![]()
Microsoft® Site Server has enterprise Search features that provide information gathering, indexing, search, and retrieval capabilities. This white paper was written to provide the reader with practical information on how to implement Search successfully in a large, global company as well as in a small, local company.
There are some fundamental problems in trying to locate information in a company today:
Microsoft® Site Server, complemented by an effective content tagging strategy, can indeed be a critical part of the solution. This white paper provides you with practical information on how to implement the Search feature in Site Server in a large, global company as well as a small, local company.
Search is a powerful application that lets you build catalogs of documents located on file systems, Web sites, databases, and mail servers. Catalogs can include many types of documents, such as Microsoft Word documents, text files, HTML documents, Microsoft Excel spreadsheets, and so on.
Using Active Search Page (ASP)-based search and retrieval pages, site visitors can search your catalogs for the documents they need. The site visitor enters a query on a Search Page, then a list of matching documents is returned on a Results Page. By clicking a hotlink, the original document is displayed.
You might be familiar with Index Server, Microsoft software, which comes with Microsoft Windows NT® Server operating system. Search in Site Server uses the same search engine as Microsoft Index Server, and uses almost the same ASP scripts. However, Search includes a powerful and flexible crawler that can index documents that are in different formats and reside anywhere in your intranet or even the Internet.
Before using Search, read at least the following sections of the Site Server Search online documentation:
Describes what you can do with Search, and lists the steps to take to set up your Search system and build catalogs.
Provides the key concepts for understanding how Search builds catalogs.
The next section of this paper discusses the large company and small company scenarios and the common approach that should be taken to address both companies’ problems. Subsequent sections provide detailed strategy and methodology on implementing Search using Site Server.
Fabrikam, Inc., is a leading manufacturer of consumer electronics. The company has major headquarters and data processing facilities in Paris, Hong Kong S.A.R., and New York and numerous sales and manufacturing facilities all over the world. More than 13,000 of the company’s 15,000 worldwide employees have access to the corporate intranet. The Web-based intranet is about two years old. In order to drive continual usage of the intranet, the company wants it to be the easiest and best place to find information. The biggest limitation of the company’s current search solution is that it supports only a single server and cannot search across the four intranet servers (with more servers expected to be added). Users have to navigate to each individual server’s search page to conduct a search. Site Server will be used to provide a solution that will search across all Web servers, search across content that is produced in multiple languages (this is not possible with their current solution), and across content that is also stored in file directories, databases, and Microsoft Exchange Server public folders.
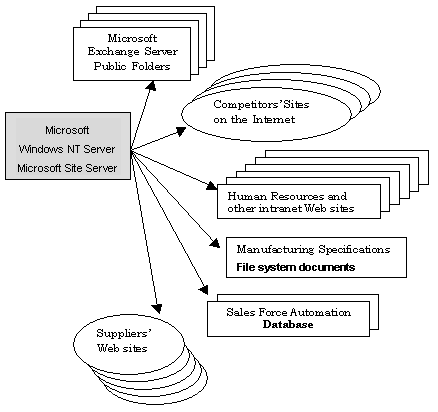
Figure 1. Network Connections (Simplified)
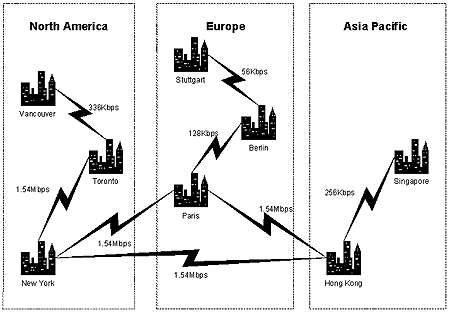
The company has its wide area network (WAN) hubs in Paris, Hong Kong S.A.R., and New York with T1 (1.54Mbps) connections between them. Other locations connect to the WAN hubs at speeds between 1.54Mbps and 56Kbps. The company also has a T1 connection (not shown above) to the Internet.
The IT personnel in the WAN hubs have autonomous authority to administer and manage the network and systems as well as to provide services and support to the end users in the respective region (for example, North America, Europe, and Asia-Pacific).
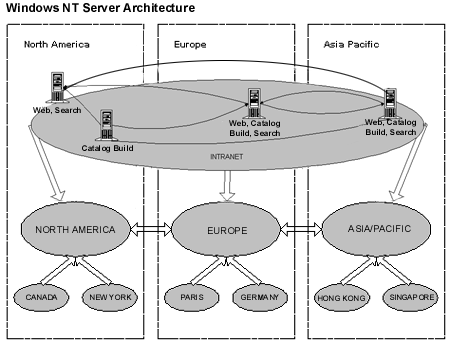
Figure 2. Windows NT Server Architecture (Simplified)
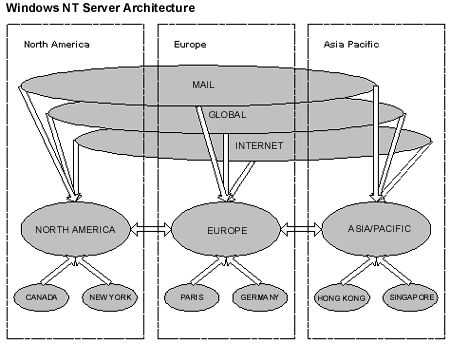
The company’s Windows NT Server architecture has a Multiple Master Domain model. The master domains (EUROPE, ASIAPACIFIC, and NORTHAMERICA) have two-way trust relationships with each other and contain all of the user accounts. The local resource domains (PARIS, HONGKONG, NEWYORK) have a one-way trust relationship with their respective master domain. Global resource domains (GLOBAL, INTRANET, MAIL) have a one-way trust relationship with all master domains. For more information on Windows NT Server domain models, refer to the Domain Planning Guide at http://www.microsoft.com/NTServer/nts/deployment/planguide/DomainPlanGuide.asp.
