![]()
The Microsoft® Site Server Membership Directory is a highly configurable directory service that supports low-end intranet to high-end Internet installations. This paper provides guidelines for deploying high-end (large-scale) implementations involving up to millions of directory objects. A large-scale directory service configuration typically will require the installation and management of multiple computers hosting several instances of the Site Server Lightweight Directory Access Protocol (LDAP) service and Microsoft® SQL Server™. A solid background in the installation and management of Microsoft® Windows NT® Server and SQL Server is highly recommended prior to deployment of a large-scale Membership Directory.
An important phase of system deployment includes identifying the target Membership Directory size, the expected system load (transactions per second), and the overall throughput requirements of the system. This section of the paper will familiarize you with the Membership Directory architecture and various configuration options and provide guidelines to help you decide which Membership Directory configuration and hardware combination will meet the objectives of your site.
Successful deployment and maintenance of a system capable of managing thousands of transactions per second on gigabyte databases can be an overwhelming task. Given the state of today’s technologies, deployment of large-scale, high-performance, network-based applications requires an architecture capable of distributing system load and data across multiple computers. The Site Server Membership Directory is a highly configurable directory service capable of scaling to the requirements of very large sites. The Membership Directory’s three-tier architecture enables sites to transparently distribute application processor, network, and database load across multiple computers.
The Membership Directory three-tier architecture consists of three levels of system resources:
Figure 1 provides an overview of these components.
Figure 1: Overview of the Membership Directory’s three-tiered architecture
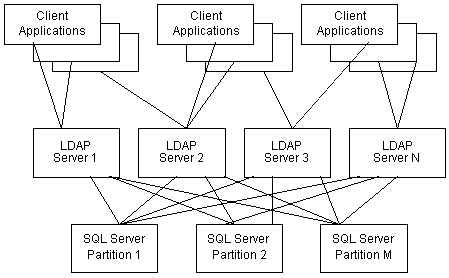
Several application programming interfaces (APIs) and applications can be used to develop customized intranet/Internet sites using a centralized Membership Directory. Microsoft, for example, provides several client APIs that target LDAP directory-based applications. These APIs include the Active Directory Services Interface (ADSI), Site Server Active User Object (AUO) and its supporting ADSI providers (including OLE DB), Active Data Object (ADO), wldap32, and many others, including Java interfaces. You can use these APIs to develop custom and powerful intranet/Internet applications that use a core Membership Directory.
Several Microsoft applications can also use directory technologies that include the Site Server Membership Directory and the upcoming Microsoft® Windows® 2000 Active Directory. The Personalization & Membership (P&M) component of Site Server 3.0, for example, is specifically designed to take advantage of user security information and personalization attributes stored in the Membership Directory. With a central repository and a standardized interface for accessing the user information, you can use P&M to develop powerful Web site applications that are customized and targeted to the individual user. Other Microsoft applications supported by the Membership Directory include Address Book, Microsoft® Internet Explorer version 4.0, Microsoft® Outlook®, and Microsoft® Exchange Server clients, Microsoft® NetMeeting®, and others.
Because the Membership Directory is an LDAP V3-compliant directory service, any third party application or API supporting the LDAP protocol can gain access to it.
The Membership Directory architecture is built around the LDAP service. The LDAP service manages all client connections to the Membership Directory and implements a fully-compliant LDAP V3 protocol. The LDAP service runs as a Microsoft® Internet Information Server (IIS) service, and thus is easily administered within the common Windows NT and IIS service framework.
For best results, each LDAP service that supports your Membership Directory should run on a separate computer (LDAP server). An individual LDAP server can manage hundreds of client connections and hundreds of transactions per second. However, in a very large-scale system that manages thousands of connections and transactions per second, adding multiple LDAP servers to the system can be a viable scalability option. Adding LDAP servers will increase overall system throughput and improve client response latency by balancing system load across multiple servers. The Site Server Service Administration tools make adding additional LDAP servers a very easy process. The only requirement is that new LDAP Services be configured to point to a common predefined Membership Directory database.
Although not shown in Figure 1, server load balancing is typically accomplished through advanced network routing hardware, Domain Name System (DNS), or built-in client logic. Specific Membership Directory configuration and tuning considerations are discussed later in this document.
The Membership Directory database manages the storage of all persistent Membership Directory information. The Membership Directory can store both static and dynamic objects. The Dynamic (RAM-based) Directory is the subject of another discussion and will not be addressed in this document. The Membership Directory currently supports the storage of static or persistent directory information in two primary database storage systems. The first, Microsoft® Access, is intended for small Membership Directory implementations that experience mid- to low-transaction rates (less then 50 queries per second and infrequent or no directory modifications). For larger systems, either Microsoft SQL Server 6.5 or 7.0 is the preferred Relational Database Management System (RDBMS) engine. A three-tiered Membership Directory architecture deployment with SQL Server as the back end can support millions of objects. As will be discussed in the following sections, the Membership Directory architecture supports several database configurations that you can use to balance transaction loads, manage data capacity, and ensure data availability using fault tolerance.
The inherent nature of the LDAP and X.500 (as described in RFC 1308) directory data models is to support the scaling and partitioning of large directories. By offering a hierarchical data model, not only is a site more naturally able to organize its directory information, but at the same time the data can be physically partitioned and distributed to multiple data servers in a seemingly transparent manner. By physically partitioning the directory information, a site can distribute processing load and manage portions of the directory tree on independent data servers. This powerful data model is what enables the directory service to support very large databases. The following section discusses the different directory data management options supported by the Membership Directory.
The Microsoft® Site Server Membership Directory supports a very high volume of objects by allowing the logical partitioning of the Directory Information Tree (DIT) as well as the partitioning of individual containers based on relative distinguished name (RDN) values. Partitioning enhances performance when dealing with very large-scale Membership Directories, because it reduces table and index sizes on a given database and allows for distributing query load in direct lookups, as well as distributing write, modify, and delete loads. Partitioning will provide significant performance benefits in systems that expect to have more than one million objects in the Membership Directory.
The Membership Directory supports two partitioning mechanisms:
With namespace partitioning, specified subtrees of the DIT are stored in separate databases. Although there may be several different reasons a site may choose to partition a Membership Directory, perhaps the two most common are for load and data distribution. If you have a namespace that you expect to handle the majority of the load for your system, supporting it in its own namespace partition may enhance performance. A typical example of this is using the ou=Members container to provide a flat search namespace for your Membership Directory users. Using namespace partitioning, you can configure your system such that all objects that were targeted for the ou=Members container are stored in their own partition.
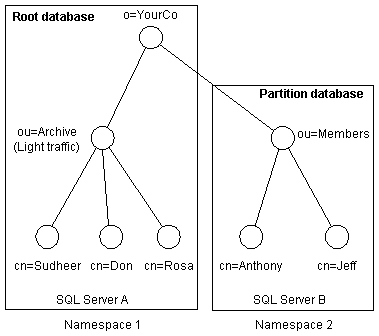
Other reasons for using namespace partitioning may include location of information, ease of administration, or security. Whatever the reason, namespace partitioning is a powerful and flexible mechanism for distributing Membership Directory information.
Value partitioning is an ideal solution if there will be a very large number of objects in a single DIT container. Value partitioning evenly distributes objects among several databases in a namespace. This distribution is achieved by hashing the RDN value of each object.
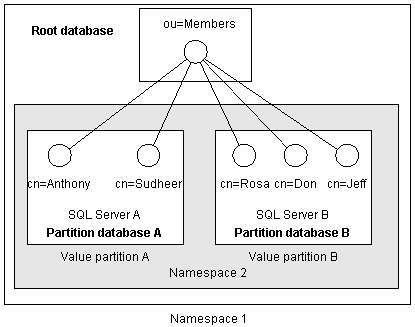
Distribution of very large Membership Directories over several databases will improve the overall system performance for the following reasons:
Distribution of very large Membership Directories over several databases may also be considered for manageability purposes. Rebuilding indexes, database recovery, replication, and other relational database management functions can be more reliable and less time-consuming when accomplished on reasonably-sized databases.
Data can be kept physically distinct on separate databases. Databases supporting different namespaces can be administered independently.
In operations where the RDN is not known (for example, subtree searches and one-level searches), the LDAP Service is forced to check each and every database. This results in increased latency time and network traffic per query.
Note This penalty does not exist for base object searches or write operations.
The LDAP Service uses database connection caching to improve database access time. With multiple databases, the number of connections required in the cache is increased, thus adding additional overhead in terms of both memory and CPU.
For discussions of Membership Directory query issues on partitioned systems, refer to Appendix D.
