June 1999
![]()
| Exposing Your Custom Data In a Standard Way Through ADO and OLE DB |
| OLE DB is a COM-based technology that serves a double purpose. The first purpose is to replace the glorious old ODBC layer, extending the same open connectivity metaphor to nonrelational data sources. OLE DB also promotes the use of COM in the land of databases. |
| This article assumes you're familiar with database programming and ATL |
|
Code for this article: oledb.exe (172KB) Dino Esposito is a senior consultant based in Rome. He works for Andersen Consulting and authored Visual C++ Windows Shell Programming (WROX, 1999). You can reach Dino at desposito@infomedia.it.
|
|
Wouldn't it be great if all the databases across the globe spoke the same language and exposed their data in the same manner? Likewise, wouldn't it be better if all the documents could be stored, or simply expressed, through a universal language? But until the Internet came along, these wishes conflicted with vendors' interests.
The Microsoft offerings in this regard are XML and OLE DB. XML is part of the storage engine employed by Office 2000 to natively publish documents on the Web. OLE DB is the underpinning of the Universal Data Access (UDA) strategy that is central to the Windows® DNA architecture. The popularity of ActiveX® Data Objects (ADO) and OLE DB means that you are finally getting a standard way to access data. Let's examine how OLE DB providers and consumers help you to mix traditional databases and custom data sources such as email messages in Visual Studio®-based applications, Microsoft® Internet Explorer, and SQL Server™ 7.0. In this article, I'll face a problem that should be familiar to many developers: how to expose custom and proprietary data formats through a common and standard programming interface. The key structure to UDA is the ADO recordset, which is a data structure built on top of OLE DB's rowsets. I'll discuss three ways to pack your data into recordsets in such a way that they can be successfully handled later via OLE DB and ADO, and published in Visual Basic®, Visual C++®, and Web-based applications.
Understanding UDA and OLE DB OLE DB is a COM-based technology that serves a double purpose. It is intended to replace the glorious ODBC layer, extending the same open connectivity metaphor to nonrelational data sources. It also promotes the use of COM in the land of databases. With OLE DB, the data management tasks are performed by two classes of components: providers and consumers. Don't let these new names scare you. They are just context-specific replacements for "server" and "client," respectively. An application that is OLE DB-compliant normally works as a data consumer; it connects to the data source, issues a command, and gets a recordset to play around with later. There are different ways to obtain such a recordset. You could utilize raw C++ and deal with pointers to COM interfaces. A better way is to use the ATL 3.0 template classes or the ADO layer from wherever you're coding (Visual Basic, Visual J++®, or ASP). The result doesn't change, though; you always get a collection of data structures that map the schema of the data source. Writing a consumer application means talking to any storage of computer data through the language of COM. A consumer program will expect the provider of choice to support a number of COM interfaces. It just has to deal with them, ask to open the archive, and get data back in a tabular format. No matter how the source data is stored, an OLE DB provider must always manage to render it as a collection of homogeneous records. For example, it's relatively easy to expose the content of a Microsoft Excel document this way because a spreadsheet has inherently tabular content. It'd be much more difficult to return a Word document as a recordset. An OLE DB provider is required to implement a number of interfaces, though not necessarily all those defined by the OLE DB reference. What's important is that the provider exposes the set of functionality that best reflects the data it handles. An OLE DB provider should manage the following objects: DataSource, Session, Command, and Rowset. They form a hierarchy as shown in Figure 1. (The COM interfaces mentioned in the figure are the most relevant, but not the only ones a provider must support.)
