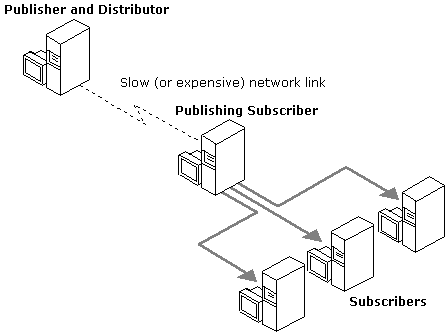
This scenario uses two servers to publish the same data. The Publisher sends data to a Subscriber, which then republishes the data to any number of Subscribers. This is useful when a Publisher must send data to Subscribers over a slow or expensive communications link. If there are a number of Subscribers on the far side of that link, using a publishing Subscriber shifts the bulk of the distribution load to that side of the link.
Note that in this illustration, both the Publisher and the publishing Subscriber are acting as their own local Distributors. If each were set up to use a remote Distributor, each Distributor would need to be on the same side of the slow or expensive communications link as its Publisher. Publishers must be connected to remote Distributors by reliable, high-speed communications links.
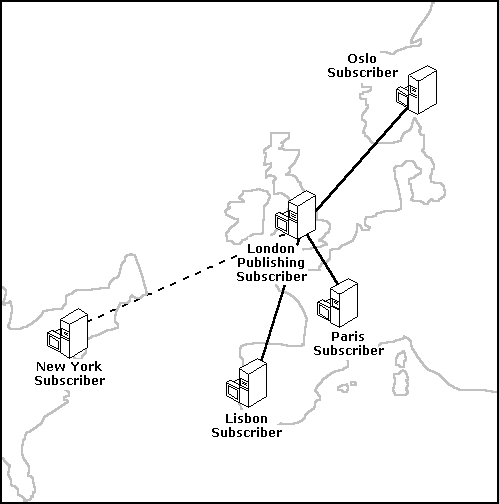
Because any server can act as both Publisher and Subscriber, setting up this configuration is simple. For example, consider the publication of a table that exists in New York and needs to be distributed to four different cities in Europe: London, Oslo, Paris, and Lisbon. The server in London is chosen to subscribe to the published table originating in New York, because the London site meets these conditions: