Fragmenting your application’s data is an alternative to applying a filter clause to each publication. For example, if your data can be filtered on regional boundaries, physically store the data in separate tables specific to each region. Replicating the data in these tables does not require costly article filters and greatly simplifies the logical view of the data model. The drawback is the requirement to maintain schema in multiple locations for each table. That is, each region-specific table (essentially the same) must be modified in the event a system-wide schema change is made. For this reason, it is critical that table attributes be well-planned.
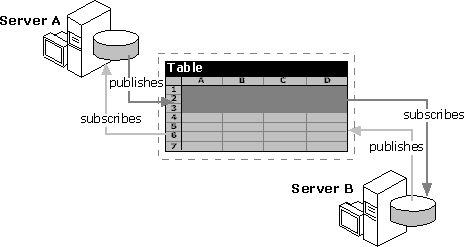
This diagram shows a single table that is maintained at two servers. The table is partitioned horizontally, and each server is the Publisher of the data in particular rows and the Subscriber to data in the remaining rows. Each Publisher controls its own data and has a view of the other data. Stored procedures can be used to allow updates to locally owned data only. This partitioning of the data may be useful, for example, for maintaining common information at regionally dispersed centers, such as warehouses or divisional offices. It could also support regional order processing.
When you partially replicate a database, you must not duplicate a single table in multiple publications targeted for a single site. Redundancy can cause synchronization and blocking problems when replicated data is applied to the Subscriber.
Important In this release of SQL Server, filter procedures referencing a bit column will fail. To work around this limitation, you must change the data type to tinyint or use a different column to filter your data.
| Data Integrity |