface. Obviously, you can't use any of the U interfaces during initialization before the U pointers are set up, so you will have to fall back to the A interfaces until initialization is finished. Afterward, however, the decision is less clear. If you call an entry point in only a few places and you know it will not encounter multilingual text, you may elect to simply call the A version. Be aware that you may change your mind later, and that you'll have to go back and change those instances to a Unicode version. For instance, I originally used GetLocaleInfoA because I thought I would only need to call GetLocaleInfo with the LOCALE_IDEFAULTANSICODEPAGE option, in which case the return string is always a set of digits representing the code page. Later, however, I found that I needed GetLocaleInfo for other cases where the text needed to be multilingual on Windows NT, so I wrote GetLocaleInfoAU and replaced the calls to GetLocaleInfoA with GetLocaleInfoU. Two functions that I decided not to wrap were GetWindowLong and SetWindowLong. I only use them with options GWL_USERDATA and GWL_EXSTYLE, which have the same implementation for the ANSI and Unicode interfaces. If you do wrap SetWindowLongA, remember that the WndProc you pass with GWL_WNDPROC must handle messages as either Unicode or ANSI, depending on the platform. (You'll probably want to convert ANSI messages to Unicode when on Windows 9x.) Similarly, wrapping CallWindowProcA will require converting many messages from Unicode to ANSI before the call, similar to the SendMessageAU wrapper included in the sample code. I would urge you to make this decision moot whenever possible by using the available routines that support Unicode on both platforms, as shown in Figure 1. For example, I use TextOutW and MessageBoxExW, which are supported on both Windows 9x and Windows NT, as well as the wcs* routines such as wcscpy, wcscat, and wcslen from the standard ANSI CRT library. One final issue to be aware of is testing. I developed the sample code on Windows 2000 beta 2 (build 1877), and included a Windows 9x emulation mode (see line #define EMULATE9x near the top of the file UAPI.H) to force use of the wrapper APIs even when running on Windows NT. Notice that this isn't perfect because some APIs may work on Windows NT but not on Windows 9x. Therefore, it's essential to test your application live on as many versions of Windows 9x as possible. I have tested the sample on English Windows 98, Japanese Windows 98, Arabic-localized Windows 98, Arabic-enabled Windows 98, and Hebrew-localized Windows 98. I'm sure that I have not found every scenario and, therefore, every bug in the code. In particular, the SendMessageAU entry point is problematic in that it can follow any of a number of code paths, depending on the message parameter. I tested SendMessageAU with every message passed to SendMessage in the sample itself, as well as with WM_CHAR, WM_IME_CHAR, WM_GETTEXT, and WM_ SETTEXT. You should do the same with any messages you use in your SendMessage wrapper. If you do find bugs, please send a description to nlshelp@microsoft.com. Multilanguage User Interface The technique I discussed for using Unicode on both Windows 9x and Windows NT can be considered infrastructure and, therefore, may not seem very exciting until it results in real functionality to the user. In this section, I'll use the Unicode APIs to allow the user to change their preferred user interface language by selecting from a list of languages, where the name of each language is displayed in that particular language. Other than demonstrating use of the U APIs in solving a real problem, my reason for choosing selectable user interface language as an example is that Windows 2000 is scheduled to ship a multilanguage version that will allow users to change the user interface of the system itself. In support of this feature, there will also be a handful of new APIs for querying information such as the current user interface language, the original user interface language of the system when installed, and the set of all user interface languages installed (see Figure 4). In the sample code, I make use of only one of these: GetUserDefaultUILanguage. I recommend that applications also use EnumUILanguages or EnumSystemLanguageGroups during installation on Windows 2000 to avoid installing user interfaces not supported by the system. Before I launch into a description of the selectable user interface in the sample code, let's look at a well-known alternative that is familiar to longtime practitioners of Windows programming. That approach is to include multiple copies of the resource in the same .RC file, all with the same identifiers, but distinguished by LANGUAGE labels. This leads to