DataSource is the root of the tree and represents the channel through which it's linked to the physical data store, be it a SQL Server table, a Microsoft Excel document, or the Outlook® Inbox folder. It provides the consumer with the means to create a Session object. A session here is just a standalone transaction with the data store. In a certain sense, the DataSource represents the logical channel to the source, whereas the Session is the physical link. The Session object instantiates the queries to execute. A DataSource object can handle simultaneous sessions to the same data store. The Command object asks the provider to do what it is supposed to do. A command can be a SQL query, a stored procedure, or a string written in syntax that the provider recognizes. Finally, the Rowset is what a command produces: a table of data with a number of rows and columns. Each column is composed of homogeneous data. Not all providers support the same number of features. The OLE DB reference material states that a COM module that wants to act as a provider must support at least the DataSource, Session, and Rowset objects. The Command object is not strictly required. This minimal configuration includes the COM interfaces described in Figure 2. Before going any further, let me address how OLE DB stands with respect to ODBC, and why the need for custom OLE DB providers is far stronger than for custom ODBC drivers. Both OLE DB and ODBC are aimed at simplifying data access across multiple platforms. ODBC, though, works primarily with relational data accessible through SQL, even though it can read other sources such as flat text files. An ODBC application sees a common programming interface despite the underlying database management system (DBMS) and could target different DBMSs with the same layer of code. (This is not always true in the real world, since not all DBMSs support the same SQL language beyond the Entry level of the SQL-92 standard, but this doesn't make the statement generally less true.) The module that takes care of linking the application to the chosen DBMS is an ODBC driver. All the installed drivers are governed by the Driver Manager (odbc32.dll). ODBC copies the data it gets from the database directly into an application's memory area, which is identified by an hEnv environment handle. Instead, OLE DB fills out a shared object that is an independent entity with respect to the data source and the caller (see Figure 3). The presence of such an object allows, for example, multiple client components to work on the same data at the same time. Furthermore, there's no requirement for the OLE DB consumer to get and maintain an explicit connection to the data source. The Rowset object in the middle ensures that the data will be retrieved (via a hidden and temporary connection) and managed by a standalone object that takes care of concurrent access, state, changes, scrolling, and whatever. This allows the consumer to continue working in an environment that doesn't maintain a connection with the source. |
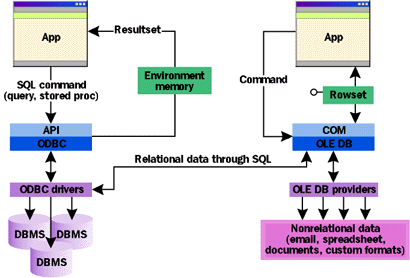 |
| Figure 3 ODBC Versus OLE DB Data Access |
|
ODBC and OLE DB seem similar, as in the global approach to data retrieval, but they're very different as well. First and foremost is the presence of COM. The OLE DB object hierarchy is simpler, thinner, and less dependent on the physical structure of the data store. This opens up a new world of opportunities to ISVs. OLE DB is the means to expose any kind of data that can be expressed in terms of rows and columns. The modules that do this are OLE DB providers, distant relations to ODBC drivers. They are components with the task of reading data from any source and packing it into a common format exposed to consumers. The consumers will read it through elements called accessors. An accessor is a data structure (typically C++ classes or a user-defined struct) mapping how to unpack each row of data into its fields to allow easier manipulation. Normally you don't need to write an ODBC driver for a DBMS because, in most cases, the DBMS vendor already provides it. Instead, there are many more opportunities for OLE DB providers. Literally every bit of data you can find could be exposed via OLE DB—from the content of a file system directory to the resources of an active directory service, from a Microsoft Excel spreadsheet to your Inbox email folder, from registry contents to the list of the running processes. Even if OLE DB evokes the idea of a persistent data store, nothing prevents a provider from getting the data to return from the system memory, as in the case of the list of running processes or opened windows. The Role of ADO OLE DB is not replacing ODBC. Rather, OLE DB uses ODBC technology on a more versatile architecture and a more general hierarchy of objects. There are two main approaches to consider. You can migrate all the data, relational and nonrelational, into a fixed format and storage (say a new, unique, all-encompassing DBMS server). Alternately, you can leave the data unchanged but build an extensible layer of code on top of it for universal application access. As far as I can see, efficiently integrating legacy data and applications with modern tools and architectures is one of the key problems for the future. ADO is the recommended programming interface to develop applications that act as OLE DB consumers. As explained in my article "With Further ADO: Coding Active Data Objects 2.0 with Visual Studio 6.0" (MSJ, February 1999), ADO is an object model that includes all the features of RDO and DAO, plus additional functionality. Through ADO you can still issue SQL queries as you did working with ODBC; in fact, Microsoft provides a generic OLE DB provider for ODBC (MSDASQL) that simply works as your old ODBC-compliant applications expect. For compatibility, this is the default OLE DB provider within ADO. Figure 4 shows three possible ways in which an application can access a relational database server.
