SOLUTIONS
BY DESIGN
Adding a Questionnaire to a Design
A star schema is
born
With this month's column, I change direction somewhat and look at design case studies, what makes them work, and why. I'll start by examining the questionnaire.
The questionnaire is a popular and valuable source of data for an organization. Many organizations ask their customers to fill out questionnaires with the intent of collecting and using the customer feedback. Then comes the inevitable question of how to integrate the questionnaire information into an existing database's design.
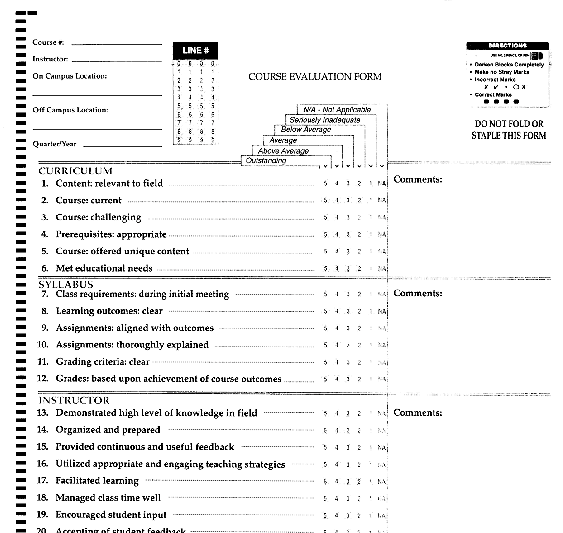
The university I'm affiliated with routinely gives a two-page questionnaire to students at the end of each class, every term. Figure 1 is the first portion of this questionnaire. It's typical in that it has two parts: the static information (e.g., course number, instructor) and the variable (the student evaluation of the class and fill-in and free-form comments). From a design standpoint, the class evaluation questionnaire data should be easy to incorporate into the existing database. But the questionnaire and accompanying software package were developed independently, and were never integrated into the university database. As a result, when evaluation reports are printed and distributed to department directors and faculty, items such as the instructor's name and the course code and title are missing because the program doesn't include them. No one remembers why things were done this way, but this little glitch can be a big problem.
Even worse, the valuable information these class evaluations contain has been very difficult to use. The questionnaire software can produce only one report, which gives a perspective on how the students received the class, on a per-class basis. But it has no built-in capability to analyze the numbers to determine how an instructor is doing overall, how students accept a class overall, or whether most students despise a particular classroom or textbook! An overworked departmental and administrative staff must then perform any analysis beyond the per-class level manually, and sometimes subjectively.
This situation is crying out for integration, which isn't hard to implement. Counterpart attributes to the static information (course, instructor, term, etc.) already exist in other tables in the university database. The university could easily incorporate this section into its current database design. The variable-length comment portion is a new attribute set, which someone simply needs to add to the database schema. Most questionnaires follow this model. No matter what kind of organization you work in, the static portion of the form is probably corporate data you already have in your organization's database. You then need to add the opinion portion to your database schema.
The ERD
A
first attempt at integration might follow the path of least
resistance: you could create just one table that contains the data
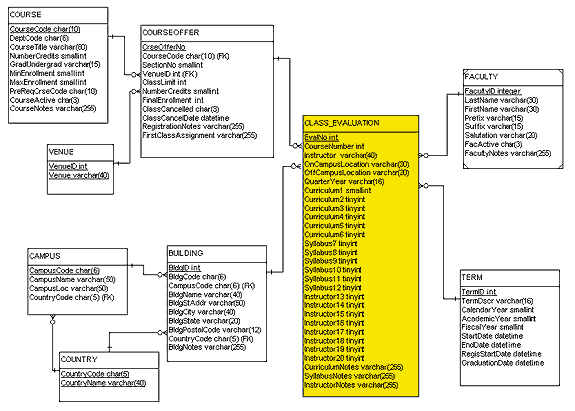
you see on the questionnaire, as the entity relationship diagram
(ERD) in Figure
2 illustrates. However, you risk running into problems
when you try to integrate this single table into the rest of the
database, as I'll show. The integration usually isn't an impossible
task, but you'll want to be careful in designing the questionnaire
schema, and Figure 2 isn't the best model you can use.
Figure 2 shows the class evaluation entity, with attributes that directly reflect the questionnaire. The other entities in the figure are part of the established university database (modified somewhat to protect proprietary university interests). Looking at the CLASS_EVALUATION entity, you can see that producing a per-class evaluation report with class number--in this context, a class code such as MATH 101--instructor, and class location would be easy. And, if you remain within the attribute set that CLASS_EVALUATION provides, you can gather statistics and do analysis. But what happens when you want to integrate the findings from CLASS_EVALUATION with the other entities on the ERD? Here's where things can get confusing and where your statistics might become meaningless.