multiple copies of the resource in the exe or DLL file (even on systems where those languages aren't supported), and you can't eliminate copies that you don't need in a particular configuration without rebuilding the application. For this reason, I don't recommend it unless you are absolutely certain that you will only ever support a small number of languages. Even so, it has no real advantage over the satellite resource DLL method used here. As the name implies, the idea behind satellite DLLs is to put resources in DLLs, one for each language. Each set of resources uses the same set of identifiers, but each DLL contains strings (and possibly other language or locale-dependent resources) in a different language. The DLLs are given a name that indicates the language of its resources. The application loads and gets a handle to the DLL of the appropriate language using Loadlibraryex, and then uses that handle in all calls to load resources. The sample code saves the handle to the resource DLL in pLState->hMResource. A significant benefit of this satellite DLL approach is that you have complete flexibility in the choice of languages to offer the user. You can elect to install only the language corresponding to the user's interface language setting, or offer an option to install other languages. You may also choose to offer all available languages automatically (given that the system supports them, of course). Maintenance is also straightforward. Since your resources are all isolated into DLLs—one per language—you can distribute bug fixes and new language modules without shipping large exe files. This method is ideal for updating through a Web site, for example. As mentioned, this approach to multilingual UI requires a naming convention for the resource DLLs. This is simply so you know where to look when you need to set up your user interface. The sample code assumes that all resources are in a directory called RESOURCES below the main executable directory, and are of the form RESLANGID.DLL. A real application would use an installer, such as the new Microsoft® installer available on Windows 2000, and may call one of the functions in Figure 4, such as EnumSystemLanguageGroups, to decide which of the resource DLLs to install. Note that there are two common scenarios requiring selection of a resource DLL to load, each with its own data and fallback requirements. The first is language-driven; you decide on a language and look for a matching DLL, for example, to set the default user interface during application initialization. This situation requires fallback in case the requested language isn't available. How do you determine the default UI language? On Windows 2000 the answer is simple: use the new API GetUserDefaultUILanguage. For earlier platforms, you need to check the registry to determine the interface language of the system. On Windows 9x use the language of the resource locale (HKEY_CURRENT_USER\Control Panel\ desktop\ResourceLocale), and on Windows NT use the locale of the default user (HKEY_USERS\.DEFAULT\ Control Panel\International\Locale). The sample code handles this in the InitUILang routine. After resolving the default UI language as described previously, it calls UpdateUILang to set all the handles required for the user interface. UpdateUILang takes a LANGID as input and calls the GetResourceModule function to find the resource DLL of the given LANGID. On failure, UpdateUILang returns FALSE, in which case UpdateUILang is called again with a fallback language (in this case hardcoded to U.S. English). A real application may try more than one fallback language, for example, looking for a match in the primary language only. The second scenario in setting the user interface is when it is necessary to find all resource DLLs matching the naming convention and selecting one, as when the user requests a change in the user interface language of the application. Once selected, you know the language is available because you found it before offering it as a choice. The sample code does this in the dialog box callback routine DlgSelectUILang, calling SetupComboBox during WM_ INITDIALOG. SetupComboBox builds a string to match the naming convention of the resource DLL file names and then uses FindFirstFileU and FindNextFileU (this allows multilingual path names on Windows NT) to find all resource files and list them in the combobox. If the user selects an interface language and clicks OK, DlgSelectUILang returns the LANGID of the UI selected. After this, the UI language is updated via UpdateUILang. When implementing multilanguage UI on both Windows 9x and Windows NT, you'll notice platform differences in some of the Win32 API functions. For example, ideally you would like to load