![]()
This document provides an overview of the effectiveness with which the Membership Directory can scale. Details are provided in a separate document included in the Microsoft® Commercial Internet System (MCIS) Resource Kit titled Site Server 3.0 Membership Directory Capacity and Performance Analysis.
In this summary, several assumptions are made about a representative user profile. Scalability is discussed based on these assumptions, and on the observed costs of the transactions in the Membership Directory. The two factors that must scale are LDAP Servers (computers that run instances of the LDAP Service) and the SQL Server disk subsystem.
Operational and database design and directory organization are not taken into consideration in this summary. This is purely a performance and scaling view of the Membership Directory.
Note Your performance numbers may vary from those provided here based on your hardware and software platform.
The following system configurations were used in the original test scenarios:
| LDAP Server1 | CPU | 1, 2, and 4 X 200 MHz Pentium Pro |
| Memory | 512 MB of RAM | |
| Disk | 4 GB Raid 0 | |
| Network | 100 BaseT (switched) | |
| Software | Microsoft® Windows NT® 4.0 operating system Option Pack, Microsoft ® Internet Information Server |
1. One LDAP server was used to test LDAP processor scaling. Three LDAP servers were used to test scaling to multiple servers.
| SQL Server2 | CPU | 4 X 200 MHz Pentium Pro |
| Memory | 512 MB of RAM | |
| Disk | System drive and SQL TempDB: 2 GB—Raid 0 | |
| SQL data device drive: 6 X 9.1 GB—Raid 0 | ||
| SQL transaction log drive: 9.1 GB—Raid 0 | ||
| Network | 100 BaseT (switched) | |
| Software | SQL Server 6.5 SP33 |
2. To test Membership Directory database scalability, the database was partitioned across two Microsoft SQL Servers.
3. Microsoft SQL Server was configured with 75 percent available RAM, 300 user connections, no truncate on checkpoint, and 120 minute checkpoint interval.
The following chart and table illustrate the number of servers required to support between five and 50 million members. These assumptions are made:
4. The LDAP Servers are expected to process two times as many transactions with the MDAC 2.0 Drivers. This will reduce the number of LDAP servers by one half.
Chart 1: Number of LDAP and SQL Servers Required vs. Total Members
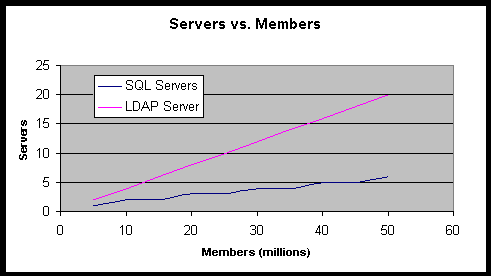
The following is a table representation of the information contained in Chart 1.
Table 1: Number of LDAP and SQL Servers Required vs. Total Members
| Members | LDAP Servers | SQL Servers |
| 5 million | 2 | 1 |
| 10 million | 4 | 2 |
| 15 million | 6 | 2 |
| 20 million | 8 | 3 |
| 25 million | 10 | 3 |
| 30 million | 12 | 4 |
| 35 million | 14 | 4 |
| 40 million | 16 | 5 |
| 45 million | 18 | 5 |
| 50 million | 20 | 6 |
The requirements for LDAP Servers are due to CPU. The requirements for SQL servers are due primarily to the disk subsystem throughput capacity, followed closely by disk space requirements.
This section offers details of the calculation presented in the preceding chart and figure. It includes a configuration of a typical large-scale Personalization & Membership (P&M) implementation which, as indicated above, does not take into account partitioning and limiting database sizes based on operational needs.
Also included is a discussion of the transactions used in P&M and the cost of each of these transactions in terms of CPU and Disk, where applicable. Sample calculations are provided for Chart 1 and Table 1, as well.