|
 |
| Figure 4 Database Access |
|
As you can see, the third solution (which is the default in ADO) is also the least efficient since it requires you to pass through an additional layer of code. In fact, MSDASQL is an OLE DB provider that accesses the data store via direct ODBC calls. You can get the same result via RDO or ODBCDirect, without MSDASQL. Of course, the pure and ideal solution from the ADO point of view is leveraging a database-specific OLE DB provider that exploits native calls for data collection. This approach is not always practical today since OLE DB is a relatively new technology and can't rely on a very large number of trusty and reliable providers. It's not unusual these days to discover that a provider doesn't support a certain operation. Thus, in most cases, you need to resort to the pure ODBC approach. Despite all this, however, ADO is certainly destined over time to supersede any other object model for accessing data. One part of its architecture deserves further comment: ADO doesn't do data access on its own. Never. ADO is heavily dependent on what the underlying OLE DB providers do, bad and good. Many of the undesirable behaviors you run into with ADO are due to bugs or incorrect provider usage. This doesn't mean that the ADO objects are perfect, but don't forget that they are the topmost tier of a three-level architecture; ADO deals with commands but actually does not retrieve rows of data. ADO exposes a collection of objects that map pretty well to the OLE DB interfaces and methods. The key ADO object is the recordset, a high-level representation of the tabular data retrieved by the provider. A recordset can be scrolled, saved, and loaded from the local disk, and scanned for a precise row. It's a very flexible data structure that can be passed to many data-bound controls to get a quick display. With ADO 2.0, it's now possible to create connectionless recordsets, which are recordsets that your application creates by filling the rows with custom information. In other words, ADO 2.0 allows you to consider the recordset as a native user-defined type supported by various development tools. Creating connectionless recordsets with Visual Basic to expose custom data is perhaps the simplest way to begin walking the road to full-fledged OLE DB providers. In the meantime, Figure 5 lists the OLE DB providers you should have after installing the Microsoft Data Access SDK 2.x and SQL Server 7.0. A Pseudo-provider To start off with OLE DB providers, I'll use something that is not a real provider. In fact, it's a simple component that returns data through an ADO recordset. Using the newest features of ADO, you can create your own recordsets, add columns and rows, and fill them with the same logic you employ with multidimensional arrays. This is a snap, especially if you're using Visual Basic or Visual J++. Given this, you can write a layer of code to access the data and then return a recordset object. Figure 6 shows a Visual Basic code snippet that creates a recordset from the emails contained in the Outlook Inbox folder. Once you've converted the data into an ADO recordset, you can immediately start exploiting the power of several databound controls, such as datagrids. With the advent of ADO 2.0, recordsets seem poised to become a pretty universal data structure to marshal information across components. Recordsets are self-describing structures formed by a collection of columns. The number and type of the columns may vary quite a bit depending upon the data to be rendered. For the purpose of this article, I've written a Visual Basic-based ActiveX control called ReportView that takes an ADO recordset and displays it, adding to the view as many columns as needed. ReportView is derived from a listview with the Report style. I'll be using it throughout the examples here. |
|
| The code above demonstrates how to get and display a recordset with all the Outlook messages. This is the simplest way to expose your custom data through an ADO-compliant interface; just figure out a tabular format to render the data and most of your work is finished.
Visual Basic Data Source Classes Since the first example was in Visual Basic, let's continue working in this environment for a while. Figure 6 presented a set of global Visual Basic subroutines that do the job of retrieving information and recordset formatting. There's a better way, however, than using functions from a .BAS module: creating a class. When you ask the Visual Basic 6.0 IDE to add a new class module to the project, you are prompted with a range of different types of classes, among which the DataSource Class option clearly stands out. A data source class is an ordinary Visual Basic class where the DataSourceBehavior property defaults to vbDataSource (which equals 1). This setting makes the class work as a data provider. As soon as you assign the vbDataSource value to the DataSourceBehavior attribute, the Visual Basic IDE adds the handler for a new event, GetDataMember: |
|
| This event is meant to return an ADO recordset to the caller through the Data argument. And who's the caller? A data consumer class; that is, a Visual Basic class with the DataBindingBehavior property set to vbSimpleBound or vbComplexBound.
There's an important change with Visual Basic 6.0 for a control's data binding. In the past, when using data-bound controls, you were forced to establish a direct link between the control and the data source. This results in a pretty inefficient two-tier schema that clashes with modern real-world systems, which are mostly three-tiered with a thick layer of business objects in the middle. From a higher level of abstraction, it also clashes with the Windows DNA specification which recommends that COM-based middleware go straight to the data. Visual Basic 6.0 lets data consumers be bound literally to anything that can expose data. So the next step is building an ActiveX DLL, making it a data source, and adding some code to create the recordset to expose. Figure 7 shows a Visual Basic data source class that provides the paragraphs of a given Word document as a single-column recordset. The DataMember argument is filled with the name of the Word document to open. There are a couple of items worth noting. First, in the code I'm creating the recordset each time the consumer asks for the data. This might not be particularly efficient since the recordset's (re)creation is accomplished repeatedly. On the other hand, this ensures that any change to the data is detected soon. Furthermore, since the consumer may request different types of data (data members), you don't have to maintain multiple recordsets. Of course, do what you think is better for your own business. The second note is in regards to the three-tier design of the overall schema: the data consumer, the data source class, and finally the data store. I've based the sample on Word documents just to demonstrate that now you can use, say, a datagrid control to show virtually everything. |
|
| In addition, consider that the ADO 2.0 hierarchical recordsets also allow you to publish structured data through a specialized grid such as the Visual Basic 6.0 MSHFlexGrid control.
