As its name implies, snapshot replication takes a picture, or snapshot, of the published data in the database at a moment in time. Snapshot replication requires less constant processor overhead than transactional replication because it does not require continuous monitoring of data changes on source servers. Instead of copying INSERT, UPDATE, and DELETE statements (characteristic of transactional replication), or data modifications (characteristic of merge replication), Subscribers are updated by a total refresh of the data set. Hence, snapshot replication sends all the data to the Subscriber instead of sending just the changes. If the article is very large, it can require substantial network resources to transmit. In deciding if snapshot replication is appropriate, you must balance the size of the entire data set against the volatility of change to the data.
Snapshot replication is the simplest type of replication, and it guarantees latent transactional consistency between the Publisher and Subscriber. Snapshot replication is often used by groups needing to look up data such as price lists, or needing data for decision support, where the most current data is not essential. This type of replication is a good solution for read-only Subscribers that do not require the most recent data. Such Subscribers can be disconnected totally if they are not updating. Snapshot replication is also a good solution for immediate-updating Subscribers that make changes to a database infrequently.
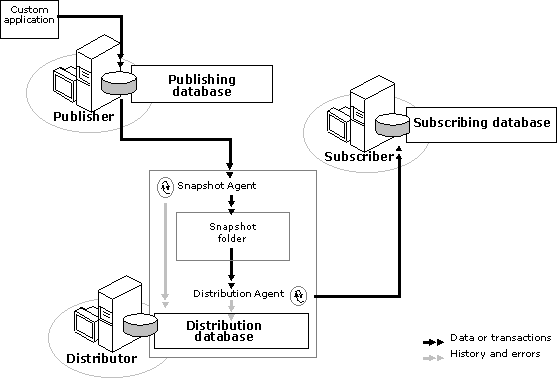
As illustrated in the diagram, snapshot replication is carried out by the Snapshot Agent and the Distribution Agent. The Snapshot Agent prepares snapshot files containing schema and data of published tables, stores the files in the snapshot folder on the Distributor, and records synchronization jobs in the distribution database on the Distributor. The Distribution Agent moves the snapshot jobs held in the distribution database tables to the destination tables at the Subscribers. The distribution database is used only by replication and does not contain any user tables.
Each time the Snapshot Agent runs, it creates schema and data files to be sent to Subscribers. The agent does this in several steps:
Each time the Distribution Agent runs for a snapshot publication, it moves the schema and data to Subscribers. The agent does this in several steps:
When handling a large number of Subscribers, running the Distribution Agent at the Subscriber’s computer (that is, as a pull subscription) can save valuable processing resources on the Distributor.
Snapshots can be applied either when the subscription is created or according to a schedule set at the time the publication is created. When the scheduled time arrives, only those Subscribers who have not been synchronized after the last scheduled synchronization event occurred (therefore, not all Subscribers to that publication) get synchronized. This minimizes the effect on the Publisher.
Note For agents running at the Distributor, scheduled synchronization is based on the date and time at the Distributor (not the date and time at the Subscribers). Otherwise, the schedule is based on the date and time at the Subscriber.
Because automatic synchronization of databases or even individual tables requires increased system overhead, a benefit of scheduling automatic synchronization for less frequent intervals is that it allows the synchronization snapshot to be scheduled for a period of low activity on the Publisher.
When the distribution database is created, SQL Server adds three tasks automatically at the Distributor:
These tasks help replication to function effectively in a long-running environment. After the snapshot is delivered to all Subscribers, replication cleanup deletes the associated .bcp file for the initial snapshots.
| MSrepl_commands | Transferring Data with bcp |
| MSrepl_transactions |