The following diagram depicts the way P&M would be rolled out. The key here is a tiered approach, with the Web servers up front, supported by the proper number of LDAP Servers, supported in turn by the correct number of SQL Servers, and database partitions.
Diagram 1: Example of Personalization & Membership (P&M) Configuration
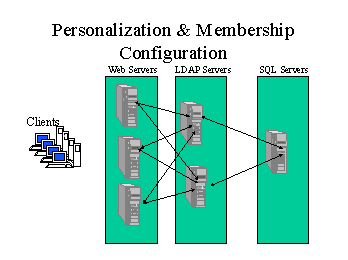
The following example highlights factors that go into the user profile and how they affect membership scaling. The main scaling factor is the number of trips a client makes to the backend SQL Server.
A member signs on to the site and makes a request to a secured or personalized page.
The Authentication Service on the Web server has no knowledge of the user, so it makes a call to the LDAP Server to retrieve user information. The LDAP Server performs a lookup in the database and retrieves the user’s authentication, authorization and personalized profile. This information is passed back to the Authentication Service on the Web server. The Authentication Service caches this information. From now on, when the user requires authentication, authorization, or personalization information, the Authentication Service cache will service the request from cache as long as the user maintains a session with the particular Web server, or until the user’s information in the Membership Directory changes or is updated. Note that some installations may not use caches at all for security (SetInfo clears cache).
The main factor in P&M is the number of trips a user makes to the LDAP and SQL Servers. In theory, a user will connect to one server and only make one trip to the backend servers, and satisfy the rest of the queries from the Authentication Service cache. In reality, however, the user does not stay connected to the same server. Therefore, the number of unique Web servers the user connects to is very important for P&M.
Session duration is assumed to be 30 minutes, with a five-minute sticky period to a particular Web server. Therefore, each user will make six trips to the backend servers, regardless of other user behavior.
If a user makes six trips to the server in 30 minutes, then that user will make .003333 queries per second. These queries are estimated to be 80 percent base level searches, 10 percent one level searches and 10 percent sub tree searches.
It is estimated that 20 percent of these queries write to the Membership Directory. These are personalized pages where a property is modified or added and has to be written back to the Membership Directory. An estimated 80 percent of the requests will modify an existing property, and 20 percent will add a property.
Thus, for purposes of this summary, it is assumed that:
The foregoing data was used to calculate the data presented in Chart 1 and Table 1.
Having defined the user profile, it is next necessary to address the cost of each of the transactions. The following section discusses the cost of each query at the LDAP Server and the SQL Server.
Cost per transaction was calculated by exercising each of the transactions separately and watching their effect on resources. Various loads were used to measure the cost of each transaction. For verification purposes, all transactions were run concurrently, and the calculated and observed resource utilization was graphed for various user loads. Observed and calculated resource utilization were within 15 percent of each other.
Because of the behavior of the LDAP Server, the costs are represented by the following equation: R x (C1+C2xR+C3xR^2).
With C1, C2, and C3 given in the table below under cost, R is the rate of the transaction given under the column Rate Range. The equation holds true for all ranges of rate from one to maximum.
Table 2: Operation Costs
| Operation | Cost in PPEM5 | Rate Range |
| Connect & Bind | 1.7816, 0.0569, -0.0001 | 1 – 100 |
| Base Object Lookup | 2.6782, 0.0048 | 1 – 180 |
| Modify Add an attribute | 1.4841, -0.0002 | 1 – 110 |
| Modify Replace an attribute | 2.9435, -0.0158, 0.0001 | 1 – 110 |
| One Level Lookup | 2.0946, -0.0382, 0.001 | 1 – 180 |
| Subtree Search | 3.76 | 1 – 119 |
| Add a new record | 2 | 1 – 46 |
5. Cost expressed in Pentium Pro Equivalent MHz (PPEM). This is total MHz on a Pentium Pro server. For example a 4 x 200 Processor has 800 PPEMHz. Transaction cost is calculated by taking %CPU times total PPEMHz on the server divided by Trans/sec.