OLE DB Simple Provider With data source classes you have COM objects capable of returning recordsets with data coming from anywhere: a DBMS, proprietary files, or even system memory. This is a fast way to write data-aware components that can encapsulate a data source. However, the interface between the provider and its consumers is very simple. Basically, it consists of the sole DataSource interface. (Check the Visual Basic data source class with the OLE Viewer.) |
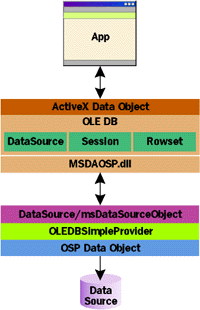 |
| Figure 8 OLE DB Simple Provider |
|
A data source class is not a real OLE DB provider, but a simpler component that makes data available externally. What is a data source class missing to be a full-fledged OLE DB provider? The answer is shown in Figure 8, where the architecture of the OLE DB Simple Provider (OSP) is depicted. OSP is a toolkit that originally shipped with Internet Explorer 4.0. It is composed of a DLL (msdaosp.dll), a few type libraries, and a number of examples written in different languages, including C++, Visual Basic, and Java. Basically, it provides you with a generic layer of precompiled code to properly communicate with any OLE DB consumer. It exposes three interfaces for the minimal OLE DB support: DataSource, Session, and Rowset. Behind these interfaces there are many methods to code, but the toolkit does most of the work for you. Your only task is writing a COM object that looks like a Visual Basic data source class. Such an object is said to be an OSP Data Object. As Figure 8 shows, however, there's a bit more. An OSP Data Object actually implements the OLEDBSimpleProvider interface, which summarizes 14 functions that span from data retrieval to updating and from row counting to searching. These functions alone don't constitute a valid OLE DB interface, but with the help of msdaosp.dll, an OSP is a legitimate provider whose registered server is always msdaosp.dll. How is the link between msdaosp.dll and your specific OSP Data Object established? Through the registry, of course. While registering the data object you should set the default entry of |
| to the ProgID of your OSP component. This ensures that msdaosp.dll can get in touch with it via the services of the DataSource interface, which returns a recordset against a data member name. A data member is usually what you pass through the first argument of the recordset's Open method. It identifies the source of the data and could be a SQL-like command or, more likely, a file or folder name.
OSPs have good and bad aspects. They let you easily write small providers with a significant number of features such as data change and searching. The fairly simplified programming interface also makes it possible to write OLE DB providers using languages like Visual Basic or Java. One drawback is that OSPs aren't extensible since all of the exported functionality is coded once and for all into the OLEDBSimpleProvider interface. In addition, they don't support commands. This means that such providers are useful for rendering data and don't require complex queries. Full documentation for OSP is available through MSDN™.
