Persistent Storage
As mentioned in Chapter 1, the enhanced COM services define a number of storage-related interfaces, collectively called Persistent Storage or Structured Storage. By definition of the term interface, these interfaces carry no implementation. They describe a way to create a file system within a file, and they provide some extremely powerful features for applications including incremental access, transactioning, and a sharable medium that can be used for data exchange or for storing the persistent data of objects that know how to read and write such data themselves. The following sections deal with the structure of storage and the other features.
A File System Within a File
Years ago, before there were disk operating systems, applications had to write persistent data directly to a disk drive, or drum, by sending commands directly to the hardware disk controller. Those applications were responsible for managing the absolute location of the data on the disk, making sure that it was not overwriting data that was already there. This was not too much of a problem seeing as how most disks were under complete control of a single application that took over the entire computer.
The advent of computer systems that could run more than one application brought about problems where all the applications had to make sure they did not write over each other's data on the disk. It therefore became beneficial that each adopted a standard of marking the disk sectors that were used and which ones were free. In time, these standards became the disk operating system which provided a file system. Now, instead of dealing directly with absolute disk sectors and so forth, applications simply told the file system to write blocks of data to the disk. Furthermore, the file system allowed applications to create a hierarchy of information using directories which could contain not only files but other sub-directories which in turn contained more files, more sub-directories, and so forth.
The file system provided a single level of indirection between applications and the disk, and the result was that every application saw a file as a single contiguous stream of bytes on the disk. Underneath, however, the file system was storing the file in dis-contiguous sectors according to some algorithm that optimized read and write time for each file. The indirection provided from the file system freed applications from having to care about the absolute position of data on a storage device.
Today, virtually all system APIs for file input and output provide applications with some way to write information into a flat file that applications see as a single stream of bytes that can grow as large as necessary until the disk is full. For a long time these APIs have been sufficient for applications to store their persistent information. Applications have made some incredible innovations in how they deal with a single stream of information to provide features like incremental fast saves.
However, a major feature of COM is interoperability, the basis for integration between applications. This integration brings with it the need to have multiple applications write information to the same file on the underlying file system. This is exactly the same problem that the computer industry faced years ago when multiple applications began to share the same disk drive. The solution then was to create a file system to provide a level of indirection between an application file and the underlying disk sectors.
Thus, the solution for the integration problem today is another level of indirection: a file system within a file. Instead of requiring that a large contiguous sequence of bytes on the disk be manipulated through a single file handle with a single seek pointer, COM defines how to treat a single file system entity as a structured collection of two types of objects-storages and streams-that act like directories and files, respectively.
Storage and Stream Objects
Within COM's Persistent Storage definition there are two types of storage elements: storage objects and stream objects. These are objects generally implemented by the COM library itself; applications rarely, if ever, need to implement these storage elements themselves.9. These objects, like all others in COM, implement interfaces: IStream for stream objects, IStorage for storage objects as detailed in Chapter 8.
A stream object is the conceptual equivalent of a single disk file as we understand disk files today. Streams are the basic file-system component in which data lives, and each stream in itself has access rights and a single seek pointer. Through its IStream interface stream can be told to read, write, seek, and perform a few other operations on its underlying data. Streams are named by using a text string and can contain any internal structure you desire because they are simply a flat stream of bytes. In addition, the functions in the IStream interface map nearly one-to-one with standard file-handle based functions such as those in the ANSI C run-time library.
A storage object is the conceptual equivalent of a directory. Each storage, like a directory, can contain any number of sub-storages (sub-directories) and any number of streams (files). Furthermore, each storage has its own access rights. The IStorage interface describes the capabilities of a storage object such as enumerate elements (dir), move, copy, rename, create, destroy, and so forth. A storage object itself cannot store application-defined data except that it implicitly stores the names of the elements (storages and streams) contained within it.
Storage and stream objects, when implemented by COM as a standard on a system, are sharable between processes. This is a key feature that enables objects running in-process or out-of-process to have equal incremental access to their on-disk storage. Since COM is loaded into each process separately, it must use some operating-system supported shared memory mechanisms to communicate between processes about opened elements and their access modes.
Application Design with Structured Storage
COM's structured storage built out of storage and stream objects makes it much easier to design applications that by their nature produce structured information. For example, consider a diary program that allows a user to make entries for any day of any month of any year. Entries are made in the form of some kind of object that itself manages some information. Users wanting to write some text into the diary would store a text object; if they wanted to save a scan of a newspaper clip they could use a bitmap object, and so forth.
