The read requests generated by the system are controlled by the relational engine and further optimized by the storage engine. The access method used to read pages from a table determines the general pattern of reads that will be performed. The relational engine determines the most effective access method, such as a table scan, an index scan, or a keyed read. This request is then given to the storage engine, which optimizes the reads required to implement the access method. The reads are requested by the thread executing the batch.
Table scans benefit from the new data structures introduced in Microsoft® SQL Server™ version 7.0. In earlier versions of SQL Server, data pages were in a doubly-linked chain that often had a somewhat random distribution through the database file. SQL Server had to read each page individually to get the pointer to the next page, resulting in a series of single, somewhat random reads. Read-ahead capabilities were limited. In a SQL Server 7.0 database, the IAM pages list the extents used by a table or index. The storage engine can read the IAM to build a serial list of the disk addresses that must be read. This allows SQL Server 7.0 to optimize its I/Os as large sequential reads in disk order. SQL Server 7.0 issues multiple serial read-ahead reads at once for each file involved in the scan. This takes advantage of striped disk sets.
SQL Server 7.0 also reads index pages serially in disk order, improving the performance of index scans. Index processing is further improved by the use of pre-fetch hints to allow serial read-ahead processing of a nonclustered index.
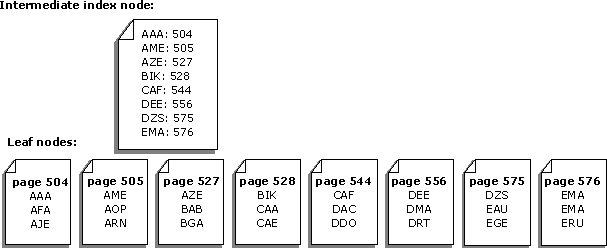
For example, this illustration shows a simplified representation of a set of leaf pages containing a set of keys and the intermediate index node mapping the leaf pages.
SQL Server 7.0 uses the information in the intermediate index page above the leaf level to schedule serial read-ahead I/O's for the pages containing the keys. If a request is made for all the keys from ‘ABC’ to ‘DEF’, SQL Server 7.0 reads turn around the index page above the leaf page but does not simply do a read for page 504, then a read for 505, and so on. until it finally reads page 556, the last one with keys in the desired range. Instead, the storage engine scans the intermediate index page and builds a list of the leaf pages that must be read. The storage engine then schedules all the I/O's in disk order. The storage engine also recognizes that pages 504/505 and 527/528 are contiguous and perform a single scatter-gather I/O to read adjacent pages in one operation. When there are many pages to be retrieved in a serial operation, SQL Server schedules a block of reads at a time. The number of reads scheduled is slightly larger than the value of the max async io configuration option. When a subset of these reads is completed, SQL Server schedules an equal number of new reads until all the needed reads have been scheduled.