ATL Templates for OLE DB Before Visual C++ 6.0 and the newest ATL, OSP was the only simple way to write providers, albeit with the limitations mentioned. With the advent of ATL 3.0 you're given a new choice: using template classes for providers and consumers. The initial steps to create an OLE DB provider are the same as those for any COM server. After starting an ATL COM project (using the ATL COM Wizard), add a specialized ATL object. The wizard-generated code is already a valid and functional provider that makes available the files that match a given file specification as a recordset. If you name your object FileSystem and simply build the project, without any further changes you obtain an OLE DB provider that works this way, |
|
| returning all the files found in the C: root path. Figure 9 shows its input. As you can see, the rowset looks the same as a WIN32_FIND_ DATA structure. Let's examine the code before customizing it. |
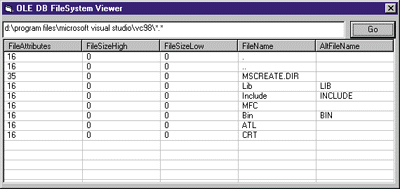 |
| Figure 9 OLE DB FileSystem Viewer |
|
The wizard creates the eight different classes described in Figure 10. To understand the steps of a transaction between a provider and a cons umer, take a look at the raw C++ examples available with the Platform SDK in the Database/Messaging area. Here, I'll skip over some details, instead focusing on the higher-level functionality provided by ATL classes. A significant change observed with OLE DB (as opposed to ODBC) is in the area of property management. Properties are object attributes that help consumers know about the characteristics of a provider. Properties are also a means for a consumer to tailor and refine its requests. In OLE DB, a property always belongs to a property set, which is identified by a GUID. Furthermore, each property gets its own unique ID within the property set. Property sets are provider-specific and any OLE DB provider can define new property sets. ADO exposes OLE DB properties through the Automation properties of the high-level objects: Recordset, Connection, Command. You can set multiple properties with a single call by filling an array of DBPROP structures and exploiting the DataSource's IDBProperties interface. An ATL OLE DB provider declares the properties it supports through the BEGIN_PROPERTY_SET macro. |
|
| Inside the macro, PROPERTY_INFO_ENTRY is used to declare the ID of the property that belongs to that property set. By using slightly different macros, you can also assign a value or a flag.
In the wizard-generated file that manages sessions, three classes are worth taking a closer look. Their names contain the SchemaRowset suffix, and they are passed as an argument to the SCHEMA_ENTRY macro. |
|
| OLE DB utilizes schema rowsets to provide consumers with information about the data it manages. Usually referred to as metadata, this information can be obtained without directly accessing the data store, but by simply interrogating the provider. A schema rowset is a type of database record that provides not just a row of data, but a row of information about the structure of the data source. The layout of the schema rowset is predefined and depends upon the type of information required. Predefined rowsets let you obtain descriptions of the available tables, columns, supported data types, views, indexes, and more.
A schema rowset is identified by a GUID, the DBSCHEMA_XXX constants used above. The ATL macros map all the schemata to classes that derive from CRowsetImpl and templatize on the Session class. |
|
| Such classes have an Execute method to do the job. |
|
| Here, CTABLESRow is the structure that binds to the rowset's columns and that's returned to the consumer.
Similar structures exist also for columns (CCOLUMNSRow) and types (CPROVIDER_TYPESRow). You won't see these classes in the MSDN documentation. However, they are defined in the atldb.h header file. Here's how to get schema information for a provider: |
|
| The following code snippet is excerpted from CFileSessionTRSchemaRowset::Execute, as the wizard generates it. |
|
| In front of this code, the schema returned through the ADO OpenSchema function consists of a one-row record- set as shown in Figure 11. As you can see, the structure of such a recordset is predefined in the OLE DB SDK and maps to the fields of the CTABLESRow structure. |
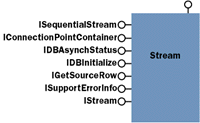 |
| Figure 11 Schema Recordset |
|
The FileSystem OLE DB provider, though simple, gives a clear understanding of what you can do with OLE DB: expose any kind of data, despite its actual storage medium, in a standard COM-based way, exploiting a unique front-end interface (ADO). Given this, a program to query for all the Word documents created by a given author or all the messages received by a customer is not far-fetched.
An Outlook OLE DB Provider Many technical papers about OLE DB consider email messages typical of the kinds of non-SQL-based information you might want to handle. Email messages could be joined with fields coming from regular SQL databases or filtered via SELECT commands. Once you grasp the essence of OLE DB, this is quite obvious. But still, there's no demonstration of it anywhere. So let's try to design and implement an OLE DB provider for email messages. Once more the ATL COM Wizard provides the basic functionality of the component, while the Insert|New ATL Object command enriches the project with OLE DB provider specific files. The progID of such an Outlook provider is MailProvider.Outlook.1. As for the files created by the wizard, I left unchanged the DataSource object (OutlookDS.h) and simply modified the Session schema rowsets to add a Messages table with a decent description. All the changes are concentrated in the OutlookRS.h file, which produces the rowset. The first thing to figure out is the row. In this case, the row is given by an email message. In principle, all the fields of an email message should be a column in the final rowset. However, for the sake of simplicity, I limited the rowset to just four columns: sender, address, subject, and time of receipt. The accessor structure looks like this: |
|
| The TCHAR buffers render the memory space where each row will be stored after being extracted from the data source. The COutlookMessage class is a transfer buffer that moves records from the data store to the consumer's recordset. The bindings between the accessor's fields and the database columns are coded within the provider column map. Each PROVIDER_COLUMN_ENTRY assigns a name to the column, its ordinal number, and the name of the linked member. Pay attention to this macro. It doesn't say anything explicit about the type of the column or about its size. Nevertheless, these are two important attributes.