You'll notice that the ERD has a master course listing (entity COURSE) and a listing of instances of each course offered (entity COURSEOFFER). The CourseCode uniquely identifies each course, and CrseOfferNo (course offering number) uniquely identifies each course offering. These are the primary identifying attributes (primary keys) for these two tables. (For a complete discussion of primary keys, see SQL by Design, "How to Choose a Primary Key," April 1999.) Because the same course might be offered twice in the same term, COURSEOFFER also contains a section number (SectionNo), which differentiates between the offerings. In most such cases, a different instructor teaches each course offering--but not always. Sometimes one instructor teaches two sections of a course during one term, in the same classroom, at different times, and on different days. The established university database can differentiate between these course offerings, but the CLASS_EVALUATION entity, as it's currently constructed, can't.
To accurately relate a CLASS_EVALUATION to a specific offering of a course, you must be able to link the evaluation to a specific course held at a specific time and place, offered during a specific term by a specific instructor. But the relationship between CLASS_EVALUATION and the CAMPUS-BUILDING-COUNTRY schema is fuzzy. The university database was built to manage and schedule classes, both real and virtual, instructor-led, and distance-delivery. The COURSEOFFER entity contains no information about where a class meets, or when. Other entities contain those attributes. Also notice the entity VENUE, which flags whether a class is instructor-led or distance-delivery. CLASS_ EVALUATION has two attributes, OnCampusLocation and OffCampusLocation. To bring this information together, you'd have to create some sort of cross-mapping to relate OnCampusLocation and OffCampusLocation to the entities COUNTRY, CAMPUS, BUILDING, and VENUE. But I'm not sure how you'd do it so that the result would be easily interpreted by the end user, consistent in meaning, and easy to administer.
Mapping the Instructor attribute of CLASS_EVALUATION to the FirstName and LastName attributes of FACULTY is tricky, and in some situations might be entirely misleading. But having the Instructor attribute reflect just the last name of the instructor isn't enough, because the set of Faculty data includes seven Smiths, three Johnsons, and two people named Mendez. How you handle such potential duplication depends on your data set.
In this situation, you must empower the end users, the people who'll be doing the statistical evaluations and reporting. Statisticians need a strong knowledge of the business operations and must be comfortable with statistical software packages. Statisticians, like managers, have a vested interest in the accuracy and meaningfulness of the result. But you can't expect them to know how to write programs in SQL or Visual Basic (VB) to manipulate the data to force associations between tables. Therefore, finding a different approach to integrating the questionnaire from the one in Figure 2 is probably the best solution.
The Star/Snowflake
When you model a database, using a variation of the
star schema model seems to work best for a questionnaire. The star
schema, or dimensional model, is the standard modeling scheme for
data marts and data warehouses. Its name comes from the star-shaped
format of the ERD. (For more information on the star schema, see Bob
Pfeiff, "OLAP: Resistance is Futile!" April 1999.) A simple star
schema has a central fact entity, or table, which contains
measurements of the business activities that you're interested in
evaluating. The fact table is similar to the gerund, or associative
entity, of the transactional ERD. It associates many noun entities
(dimension tables in data-warehouse modeling) and consists of its
primary key attribute, a set of foreign keys that enforce the
relationships, and facts about the business activities.
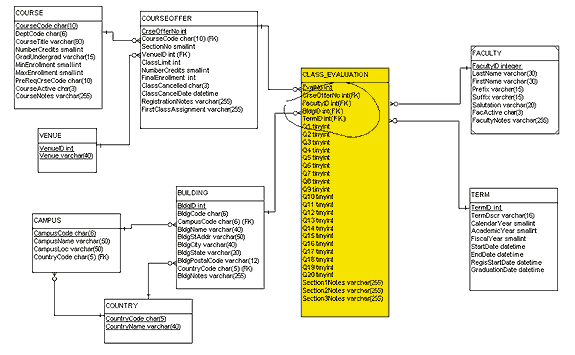
Figure 3 is an ERD in snowflake schema format that positions CLASS_EVALUATION as the fact table, with modifying tables, or dimensions, such as COURSEOFFER, TERM, FACULTY, and BUILDING. These dimension tables define, decode, and add depth and meaning to the fact table. Each dimension table has a unique identifier (a primary key) that is embedded in the fact table as a foreign key. As with all good primary keys, the values are integer and identity, devoid of inherent meaning. Other entities (e.g., COURSE, VENUE, CAMPUS, and COUNTRY) are the second-level dimension tables, or outriggers, that further define and give meaning to the model. A star schema with outriggers, in which two or more levels of dimension tables modify the fact table, is sometimes called a snowflake schema.
