![]()
This article assumes you're familiar with Active Server Pages
|
This article may contain URLs that were valid when originally published, but now link to sites or pages that no longer exist. To maintain the flow of the article, we've left these URLs in the text, but disabled the links.
|
|
Architecting Your Web Applications
John Lam and Aaron Skonnard |
| Developing Internet-based apps means discarding many traditional concepts of client/server design. You have to pay attention to scalability and concurrency issues that never came into play before. |
|
A friend confessed to us recently that he felt unsure about joining the ranks of the Web application industry. His strong C++/MFC skills gave him a sense of job security and self-worth that, in his mind, would be lost by becoming yet another HTML programmer. He was right to assume that simply adding HTML to his resume wouldn't make him invaluable overnight. Anyone can create an HTML page these days, right? Just ask your marketing department.
Not everyone can create interactive Web applications that improve the profitability of your company. Even more difficult is creating Web applications that can scale over time without requiring a rewrite of a single line of code. Web application developers who understand how to build these complex systems are indeed invaluable in today's Web-driven market. If you're a Web application developer or trying to become one, it's imperative to understand the design considerations you'll be facing. In this article, we'll begin by reviewing the typical client/server design strategies used today and explain why they can't be adapted to the Web model. As you read this article, you'll learn how you can start thinking in terms of Web applications. In the process, you may have to set aside many of the design principles (and habits) you've learned over time because they simply don't work on the Web. In addition to covering the design limitations with the Web model, we'll define the concepts of a user session and session state in a Web application and how they can influence the overall performance and scalability of your system. We'll tackle one of the toughest design questions every Web application developer faces: where should I store session state? Next, we'll turn to a new Web application design pattern that we call the one-page Web application. While this innovative design pattern can be implemented on most browser flavors (if the developers are creative enough, that is), it becomes trivial with the new technologies built into Microsoft Internet Explorer 5.0. You'll see how XML along with new features in Internet Explorer 5.0 can help you achieve your Web application design goals.
Typical Client/Server Application Design
Unlimited Users
Browsers Galore
|
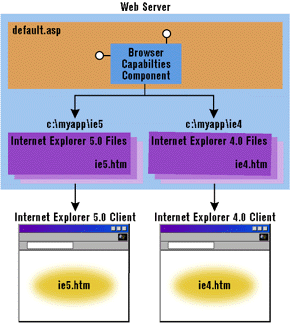 |
| Figure 1: Different Versions for Different Browsers |
|
HTTP
Session, State, and Security
Managing Sessions
|
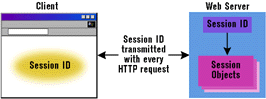 |
| Figure 2: Passing Session IDs |
|
The server can pass session identifiers by using a hidden form field or embedding it within every relative link (see Figure 3). Like the pass-by-value approach, this also works on all browsers, but is much less cumbersome than the complete pass-by-value technique. The only thing you would pass as part of every HTTP request is the session ID. The server uses the session ID to look up the user's session data. This approach is commonly used today by big Web applications that have to support a wide range of Web browsers. For an example, point your browser to Amazon's Web site and view the HTML source for the pages you get back. You'll notice a session identifier embedded within every URL from the Amazon domain.
If you can assume cookie-compatible browsers, you can also use cookies to send a session identifier back to the client. This is actually how the built-in Active Server Pages (ASP) session management works. If you have session management enabled (the default), the first time you hit an ASP page in your Web application, the ASP runtime automatically sends a cookie to the client containing the session ID. Since ASP uses in-memory cookies, you won't see the cookie on disk, but you can use NetMon to verify this behavior.
Session Lifetime
Durability and Scope
In-memory State on a Web Server
|
|
| This would increment the application-wide hit count. Storing information at session scope is just as easy using ASP: |
|
| The ASP intrinsic objects store the data in memory on the Web server on which the ASP page is executing. As noted earlier, the ASP session management scheme uses cookies behind the scenes to match a given client with its corresponding Session object in memory. As you can see, this nondurable state mechanism is very straightforward and easy to use; the ASP runtime hides all of the pass-by-reference details, allowing you to be more productive. If your Web application is small and will never need to scale, this is the best solution for you.
If there is even a small chance that your Web application will have to scale to a Web farm scenario (where you deploy it on multiple identical Web servers), you may want to think twice about using this strategy. In the Web farm scenario, storing data at application scope in memory on the Web server doesn't work; ASP pages running on other Web servers in the farm will not see each other's updates. You could still get away with storing session state in memory on the Web server, but now you've pinned the client to a single Web server for the lifetime of its session (see Figure 4). This completely destroys any type of dynamic load-balancing strategy you might try to implement within the Web farm. Plus, you'll probably need some expensive hardware (like the Cisco Local Director router) or software to accomplish the session pinning. In other words, you've created a very complicated mess. |
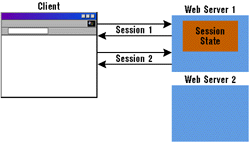 |
| Figure 4: Effect on In-memory State Storage |
|
Another major downside to storing state in memory on the Web server has to do with fail-over. If the Web server
goes down, the state is completely lost and all users in the middle of sessions lose their data. Plus, if a user is pinned to a server and that server goes down, he is stuck until it comes back online.