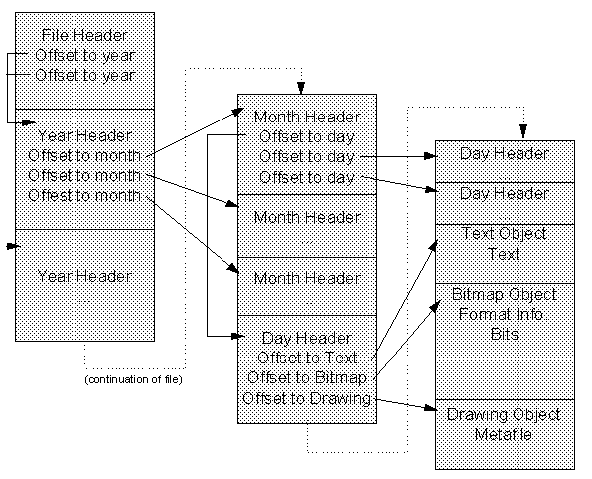 Figure 2-11. A flat-file structure for a diary application. This sort of structure is difficult to manage.
Without a powerful means to structure information of this kind, the diary application might be forced to manage some hideous file structure with an overabundance of file position cross-reference pointers as shown in Figure 2-11.
There are many problems in trying to put structured information into a flat file. First, there is the sheer tedium of managing all the cross-reference pointers in all the different structures of the file. Whenever a piece of information grows or moves in the file, every cross-reference offset referring to that information must be updated as well. Therefore, even a small change in the size of one of the text objects or an addition of a day or month might precipitate changes throughout the rest of the file to update seek offsets. While not only tedious to manage, the application will have to spend enormous amounts of time moving information around in the file to make space for data that expands. That, or the application can move the newly enlarged data to the end of the file and patch a few seek offsets, but that introduces the whole problem of garbage collection, that is, managing the free space created in the middle of the file to minimize waste as well as overall file size.
The problems are compounded even further with objects that are capable of reading and writing their own information to storage. In the example here, the diary application would prefer to give each objects in it-text, bitmap, drawing, table, and so forth,-its own piece of the file in which the object can write whatever the it wants, however much it wants. The only practical way to do this with a single flat file is for the diary application to ask each object for a memory copy of what the object would like to store, and then the diary would write that information into a place in its own file. This is really the only way in which the diary could manage the location of all the information. Now while this works reasonably well for small data, consider an object that wants to store a 10MB bitmap scan of a true-color photograph-exchanging that much data through memory is horribly inefficient. Furthermore, if the end user wants to later make changes to that bitmap, the diary would have to load the bitmap in entirety from its file and pass it back to the object. This is again extraordinarily inefficient.10.
COM's Persistent Storage technology solves these problems through the extra level of indirection of a file system within a file. With COM, the diary application can create a structured hierarchy where the root file itself has sub-storages for each year in the diary. Each year sub-storage has a sub-storage for each month, and each month has a sub-storage for each day. Each day then would have yet another sub-storage or perhaps just a stream for each piece of information that the user stores in that day.11. This configuration is illustrated in Figure 2-12.
Figure 2-11. A flat-file structure for a diary application. This sort of structure is difficult to manage.
Without a powerful means to structure information of this kind, the diary application might be forced to manage some hideous file structure with an overabundance of file position cross-reference pointers as shown in Figure 2-11.
There are many problems in trying to put structured information into a flat file. First, there is the sheer tedium of managing all the cross-reference pointers in all the different structures of the file. Whenever a piece of information grows or moves in the file, every cross-reference offset referring to that information must be updated as well. Therefore, even a small change in the size of one of the text objects or an addition of a day or month might precipitate changes throughout the rest of the file to update seek offsets. While not only tedious to manage, the application will have to spend enormous amounts of time moving information around in the file to make space for data that expands. That, or the application can move the newly enlarged data to the end of the file and patch a few seek offsets, but that introduces the whole problem of garbage collection, that is, managing the free space created in the middle of the file to minimize waste as well as overall file size.
The problems are compounded even further with objects that are capable of reading and writing their own information to storage. In the example here, the diary application would prefer to give each objects in it-text, bitmap, drawing, table, and so forth,-its own piece of the file in which the object can write whatever the it wants, however much it wants. The only practical way to do this with a single flat file is for the diary application to ask each object for a memory copy of what the object would like to store, and then the diary would write that information into a place in its own file. This is really the only way in which the diary could manage the location of all the information. Now while this works reasonably well for small data, consider an object that wants to store a 10MB bitmap scan of a true-color photograph-exchanging that much data through memory is horribly inefficient. Furthermore, if the end user wants to later make changes to that bitmap, the diary would have to load the bitmap in entirety from its file and pass it back to the object. This is again extraordinarily inefficient.10.