If you look at how such a macro expands in atldb.h, you'll notice that it assigns to the column the type of the data member as returned by the inline function _GetOleDBType (see atldbcli.h, always in the Atl\Include folder of Visual Studio 98). It also sets the size to the number of bytes the member requires. And it turns on a bit in the column's flags that states that the length of the column is fixed. This wouldn't be a problem if you weren't using strings. In fact, normally a string has its own length that is less than the amount of space it occupies. So you turn out having a column content of, say, 20 bytes and a fixed column size of, say, 50 bytes. As I'll show you later on, this can be source of headaches when managing an OLE DB provider under SQL Server 7.0. If you plan to put variable length strings inside a column, remember to bind using PROVIDER_COLUMN_ENTRY_ STR or with the final WSTR if you're manipulating Unicode content. |
|
| This ensures that the type is DBTYPE_STR, the fixed-length flag is turned off, and no default size is defined.
Having done this, all that remains is to implement the procedure that actually reads and returns data. This will occur within the COutlookRowset::Execute method shown in Figure 12. To access the email messages, I'll use the Simple MAPI functions to walk the content of the Outlook Inbox folder. The Simple MAPI SDK provides a couple of functions to do this. MAPIReadMail fills in a structure with all the details about the message, from recipients to attachments. MAPIFindNext manages a pointer for selecting successive messages. Despite the apparent simplicity, making them work properly is a bit tricky. The first thing to consider is that MAPIFindNext always moves its pointer to the closest message with a given seed. To move to the first absolute message just zero the seed string. |
|
| Each message has its own msgID that MAPIFindNext loads and returns. The msgID is necessary to identify the message that MAPIReadMail will read. To get the next message you should use the current msgID as the new seed. |
|
| It's possible to get the messages in the order they arrived and also obtain only a subset of the information available for each message. To use Simple MAPI it's necessary that you log on. MAPILogon is the function to call to get the session handle to be used in all the subsequent calls.
A real OLE DB provider should also support a more or less structured query language. A good syntax for an email provider might be: |
|
| After all, the real problem is arranging a module to parse and interpret such a SQL-like language.
I think that the easiest way to add query support to your OLE DB provider is to define a string-based syntax for Command objects. In practice, the command text will be a tokenized string much like the ConnectionString of the ADO Connection object. The pseudocommand seen above could be rephrased like this: |
|
| This line searches for all the email messages that arrived after February 1, 1999, with the "MSJ" string in the subject line and that were sent by someone whose display name includes the substring "Jos".
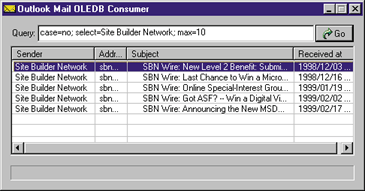
Figure 13 details the complete syntax that this Outlook email provider supports. There are six keywords that accept a value. More keywords can be concatenated in the same command string using the semicolon as the separator. The parser first analyzes the string and isolates the parameters in the command string. These parameters are stored into a custom structure called FILTERMESSAGE. This structure is completed with the data taken from any message read and is then passed to the procedure that will verify whether the current message should be added to the rowset. The scan stops when either the messages are finished or the maximum number of records requested has been reached. Here's an example of a pretty complex query: |
|
| The query selects all the messages sent last February by someone whose mail server was microsoft.com. All the messages, furthermore, contain MSJ somewhere in the subject. As for the range of dates, you can use unbound intervals as well. For example, from a certain date on (from=date) or by a certain date (from=,date). The role of the by address clause is precious, since it lets you do searching for the "select" text on email addresses instead of sender names. This is a good junction point to combine the Inbox folder with the ordinary databases of customers or contacts. (More on this later.)