the resource-only DLLs as data files, without referencing any executable code. The advantage is that the same DLLs will work on both the Intel x86 platform and the Compaq Alpha platform under Windows NT. However, Loadlibraryex( , LOAD_LIBRARY_AS_DATAFILE) has restricted functionality on Windows 9x; you can only use the module handle returned with the lower-level resource functions such as FindResource and LoadResource. I wanted to keep the sample application simple, so I used the simpler functions, such as LoadMenu. Since the resource DLL can't be loaded as a data file, each of these resource-only DLLs must have a dummy DLLMain, making the DLL slightly larger and slower to load than necessary. Another design issue that you'll encounter with a multilingual user interface is whether to add, remove, or modify some UI elements when switching the UI language. For example, most applications have one call to LoadAccelerators before the main message loop in WinMain, and use the same accelerator table throughout the life of the application. The sample application for this article loads the accelerator table from the new resource DLL whenever the user changes the user interface, allowing the localizers to specify different accelerator keys for each UI language. This is fine if each user only uses the application with one UI language, which is the usual case. However, users who regularly use the application with more than one user interface language may find it inconvenient, as they will have to memorize a different set of accelerator keys for each language. You need to consider your customers' needs and common scenarios in deciding which approach to take. Right-to-left Layout of Windows I now come to a topic that is likely to inspire awe and bewilderment in the uninitiated: RTL layout of windows in an application with an Arabic or Hebrew user interface. This mirrored layout is required of software localized to languages of the Middle East, following the local conventions for books and documents. As you can see in Figure 5, the entire screen for Arabic-localized Windows 98 has an overall RTL orientation: the Start button is on the right, kill buttons are on the left, and tree controls cascade from right to left. I'll refer to this as RTL layout or mirroring. Left-to-right (LTR) layout refers to the layout of English Windows 9x and Windows NT. |
 |
|
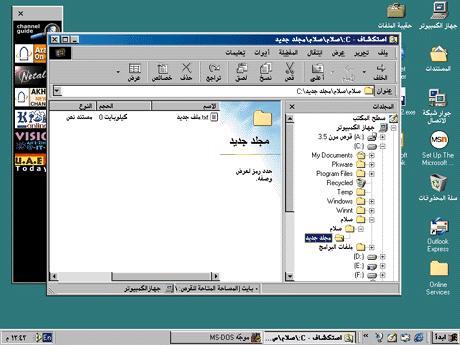
Figure 5 Right-to-left Script in Windows 98 |
The code modifications required to mirror windows in Arabic and Hebrew Windows 98, while not trivial, were less extensive than you might think. The development team first designed an architecture and programming interface to make most of the layout more or less automatic. The basis of this architecture is a simple coordinate transformation: the origin of a window changes from the upper-left corner to the upper-right corner, and the x scale factor changes such that x values increase from right to left, rather than from left to right. Function calls hide the details and allow applications to take advantage of the same RTL mirroring functionality that is used by the system in Arabic and Hebrew Windows 98. These APIs are available on those versions of Windows 98 and are planned to be available on all versions of Windows 2000.
The transformation described previously is a per-window setting that you can activate using the new extended style WS_EX_LAYOUTRTL in the call to CreateWindowEx. One of the design goals of this architecture is to set the layout of all windows and child windows to RTL easily—that is, without modifying every call to CreateWindowEx. Thus, the system also provides an inheritance mechanism; by default all child windows (those created with the WS_CHILD style and with a valid parent hWnd parameter in the call to CreateWindow or CreateWindowEx) will have the same layout as the parent window. You can disable this inheritance of mirroring to child windows in the CreateWindowEx call by specifying the extended style WS_EX_NOINHERITLAYOUT. Note that mirroring is not inherited by owned windows (those created without the WS_CHILD style) or those created with the parent hWnd parameter set to NULL in the call to CreateWindowEx.
You can also set the default layout by calling SetProcessDefaultLayout, whose prototype is:
|
| You set the default direction for a process to RTL by calling SetProcessDefaultLayout(LAYOUT_RTL). All windows created after the call will be mirrored. (SetProcessDefaultLayout does not affect existing windows.) You can also turn off default mirroring by calling SetProcessDefaultLayout(0).
There is also a way to query the current default layout direction: |
|
| After returning successfully, pdwDefaultLayout contains LAYOUT_RTL or 0.