Referrals are a basic facility supported by LDAP V3-compliant servers. The Site Server LDAP Service supports referrals as a means of integrating independent Membership Directories. In this model, each Membership Directory manages an independent namespace (for example, o=Inspired and o=Microsoft); however, each also supports a referral to the other Membership Directory. LDAP V3 client applications that support referrals can take advantage of this facility. When an LDAP sub-tree query finds a Membership Directory object that is specified as a referral to another Membership Directory, the namespace address for that Membership Directory is returned as part of the search results for that query. If the client application seamlessly supports chasing referrals, then the client can follow the referral to the specified Membership Directory and reissue the query there, as well.
As an example, suppose a merger takes place between two well-established businesses. Further, assume each business already has established an internal Membership Directory for the management of its employees.
Rather than integrating the two databases, you can use referrals to logically connect the two Membership Directories, as depicted in the following figure.
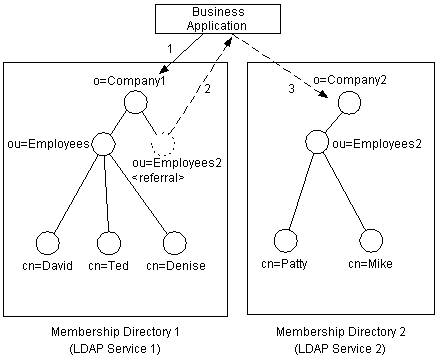
Although referrals can be a powerful and flexible means of distributing Membership Directory information, each Membership Directory’s schema is managed independently. Synchronization of Membership Directory schemas between independent Membership Directories is not automatically supported. Membership Directory schema information, authentication modes, and other configuration-related information must be synchronized manually.
Partition the DIT across multiple databases. A site can host the main object to the directory (dseRoot of DIT) in the Membership Directory root database while moving the organizational unit containers to Membership Directory partition databases, thus providing a level of logical data distribution.
Partition a large Membership Directory container (for example, ou=Members) based on the RDN of the object. The LDAP Service hashes the RDN value, thus distributing the objects across multiple databases.
Use LDAP V3 referrals to connect independent Membership Directories that manage independent namespaces. Provided that an LDAP client supports LDAP V3 referrals, the client can transparently chase referrals. Referrals make the two separately-managed Membership Directories appear to be a single Membership Directory.
In summary, the Membership Directory provides several options for partitioning and distributing data. Each option can be used exclusively or inclusively with each of the others. Nothing in the design prevents a configuration from using all of the previous options. Good planning is the key to a successful partitioning deployment.
Finally, note that re-partitioning a container is not possible in this release of Site Server. Configure your partitions for the volume and traffic you expect to see in 12 to 24 months. If hardware is limited, you can set up multiple databases on a single SQL Server computer and move them to separate SQL Server computers later.
The Membership Directory database model was designed so that the Membership Directory can be extended easily and dynamically to meet the diverse requirements of Microsoft customers. Two key features provide the power of the model. The first is the Directory Information Tree (DIT), which makes it possible to create and organize information in a hierarchical structure. The second is the extensible schema, which makes it possible for sites to derive new object types for storage in the Membership Directory. The fully extensible attributes and classes are derived from the X.500/Lightweight Directory Access Protocol (LDAP) definitions for directory schema support. You can use Site Server Service Administration to create and manage both the DIT and the schema dynamically. You can also administer the DIT and the schema through normal LDAP operations.
The design of the Membership Directory database was driven by two primary objectives. The first was to provide a very flexible and extensible Membership Directory. As mentioned, the database design takes into account key X.500 directory features such as the hierarchical data model, extensible object class definitions, and multi-valued attributes. The second objective was to provide a system capable of hosting large-scale databases with high volumes of query transactions.
The core of the Membership Directory schema is based on two primary tables. The Object_Lookup table stores unique object definitions and enables storage of hierarchical information. The Object_Attributes table stores object attribute definitions. Although very flexible and extendable, these two tables can become very large in a large-scale Membership Directory. With large tables, the Membership Directory partitioning options become a very important design consideration.
To achieve a high level of performance for object lookups, each table is supported with multiple indexes. Unfortunately, indexes have an associated cost in database disk space and expense of transaction performance for insert and modify operations. Although the Membership Directory provides a very flexible, scalable, high-performance solution, it must be balanced against disk space and OLTP (insert/modify/delete) performance. Obtaining good database performance is a challenging task, but with good insight into the database design and with solid knowledge of SQL Server administration and tuning, you can readily achieve a very high level of performance with the Membership Directory.
Given these insights into the Membership Directory database design, you will be better equipped to make solid decisions when building your system and tuning it for high-end performance. For a detailed design overview of the Membership Directory database, see Appendix C.
When tuning and configuring the Lightweight Directory Access Protocol (LDAP) Service layer, you must decide how many LDAP Services, residing on separate computers, should be available. This decision will depend on the expected load of client activity and the desired system throughput. Multiple LDAP servers have been proven through internal testing to scale to the limitations of the underlying databases. Thus, if a well-tuned database system is provided, adding multiple LDAP servers to the system should result in improved system throughput and load balancing.
The specific load that a single LDAP server can manage will depend on several factors, including computer hardware (CPU, RAM, disk speed), resource contention with other processes on the computer, network, client application behavior and load, and underlying database performance. You can expect to get approximately 150 lookups/second, 75 modifications/second, and 20 inserts/second on a P200 with 500 MB of RAM going to a well-tuned, off-box SQL Server 6.5 computer on similar hardware and a Membership Directory of approximately 500,000 objects. In this configuration, adding more LDAP servers continues to scale up performance until the SQL Server computer becomes the bottleneck. At this point, you should consider partitioning your Membership Directory onto multiple databases, thus adding more SQL Server computers. Note that significant improvements are available with SQL Server 7.0 and all of the associated database drivers.
As always, continuous monitoring of system performance is recommended. The Membership Directory provides several performance monitor counters in addition to the system counters that may prove useful in analyzing and tuning system performance (see Appendix A).
The following sections contain some helpful hints and suggestions for tuning your LDAP server.
Always be aware of how much memory is being used by the LDAP server. A computer with inadequate system memory may result in an extensive amount of memory paging by the operating system, resulting in significant performance degradation. Paging should always be avoided, if possible, and the only real solution is to make sure each computer has enough memory available. As a general rule, Windows NT 4.0 Server requires approximately 16 MB of memory and a Site Server installation running only the LDAP Service requires a minimum of 12 MB of memory. Depending on the system load and Dynamic Directory usage requirements, the LDAP Service (discussed later in this topic) memory requirements can grow dramatically. To improve performance, the LDAP Service relies heavily on memory caching and object pooling. Thus, in extreme environments, the LDAP Service has required as much as 80 MB of memory. The minimum requirement for a complete Site Server 3.0 installation is currently 64 MB. However, if your site will be using other Site Server components such as Search, Analysis, Push, and Publishing, and you expect to support extensive client activity, it is highly recommended that you do not skimp on memory.
The Membership Directory supports the LDAP Extensions for Dynamic Directory Services, which applications can use to store dynamic short-lived objects. This feature is implemented by the Membership Directory as a RAM database called the Dynamic Directory. The size of the Dynamic Directory correlates directly to the amount of memory required by the LDAP Service.
To determine exactly how much memory will be required to run the LDAP Service in your environment, monitor the system memory with the application under load with a fully populated Dynamic Directory. By monitoring the private bytes, available bytes, and page faults/second counters in Performance Monitor, you should be able to determine if the system is memory-bound. Additionally, if the LDAP server unsuccessfully attempts to grow any of its internal memory pools to handle the system load, error messages will appear in the Windows NT Event Log indicating that memory resources need to be increased. If memory is insufficient, add memory to the system. If memory is sufficient, then it is possible that the LDAP server has reached one of its internal memory limits. You can configure the maximum number of dynamic objects using Site Server Service Administration or the command-line interface.
It is equally important to be aware of the services and applications that will be running on the same computer as the LDAP Service. If possible, configure the computer as a dedicated LDAP server by disabling or uninstalling any services that are not required; these services may compete for valuable system resources, which can be better used by the LDAP Service.
Important On any computer running P&M, the Site Server LDAP Service, Site Server Message Builder Service, and Site Server Authentication Service must always be left running. Disabling any of these services, even if they do not seem to be used, can cause problems with Microsoft® Management Console (MMC).
As previously discussed, the Membership Directory is tuned for object lookups, not for extensive OLTP environments that involve object creation or decision support system (DSS) environments involving complex queries. Excessive object creation and complex queries have associated database system costs that ultimately impact the overall throughput of the system; you should minimize such operations. If your system requirements include a lot of object creation and complex queries, it is suggested that you carefully analyze and test the system’s performance to ensure it meets your performance objectives before you to push too far with implementation.