Putting the Sample to Work In general, to test a server module, you should create a client and see if they can communicate with each other. With OLE DB providers, things are a bit complicated. You should do even more than check to see whether it can talk to a client. An OLE DB provider will be accessed and stressed in a number of ways: through ADO from several environments (Visual Basic, Visual J++, and ASP, to name a few), from C++ consumers, even from SQL Server stored procedures or Microsoft Access 2000. Let's verify that it works fine everywhere. |
 |
| Figure 14 Visual Basic Consumer |
|
The first test takes place in the Visual Basic environment. The demo program shown in Figure 14 uses ADO to access email. |
|
| You can take several approaches to get the recordset. The sample above passes through a Command object whose text is read from the textbox. Note that you should set both the CursorLocation and the command's active connection. To display the results, I'm using the ReportView control I mentioned earlier. Any OLE DB provider is referenced through the Provider keyword in the connection string or the Provider connection's attribute. If no provider is specified, ADO assumes MSDASQL, the OLE DB provider for ODBC. This has been done mostly to preserve backward compatibility. In fact, you didn't need a provider to access an ODBC source as you would have, say, with a previous version of ADO.
Visual Basic 6.0 also introduces a number of facilities for data access. One of these is the Data Environment (DE). In practice, it works as a central console to manage anything you can do to data at design time: connections, commands, views, and so on. DE is very comfortable even with dynamic queries, since it exposes an object model that lets you change a command before execution. DE is a resource you can add to any project built with Visual Basic 6.0. Here's how to run a predefined command where cmd_MsgsFromMS is the name of the command in the DE: |
|
| Notice that the DE user interface requires you to type the query string into the window reserved for SQL statements—it doesn't matter that there's no SQL involved at all.
The generated recordset can be made persistent to disk using the ADO Save method. You can choose among two possible formats: the Advanced Data TableGram (adPersistADTG), which is the default, and XML (adPersistXML). Notice that XML is available only with ADO 2.1. (If you're interested in rowset persistence, take a look at the article, "Rowset Persistence in Microsoft Data Access Components," by Peter Tucker, MSDN News, September/ October 1998.)
A Consumer in C++ When talking about data access, almost all the samples you can find use Visual Basic or a script-based environment. Let's go over how to write an OLE DB consumer with raw C++, not using ADO. ATL provides support for consumers as well as for providers. However, for consumers you usually have to do a bit of coding to gain the same results you'd get in ADO. A consumer is a software component that is capable of getting in touch with an OLE DB provider through a set of COM interfaces. If you're using MFC as the framework of choice, then you can embed a templatized ATL object to act as an OLE DB consumer. If you aren't using MFC, then consider ADO. Alternately, you could create a COM server that exposes a simplified interface to get and set data, or resort to a DLL-based interface. Here I'm covering what appears to be (to me, at least) the most common case: MFC and ATL together. While adding a new ATL object of type OLE DB consumer to the project, you're prompted to choose the desired provider. Choose Outlook OLE DB Provider and you won't need to set the data source or the location. Next, the wizard will show all the available tables for the data source. As seen earlier, there's just one logical table: Messages. The project is enriched with a new header file, Messages.H, that defines two classes. CMessagesAccessor is the intermediate structure used to bind the table's columns, while CMessages is the rowset class you have to deal with in your code. By default, the wizard assigns dummy names to the members that map columns: m_column0, and so on. Feel free to change them to more evocative names. The structure of the default rowset class is a bit rigid and needs some explanation. If you have no particular commands to specify, to get a rowset and fill a listview you need just this: |
|
| In Messages.H (see Figure 15), the Open method is defined to take into account only the default command that, in this case, causes the provider to return all the email messages. It ends up calling the following function. |
|
| It omits the second parameter of CCommand's Open method, which is just the command text (see the ATL documentation). To get a more flexible rowset class, you could change the declaration of CMessages, adding an argument to Open that will be passed down to OpenRowset. Alternatively, you can do in your code what's done in the header file. |
|
| This approach is more akin to ADO. Figure 16 shows the sample MFC application. |
 |
| Figure 16 MFC Consumer |
|
Did You See UDA so Far?
It took a lot of time and effort to demonstrate how to create and use an OLE DB provider. Now how can you turn the primary principle of UDA into |
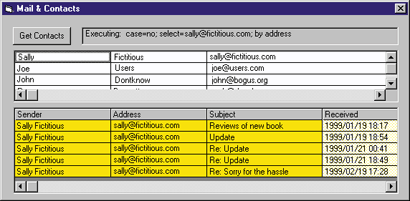 |
| Figure 17 Consuming from Multiple Providers |
| practice? In other words, can you combine different providers and build applications that span a variety of data? Figure 17 illustrates how you can. It's a Visual Basic-based application that shows a list of contacts taken from a SQL Server database. As soon as you select a name in the list (it's a MSHFlexGrid control), the program executes a query like this: |
|
| The code executes after the SelChange event. It gets the content of the email column from the contacts recordset and uses it to format a query string. Such a string will become the text of a DE command that retrieves all the emails that contact sent. Now email messages are definitely part of the enterprise data store. However, the previous application was getting a recordset dynamically for each selected name. Wouldn't it be possible to get an all-encompassing recordset that is the JOIN of the contacts database and the Outlook Inbox? Starting with SQL Server 7.0 this is possible.
