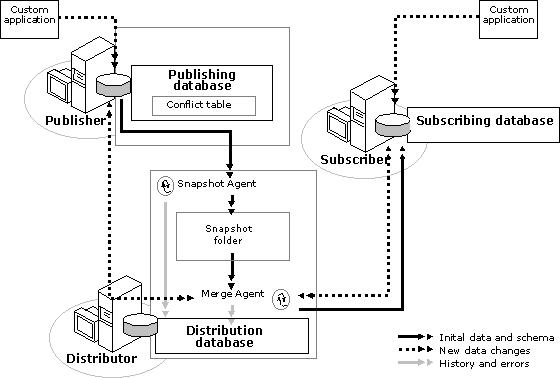
Merge replication tracks changes in a source database and synchronizes the values between the Publisher and Subscribers, all of whom may update data. In merge replication, the Publisher is the server that created the publication. Although the Publisher created the publication, the Publisher does not automatically “win” a conflict with a Subscriber. The winner is determined by criteria you establish. Similarly, data changes at the destination database are propagated to the source database.
As illustrated in the following diagram, merge replication is carried out by the Snapshot Agent and Merge Agent. The Snapshot Agent prepares snapshot files containing schema and data of published tables, stores the files in the snapshot folder on the Distributor, and records synchronization jobs in the publication database. The Merge Agent applies the initial snapshot jobs held in the publication database tables to the Subscriber. It also merges incremental data changes that occurred at the Publisher after the initial snapshot was created, and reconciles conflicts according to rules you configure or using a custom resolver you create.
When a base table is published using merge replication, Microsoft® SQL Server™ makes three important changes to the schema of the database. First, SQL Server identifies a unique column for each row in the table being replicated. This allows the row to be identified uniquely across multiple copies of the table. If the base table already contains a uniqueidentifier column with the ROWGUIDCOL property, SQL Server uses that column automatically as the row identifier for that replicated table. Otherwise, SQL Server adds the column rowguid (with the ROWGUIDCOL property) to the base table. SQL Server also adds an index on the rowguid column to the base table. The rowguid column and the index are added to the base table either the first time the Snapshot Agent executes for the publication or when the article is activated at the time of creation.
Second, SQL Server installs triggers that track changes to the data in each row or (optionally) each column. These triggers capture changes made to the base table and record these changes in merge system tables. The tracking triggers on the base tables are created while the Snapshot Agent for the publication runs for the first time or when the article is activated at creation time. Different triggers are generated for articles that track changes at the row level or the column level. Because SQL Server supports multiple triggers of the same type on the base table, merge replication triggers do not interfere with the application-defined triggers; that is, both application-defined and merge replication triggers can coexist.
Third, SQL Server adds several system tables to the database to support data tracking, efficient synchronization, and conflict detection, resolution and reporting. The tables MSmerge_contents and MSmerge_tombstone track the updates, inserts, and deletes to the data within a publication. They use the unique identifier column rowguid to join to the base table. The generation column acts as a logical clock indicating when a row was last updated at a given site. Actual timestamps are not used for marking when changes occur, nor deciding conflicts, and there is no dependence on synchronized clocks between sites. At a given site, the generation numbers correspond to the order in which changes were performed by the Merge Agent or by a user at that site.
Before a new Subscriber can receive incremental changes from a Publisher, it must contain tables with the same schema and data as the tables at the Publisher. The process that copies the complete current publication from the Publisher to the Subscriber is called the initial snapshot. Replication of changed data occurs only after merge replication ensures that the Subscriber has a current snapshot of the table schema and data. When snapshots are distributed and applied to Subscribers, only those Subscribers waiting for initial snapshots are affected. Other Subscribers to that publication (those that are already receiving inserts, updates, deletes, or other modifications to the published data) are unaffected.
The procedures by which the Snapshot Agent implements the initial snapshot in merge replication are similar to the ones used in snapshot replication.
When setting up a subscription, you can load the initial snapshot on the Subscriber manually instead of sending it over the network. If the publication is very large, it may be more efficient to load the snapshot from a tape or other storage device. For example, if you have a 20 GB database, it may be easier and faster to dump the database to tape, express courier the tape to the Subscriber location, and reload the database instead of sending the file over a slow network. If you opt to load the snapshot this way, SQL Server will not synchronize the published articles with the destination tables. The Merge Agent then assumes that the Publisher and Subscriber are already synchronized, and immediately starts sending inserts, updates, deletes, or other modifications to the published data.