COM's Persistent Storage technology solves these problems through the extra level of indirection of a file system within a file. With COM, the diary application can create a structured hierarchy where the root file itself has sub-storages for each year in the diary. Each year sub-storage has a sub-storage for each month, and each month has a sub-storage for each day. Each day then would have yet another sub-storage or perhaps just a stream for each piece of information that the user stores in that day.11. This configuration is illustrated in Figure 2-12.
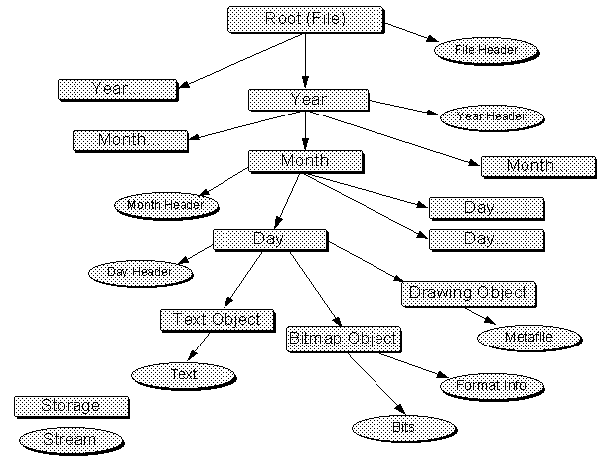 Figure 2-12. A structured storage scheme for a diary application. Every object that has some content is given its own storage or stream element for its own exclusive use.
This structure solves the problem of expanding information in one of the objects: the object itself expands the streams in its control and the COM implementation of storage figures out where to store all the information in the stream. The diary application doesn't have to lift a finger. Furthermore, the COM implementation automatically manages unused space in the entire file, again, relieving the diary application of a great burden.
In this sort of storage scheme, the objects that manage the content in the diary always have direct incremental access to their piece of storage. That is, when the object needs to store its data, it writes it directly into the diary file without having to involve the diary application itself. The object can, if it wants to, write incremental changes to that storage, thus leading to much better performance than the flat file scheme could possibly provide. If the end user wanted to make changes to that information later on, the object can then incrementally read as little information as necessary instead of requiring the diary to read all the information into memory first. Incremental access, a feature that has traditionally been very hard to implement in applications, is now the default mode of operation. All of this leads to much better performance.
Naming Elements
Every storage and stream object in a structured file has a specific character name to identify it. These names are used to tell IStorage functions what element in that storage to open, destroy, move, copy, rename, and so forth. Depending on which component, client or object, actually defines and stores these names, different conventions and restrictions apply.
Names of root storage objects are in fact names of files in the underlying file system. Thus, they obey the conventions and restrictions that it imposes. Strings passed to storage-related functions which name files are passed on un-interpreted and unchanged to the file system.
Names of elements contained within storage objects are managed by the implementation of the particular storage object in question. All implementations of storage objects must at the least support element names that are 32 characters in length; some implementations may if they wish choose to support longer names. Names are stored case-preserving, but are compared case-insensitive.12. As a result, applications which define element names must choose names which will work in either situation.
The names of elements inside an storage object must conform to certain conventions:
Figure 2-12. A structured storage scheme for a diary application. Every object that has some content is given its own storage or stream element for its own exclusive use.
This structure solves the problem of expanding information in one of the objects: the object itself expands the streams in its control and the COM implementation of storage figures out where to store all the information in the stream. The diary application doesn't have to lift a finger. Furthermore, the COM implementation automatically manages unused space in the entire file, again, relieving the diary application of a great burden.
In this sort of storage scheme, the objects that manage the content in the diary always have direct incremental access to their piece of storage. That is, when the object needs to store its data, it writes it directly into the diary file without having to involve the diary application itself. The object can, if it wants to, write incremental changes to that storage, thus leading to much better performance than the flat file scheme could possibly provide. If the end user wanted to make changes to that information later on, the object can then incrementally read as little information as necessary instead of requiring the diary to read all the information into memory first. Incremental access, a feature that has traditionally been very hard to implement in applications, is now the default mode of operation. All of this leads to much better performance.
Naming Elements
Every storage and stream object in a structured file has a specific character name to identify it. These names are used to tell IStorage functions what element in that storage to open, destroy, move, copy, rename, and so forth. Depending on which component, client or object, actually defines and stores these names, different conventions and restrictions apply.