6. Limiting factor was the disk subsystem in the test server. 6 disk RAID 0.for data.
From the above costs, the number of PPEM for Base Object Lookup can be calculated for 10 million users as follows:
10 million users x 2 percent concurrent = 200,000
200,000 concurrent x 0.003333 queries per user per second = 666.6 queries/second
666.6 x 80 percent base object lookup = 533.28
As shown in Table 1, the rate range has a maximum of 180. Dividing 533.28 by 180, you get 2.96. Rounding up, you get 3. Thus you will need to support a transaction rate of 178 on each server. 533/3 = 178.
To solve for CPU cost, use R x (C1+C2xr+C3xr2). From Table 1 you get C1= 2.6782, and C2 = 0.0048, and C3 = 0. Therefore:
178 x (2.6782 + .0048x178) = 628 PPEM
Similarly you can calculate for the rest of the profile to obtain the results in Chart 1 and Table 1.
Using the SQL Server cost table, you can calculate for CPU and disk utilization. SQL Server CPU costs are given in PPEM. The Disk costs are given in number of operations (writes and reads) per second.
SQL Server Costs for Non-Cached Transactions
| Operation | Cost in PPEM | Disk Reads | Disk Writes |
| Connect & Bind | .23 | 0 | 0 |
| Base Object Lookup | .26 | 2 | 0 |
| Modify/Add attribute | 2 | 6 | 4 |
| Modify/Replace attribute | 2 | 6 | 4 |
| One Level Lookup | 1.4 | 4 | 11 |
| Subtree Search | 2 | 4 | 16 |
| Add new record | 15 | 40 | 90 |
Using the 10 million example, you have the following:
10 million users x 2 percent concurrent = 200,000
200,000 concurrent x 0.003333 queries per user per second = 666.6 queries/second
666.6 x 80 percent base object lookup = 533.28
533 x .26 = 138.6 PPEMhz.
This configuration assumes a worst case scenario, that none of the accounts being looked up is cached in the SQL Server cache.
CPU is not the bottleneck for SQL Server, so you will calculate the number of disks required for throughput. Again, take the 10 million-user scenario.
10 million user x 2 percent concurrent = 200,000
200,000 concurrent x 0.003333 queries per user per second = 666.6 queries/second
666.6 x 80 percent base object lookup = 533.28
You require 4 reads for each lookup, so the total number of reads is:
4 x 533.28 = 2133.12
A disk can do about 50 random reads per second, so this will translate into 44 RAID 1 disks. Since a cabinet can only hold 7 disks and only 2 cabinets can be hooked to one controller, this would translate into 8 cabinets with 7 disks each and 4 controllers. One server with a very high-end disk subsystem would support this.
As demonstrated, the number of SQL Servers is dependent on the disk throughput and not on CPU utilization.
Information in this document, including URL and other Internet web site references, is subject to change without notice. The entire risk of the use or the results of the use of this resource kit remains with the user. This resource kit is not supported and is provided as is without warranty of any kind, either express or implied. The example companies, organizations, products, people and events depicted herein are fictitious. No association with any real company, organization, product, person or event is intended or should be inferred. Complying with all applicable copyright laws is the responsibility of the user. Without limiting the rights under copyright, no part of this document may be reproduced, stored in or introduced into a retrieval system, or transmitted in any form or by any means (electronic, mechanical, photocopying, recording, or otherwise), or for any purpose, without the express written permission of Microsoft Corporation.
Microsoft may have patents, patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document. Except as expressly provided in any written license agreement from Microsoft, the furnishing of this document does not give you any license to these patents, trademarks, copyrights, or other intellectual property.
© 1998-2000 Microsoft Corporation. All rights reserved.
Microsoft, Windows and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the U.S.A. and/or other countries/regions.
The names of actual companies and products mentioned herein may be the trademarks of their respective owners.