Several Membership Directory features have associated costs on overall system performance. For example, transaction logging, access control, password encryption, blacklisting, and distribution list processing can adversely impact system performance, depending on the level of usage. If you do not need these features, make sure you disable them or do not configure them.
System developers should also be aware that the LDAP Service caches the directory hierarchical structure, called the Directory Information Tree (DIT) and the schema for improved LDAP processing performance. Modifications to the DIT or the schema are managed as configuration changes, forcing local and remote cache refreshes to occur, and thus impacting overall system performance. Although supported, applications should avoid depending excessively on runtime modifications to these areas of the Membership Directory and should rely on administrative tools to make these modifications during times when the system load requirements are minimal.
It is equally important when developing custom client applications to understand thoroughly the types of transactions being used. Giving thought to certain design considerations up front, such as implementing support for data and connection caching on the client, can have a tremendous impact on application usability. It is also very helpful to understand the client APIs and number of levels being invoked. The more directly the client API connects to the actual LDAP network interface, the less overhead is incurred. Web developers, for example, should understand that Active Server Pages (ASPs), COM objects, and CGI scripts, which load and create objects and open and close connections over the network for every page-hit, can be very expensive. Application caching of objects, connections, and data can offer tremendous latency and throughput gains..
As previously mentioned, the Membership Directory is optimized for object lookups. Although supported, complex and ambiguous queries should be avoided where possible. Simple LDAP search filters involving single filter components (cn=joe, mail=joe@company, and so on) will provide the best performance. Appendix D provides some helpful hints for specific LDAP searches that are optimized for the Membership Directory.
If system throughput is inadequate and CPU utilization is consistently high on the LDAP server (CPU usage greater than 70percent), then adding an additional LDAP server to the system should help distribute the system load and ultimately increase the overall system throughput. As a guideline for expected LDAP Server performance, refer to Appendix B. As more LDAP servers are added, the database will eventually become the bottleneck. At that point, more sophisticated data distribution options, such as partitioning, will become necessary to continue an upward slope on your scalability graph.
This topic provides some helpful hints and guidelines for obtaining optimal performance with the Membership Directory using a Microsoft® SQL Server™ version 6.5 or 7.0 database. There are already several very good books and papers written about detailed configuration and tuning of SQL Server 6.5. It is highly recommended that system administrators refer to these resources for more detailed discussions, as necessary. Similar resources should soon be available for SQL Server 7.0.
Database tuning of the SQL Server system can be the most challenging and time-consuming aspect of deploying and maintaining a large-scale Membership Directory. Careful planning and analysis in the early phases of deployment are essential to getting a successful system up and running. Ideally, analysis and system design should start with a thorough understanding of the OLTP nature of the environment, what the expected system peak load will be, how big the database is expected to grow, and what level of fault tolerance is required. These key questions will serve to help determine what hardware will be required and what level of maintenance is going to be necessary to maintain the system on a day-to-day basis.
Ideally, SQL Server should run on a dedicated Microsoft® Windows NT® Server computer. All unnecessary services on this computer should be removed or disabled. Additionally, a Windows NT Server computer dedicated to SQL Server should not be configured as a PDC or BDC.
Important The Site Server LDAP Service cannot run properly if it is installed on a computer that runs SQL Server 7.0.
In general, the more data cache SQL Server has dedicated internally, the better it performs. If the computer is a dedicated SQL Server system, then all of the system memory except the 16-20 MB required by the operating system should be given to SQL Server. To determine how much memory is enough, keep adding memory to the system until the cache-hit ratio of the system (under load) stops improving or your budget runs out, whichever comes first. To achieve optimal performance, avoid system paging altogether. If your database will be managing a steady load of activity (100 or more transactions per second) then 500 MB or more of memory is not unreasonable.
Be sure to monitor SQL Server memory usage to ensure memory is used efficiently. If you are using SQL Server 6.5, you can use the DBCC MEMUSAGE command to get a good report of how SQL Server is using memory, including the top 20 largest stored procedures in the cache. If you are using SQL Server 7.0, you can use Windows NT Performance Monitor and the following SQL Server counters:
If the Windows NT Server computer is a dedicated SQL Server system, configure Windows NT for Network applications. To configure it, in Control Panel, click the Network icon, click the Services tab, click Properties for the Server option, and then enable Maximize Throughput for Network Applications. This option is typically set by the SQL Server installation process; however, other applications may override it if they are installed after SQL Server.
Assuming that the SQL Server computer is configured for adequate memory on a reasonably-powered system, I/O remains perhaps the most essential area for performance tuning. As always, the amount of I/O tuning required will depend on the throughput requirements of the system and the amount of capital a site is willing to dump into the system.
If the Membership Directory partitioning feature adequately distributes the data so that SQL Server is not disk bound, then perhaps a moderate I/O subsystem is sufficient. If, however, SQL Server continues to be bottlenecked on I/O, consider distributing the SQL Server devices (data, log, tempdb, and indexes), and take a hard look at the I/O subsystem.
Input/output (I/O) is a critical factor in database performance. A full discussion of this issue is beyond the scope of this document. The list of related documents later in this document includes books about tuning SQL Server and about the importance of I/O tuning.
For a large-scale Membership Directory, it is essential that the I/O subsystem be supported by an optimized disk array that supports striping across multiple disks. Depending on your hardware vendor, it is worth investigating SQL Server benchmarks on specific vendor subsystems and purchasing the level of hardware you think you will need to scale your database.
For SQL Server data files that support the database tables and indexes (device files in SQL Server 6.5 and database files in SQL Server 7.0), it is highly recommended that you implement RAID0 and RAID1 for optimal performance and fault tolerance. RAID0 (striped) provides the best I/O performance; if you need fault tolerance, RAID1 or mirroring is preferred over RAID5 configurations.
Unlike SQL Server 6.5, SQL Server 7.0 does not store databases on logical devices. Instead, each database has a primary data file and at least one transaction log file. A database may also have secondary data files.
You can organize the data files into filegroups. A database can have up to 256 filegroups. Filegroups are useful for placing specific sets of data on specific disk drives or arrays of disk drives. Spreading filegroups across multiple disk drives will improve performance, because SQL Server can then access the data on the different drives in parallel.
For more information about files and filegroups, see Using Files and Filegroups in the SQL Server Books Online.
A key performance consideration is how the distribution of data across multiple logical disks allows SQL Server to distribute the I/O, providing improved system throughput. The most obvious consideration is to create the transaction log on a separate disk that is independent of the data disks. In SQL Server 6.5, this means placing the transaction log on its own SQL Server device on a particular disk. In SQL Server 7.0, this means placing the transaction log files (always separate from the data files) on a particular disk.
The log device does not need to be striped (Compaq RAID0), because the transaction logging is sequential to disk. Compaq RAID1 mirroring will provide the best performance if fault tolerance is to be built into the system. As always, backing up the transaction log is a critical aspect of database recoverability.
Isolation of the tempdb and system databases can also provide good I/O results. As an example, a database configuration that fully distributes the I/O might offer the following configuration:
Separating data and indexes is also a valid approach and is discussed in a later section. This option, however, comes at a heavy expense of complexity and maintenance. In SQL Server 6.5, separating data and indexes relies on database segments. In SQL Server 7.0, separating data and indexes relies on an additional file or filegroup.
Consider partitioning the Membership Directory if you expect it to grow beyond one million objects. Although more complex to administer, a partitioned Membership Directory improves performance and overall throughput by distributing the load across multiple SQL Server computers. If investing in high-end hardware is not an option, partitioning the Membership Directory across several databases may be the best alternative to using a single large database.
If the system memory is inadequate and you do not have the option of adding memory, and your system is experiencing consistently high levels of paging, consider moving the Windows NT page file to a dedicated disk.
In an OLTP environment, disk mirroring is the most efficient fault tolerance approach. RAID5 is also an alternative; although it carries the overhead of check-summing on data writes, it is perhaps the more economical option. Microsoft® Windows NT® Clustering Services are also worth investigating.
Again, whenever discussing fault tolerance, it is recommended that you include a good database backup strategy, which involves regular database backups and transaction log dumps.
The following parameters are recommended as starting points for a newly-configured SQL Server computer supporting a Membership Directory. Most of the other SQL Server configuration parameters were already well tuned by the SQL Server team. As always, the behavior of SQL Server may vary depending on your site-specific configuration and environment, so carefully monitor and analyze any tuning activity.
This tables list the parameters in order of their importance to Membership Directory operations.