Names of root storage objects are in fact names of files in the underlying file system. Thus, they obey the conventions and restrictions that it imposes. Strings passed to storage-related functions which name files are passed on un-interpreted and unchanged to the file system.
Names of elements contained within storage objects are managed by the implementation of the particular storage object in question. All implementations of storage objects must at the least support element names that are 32 characters in length; some implementations may if they wish choose to support longer names. Names are stored case-preserving, but are compared case-insensitive.12. As a result, applications which define element names must choose names which will work in either situation.
The names of elements inside an storage object must conform to certain conventions:
- The two specific names "." and ".." are reserved for future use.
- Element names cannot contain any of the four characters "\", "/", ":", or "!".
In addition, the name space in a storage element is partitioned in to different areas of ownership. Different pieces of code have the right to create elements in each area of the name space.
- The set of element names beginning with characters other than '\0x01' through '\0x1F' (that is, decimal 1 through decimal 31) are for use by the object whose data is stored in the IStorage. Conversely, the object must not use element names beginning with these characters.
- Element names beginning with a '\0x01' and '\0x02' are for the exclusive use of COM and other system code built on it such as OLE Documents.
- Element names beginning with a '\0x03' are for the exclusive use of the client which is managing the object. The client can use this space as a place to persistently store any information it wishes to associate with the object along with the rest of the storage for that object.
- Element names beginning with a '\0x04' are for the exclusive use of the COM structured storage implementation itself. They will be useful, for example, should that implementation support other interfaces in addition to IStorage, and these interface need persistent state.
- Element names beginning with '\0x05' and '\0x06' are for the exclusive use of COM and other system code built on it such as OLE Documents.
- All other names beginning with '\0x07' through '\0x1F' are reserved for future definition and use by the system.
In general, an element's name is not considered useful to an end-user. Therefore, if a client wants to store specific user-readable names of objects, it usually uses some other mechanism. For example, the client may write its own stream under one of its own storage elements that has the names of all the other objects within that same storage element. Another method would be for the client to store a stream named "\0x03Name" in each object's storage that would contain that object's name. Since the stream name itself begins with '\0x03' the client owns that stream even through the objects controls much of the rest of that storage element.
Direct Access vs. Transacted Access
Storage and stream elements support two fundamentally different modes of access: direct mode and transacted mode. Changes made while in direct mode are immediately and permanently made to the affected storage object. In transacted mode, changes are buffered so that they may be saved ("committed") or reverted when modifications are complete.
If an outermost level IStorage is used in transacted mode, then when it commits, a robust two-phase commit operation is used to publish those changes to the underlying file on the file system. That is, great pains are taken are taken so as not to loose the user's data should an untimely crash occurs.
The need for transacted mode is best explained by an illustrative scenario. Imagine that a user has created a spreadsheet which contains a sound clip object, and that the sound clip is an object that uses the new persistent storage facilities provided in COM. Suppose the user opens the spreadsheet, opens the sound clip, makes some editing changes, then closes the sound clip at which point the changes are updated in the spreadsheet storage set aside for the sound clip. Now, at this instant, the user has a choice: save the spreadsheet or close the spreadsheet without saving. Either way, the next time the user opens the spreadsheet, the sound clip had better be in the appropriate state. This implies that at the instant before the save vs. close decision was made, both the old and the new versions of the sound clip had to exist. Further, since large objects are precisely the ones that are expensive in time and space to copy, the new version should exist as a set of differences from the old.
The central issue is whose responsibility it is to keep track of the two versions. The client (the spreadsheet in this example) had the old version to begin with, so the question really boils down to how and when does the object (sound clip) communicate the new version to the spreadsheet. Applications today are in general already designed to keep edits separate from the persistent copy of an object until such time as the user does a save or update. Update time is thus the earliest time at which the transfer should occur. The latest is immediately before the client saves itself. The most appropriate time seems to be one of these two extremes; no intermediate time has any discernible advantage.
COM specifies that this communication happens at the earlier time. When asked to update edits back to the client, an object using the new persistence support will write any changes to its storage) exactly as if it were doing a save to its own storage completely outside the client. It is the responsibility of the client to keep these changes separate from the old version until it does a save (commit) or close (revert). Transacted mode on IStorage makes dealing with this requirement easy and efficient.
The transaction on each storage is nested in the transaction of its parent storage. Think of the act of committing a transaction on an IStorage instance as "publishing changes one more level outwards." Inner objects publish changes to the transaction of the next object outwards; outermost objects publish changes permanently into the file system.