The CLASS_EVALUATION fact table relates directly to the questionnaire, although the first part, the static information, is now almost all foreign-key data. The course number from the questionnaire is now CrseOfferNo, the instructor is FacultyID, on-campus location is BldgCode, off-campus location is VenueID, and quarter/year is TermID. Thus, the questionnaire is successfully integrated into the existing data model.
Notice in Figure 3 that I have renamed most of the attribute set for CLASS_EVALUATION. (I've circled the changes I made to the CLASS_EVALUATION table.) What was an intelligent, meaningful attribute name (Curriculum1) is now a meaningless label (Q1). To be honest, the rationale behind this change is self-preservation for the database team! The questionnaire-makers are continually tweaking and adjusting the questions on the form. In an effort to design a universal schema to hold the collected data, I used general attribute names. Granted, each time someone alters the questionnaire, a different set of data is collected, so the statistical analysis of data taken across two different questionnaires might be invalid.
So, why am I not satisfied with this design? Is it because, to get any information out of this model, I have to write at least a five-table join? For the end users, I could create a view that joins the five tables, but that approach doesn't resolve the performance overhead problems I'll encounter. Perhaps there's a better solution.
The Compromise
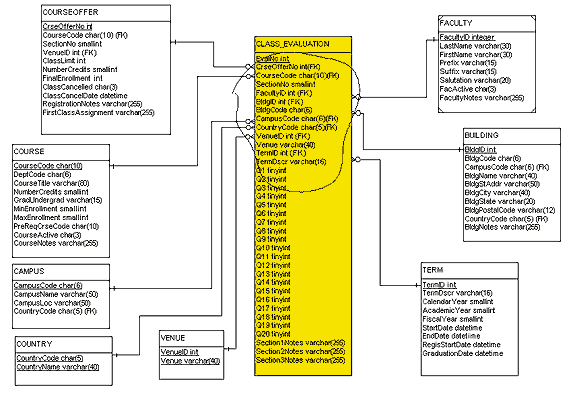
Figure
4 is a compromise ERD, a modification of Figure 3 that lets end
users extract the information they require without more than a
single-table select, yet provides the same, or higher, level of
integration than the model in Figure 3 does. By including both the
primary keys and the candidate keys of the dimension tables in
CLASS_EVALUATION wherever possible, I've introduced meaning into the
data in the fact table. The candidate keys (CourseCode, Venue,
TermDscr, BldgCode), like the primary keys, are unique identifiers
for their respective tables, but they're intelligent identifiers.
Like all intelligent identifiers, they're subject to change with
time (building code MRB might change to MRH if someone renames the
Mary Reed Building Mary Reed Hall). Candidate keys are valuable
because they contain inherent information in the form of codes,
which can be useful to corporate decision-makers. By incorporating
the candidate keys into the table schema for CLASS_EVALUATION, you
introduce intelligence and meaning into the entity. And, even if a
candidate key's value changes, the original relationships remain
because the identity-type foreign keys bind them.
I've introduced some redundancy into the design by adding VENUE, CAMPUS, COUNTRY, and COURSE to the list of dimension tables, thus shrinking the snowflake schema back to a star schema. Data modeling purists might argue that this design violates many principles of entity modeling and data normalization, and technically such purists are right. However, data modeling for the real world is often a compromise between the rules of absolute normalization and generating a database that performs within expectations.
In this model, faculty identification is still awkward. The set of faculty names in our organization is so large that duplicate last names and first-and-last-name combinations occur. I limited the reference to faculty in CLASS_EVALUATION to FacultyID, thus requiring a join between CLASS_EVALUATION and FACULTY to determine who taught which classes. This approach works for our organization from both an operational and a privacy perspective. Anyone who examines class evaluations won't be swayed by knowing who the instructor is unless that person joins the tables.
Integrating a questionnaire into an existing database isn't difficult, but you must approach it carefully. Borrowing from the star schema, or dimensional modeling, methodology to build the ERD and bending the rules of data normalization on the questionnaire entity can add information content and performance value to the data model.
SQL Server MagazineCopyright Duke Communications Intl, Inc. All rights reserved.
{kind=link}
{kind=link}
{kind=link}
{kind=link}