In-memory State on
Another Server
|
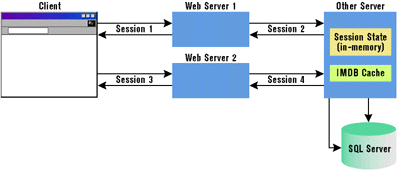 |
| Figure 5: The "Next-available" Web Server Approach |
|
Windows® 2000 will introduce a new technology called the In-Memory Database (IMDB). (IMDB technology has been discontinued. See the IMDB update page for more information Ed.). This technology will, in theory, allow you to cache database tables in memory on all Web servers within a Web farm for lightning-fast access. The first release of IMDB, however, only works in single-node scenarios. IMDB acts as a write-through cache manager for a specific relational database. All updates to the IMDB tables must take place through the IMDB cache.
To make this work in a Web farm scenario, an IMDB cache must exist on each Web server. Problems arise when you need to do updates on the database tables. If one machine updates a table that lives in an IMDB cache on another machine, the IMDB machine won't see the change. You need to keep the IMDB caches synchronized on all the Web servers in the farm. This cache synchronization mechanism is planned for the next release of IMDB. Today, you can use IMDB on a dedicated state server as long as all changes go through the IMDB cache (see Figure 5). As you can see, IMDB gives you the best of both durable and nondurable state. Probably the most common approach today for storing application and session-scoped state in large-scale Web applications is to use a durable storage mechanism like a relational database. The database can reside on the Web server at first. Then, when the site needs to scale to a Web farm, it can be moved to a dedicated database server. Shopping cart applications that keep your purchase data around for days or even weeks are probably using this strategy. Although this strategy offers lower performance than the nondurable solutions, it allows your application to take advantage of dynamic load-balancing and fail-over strategies. Furthermore, using durable storage makes system failures much less of a problem.
Client State
|
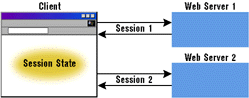 |
| Figure 6: Client-side Session State |
|
The biggest problem with this approach is cross-browser compatibility. None of these techniques are universally
supported across browsers, and most of them—with the exception of in-memory cookies—are supported by Internet Explorer 4.0 and later.
You can take things a step further and store session state on the client's disk. You can accomplish this today using persistent cookies (cookies with an expiration date). Internet Explorer 5.0, however, offers a much more powerful and flexible solution with its new userData behavior. The userData behavior allows you to store state as XML on the client's disk. This allows you to add rich structural meaning to your data store, and it gets you around the standard 4KB cookie limit. Using this approach, you get all the same advantages described above, plus the ability to persist state across user sessions. If the user closes their browser and comes back to your application two days later, the state will still be on their disk and available for use. The downside, once again, is cross-browser compatibility.
Do We Really Need Session State?
A One-page Web Application
|
|
| XML data islands also have an src attribute that you can use to point to XML data on the Web server: |
|
| Notice that XML data islands can point to static XML files or even ASP files that generate XML output. Now for the interesting stuff: you can also dynamically change the src attributes of XML data islands from script. |
|
| As you can see, XML data islands are a very convenient mechanism for requesting additional data from the server without forcing a page transition.
Another new object in Internet Explorer 5.0, XMLHttpRequest, gives you direct access to the underlying HTTP protocol along with XML parsing support. For example, consider the following script (disclaimer: this only works with the final release of Internet Explorer 5.0): |
|
| This block of script, which can be executed in response to some user interaction, sends an HTTP request to the server and waits to receive the HTTP response. Once the script receives the response, it can use DHTML to update any scriptable element within the HTML page (see Figure 7). |
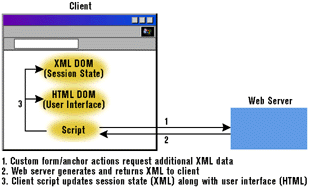 |
| Figure 7: Updating Session State |
|
Internet Explorer 5.0 also has excellent support for the Extensible Stylesheet Language (XSL). This allows you to store most of your page-scoped data as XML. You can then use XSL to transform the XML data into HTML—use XML to represent page-scoped data and XSL to describe how that data should look to the user.
When you need to persist your XML data across user sessions, once again you can save it to disk using the Internet Explorer 5.0 intrinsic userData behavior. As you can see, Internet Explorer 5.0 and its extensive support for XML and out-of-band requests makes the one-page Web application very feasible. Imagine being able to save all session-scoped state within a single Web page, having programmatic access to the data via a standard DOM, and being able to easily persist the session data to disk using XML. This gives you better performance, scalability, and simplicity than any of the other strategies we've discussed here.
Techniques for Avoiding Page Transitions
|
|
| To make the user feel like there was a page transition (and that something actually happened in response to the user's interaction), you can use DHTML to hide, show, or update elements on the page. We should also point out that you could accomplish this type of functionality on down-level browsers using more traditional technologies like Java applets or ActiveX® controls. The downside is that they're more difficult to implement and require downloading binary images. Plus, if you want to take advantage of XML on these down-level systems, you'll have to implement most of the XML functionality yourself. (See Ken Spencer's Beyond the Browser column in this issue for a discussion of how to do this in Visual Basic.)
A New Role for ASP
Conclusion
|
|
|
|
http://msdn.microsoft.com/library/techart/msdn_csarctop.htm |
|
From the September 1999 issue of Microsoft Internet Developer.
|