A new feature of SQL Server 7.0 is the ability to define a linked server, a generic OLE DB provider that appears as an ordinary, but remote database. Using a linked server, you can refer to any OLE DB-compliant source of data across the network with the same SQL approach. A linked server has a name and relies on an OLE DB provider. A direct consequence of this functionality is that you can issue queries that get data from SQL Server and Oracle databases at the same time. A linked server, though, is something static that you must register in the SQL Server Enterprise Manager. The OPENROWSET command, instead, provides you with the same power to link servers, but is as dynamic as a keyword. |
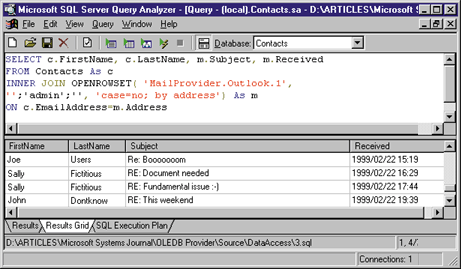 |
| Figure 18 Joining SQL and Outlook Data |
|
Look at Figure 18, where I show the results of a JOIN between the SQL Server table of Contacts and the contents of the Outlook Inbox folder. |
|
| If it weren't for the new OPENROWSET keyword, it would look like an ordinary SQL-to-SQL JOIN. Finally, a practical demonstration of distributed and heterogeneous queries involving different data types across the enterprise data store. This is the essence of UDA and OLE DB.
As you probably remember, earlier I mentioned a problem with SQL Server 7.0 and variable-length fields. The first implementation of the OLE DB Outlook Provider used the PROVIDER_COLUMN_ENTRY macro to bind columns that caused the column to be registered as a fixed-length type. Thus, when reading rows, SQL Server expected to get single fields of a well-known size, which is rarely the case with strings. As a result, I got mysterious errors due to unexpected size. Curiously, nothing of the kind was happening through ADO. Using PROVIDER_
COLUMN_ENTRY_STR fixed everything.
What About the Web? Due to the power of Remote Data Services (RDS), the Web counterpart of ADO, you can exploit this new OLE DB provider even on the Internet or a corporate intranet. So far nothing new or particularly exciting. Things get interesting as soon as you consider Dynamic HTML (DHTML) Scriptlets as lightweight but powerful objects to publish data. You can write a DHTML Scriptlet that allows you to transplant a desktop application on the Web. By exploiting the DHTML object model and the advanced features of Internet Explorer 4.0 and higher, it's easy to arrange a Web component that behaves much like the ReportView control I presented earlier. I called this scriptlet the Recordset viewer since it takes a provider name and a connection string and uses them to retrieve the data. The plumbing that allows a recordset to be displayed is the data binding. This is an Internet Explorer feature that lets you automatically assign data to some HTML tags in the same fashion as data-bound controls in Visual Basic 6.0. The bridge across the Web page and the OLE DB data source is RDS. It needs specialized components either on the client or the server side. On the client, you can use an ActiveX control that pumps data into a <TABLE>. The bindings between the recordset's fields and the table's columns are done via an HTML attribute called datafld. As a result, you can easily publish any application that uses a custom OLE DB provider on the Web (see Figure 19). |
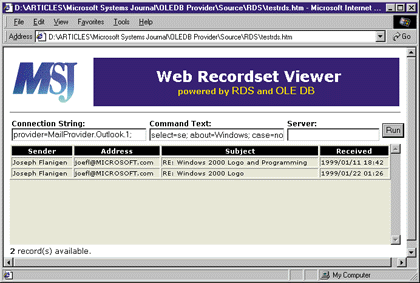 |
| Figure 19 Web-based Consumer |
|
Summary
This article is mainly devoted to showing you how to expose custom and legacy data in a standard and more manageable way. With ADO and OLE DB, the world of data access is moving toward a long-awaited standard. Curiously, the standard doesn't apply at the storage level, as it was expected to be for a long time. Instead, it applies at the level of programmatic data access. Once you understand the rules and the techniques to create standard data source modules, there's no limit to what you can do, and the tools make it even easier to integrate the various data sources.
|
|
From the June 1999 issue of Microsoft Systems Journal.
|
