November 1999
![]()
| Using OLE DB and ADO 2.5 to Represent Nonlinear, Nonrelational Types of Data |
| OLE DB is a COM object model that is defined as a set of cotypes such as Data Source or Rowset. a cotype is expressed in pseudo-IDL and simply lists the set of mandatory and optional interfaces. OLE DB can be extended by adding a new cotype or refining the definition of an existing one. |
| This article assumes you're familiar with OLE DB |
|
Bob Beauchemin works at DevelopMentor, teaching and developing the OLE DB/ADO and MTS/COM+ curriculum. Reach Bob at bobb@develop.com or http://www.develop.com/hp/bobb. (Microsoft Press, 1998). |
|
OLE DB was introduced in 1996 as part of the Microsoft® Universal Data Access strategy. The Universal Data Access strategy can be summarized as follows: data should be accessible through a common API without changing its format, replicating it to a common data store, or sacrificing performance for generic functionality. The original OLE DB specification defined data access in terms of the relational DBMS (RDBMS) paradigm of rectangular rowsets of rows and columns. This was consistent with the preceding APIs that dealt with relational databases (such as ODBC, dbLib, and DAO), and made it easy for developers who were already familiar with an existing data access API to transition to the world of OLE DB.
OLE DB is a COM object model that is defined as a set of cotypes such as Data Source or Rowset. The definition of a cotype is expressed in pseudo-IDL and simply lists the set of mandatory and optional interfaces. To allow extensibility, a provider can implement additional interfaces not specified in the cotype definition. To accommodate different types of data, OLE DB can be extended by adding a new cotype or refining the definition of an existing one. Dino Esposito's article, "Exposing Your Custom Data in a Standardized Way Through ADO and OLE DB" (MSJ, June 1999), covered the existing base cotypes and how to use them. He looked at OLE DB objects from both provider (OLE DB COM server) and consumer (OLE DB COM client) points of view. In this article, I'll discuss in detail the new cotypes introduced by OLE DB 2.5 that accommodate certain nonrelational types of data. I'll show you how to use these new cotypes and explain how they integrate with the existing OLE DB object model. While most of this article will focus on OLE DB-level access, the impact on ADO will be discussed as well. You'll see that as the OLE DB object model morphs to encompass different types of data, it comes closer to providing truly universal data access. Extensions for Tree-structured Data
|
 |
| Figure 1 Repeating Fields in a Join |
|
The OLE DB 1.5 specification addressed this problem by introducing a new type of column called a chapter column. The idea was that individual levels of the hierarchy would be represented as separate rowsets and the chapter column would contain pointers from each parent row into the corresponding set of rows in the child rowset. Figure 2 shows such a hierarchy using chapters. At the same time that chapters were introduced, Microsoft included an OLE DB service provider—which is simply a provider that gets its data from other OLE DB providers rather than a data store—called the MSDataShape provider. This provider consumes sets of rectangular rowsets and produces chaptered hierarchies, which solved the hierarchical data model problem for the time being. |
 |
| Figure 2 Chapter Hierarchy |
|
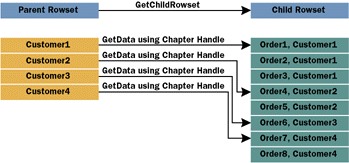
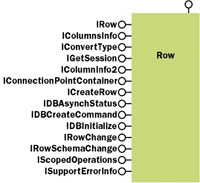
Next on the agenda was multidimensional data. Rectangular rowsets have two dimensions represented by rows and columns; multidimensional data is represented as a series of points that can be organized around many dimensions at once. Although this can be modeled as rows and columns, multidimensional query results often use more than two axes, and the performance penalty of modeling them as multiple rectangular rowsets is severe. OLE DB for OLAP (introduced as part of OLE DB 2.0) introduced the Dataset cotype that more closely represents how multidimensional data is structured and used. With the new Dataset cotype and a few other minor changes, multidimensional data was integrated into the OLE DB object model. The chapter paradigm is useful for modeling parent/child relationships in homogenous hierarchies, where the rows at a given level of the hierarchy contain the same structure and number of columns. It is not as effective for modeling heterogeneous tree-structured hierarchies where, at a given level, each node (row) may contain varying properties (columns). Examples of tree-structured hierarchies include file systems that contain different metadata (extended attributes) for each node, and data stores like Exchange where different types of data can be stored in different folder types. Tree-structured