The Configuration tab of the Server Configuration/Options dialog box in SQL Enterprise Manager lists all of the parameters in alphabetical order.
| SQL Server 6.5 Parameter | Description |
| Show Advanced Options | Set to 1 to enable all of the available options. |
| Memory | Increase to give as much of the available system memory to SQL Server as possible. This parameter represents the number of 2-KB pages to allocate, so if you are providing SQL Server with 256 MB, then set this value to 128 (approximately half). Do not over-allocate available memory; that will result in system paging, and defeat any efforts at performance improvement.
The memory allocated to the SQL Server data cache is by far the most important aspect of tuning SQL Server. Be cautious about increasing other options that take away from the data cache (for example, connections, hash, locks, objects, and so on). If you get too aggressive with these other parameters, you may be wasting memory that can be better used by the data cache. |
| Hash Buckets | Hash buckets are an important consideration if you have more than 64 MB of memory. Hash buckets are used to optimize data cache page access; thus, the more hash buckets, the better. The default value is approximately 8, with a maximum of 256,003. If you use the maximum setting, you can estimate that it will use approximately 3 MB of SQL Server memory (~12bytes/bucket). As long as it does not compromise the overall size of the data cache, it is recommended that you use the maximum.
Note: The optimal average length of hash buckets is 4. The chain length of hash buckets can be monitored with the following command sequence: DBCC TRACEON(3604) Go DBCC BUFCOUNT Go DBCC TRACEOFF(3604) |
| Procedure Cache | Decrease the percentage as more memory is added. The default value for Procedure Cache is 30 percent, which means SQL Server will reserve 30 percent of its memory for the procedure cache. As more memory is added to the SQL Server computer, 30 percent is probably too much to be allocating to the stored procedure cache, so decrease the percentage to allow more memory to be available for the data cache.
Monitor actual usage with the DBCC MEMUSAGE and DBCC PROCCACHE commands. SQL Server performance monitor counter Procedure Cache Used % can assist in determining if the percentage of the cache is too high. Ideally the percentage of the cache used should be approximately 90 to 95 percent. If it is a lower value, decrease the procedure cache value (and restart the SQL Server computer) so that more memory is available for the SQL Server data cache. |
| Sort Pages | If you have more than 128 MB of memory, set this value to 511 (the maximum). This value specifies the maximum number of pages per user that will be allocated to sorting. |
| User Connections | Increase to 100 or more as needed. Each user connection requires approximately 40 KB of SQL Server memory. If either the SQL Server computer or the computer running the LDAP Service continues to report connection failures, then increase the value as necessary.
Monitor the SQL Server object Max Users Connected counter in Performance Monitor to get a better idea of how many connections your system is using. |
| Locks | Increase to 10000. If SQL Server reports out of lock errors beyond this limit, continue to increase the value as necessary. Locks consume 60 bytes each. |
| Open Objects | Increase to 1000. If SQL Server reports out of object errors beyond this limit, continue to increase the value as necessary. Objects consume 240 bytes each. |
| Max Async IO | Increase if you have good I/O subsystem only or a good I/O subsystem (RAID arrays) and an environment with high OLTP transaction rates. Max Async IO specifies how many outstanding I/O operations SQL Server can have. In a good I/O system, the default value of 8 might be too low. Increase it to approximately 8 times the number of drives you have and increase it from there.
You can monitor Async I/O with the Disk I/O Physical Disk: Disk Queue Length perf counter. If the counter value is consistently less than the configuration option value, the disk subsystem can handle more I/Os. In this situation, increasing Max Async I/O and max lazywrite IO values may result in improved performance. Note: If this parameter is too high, then you could flood the I/O subsystem and hurt overall throughput. Be sure to monitor the system as you are tuning it. If the Disk Queue Length counter indicates a value greater then the configured option, then conversely, decreasing the value may help your system. You may want to check with your hardware vendor for recommendations. |
| Logwrite Sleep | Set to -1 to force all log writes to commit immediately. |
If SQL Server is running on a dedicated computer, set the following parameters.
| Parameter | Description |
| Set Working Set Size | Set to 1 to ensure that Windows NT does not page out any of the SQL Server memory to disk. Make sure the memory is properly configured on the system or you could receive Out of Virtual Memory errors. Ideally, this should not be an issue, because SQL Server should have had ample memory in the first place. |
| Priority Boost | Set to 1 to bump the priority of SQL Server. |
| SMP Concurrency | Set to -1 on multiprocessor systems and 1 on uniprocessor systems. |
The following options (referred to as parameters by SQL Server 6.5) are available in SQL Server Enterprise Manager. You can also set them using the sp_configure stored procedure. For information about these options, see Setting Configuration Options in the SQL Server Books Online.
| SQL Server 7.0 Option | Description |
| Minimum Server Memory/Maximum Server Memory | Unlike previous versions of SQL Server, SQL Server 7.0 dynamically allocates and frees memory. The automatic settings normally will produce the best performance. If you need to set different values, you can specify a range of memory for SQL Server to work within (using the max server memory and min server memory options).
Give as much of the available system memory to SQL Server as possible. Do not over-allocate available memory; that will result in system paging, and defeat any efforts at performance improvement. The memory allocated to the SQL Server data cache is by far the most important aspect of tuning SQL Server. Be cautious about increasing other options that take away from the data cache (for example, connections, hash, locks, objects, and so on). If you get too aggressive with these other parameters, you may be wasting memory that can be better used by the data cache. In SQL Server Enterprise Manager, these options appear in the Memory tab of the Server Properties dialog box as a pair of sliders under Dynamically configure SQL Server memory. |
| User Connections | SQL Server 7.0 manages user connections automatically. If either the SQL Server computer or the computer running the LDAP Service continues to report connection failures, set the value to 100 and increase the value as necessary. Each user connection requires approximately 40 KB of SQL Server memory.
Monitor the SQL Server object Max Users Connected counter in Performance Monitor to get a better idea of how many connections your system is using. In SQL Server Enterprise Manager, this option appears in the Connections tab of the Server Properties dialog box as Maximum concurrent user connections. |
The following options can be set using the sp_configure stored procedure. For information about this procedure and its arguments, see Setting Configuration Options in the SQL Server Books Online.
| SQL Server 7.0 Option | Description |
| Show Advanced Options | Set to 1 to enable all of the available options. |
| Locks | SQL Server 7.0 manages locks automatically. If your system generates errors caused by too few locks, increase the number of locks to 10000. Continue to increase the value as necessary. Locks consume 60 bytes each. |
| Open Objects | SQL Server 7.0 manages open objects automatically. If SQL Server reports out of object errors, set the value to 1000 and continue to increase the value as necessary. Objects consume 240 bytes each. |
| Max Async IO | Increase if you have good I/O subsystem only or a good I/O subsystem (RAID arrays) and an environment with high OLTP transaction rates. Max Async IO specifies how many outstanding I/O operations SQL Server can have. In a good I/O system, the default value of 8 might be too low. Increase it to approximately 8 times the number of drives you have and increase it from there.
You can monitor Async I/O with the Disk I/O Physical Disk: Disk Queue Length perf counter. If the counter value is consistently less than the configuration option value, the disk subsystem can handle more I/Os. In this situation, increasing Max Async I/O and max lazywrite IO values may result in improved performance. Note: If this parameter is too high, then you could flood the I/O subsystem and hurt overall throughput. Be sure to monitor the system as you are tuning it. If the Disk Queue Length counter indicates a value greater then the configured option, then conversely, decreasing the value may help your system. You may want to check with your hardware vendor for recommendations. |
If SQL Server is running on a dedicated computer, set the following options.
| Option | Description |
| Set Working Set Size | Use this option only if you are manually setting the amount of memory that SQL Server uses.
Set to 1 to ensure that Windows NT does not page out any of the SQL Server memory to disk. Make sure the memory is properly configured on the system or you could receive Out of Virtual Memory errors. Ideally, this should not be an issue, because SQL Server should have had ample memory in the first place. In SQL Server Enterprise Manager, this option appears in the Memory tab of the Server Properties dialog box as Reserve physical memory for SQL Server. |
| Priority Boost | Set to 1 to bump the priority of SQL Server.
In SQL Server Enterprise Manager, this option appears in the Processor tab of the Server Properties dialog box as Boost SQL Server priority on Windows NT. |
SQL Server transaction log processing adds quite a bit of overhead to transaction processing. If you are running an OLTP-intensive environment, then the SQL Server background processes (CheckPoint and LazyWriter) can have a substantial impact on overall SQL Server performance. Tuning the subsystem I/O and SQL Server configuration parameters (Max Async IO and Recovery Interval, and for SQL Server 6.5 only, Max LazyWrite I/O and Free Buffers) can help minimize the impact of these processes. However, this only helps if you are running on an advanced I/O subsystem supporting asynchronous I/O to multiple I/O channels.