There is no way to specify that a window must have standard LTR layout, but the default is for all windows to lay out LTR. If you want to give RTL layout to only some windows, create those windows with WS_EX_LAYOUTRTL | WS_EX_NOINHERITLAYOUT. In localizing system applets for Arabic and Hebrew Windows 98, the Arabic and Hebrew Windows 98 development team found that a good approach is to first try calling SetProcessDefaultLayout(LAYOUT_RTL) in WinMain before any call to CreateWindow, and then test if there are any problems with the display of some windows. If there are clearly some windows that shouldn't be mirrored in a particular application, you should back out the call to SetProcessDefaultLayout and instead call CreateWindowEx with extended styles WS_EX_LAYOUTRTL | WS_EX_NOINHERITLAYOUT on every window that is to be mirrored. In some cases, every child window under a particular parent should be mirrored, so allow inheritance—that is, only set the WS_EX_LAYOUTRTL style. But what if the user changes the user interface language of an existing window from Hebrew, say, to French? The window was created as a mirrored window because the interface language was Hebrew, but you need to turn off mirroring for the new interface language. The answer, of course, is to use SetWindowLong to modify the extended styles. Here is a snippet from the sample code that turns mirroring on or off as needed: |
|
|
The mirroring described previously applies to all objects in a standard window; bitmaps and icons in a mirrored window are also mirrored by default. Obviously, there are some graphic objects, particularly those including text, that shouldn't be mirrored, such as the MSN™ icon in Figure 5. Therefore, Microsoft provides the following GDI functions in platforms that support mirroring: |
|
|
The device context of a mirrored window is mirrored by default. You can disable mirroring in a device context by calling SetLayout(hdc, 0), and activate it by calling SetLayout (hdc, LAYOUT_RTL). To inhibit mirroring of bitmaps, call SetLayout with the LAYOUT_BITMAPORIENTATIONPRESERVED bit set in dwLayout: |
|
|
Upon successful completion of GetLayout, it returns a DWORD indicating the layout settings of the device context by the settings of the LAYOUT_RTL and/or LAYOUT_BITMAPORIENTATIONPRESERVED bits. So far I've addressed standard windows that an application creates via CreateWindow or CreateWindowEx, but not dialog boxes or message boxes. To mirror a message box, include the option MB_RTLREADING in the call to MessageBox or MessageBoxEx. To lay out a dialog box RTL, use the extended style WS_EX_LAYOUTRTL in the dialog template of the .RC file. Property sheets are a special case of dialog boxes; each tab is treated as a separate dialog box, so you need to include the WS_EX_LAYOUTRTL style in every tab that you want mirrored. This extended style is also supported in the dialog editor of Visual Studio® 6.0. See the file RES401.RC in the sample code for an example of how to use this extended style in a dialog box. (There is a bug in the original release of Visual Studio 6.0. The dialog editor writes the symbol to the .RC file as WS_EX_LAYOUT_RTL rather than WS_EX_LAYOUTRTL. This should be fixed in a future version of Visual Studio.) As mentioned earlier, the mirroring APIs made the RTL layout of Arabic and Hebrew Windows 98 almost automatic. However, there were some coding practices that caused bugs in mirroring. The biggest problems surfaced when mapping between screen coordinates and client coordinates, or failing to do so. For example, developers often use code such as the following to position a control in a window: |
|
| In this code, the left edge of a rectangle becomes the right edge in a mirrored window, and vice versa, causing unintended results.
The solution is to replace the ScreenToClient calls as shown in the following code: |
|
| This works because MapWindowPoints has been modified on platforms that support mirroring to swap the left and right point coordinates when the client window is mirrored.
Another common practice that can cause problems in mirrored windows is the use of offsets in screen coordinates to position objects in a client window, where it should be using client coordinates. For example, the following code uses the difference in screen coordinates as the x position in client coordinates to position a control in a dialog box: |
|
|
This works fine when the dialog window has LTR layout and the mapping mode of the client is MM_TEXT. The new x position in client coordinates corresponds to the difference in left edges of the control and the dialog in screen coordinates. In a mirrored dialog, however, the roles of left and right are reversed. You can remove the assumption that near is left and far is right from the previous code by using MapWindowPoints to go into client coordinates: |
|
|
There is a common theme in these examples. Instead of thinking in terms of the concrete notions of left and right, developers should abstract those concepts into near and far. Here are some specific guidelines on developing applications that can be mirrored by using the automatic mirroring interfaces:
The Sample Code In exploring the coding techniques to this point, you've already seen the relevant portions of the sample code. Nevertheless, there are a few points left uncovered that I'll explore now to make the code more understandable. One question I've already been asked before this article was published is why the sample is written in straight C using the Win32 API directly, rather than in C++ with a popular class library such as MFC. The answer is that there are still people who program in straight C, and this sample code is meant to illustrate the concepts for all Win32 programmers. Also, keep in mind that this sample cannot serve as the starting point for anything but the simplest application, so anyone who wishes to implement these techniques will have a lot of work to do in any case. Looking at the code, you'll notice that I use three structures throughout to avoid the use of global and static variables (although I don't avoid them entirely). PLANGSTATE is for storing global information about language and locale, typedefed in UPDTLANG.H: |
|
|
PAPP_STATE is for global data specific to this sample application, typdefed as follows in UMHANDLERS.H: |
|
| There is also a general struct, GLOBALDEV, whose only two fields are pointers to the previous two structs, typedefed in UMHANDLERS.H: |
|
|
WinMain preserves state between calls to WndProc in an instance of GLOBALDEV, *pGlobalDev. When it calls CreateWindowEx, the initialization code in WinMain passes pGlobalDev to the WM_CREATE window handler OnCreate, which initializes the main window's user data to pGlobalDev using SetWindowLongA(hWnd, GWL_USERDATA, (long) pGlobalDev). Afterward, WndProc always sets its own copy of pGlobalDev to point to the same location using GetWindowProcA. The Windows message handlers can all be found in the file UMHANDLERS.CPP. Following a popular convention, the names of the message handlers are of the form OnMessageID, where MessageID is the message identifier (leaving off WM_). For example, the handler for WM_CHAR is OnChar. The prototype of the messages handlers are of the form: |
|
| I use the last argument to pass one of the state structures, as needed, for use in processing the message.