data stores have some unique requirements. First, each row can have a varying number of columns. There will often be some common columns and some extended columns. The ability to add columns to an individual row without affecting other rows in the same rowset is mandatory. Second, operations may be performed that affect every row at a given hierarchical level, for example, moving or renaming a directory in a file system (and every file in it). Third, each node consists of one main source data column (the file contents in a file system or the message in a message store), as well as common columns (file name, file size, and so on) and varying columns (extended attributes). Often the requirement is just to access the source data column directly, as in a request to open the file C:\myfile.txt and read its contents. To accommodate tree-structured data without the performance penalty of coercing it into the rectangular model (imagine a rowset containing all the possible extended attributes as columns), OLE DB 2.5 introduces two new cotypes, the Row and the Stream. The definition of these cotypes is shown in Figure 3. The Row cotype represents an individual row in a rowset (a single file in a directory of files or the result of a singleton SELECT statement in SQL). It can be fetched in the context of a rowset or by itself. a handful of new interfaces integrate the Row cotype into the existing OLE DB object design. The Stream cotype represents the source data column of such a row and contains familiar interfaces like IStream and ISequentialStream to access its contents. You can determine whether a provider supports row objects by checking the DBPROPVAL_OO_ROWOBJECT bit on the property DBPROP_OLEOBJECTS. The value of this property can be obtained by using the GetProperties method on the Data Source object's IDBProperties interface as shown here: |
|
| For simplicity, this code uses the ATL CDataSource object, which encapsulates the functionality of IDBProperties::
GetProperties.
Often what needs to be accomplished is to access the row or default stream directly, so OLE DB 2.5 also introduces a new binding mechanism based on URLs. The URL binding mechanism allows you to use a URL as a connection string without knowing which provider services the URL you are requesting. Through this mechanism, it is also possible to ask for any specific OLE DB object type directly without traversing through all the OLE DB object hierarchy (as in Data Source creates Session, which creates Rowset, which creates Row, and so on). This is accomplished by means of a new provider cotype called the Binder and a new runtime component called the Root Binder. The first provider to take advantage of these new features is the OLE DB Provider for Internet Publishing, MSDAIPP. This provider works by communicating with a Web server through either the Web Extender Client (WEC) protocol of Microsoft FrontPage® or the Web Distributed Authoring and Versioning (WEB-DAV) protocol. This provider first shipped with Microsoft Internet Explorer 5.0 and also ships with Office 2000 (it's used in the implementation of Web Folders) and Windows® 2000. The Internet publishing provider has unique features geared toward team development, version control, and working while offline. I'll use this provider as my vehicle to explore OLE DB 2.5 extensions. While occasionally I will address some provider-specific behavior, the overall architecture can be generalized to other OLE DB 2.5-aware providers. Inside the Row Object
|
 |
| Figure 4 The Row Object |
As it turns out, there are many different ways to get a Row object—this
is OLE DB, after all. In previous versions of OLE DB, Rowsets were typically acquired by calling IOpenRowset::OpenRowset on the Session object or by calling ICommand::Execute on the Command object. These two methods have been overloaded to now return either Rowsets or Rows. The OLE DB Session object is often used as a factory object for the Rowsets and Rows. The Session object's implementation of IOpenRowset::OpenRowset determines which cotype to return based on the requested interface. If a Row-specific interface is requested (for example, IRow), then a Row object is returned. If a Rowset-specific interface or an interface that is part of both Rowset and Row is specified, a Rowset object is returned instead. You can also force a Row object to be returned by setting the initial property set's DBPROP_IRow property to VARIANT_TRUE.
|
| You can also execute a Command that returns a Row using ICommand::Execute. As with OpenRowset, you indicate your preference for a row by asking for an interface that is specific to the Row object. This would be useful in a SQL scenario for SELECT statements that return a single row. In some DBMSs, it is much more efficient to fetch a single row than to fetch a rowset containing a single row.