Note that if the database option Truncate Log on Checkpoint is selected, the Checkpoint process will incur the expense of truncating the transaction log. If your site is transaction-intensive, such truncation will be a very expensive operation. The truncation process will essentially block all write transactions until completion.
If you use the Membership Directory primarily for query and lookup functions with very infrequent updates, and if you are not interested in database recovery under failure conditions, then you can use Truncate Log on Checkpoint with no adverse impact on the system.
The following discussions are intended for database management system (DBMS) administrators who are very familiar with SQL Server administration. This section is not recommended for the novice user. Some of these suggestions should not be attempted on a live mission/business critical system (practice only in an evaluation and testing environment). Results will vary depending on hardware, size of the database, type of data, transaction load, and so on.
Note The Membership Directory SQL scripts are installed in the Microsoft Site Server\Bin\P&M subdirectory. The SQL scripts objtbl.sql, objsp.sql, and indexes.sql contain the primary schema definitions that are discussed in the following sections. Modification of these scripts is not advised and not supported. They are mentioned here as a reference for the table, index, and stored procedure definitions that are discussed in this section.
Include the –x option in the startup command for SQL Server. You can disable statistics collection for a single session by starting SQL Server from the Windows NT command line with the command sqlservr.exe –x.
If you are using SQL Server 6.5, you can add this as a startup option using SQL Enterprise Manager (the Server Parameters dialog box, accessible on the Server Options tab of the Server Configuration/Options dialog box. If you are using SQL Server 7.0, you must edit the Windows NT registry to add the –x option as a persistent startup option. For more information, see Creating and Storing Alternate Startup Options in the SQL Server Books Online (SQL Server 7.0 version).
Note This option disables monitoring of the cache-hit ratio CPU time statistics, so if you are interested in monitoring these, do not include this option as a startup flag.
The procedure for compacting a table, in the current implementation of SQL Server, involves following a linked list of extent pages and allocation units, looking for any empty space for a new row. This behavior is acceptable, and in fact very useful for smaller tables, but once a table becomes quite large (between 1 and 2 GB in size or more) this algorithm causes huge amounts of disk I/O. To avoid that, if the trace flag 1040 is set, SQL Server will try to fit the new row into the current allocation unit (512 KB in size). If that is unsuccessful, it will go to the high end of the structure and insert it there. Refer to Knowledge Base article Q150748 for additional information about GAMINIT.
If your system is experiencing a large number of ambiguous searches (single-level or subtree searches with complex filters), consider placing the SQL Server tempdb in RAM. Significant query performance for LDAP subqueries has been measured with this configuration. Note, however, that using tempdb in RAM requires that the computer have sufficient memory; be sure to monitor the system under load. Overall, it is not recommended that you put tempdb in RAM unless you are absolutely certain SQL Server cannot use the memory more efficiently in its internal SQL Server data cache.
Another option for tempdb is to move it to an isolated device that has write cache enabled. In general, a disk write cache for the data devices is always recommended, so long as the I/O subsystem supports it and guarantees reliability under SQL Server.
SQL Server provides the trace flag 1081. This flag affects buffer management so that index pages are favored over data pages in the cache. You may try this option if data cache-hit ratios are not very high. A low cache-hit ratio may suggest that data access in your environment is random; thus, preferred index caching would be beneficial. If cache-hit ratios increase with this option set, then it may be an improvement for your system. It has been found to have a positive effect on query performance in some query cases. However, it has a negative performance impact on Membership Directory add performance.
For testing, you can set this option dynamically using the DBCC TRACEON/TRACEOFF commands. If this setting looks like an improvement, it can be added to the startup parameter flags using the -t option.
If your I/O subsystem supports multiple I/O channels, it may be advantageous to experiment with moving the Membership Directory non-clustered indexes to isolate them from the transaction log and the data. This should only be experimented with on an offline system.
Note Do not attempt this if you are not an experienced SQL Server administrator.
Isolate indexes by creating a new device on a separate I/O device, and then moving the indexes to this device.
Use the following commands:
Sp_addsegment DS_INDEXES_SEGMENT, DsIndexDevice
Go
Sp_addsegment DS_DATA_SEGMENT, DsDataDevice
Go
Note The data device can be what the default device was before. The idea is to make sure data and index allocations on disk are isolated from each other.
Sp_placeobject DS_INDEXES_SEGMENT, ‘Object_Attributes.IND_vc_Aid’
Go
DROP INDEX Object_Attributes.IND_vc_Aid
Go
CREATE INDEX IND_vc_Aid ON Object_Attributes(vc_Val, I_Aid)
WITH FILLFACTOR=70
ON DS_INDEXES_SEGMENT
Note The previous examples are for a single index only. Ideally this would be done on all non-clustered indexes on the Object_Lookup and Object_Attributes tables.
Sp_placeobject DS_DATA_SEGMENT, Object_Attributes
Go
Sp_placeobject DS_DATA_SEGMENT, Object_Lookup
Go
Isolate indexes by creating a new filegroup on a separate I/O device, and then moving the indexes to this filegroup.
For more information about the steps in this procedure, see the following topics in the SQL Server Books Online:
If your system is OLTP-intensive (large numbers of add, modify, and delete transactions), you may be able to use PAD_INDEX and Fill Factor values for the database indexes to avoid page splitting. Page splitting is an expensive database operation in SQL Server. If page splitting occurs frequently, it will impact the overall throughput of the system. As a general rule, a fill factor of between 50 and 70 percent to all of the indexes should be adequate.
To maintain the advantage of having a fill factor and to avoid SQL Server page-splitting overhead, system administrators should use the DBCC DBREINDEX command to rebuild the indexes periodically (during off-hours).
You can detect page splitting by monitoring the performance counter I/O Single Page Writes/sec. If you have a lot of single-page write activity during OLTP processing, it is highly likely that SQL Server is busy splitting index pages.
Note Adding a fill factor value to database objects increases the size of the database and can adversely impact query performance, because the amount of data required to read database pages from disk increases due to the data padding. A fill factor is added to some of the Membership Directory indexes by default, so if your site is more concerned with search performance and/or database sizing, you should consider removing the fill factor from the Object_Lookup and Object_Attribute table indexes.
Rebuilding indexes is another useful way to remove fragmentation from the database. Fragmentation can have a large impact on I/O performance, so you should monitor it and remove it periodically. Use the DBCC SHOWCONTIG command to monitor how contiguous the pages are on a given index (scan density).
For a site that is migrating data into the database or populating the database with a large set of data, the insert performance of the database can be a significant issue. Rather than adding a fill factor and rebuilding indexes periodically, another option may be to temporarily remove some of the table indexes from the database.
Drop the following non-clustered indexes during migration of Membership Directory objects:
Once the tables have been populated, you must recreate these indexes or else several types of LDAP Service queries may fail or return operation errors. In any case, once you finish populating the database it is always a good idea to rebuild the indexes. Rebuilding the indexes removes fragmentation and re-establishes the fill factor (if used).
Note This information does not apply to SQL Server 7.0, which automatically updates database statistics.
SQL Server 6.5 requires that you manually update database statistics as the database table and index sizes change over time. This ensures the SQL Query Optimizer selects the optimal indexes for the processing of database requests. Failure to periodically update the database statistics can result in dramatic performance degradation as the database characteristics change.
Execute the following commands against each Membership Directory database in the system (including all partition databases) regularly to ensure the statistics are up to date:
DBCC UPDATEUSAGE (0, Object_Lookup) WITH NO_INFOMSGS, COUNT_ROWS
go
DBCC UPDATEUSAGE (0, Objects_Attributes) WITH NO_INFOMSGS, COUNT_ROWS
go
Update statistics Object_Lookup
go
Update statistics Object_Attributes
go
Sp_recompile Object_Lookup
go
Sp_recompile Object_Attributes
go
You can run this command manually from ISQLW or run it as a scheduled task from within SQL Enterprise Manager.
Rebuilding the indexes on a regular basis is essential for optimizing performance. When you rebuild indexes, the database is able to compress the clustered index/data pages and reclaim unused pages. If clustered indexes were created with a fill factor value, rebuilding the clustered indexes periodically will re-establish the fill factors and avoid future page splitting. You can monitor fragmentation by using the DBCC SHOWCONTIG command.
Use the DBCC DBREINDEX command to rebuild indexes.