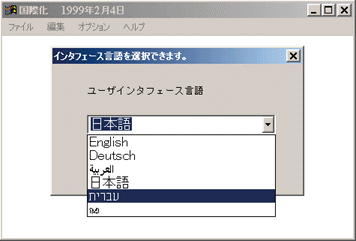
The complete source code can be found here. To use the sample code, first copy the file GLOBALDV.EXE into a directory, say GLOBALDV, and all resource DLLs (of the form RES*.DLL) into a subdirectory called RESOURCES directly under GLOBALDV. If you're running Windows 95 or Windows 98, you must also copy UNIANSI.DLL into GLOBALDV. Next, start the main executable GLOBALDV.EXE. If all goes well and you are running on an English language platform, you should see a window whose title is "GlobalDev (U.S. English)," followed by the date. If the user interface of your platform is one of the supported languages (currently Arabic, German, Hebrew, Hindi, Japanese, Tamil, and U.S. English), both the title and the other user interface elements will be in that language. Now go to the Options menu and choose Interface Language (or the equivalent in another language). You'll see a dialog box that includes a combobox to allow you to choose one of the supported user interfaces. If running on Windows 2000, you'll see the name of each language in the language itself, as shown in Figure 6, where the main interface language is Japanese. On Windows 9x you'll also see the list of languages, but only those that can be displayed in the system code page will appear. |
 |
|
Figure 6 GLOBALDV in Japanese |
By the way, if you are running Windows 2000 and you don't see each of the language names correctly, you can go to the Regional Options control panel applet and install the missing language groups. The language groups are listed in a panel at the bottom of the main tab of the Regional Options applet, and those that are already installed will have a check in the checkbox.
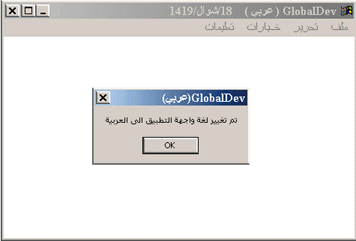
If you are running Arabic or Hebrew Windows 98 or Windows 2000, try changing the user interface language to either of those languages. You should see the new user interface with RTL layout, as shown in Figure 7. Notice that the light source of both the main window and the message box is on the upper right, as you'd expect with RTL layout.
 |
|
Figure 7 Changing Interface Language |
Going back on the main window, type in some text. Now change the input locale by typing ALT+SHIFT or by choosing the input locale indicator on the system tray. (If you only have one input locale installed, you can install others using the Regional Options applet.) If you're running on Windows 2000, try out some of the other options, such as changing fonts, using an edit control, and so on.
If you have a Windows 95 or Windows 98-based system available, copy the files to it and try the same features as when running on Windows 2000. You'll notice that everything works more or less as before, with the exception that unsupported languages will not be displayed. You'll be able to choose fonts, change input locale, use an edit control, and type text. This may not look very exciting, but keep in mind that all strings are stored in Unicode internally, and that the application is converting to and from Unicode whenever it makes use of these system calls.
Conclusion
As I've shown, the best way to take advantage of these multilingual user interface features is to use Unicode to encode text in your Win32 application. I've explored a technique to allow you to use Unicode in your Win32 application and still run the same binary file on Windows 95 and Windows 98. I encourage you to seriously consider using Unicode as your text encoding, either by using this technique or one of the other techniques outlined in this article. You'll be able to easily implement other techniques to create software that meets the language and locale needs of all your customers throughout the world.
|
For related information see: Roadmap to Windows Installer Documentation at http://msdn.microsoft.com/library/psdk/msi/leglivt_5bxq.htm. Also check for daily updates on developer programs, resources and events. |
|
From the April 1999 issue of Microsoft Systems Journal
|