The following query counts the number of orders placed in a given quarter starting on April 1, 1998 in which at least one line item of the order was received by the customer later than the committed date. This query lists the count of such orders grouped by each order priority and sorted in ascending priority order.
Note This example uses theoretical table and column names.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '1997/04/01'
AND o_orderdate < DATEADD (mm, 3, '1997/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Assume the following indexes are defined on the lineitem and orders tables:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
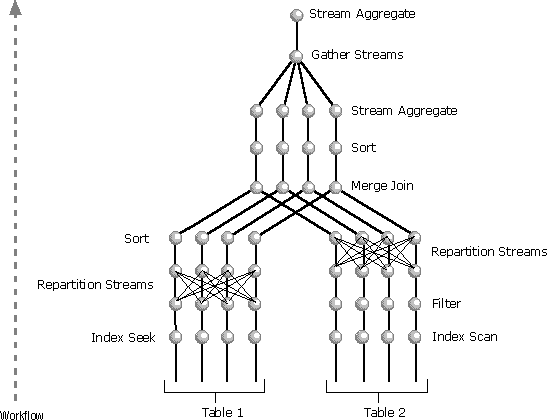
Here is one possible parallel plan generated for the query shown earlier:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 1997 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 1997 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
The illustration shows an optimizer plan executed with degree of parallelism equal to 4 and involving a two-table join.
The parallel plan contains three Parallelism operators. Both the Index Seek operator of the o_datkey_ptr index and the Index Scan operator of the l_order_dates_idx index are performed in parallel, producing several exclusive streams. This can be determined from the nearest Parallelism operators above the Index Scan and Index Seek operators, respectively. They are both repartitioning the type of exchange; they are merely reshuffling data among the streams producing the same number of streams on their output as they have on input. This number of streams is equal to the degree of parallelism.
The Parallelism operator above the l_order_dates_idx Index Scan operator is repartitioning its input streams using the value of L_ORDERKEY as a key so the same values of L_ORDERKEY end up in the same output stream. At the same time, output streams maintain the order on the L_ORDERKEY column to meet the input requirement of the Merge Join operator.
The Parallelism operator above the Index Seek operator is repartitioning its input streams using the value of O_ORDERKEY. Because its input is not sorted on the O_ORDERKEY column values and this is the join column in the Merge Join operator, the Sort operator between the Parallelism and Merge Join operators ensure the input is sorted for the Merge Join operator on the join columns. The Sort operator, like the Merge Join operator, is performed in parallel.
The topmost Parallelism operator gathers results from several streams into a single stream. Partial aggregations performed by the Stream Aggregate operator below the Parallelism operator are then accumulated into a single SUM value for each different value of the O_ORDERPRIORITY in the Stream Aggregate operator above the Parallelism operator.
Logical and Physical Operators