Let's examine for a moment the implications of using instead the second option, where the object keeps all editing changes to itself until it is known that the user wants to commit the client (save the file). This may happen many minutes after the contained object was edited. COM must therefore allow for the possibility that in the interim time period the user closed the server used to edit the object, since such servers may consume significant system resources.
To implement this second option, the server must presumably keep the changes to the old version around in a set of temporary files (remember, these are potentially big objects). At the client's commit time, every server would have to be restarted and asked to incorporate any changes back onto its persistent storage. This could be very time consuming, and could significantly slow the save operation. It would also cause reliability concern in the user's mind: what if for some reason (such as memory resources) a server cannot be restarted? Further, even when the client is closed without saving, servers have to be awakened to clean up their temporary files.
Finally, if a object is edited a second time before the client is committed, in this option its the client can only provide the old, original storage, not the storage that has the first edits. Thus, the server would have to recognize on startup that some edits to this object were lying around in the system. This is an awkward burden to place on servers: it amounts to requiring that they all support the ability to do incremental auto-save with automatic recovery from crashes. In short, this approach would significantly and unacceptably complicate the responsibilities of the object implementors.
To that end, it makes the most sense that the standard COM implementation of the storage system support transactioning through IStorage and possibly IStream.
Browsing Elements
By its nature, COM's structured storage separates applications from the exact layout of information within a given file. Every element of information in that file is access using functions and interfaces implemented by COM. Because this implementation is central, a file generated by some application using this structure can be browsed by some other piece of code, such as a system shell. In other words, any piece of code in the system can use COM to browse the entire hierarchy of elements within any structured file simply by navigating with the IStorage interface functions which provide directory-like services. If that piece of code also knows the format and the meaning of a specific stream that has a certain name, it could also open that stream and make use of the information in it, without having to run the application that wrote the file.
This is a powerful enabling technology for operating system shells that want to provide rich query tools to help end users look for information on their computer or even on a network. To make it really happen requires standards for certain stream names and the format of those streams such that the system shell can open the stream and execute queries against that information. For example, consider what is possible if all applications created a stream called "Summary Information" underneath the root storage element of the file. In this stream the application would write information such as the author of the document, the create/modify/last saved time-stamps, title, subject, keywords, comments, a thumbnail sketch of the first page, and so forth. Using this information the system shell could find any documents that a certain user wrote before a certain date or those that contained subject matter matched against a few keywords. Once those documents are found, the shell can then extract the title of the document along with the thumbnail sketch and give the user a very engaging display of the search results.
This all being said, in the general the actual utility of this capability is perhaps significantly less than what one might first imagine. Suppose, for example, that I have a structured storage that contains some word processing document whose semantics and persistent representation I am unaware of, but which contains some number of contained objects, perhaps the figures in the document, that I can identify by their being stored and tagged in contained sub-storages. One might naively think that it would be reasonable to be able to walk in and browse the figures from some system-provided generic browsing utility. This would indeed work from a technical point of view; however, it is unlikely to be useable from a user interface perspective.
The document may contain hundreds of figures, for example, that the user created and thinks about not with a name, not with a number, but only in the relationship of a particular figure to the rest of the document's information. With what user interface could one reasonably present this list of objects to the user other than as some add-hoc and arbitrarily-ordered sequence? There is, for example, no name associated with each object that one could use to leverage a file-system directory-browsing user interface design. In general, the content of a document can only be reasonably be presented to a human being using a tool that understands the semantics of the document content, and thus can show all of the information therein in its appropriate context.
Persistent Objects
Because COM allows an object to read and write itself to storage, there must be a way through which the client tells objects to do so. The way is, of course, additional interfaces that form a storage contract between the client and objects. When a client wants to tell and object to deal with storage, it queries the object for one of the persistence-related interfaces, as suits the context. The interfaces that objects can implement, in any combination, are described below:
- IPersistStorage Object can read and write its persistent state to a storage object. The client provides the object with an IStorage pointer through this interface. This is the only IPersist* interface that includes semantics for incremental access.
- IPersistStream Object can read and write its persistent state to a stream object. The client provides the object with an IStream pointer through this interface.
- IPersistFile Object can read and write its persistent state to a file on the underlying system directly. This interface does not involve IStorage or IStream unless the underlying file is itself access through these interfaces, but the IPersistFile itself has no semantics relating to such structures. The client simply provides the object with a filename and orders to save or load; the object does whatever is necessary to fulfill the request.
These interfaces and the rules governing them are described in Chapter 12.