Note If you subscribe to a merge publication without initializing the subscription, you are responsible for ensuring that the table schema and data are identical for the published article and the destination table. Both the Publisher and Subscriber tables must already have a ROWGUIDCOL column and the values for the ROWGUIDCOL column at the Publisher and Subscriber must be identical. Do not simply run at both the Publisher and Subscriber a script to CREATE TABLE, add a ROWGUIDCOL column, and assign a default of newid() to the column. The script will not assign identical values because the information used to calculate the ROWGUIDCOL values is different at the Publisher and Subscriber. Instead, use DTS or bulk copy to move the ROWGUIDCOL values (and other data) from the Publisher to the Subscriber.
When a row is updated in a merge article, (except for updates performed by the Merge Agent for reconciliation purposes), a trigger sets the generation column for that row to 0. When the Merge Agent is executed, it collects all of the rows with generation=0 into one or more groups and assigns generation values that are higher than all previous generations. The Merge Agent at each site keeps track of the highest generation it has sent to each of the other sites, and the highest generation that each of the other sites has sent to it. These provide starting points, so that each table can be examined without looking at data already shared with the other site. The generations stored in a given row can differ between sites because the numbers at a site reflect the order in which changes were processed at that site.
At the time of synchronization, the Merge Agent sends all changed data to the other sites. Blocks of data flow from the changed source to the copy that are required to be updated or synchronized.
At the destination database, arriving values are merged with existing values according to extensible and flexible reconciliation rules. A Merge Agent evaluates both the arriving and current data values, and any conflicts between new and old values are resolved automatically based on assigned priorities, on which user merged changes first, or a combination (with groups of sites at equivalent priorities). Alternatively, you can implement custom resolution strategies for each article through the COM and stored procedure resolver interfaces. Changed data values are replicated to other sites only when a synchronization occurs, and synchronizations can take place minutes, days, or even weeks apart. All sites ultimately end up with the same data values, but not necessarily the ones they could have arrived at had all updates been made at one site simultaneously.
The Merge Agent is a component of SQL Server Agent and can be administered directly by using SQL Server Enterprise Manager. The agents can also be embedded into applications by using Microsoft Active X® controls. The Snapshot Agent executes on the Distributor. The Merge Agent executes on the Distributor for push subscriptions, or on Subscribers for pull subscriptions.
Site autonomy is very high under merge replication. All sites can perform inserts, updates, and deletes on published data on their server, independently of the changes being made on other servers. However, merge replication does not guarantee transactional integrity. Instead, it promotes convergence of the data. All the changes made at all the sites converge over time to the same value, although that value is not guaranteed to be the same value as if all changes had been applied to one site. Thus, this type of replication is inappropriate if transactional integrity is required and the application cannot supply that assurance of integrity by using partitioning.
The Merge Agent detects conflicts through a system column called lineage in MSmerge_contents, which represents the history of changes in a row. The agent updates the lineage column in MSmerge_contents automatically when a user updates a row. Each column contains one entry for each site that has updated the row. Because the lineage is a varbinary column, the number of sites that perform updates determines the maximum size to which the lineage can grow. The entry is a combination of a site identifier and the last version of the row created by that site. When the Merge Agent is merging changes, and it encounters a row that might have changed recently, it examines the lineage of each site’s version of the row to determine if there is a conflict. When conflicts occur, the agent initiates an automatic reconciliation. The “winner” of the conflict can be based on a user-specified priority scheme, a “first wins” solution, or a custom resolution using COM and stored procedures.
Conflicts to the data in the base table can be recognized either at the column level or at the row level. The default option presented through the user interface is column-tracked articles. This option allows changes made to disjointed columns to be merged; only changes made to the same columns are flagged as conflicts. However, in some instances, the business rules of your application may treat simultaneous changes to the entire row as a conflict. In these cases, row-level tracking is an option.
Note SQL Server merge replication is conceptually similar to the replication features of Microsoft Access. SQL Server databases and a future release of Access databases will be able to replicate data to one another.
When the distribution database is created, SQL Server adds two tasks automatically to SQL Server Agent to purge the data no longer needed:
These tasks help replication to function effectively in a long-running environment. The cleanup tasks delete the initial snapshot for each publication and update the history.
| uniqueidentifier | MSmerge_tombstone |
| MSmerge_contents | Reporting and Resolving Conflicts |