For example, the following will rebuild all indexes for the two primary Membership Directory tables with a fill factor of 80:
DBCC DBREINDEX ( ‘object_lookup’, ‘’, 80, SORTED_DATA_REORG)
go
DBCC DBREINDEX (‘object_attributes’, ‘’, 80, SORTED_DATA_REORG)
go
Note When you are using SQL Server 6.5 and a database segment fills up, SQL Server requires that either the segment be extended or some database objects be dropped. If there is no more disk space available to extend the segment, try dropping a few of the non-clustered indexes. Rebuild the clustered indexes as described earlier, and then re-add the indexes that you dropped. This process should free up disk space by compressing the clustered index/data pages.
Note When rebuilding indexes, the database should have approximately 1.2×index size MB disk space available.
Note One technique often considered for rebuilding databases is to use the bcp utility (out/in) on the database and then rebuild the indexes.
Note Re-partitioning disk devices prior to installing SQL Server is a good way to ensure that SQL Server starts off with no fragmentation. You can accomplish this using Windows NT Disk Administrator or Windows NT Setup.
As previously discussed, if the Truncate Log on Checkpoint database option is not set, you must periodically administer the log using backups (dump transactions) or truncate procedures. If the log fills up, SQL Server will cease all database activity. To return the system to service, the administrator must manually extend the log database size (in SQL Server 6.5) or truncate the log.
The Membership Directory requires that SQL Server be configured to support TCP/IP Network connections. This is the default configuration of SQL Server 7.0, but not of SQL Server 6.5.
Although not required, it is recommended that you create multiple devices on independent I/O channel drive combinations. Ideally, you should dedicate a single device channel to each Membership Directory database, transaction log, and master database, respectively.
To comply with LDAP v3, the Membership Directory requires that SQL Server be installed with case-insensitive sort order.
For most Western European languages, it is recommended that you use code page 850 and alternate dictionary sort order (case insensitive).
The following tools are useful for scheduling maintenance tasks:
| Object | Counter |
| Processor | % Processor Time |
| PhysicalDisk | Disk Transfers/sec
Current Disk Queue Length |
| Memory | Pages/sec
Page Faults/sec |
| Process | % Process Time |
Object: Site Server LDAP Service
Counters:
Object: SQLServer
Counters:
Use these guidelines when connecting a single Lightweight Directory Access Protocol (LDAP) Service to a single SQL Server computer. This information is provided as a guideline only. Numbers will vary depending on the many hardware, LDAP Service, and SQL Server configuration and tuning options discussed in this document.
For more detailed analysis and performance information, refer to the Microsoft Site Server 3.0 Membership Directory Capacity and Performance Analysis white paper.
Note Your performance numbers may vary from those provided here based on your hardware and software platform.
LDAP Server. 1-, 2-, or 4-processor Pentium Pro; 200 MHz with 512 MB of RAM, Site Server, Commerce Edition, Internet Information Server, Windows NT Server version 4.0 (Service Pack 3).
SQL Server 1. 4-processor Pentium Pro; 200 MHz with 512 MB of RAM, SQL Server 6.5 with Service Pack 4 or SQL Server 7.0, Windows NT Server version 4.0 (Service Pack 4).
| Transaction | LDAP Server, one processor |
| Xact/s | |
| Base object search - random | 180 |
| Onelevel search – random | 180 |
| Subtree search – random | 110 |
| Add new 20-attribute user | 4 |
| Modify (replace) | 110 |
| Modify (add) | 110 |
| Connect and Bind | 100 |
In estimating the size of your database, it is important to understand certain aspects of the Membership Directory database design. Following are a few guidelines and rough estimates of expected database sizes. Note that there are a number of variables that have substantial influence on database space. This section offers very general guidelines and, perhaps, a few insights into areas that can influence space allocations.
The following are some Membership Directory features that affect database storage requirements.
| Feature | Description |
| Image Data | SQL Server 6.5 allocates a minimum of 2 KB per image value. The Membership Directory stores binary attributes in an image column. Also, any varchar value over 256 bytes gets stored in an image column. Note, however, that the Membership Directory supports auto-inheritance from containers, so that security descriptors are not stored on leaf objects unless the administrator has explicitly set a unique access control entry (ACE) on the object. Default security descriptor storage is already minimized by the Membership Directory design.
SQL Server 7.0 does not have a minimum size for image values, and it can store varchar values of up to 8000 bytes. |
| Groups membership | Each user-to-group membership relationship is created as an object in the Membership Directory. |
| Fill factor | Using a data fill factor will increase database storage size. The Membership Directory default is 70 percent on non-clustered indexes. If insert performance is not an issue for your site, you may consider removing the fill factor on these indexes to reduce database storage requirements. |
| Operational attributes | Every Membership Directory object has an associated overhead in the Membership Directory for operational attributes. There are nine operational attributes ( creator’s name, creation timestamp, security descriptor, object class, and so on), which require an average of 700 bytes per object. |
Each object attribute is stored as a row in the Object_Attributes table.
The Membership Directory is optimized for object lookup performance. The indexes added to support object lookups play considerably into the storage numbers. Currently, a total of 10 indexes are created on the two core Membership Directory database tables.
A partition should not exceed one million objects or 20 million attributes. With more than 20 million attributes, overall administration of tables and indexes becomes significant. For example, when you attempt to recover or rebuild parts of the system, the time needed to rebuild an index or update statistics becomes significant. The following table provides examples of database size estimates.
| If you have | Then you need |
| 10,000 objects | 100 MB of disk space |
| 250,000 objects | 2,500 MB of disk space |
1,000,000 objects
|
6,000 MB of disk space |
This example assumes the following:
The following naming conventions will be followed throughout the schema description:
Attribute: Property of a record, which might be traditionally represented as a column in a relational database.
Value: Value associated with an attribute of a given record. This might be traditionally represented as the intersection of a row and column in a relational database.
Class: Definition of the attributes that compose a record. This might be traditionally represented as a table definition in a relational database. Note that a class may define classes as attributes (see “Containership,” later in this Appendix).
Object: An instance of a class, which composes a complete record in the database. This might be traditionally represented as a row in a relational database.
Note In an Object Database Management System (ODBMS), each unique record is traditionally tagged with an Object ID (OID). Unfortunately, this terminology conflicts with the X.500 terminology of OID. In this document, DSID is used to define the unique record identifier within the database.
Containership: The concept of modeling the hierarchical relationships within the Directory Information Tree (DIT). The DIT is a representation of all of the information in the Membership Directory as a hierarchical structure, or tree, of objects. An object’s class definition can define it as either a container or a leaf object. Containers have child objects under them in the DIT; these child objects can be either leaf objects or more containers and so forth. Leaf objects cannot have children.
The following tables exist in the Membership Directory root database, and contain configuration information for the entire Membership Directory (including Membership Directory partition databases).
The configuration table maintains information pertinent to the configuration of the specific SQL Server computer.
| Column Name | Type | Description/Notes |
| i_Replication_Key | Int | Unique key value to allow replication of this table.
Not used. |
| i_id | int | Identification number for this LDAP Service. |
| i_Container_Partition_ID | int | Identification number of the parent partition of this partition (where the container object used to create this partition resides)
Does not apply to the root partition, which contains the o= node of the directory information tree (DIT). |
| i_Container_Partition_DSID | int | DSID (within the parent partition) of the container object used to create this partition.
Does not apply to the root partition, which contains the o= node of the directory information tree (DIT). |
| vc_PeKey | varchar | Security key. |
The DsConfiguration table maintains information pertinent to the configuration of the specific SQL Server installation in relation to the LDAP Services supporting the Membership Directory.
| Column Name | Type | Description/Notes |
| i_ServerId | int | Identification number of the LDAP Service among its peers. |
| i_InstanceId | int | Identification number of the Membership Server instance among the other Membership Server instances on the same computer. The instance_id and server_id combine to establish unique replication interfaces. |
| vc_ServerName | char | LDAP server name. |
| i_DynamicDbFlags | int | Configuration information for the Dynamic Directory. |
| i_Replication_Flags | int | Configuration information for replication. |
| vc_ReplicationProto | char | Replication protocol. |
| vc_Replication_EndP | char | Replication protocol end point. |
| i_ReplicationQSize | int | Maximum size for the replication queue. |
| i_ReplicationLagTime | int | Maximum allowable lag time before replication. |
| i_ReplicationBufferSize | int | Maximum allowable replication buffer size. |
| i_ReplicationSyncTime | int | Maximum allowable time before replication re-synchronizing. |
| vc_ReplicationInfo | char | Replication interface globally unique identifier (GUID); allows multiple LDAP Services that support replication to coexist on a single computer (not a recommended configuration). |
The DsTimestamp table stores timestamp information that allows the LDAP Services to know when the last schema change, DIT change, group change, or Decision Support Object (DSO) change took place.
| Column Name | Type | Description/Notes |
| i_Replication_Key | int | Unique key value to allow replication of this table.