Getting a Row via IOpenRowset::OpenRowset or ICommand::Execute is useful for singleton select-style scenarios. To accommodate collections of rows, the existing Rowset object can now provide access to individual rows either via the new Row object or via the traditional accessor-style binding. You can get a Row object from a rowset using the Rowset's IGetRow interface as shown in Figure 5. This works, but is an awful lot of overhead to bind to a single row, especially considering the fact that code for creating and initializing the initial Data Source and Session objects is not shown here. To optimize traversal into a provider's object hierarchy, OLE DB 2.5 allows you to do direct binding to the object of your choice, rather than always explicitly instantiating all of the intermediate objects in the hierarchy. Depending on how the provider is implemented, the cost of building the intermediate object model may be bypassed. OLE DB provides a Root Binder object that can be used to bind to a provider's object via its name. The following illustrates how to use the Root Binder to attach to a Row object from the MSDAIPP provider. Row Operations
|
 |
| Figure 11 The Stream Object |
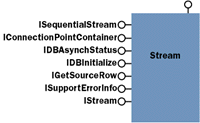
While IStream is an optional interface, it is required if the Stream object is to be usable by ADO. To get a Stream object from the Row object, read its contents, and print the contents as a string, you can use the following code. The buffer is set up with ANSI documents. Stream objects can be ANSI or Unicode.
In a tree-structured data source, some rows may represent terminal leaf nodes in the tree, while other rows may represent intermediate nodes with subrows. Because this model maps onto so many common scenarios (such as Web sites, file systems, and MAPI message stores), OLE DB formalizes this concept by characterizing such providers as Document Sources. a Document Source provider returns rows with a set of columns known as the Resource Rowset columns. These are required columns and are listed in Figure 12. The value of the column RESOURCE_ISCOLLECTION field will be set to VARIANT_TRUE if the row represents a folder. The Internet publishing provider (MSDAIPP) is a Document Source provider. Given the nature of a Document Source provider, you would like to be able to do operations like rename and move an entire folder tree, as well as list the documents contained in a folder. The easiest way to list documents is to open a rowset on a Session object that points to a folder. All the documents and subfolders in that folder will be returned as rows in the rowset. |
|
If you happen to have an existing row that points to a folder, you can enumerate its children using the IScopedOperations interface. IScopedOperations allows you to perform operations on all the child rows in one call. The correct way to list folder contents is by calling IScopedOperations::OpenRowset.
|
| The Copy, Move, and Delete methods do what you would expect, but take a special bitmask (dwMoveFlags is shown as an example in Figure 13). This allows fine-grained control over behaviors such as whether links will be updated and whether moving or copying all the existing folders and documents will be done as an atomic operation. Since these methods perform multiple operations, Copy, Move, and Delete return arrays of status fields that allow you to determine exactly what happened. You can determine whether a provider supports scoped operations against Row objects by checking the DBPROPVAL_OO_SCOPED bit on the property DBPROP_
OLEOBJECTS.
Direct Binding
|
 |
| Figure 14 The Binder Object |
|
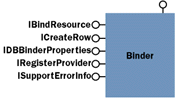
There are two types of Binder object, one that is implemented by your provider and one that is provided by the OLE DB runtime, called the Root Binder. Similar in concept to the root enumerator (which simply lists all the providers and provider-specific enumerators that are registered), the Root Binder has the smarts to look at a URL, determine which provider services that URL, and call that provider's Binder object. The Root Binder passes along the URL (and any properties you give to it), and it is up to the provider's Binder object to retrieve a pointer to the specified interface on the object of your choice. In this release, the Root Binder knows which provider to call by looking for mappings in the registry under HKLM\Software\Microsoft\DataAccess\RootBinder. This registry
key contains mappings of URL prefixes to providers. Providers claim their part of the URL namespace by calling IRegisterProvider::SetURLMapping during provider installation. Currently, each prefix can only be registered to a single provider.
The OLE DB Provider for Internet Publishing registers three prefixes: http and https as you'd expect, and another prefix, msdaipp, which it uses for internal administrative work. For example, the URL msdaipp://editedoffline returns a rowset of items that have been edited offline. The Internet publishing provider can use this list to synchronize documents between offline storage and a Web server through a special interface that it implements on the Row object, ISynchronizeRow. Your provider registers the URL prefixes it wants to support by instantiating a Root Binder object and calling IRegisterProvider::SetURLMapping. Let's see how direct binding works in code. You've already seen an example of how to use the Root Binder to produce a Row object. Here, I'll use the Root Binder to directly instantiate a Stream object for the same document: |
|
| Note that the only difference here is that I'm asking for a Stream object instead of a Row object. You can also use the Root Binder to create a new row with ICreateRow: |
|
| After reading the documentation, I originally thought that the OLE DB object type that you wanted to create was always derived from the URL. An example would be the URL bobsprovider://myspecial-row/row, with the trailing
/row being the name of the object the user wanted. The Internet publishing provider does not do this, but if a provider writer had a reason for wanting that behavior, such a URL could be handled by the provider's Binder (it is the provider's implementation choice, after all). Providers may be required to implement and register Binder objects to be considered OLE DB 2.5-compliant. In the registry on my machine, the only other provider that appears to have implemented a Binder object is the Active Directory Services Interface (ADSI) provider, which has registered the prefixes for ldap, winnt, nds, and nwcompat. You can determine if a provider supports direct binding by checking the DBPROPVAL_OO_DIRECTBIND bit on the property DBPROP_OLEOBJECTS, using IDBProperties::GetProperties. Other OLE DB 2.5 Enhancements
ADO 2.5
|
The previous code prints this:
|
The Command or Recordset objects can still be used to open an ADO Recordset as in previous versions. When using the WEB-DAV protocol, the Internet publishing provider uses its own dialect of SQL, which supports commands like "select * from scope() where RESOURCE_
STREAMSIZE > 2048". When not using the WEB_DAV protocol, a command string is required (it cannot be blank), but any command string results in a Recordset containing all the rows. Here are two examples that get a Recordset containing the contents of a folder:
|
| The URL must refer to a folder (directory); it will not work when pointed at an individual document—just as you cannot get an IRowset pointer to an individual document through the Root Binder in OLE DB.
ADO defines new Record and Stream objects that encapsulate most of the functionality of the OLE DB Row and Stream cotypes. When you get a Record object, it is not necessary to know if you are pointing at a folder or a document, but you can find out by looking at the value of the RESOURCE_ISCOLLECTION field. If you have a Recordset (folder) object, you can get a Record object (representing a folder or document) directly from the current row in a Recordset. This is the equivalent of the OLE DB IGetRow:: GetRowFromHROW. |
|
| You can also open a Record object by using the Value of the RESOURCE_ABSOLUTEPARSENAME field of the current record, like this: |
|
| That's the hard way. If you know the name of the document that you want to access, you don't have to go through the Recordset. Using MSDAIPP, Record.Open will work with a string literal specified as the source. (Make sure that it's not prefixed by URL=.) |
|
| You can also use direct binding and the URL= syntax in the connection string to invoke the Root Binder when using Record.Open, just like when using Recordset.Open and Command.Execute. Note the subtle difference between specifying the connection string using the URL= syntax (the second parameter to Record.Open) and specifying the name of the folder or document as the source (the first parameter, no URL=) on Record.Open. Columns are exposed through the Fields collection, as usual: |
|
| This produces the output in Figure 15 as you would expect.
New Record objects corresponding to new folders or documents can be created by using Record.Open. You specify the source name, the connection string, and a special flag that indicates whether you would like to create a folder (collection) or document (noncollection). |
| You can also bind to the Stream. The ADO object can read and write ASCII, Unicode, or binary streams. Unicode is the default. The only limitation is that, in order to be usable by ADO, the provider writer must include support for IStream, which is an optional interface on the OLE DB Stream object.
Here's how to open and write and read from a stream with ADO. The following code reads and writes a Unicode stream: |
|
|
| To use ASCII streams, set the Stream object's charset variable to ASCII. To read and write binary streams, use Stream.Read and Stream.Write rather than the text versions. ADO and Scoped Operations
|
|
| There is one other limitation of using ADO with the Internet publishing provider. Because synchronization between documents that are updated in offline mode and documents on the Web server is done through ISynchronizeRow, an extended interface (an interface defined outside of the standard interfaces for the specified cotype in the OLE DB specification), this functionality cannot be programmed using ADO. Summary
|
|
For related information see: Microsoft OLE DB Overview in the MSDN Online Library: http://msdn.microsoft.com/library/techart/adosql_1.htm. Also check http://msdn.microsoft.com for daily updates on developer programs, resources and events. |
|
From the November 1999 issue of Microsoft Systems Journal.
|