Not used. |
| dt_SchemaTimestamp | datetime | When the last schema change took place. |
| dt_DitTimestamp | datetime | When the last DIT change took place. |
| dt_ReplicationTimestamp | datetime | When the last replication change took place.
Not used. |
| dt_GroupTimestamp | datetime | When the last group change took place. |
| dt_DSOTimestamp | datetime | When the last DSO change took place. |
The Subrefs table maintains a list of the namespace partitions in the Membership Directory.
| Column Name | Type | Description/Notes |
| i_Namespace_Partition | int | Identification number of the namespace. |
| vc_Subref_Entry | varchar | Distinguished name (DN) of the object that is at the top of the DIT in this namespace. |
| i_Subref_Parent_Id | int | Not used. |
| i_ValuePartition_Count | int | The number of value partitions that support the namespace. |
The DsoGrid table maintains a list of the SQL Server computers that support all of the partition databases for this Membership Directory. This table only exists in the Membership Directory root database.
| Column Name | Type | Description/Notes |
| i_Namespace_Partition | int | Identification number of the namespace supported by this database. |
| i_Value_Partition | int | Identification number of the value partition supported by this database. |
| i_Server_Id | int | Unique server identification number for this SQL Server computer (identity, NOT NULL). |
| i_DSO_Type | int | The DSO Type for this database. Must always be 1 for this release, reserved for future use. |
| vc_Datasource | varchar | Server name for the SQL Server computer. (NOT NULL) |
| vc_Database | varchar | Target database for the LDAP Service-to-database connection. (NOT NULL) |
| vc_Login | varchar | Login for the LDAP Service-to-database connection. |
| vc_Password | varchar | Password for the LDAP Service-to-database connection. |
| i_Max_Cnx | int | Maximum connections the LDAP Service should hold open against the database. |
| i_Timeout | int | Timeout value the LDAP Service should use for connections to the database. |
| i_Replication_Type | int | Indicates whether this database is intended for read operations, write operations, or both, and whether the LDAP Service-to-database connection has been blocked by the administrator. |
The following tables exist in a root configuration database on the SQL Server computer that runs the Membership Directory root database. These tables contain configuration information for the root of the Membership Directory. These tables will be read at DLL load time, and will be modified when changes are made to the DIT or schema.
This table is loaded at configuration time, and provides the list of attributes supported by this Membership Directory. This table is modified when attribute definitions are created, modified, or removed. This table makes it possible to represent an attribute’s name, type, and syntax restrictions in the database by knowing its ID.
| Column Name | Type | Description/Notes |
| i_AID | int | Attribute ID, the unique identifier for an attribute.
This value provides a space-efficient representation of an attribute definition. This will be an identity table, allowing you to create a unique AID by inserting the new attribute. (IDENTITY(1,1), NOT NULL, PK) |
| vc_Name | varchar | Name (or comma-separated list of names) the LDAP Service will use to refer to this attribute.
An example of a multi-valued name list that refers to one attribute might be streetAddress, postalAddress, mailAddress where you want to be able to refer to the data by any of those names. This may be particularly useful in localization scenarios. (NOT NULL) |
| vc_OID | varchar | Directory Object ID that represents this attribute.
This is a decimal-dot-decimal representation of the attribute. For the purposes of the Membership Directory, this is another name for the attribute. (NULL) |
| vc_Description | varchar | Description of the attribute. (NULL) |
| i_Data_Type | int | SQL data type that should be used to store this attribute.
This is the enum value of the type as defined in the Membership Directory access code. (NOT NULL) |
| bit_MultiValued | bit | Whether this attribute may be multi-valued in a container (i_Container_CLSID).
This indicates the single-value/multi-valued property. (NOT NULL) |
| bit_Searcheable | bit | Whether this is a searchable attribute in a container (i_Container_CLSID).
This indicates whether the attribute instances will be stored in the Object_Attributes table or the NoSearch_Objects table. (NOT NULL) |
| c_GUID | char | GUID that will identify a specific attribute definition to Windows NT access control lists (ACLs). (NOT NULL) |
| i_Syntax | int | LDAP syntax restrictions for this attribute. |
| vc_Constraints | Char | Constraints for this attribute. |
| img_ACL | bin | ACL that controls access to this attribute definition. |
This table is loaded at configuration time, and provides the list of classes supported by this Membership Directory. This table would be modified when class definitions are created, modified, or removed. This table makes it possible to represent a class’s name and member attributes in the database by knowing its ID.
| Column Name | Type | Description/Notes |
| i_CLSID | int | Unique identifier for the class.
This is used to provide a space-efficient representation of a class definition. (IDENTITY(1,1), NOT NULL, PK) |
| vc_Name | varchar | Name (or comma-separated list of names) the LDAP Service will use to refer to this class.
See Attributes Table earlier in this document. (NOT NULL) |
| vc_OID | varchar | Directory Object ID that represents this class.
This is a decimal-dot-decimal representation of the class. (NULL) |
| vc_Description | varchar | Description of the class. |
| i_RDN_AID | int | Determines what attribute should be used to set the entryName value for instances of the class.
This is provided as information for the cache/replication layer; the Membership Directory will not enforce this. (NOT NULL) |
| c_GUID | char | GUID that will identify a specific attribute definition to Windows NT access control lists (ACLs). (NOT NULL) |
| i_Dse_DitType | int | DIT Type for objects of this class (typically leaf or container). |
| vc_DisplayName | varchar | Friendly name for the class. |
| bit_IsSecurityPrincipal | bit | Whether objects of this class are security principals. |
| i_Container_Type | int | Container type of the class. |
| img_DefaultSecurityDescriptor | image | Default ACL for an object of this class. (NOT NULL) |
| img_ACL | bin | ACL that controls access to this class definition. |
This table maintains the class/attribute hierarchy; for each attribute, the table identifies the classes that can contain this attribute. You can use this information to see what attributes a given class contains, or to see which classes must release the attribute from their definitions before the attribute can be removed from the schema.
| Column Name | Type | Description/Notes |
| i_Replication_Key | int | Unique key value to allow replication of this table.
Not used. |
| i_AID | int | ID of the attribute referenced in this row.
This must be an attribute defined in the attributes table. (NOT NULL, FK(Attributes.i_AID)) |
| i_Container_CLSID | int | CLSID of a class that has this attribute as part of its definition.
This is a CLSID defined in the classes table. (NOT NULL, FK(Classes.i_CLSID)) |
| bit_Required | bit | Whether this is a required attribute in a container (i_Container_CLSID).
This indicates the may-have/must-have property. (NOT NULL) |
This table maintains the object/class hierarchy. For each class, the table identifies the objects that can contain this class. You can use this information to see what classes a given object contains, or to see which objects must release the class from their definitions before the class can be removed from the schema.
| Column Name | Type | Description/Notes |
| i_Replication_Key | int | Unique key value to allow replication of this table.
Not used. |
| i_CLSID | int | Class referenced in this row.
This must be one of the classes defined in the classes table. (NOT NULL, FK(Classes.i_CLSID)) |
| i_Container_CLSID | int | CLSID of a class that has this class as part of its definition.
This is a CLSID defined in the classes table. (NOT NULL, FK(Classes.i_CLSID)) |
The following tables will be used to store the database representations of static Membership Directory objects.
This table provides rapid access to those attributes that are present in all objects and are single valued.
Note Use of this table may be extended to include commonly-searched single valued attributes.
| Column Name | Type | Description/Notes |
| i_DSID | int | Unique database ID that denotes a specific object (record) in the database.
There will be a 1-to-n mapping of this DSID to the DSIDs present in the Object_Attributes table. Specifically, no DSID may exist in the Object_Attributes table without a matching DSID existing in the Object_Lookup table. This column will be an identity column, and will allow you to generate unique DSIDs by inserting a row into this table. (IDENTITY(1,1), NOT NULL, PK, CLUSTERED) |
| vc_entryName | varchar | Relative distinguished name (RDN) that, together with the RDNs of this object’s containers, form the distinguished name (DN) for this object. (NOT NULL) |
| i_objectClass | int | CLSID that defines the class of this object. (NOT NULL, FK(Classes.CLSID)) |
| i_Container_DSID | int | DSID of the object that contains this object, if any.
This allows for both navigation and containership. Note that the idea of “multi-containership” (an object contained by more than one parent) is not supported in this model. (NULL, FK(Object_Lookup.i_DSID)) |
| i_DSE_Type | int | DSE type of the object.
Indicates whether the object is a member of the DIT, a referral, a subref, an alias and so on. (NOT NULL) |
| vc_creatorsName | varchar | Not used. |
| dt_createTimestamp | datetime | Not used. |
| vc_modifiersName | varchar | Not used. |
| dt_modifyTimestamp | datetime | Not used. |
| img_ACL | image | Not used. |
| dt_Expires_Time | datetime | Not used. |
As the varchar type is limited to 255 characters in SQL Server 6.5, the img_val column will be used to store long strings that cannot be contained in the vc_val field. This column will not be indexed and, with the exception of binary values or text values in excess of 255 characters, will default to NULL. If a value in excess of 255 characters is inserted into the Object_Attributes table, the first 255 characters will be put in the vc_val column, and the entire entry will be stored in the img_val column. Only the first 255 characters of such entries will be indexed and searchable.
Note SQL Server 7.0 allows the varchar type to contain up to 8000 characters instead of just 255 characters. However, the Membership Directory tables have not yet been updated to take advantage of this larger capacity.
| Column Name | Type | Description/Notes |
| i_DSID | int | Unique database ID of an object.
There will be many duplicate DSIDs in the Object_Attributes table, one for each attribute/value pair that composes the object. (NOT NULL, FK(Object_Lookup.DSID)) |
| i_Sequence | int | Extension to the DSID used for clustering and replication.
This will be a SQL Server identity column. The SQL Server team feels this will enhance its performance. (IDENTITY(1,1), NOT NULL) |
| i_AID | int | Attribute ID that identifies the attribute associated with the value in this row. (NOT NULL, FK(Attributes.i_AID)) |
| vc_Val | varchar | Value associated with the attribute tag in this row, or the first 255 characters of the value if the value exceeds 255 characters in length.
The value for the attribute/value pair will be searched and indexed from this column, and retrieved from this column in those cases when text_Val contains NULL. (NULL) |
| i_Val | int | Integer value associated with the attribute tag in this row. (NULL) |
| vb_Val | varbin | Not used. |
| img_Val | image | Binary value associated with the attribute tag in this row, or the binary representation of the text value for the row if this value is greater than 255 bytes in size. (NULL) |
| dt_Val | datetime | Datetime value associated with the attribute tag in this row. |
| dt_Expires_Time | datetime | Not used |
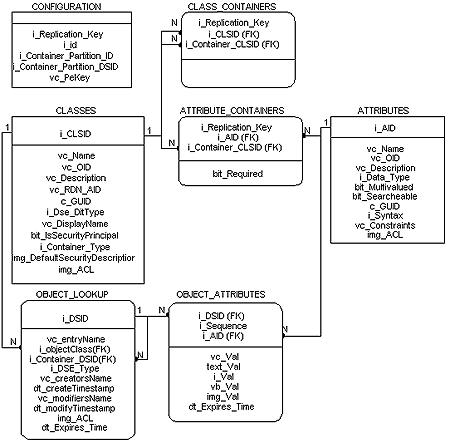
Entity Relationship Diagram for the Membership Directory database tables:
The following indexes will be defined on the tables in the Membership Directory databases.
The following indexes will be defined on the Object_Lookup table.
| Index Name | Description |
| uind_DSID | Used when creating and modifying objects whose DSIDs have already been determined. (UNIQUE) |
| ind_Container | Used when finding objects that are contained by a known object (for example, find all records within a given Organization). |
| uind_entryName_Container_objectClass | Used for distinguished name (DN) navigation. (UNIQUE) |
The following indexes will be defined on the Object_Attributes table.
| Index Name | Description |
| cind_DSID_AID_Sequence | Used for retrieval of objects once the DSID has been determined.
Clustering will allow very rapid retrievals of targeted DSIDs. (CLUSTERED) |
| ind_<type>_AID Index | Used when searching for objects that contain specific attribute/value pairs, for example, cn=Alex Weinert (Attribute CN, Value Alex Weinert).
Note that one index must be defined for each allowed attribute type (for example, each <type>_val to AID possibility). Because you can expect much less duplication of given values than of attributes, the value is used as the primary for the index. For example, you can expect to see more Last Names in the attributes field than instances of Weinert in the values field |
The Membership Directory is primarily optimized for object lookup queries. This section serves as a general guideline, outlining the LDAP queries users should expect to produce the best performance. The Membership Directory supports LDAP V3 search filtering; however, it is not specifically optimized for complex searches that include complex combination of ANDs, ORs, and so on.
Scope: Base; Distinguished Name (DN): any; Filter: any.
Example: DN: cn=mary,ou=members,o=microsoft; Filter: objectClass=*
Scope: SubTree; DN: empty or root of DIT (for example, o=microsoft); Filter: Single exact match (for example, cn=mary).
Example: DN: o=microsoft; Filter: cn=mary
Scope: SubTree; DN: any; Filter: all ORs and all same attribute type (for example, unicodeString, integer, or date).
Example: DN: ou=members,o=microsoft; Filter: (|(cn=mary)(sn=smith)
Note When using SQL Server 7.0, if you perform subtree searches that search on attributes other than the Relative Distinguished Name (RDN), performance may not be better than on SQL Server 6.5.
Scope: SubTree; DN: root context only; Filter: all ORs and all mail attribute type.
Example: DN: o=microsoft; Filter: (|(mail=msmith@domain.com)
Scope: SubTree; DN: root context only; Filter: Mixed combinations of mail, surname, givenname, and cn attributes.
Optimized filter combinations:
Favor baseobject searches wherever possible. These searches have no penalty for partitioning (no additional queries). One-level lookups are the next choice, because they will only touch the value partitions supporting a given namespace. A subtree search is the last choice in a partitioned environment, because the search must touch every database that supports the base container or any container under it.
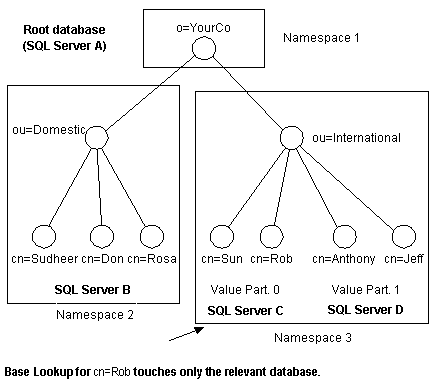
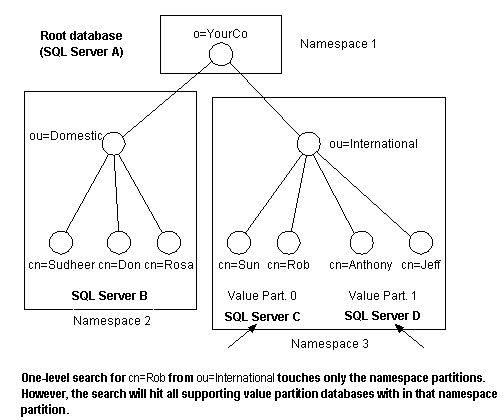
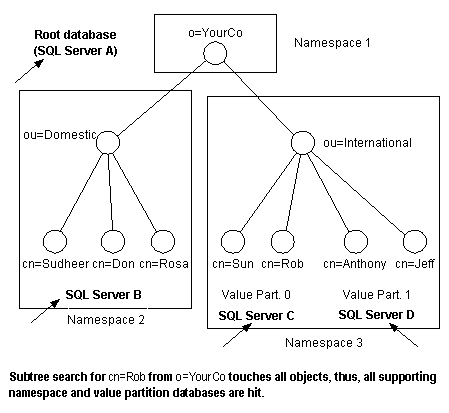
For the latest information about Microsoft® Windows NT® Server, go to the Windows NT Server Web site at http://www.microsoft.com/backoffice or the Windows NT Server Forum on MSN™, The Microsoft Network online service (GO WORD: MSNTS).
Information in this document, including URL and other Internet web site references, is subject to change without notice. The entire risk of the use or the results of the use of this resource kit remains with the user. This resource kit is not supported and is provided as is without warranty of any kind, either express or implied. The example companies, organizations, products, people and events depicted herein are fictitious. No association with any real company, organization, product, person or event is intended or should be inferred. Complying with all applicable copyright laws is the responsibility of the user. Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise), or for any purpose, without the express written permission of Microsoft Corporation.
Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document. Except as expressly provided in any written license agreement from Microsoft, the furnishing of this document does not give you any license to these patents, trademarks, copyrights, or other intellectual property.
© 1998-2000 Microsoft Corporation. All rights reserved.
Microsoft, BackOffice, Microsoft Press, NetMeeting, Outlook, Windows and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the U.S.A. and/or other countries/regions.
The names of actual companies and products mentioned herein may be the trademarks of their respective owners.