Of the 13,000 Fabrikam employees who can access the corporate intranet, 7,000 are in North America, 4,000 in Europe, and 2,000 in Asia-Pacific.
Desktop operating system share breakdown: 30 percent use Microsoft Windows® for Workgroups 3.11, 50 percent use Windows 95, 15 percent use Windows NT Workstation 3.51/4.0, 4% use MacOS 7.x, and 1 percent use UNIX (HP-UX and Solaris).
Browser share breakdown: 60 percent use Microsoft Internet Explorer 3.x/4.x and 40 percent use Netscape Navigator 2.02/3.x/4.x.
Only about 3,000 employees are allowed to have direct access to the World Wide Web.
Tailspin Toys is a leading manufacturer of educational toys and books for children in the United States. The company has its headquarters in San Francisco and several sales offices on the West Coast. Most of the company’s 1,500 employees have access to the corporate intranet. The Web-based intranet is about nine months old. In order to remain competitive, the company needs to provide an easy and quick way for its employees to find and share information. Employees store their information primarily in Microsoft Word documents and Microsoft Excel spreadsheets, which are stored on share file servers, and in discussion groups, which reside on an NNTP server and numerous Exchange Server public folders. The company’s biggest problem is that its employees have to search for information in various places, with various tools, and in various ways, making the process extremely ineffective and often counterproductive. Site Server will be used to provide a solution that will search across all file servers, the NNTP server, and the Exchange Server public folders.
Figure 3. Network Connections (Simplified)
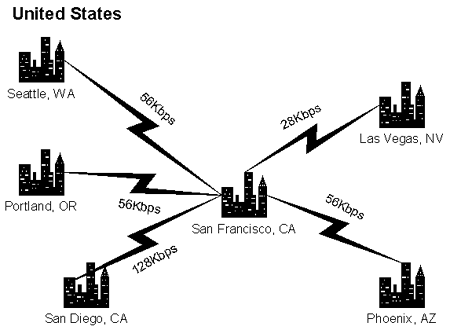
The company has its wide area network (WAN) hub in San Francisco. Other locations connect to the San Francisco hub at speeds between 128Kbps and 28Kbps. The company also has a 56Kbps connection (not shown above) to the Internet.
The IT personnel in San Francisco provide services and support to the end users company-wide.
The company’s Windows NT Server architecture has a Single Domain model in which all Windows NT-based servers are either Backup Domain Controllers or Stand-Alone Servers. There are several large servers in San Francisco and a small one in each of the sales offices.
Of the 1,500 Tailspin Toys employees who can access the corporate intranet, 1,000 are in San Francisco, and the rest are in sales offices on the West Coast.
Desktop operating system share breakdown: 5 percent use Windows for Workgroups 3.11, 80 percent use Windows 95, and 5 percent use Windows NT Workstation 3.51/4.0, and 10% use MacOS 7.x.
Browser share breakdown: 95 percent use Microsoft Internet Explorer 3.x/4.x and 5 percent use Netscape Navigator 2.02/3.x/4.x.
Only about 100 employees are allowed to have direct access to the World Wide Web.
Do not install Microsoft Internet Information Server 2.0.
Install Windows NT Server 4.0 LANGPACK to support additional codepages (see the Microsoft Knowledge Base article Q162408 located at http://support.microsoft.com/support/kb/articles/q162/4/08.asp for details).
In Start\Settings\Control Panel\System\Performance\Virtual Memory:
Set Connection\Proxy Server configuration if necessary.
Use Typical installation mode.
Use Custom installation mode.
Use Custom installation mode to selectively install components in addition to Search.
The Search feature in Site Server consists of the Catalog Build service and the Search service. The services can reside on the same server or on separate servers. The Catalog Build service does the following:
The Search service:
For more information, refer to "How Search Works" in the online documentation.
By allowing Catalog Build servers to propagate catalogs to one or more Search servers, Site Server provides for maximum flexibility in physical server placement.
Due to the potentially large amount of network traffic that the crawler can generate and the need to minimize the length of time it takes to build (or rebuild) a catalog, the optimal location for the Catalog Build server is “near” (from a networking perspective) its information source(s).
HTTP is a relatively “light weight” and “fast/efficient” protocol so the placement of the Search server (to which users will access through a browser) is not a big issue. Usually, the optimal location for the Search server is near the largest concentration of its users.
Although the Catalog Build and Search servers can reside logically and coexist peacefully together on a single physical host, consider separating the Catalog Build server onto separate physical hosts (or upgrading the existing hardware) if the Catalog Build process takes a long time and cannot fit into the “low server activity window” (usually after 20:00 and before 06:00 but not during the nightly backup period).
Although Search allows the use of different specific accounts for administering Catalog Build and Search servers, it may be more convenient to use just one account for all purposes.
The account must meet the following criteria:
For information sources such as file shares, databases, and Exchange Server public folders, the scope of the crawler is well contained within crawl seed of the catalog. However, the Web crawler, if not properly contained, has the potential of crawling every URL that it can access. Therefore, caution must be taken when changing the default Web crawler scope settings of 0 site hops. One method of containing the scope of a crawl is to disable the proxy configuration in Internet Explorer on the Catalog Build server, so the crawler cannot access the Internet. See "Crawling Tips and Techniques" later in this paper for additional information on this subject.
For Web servers that are accessible through hotlinks that originate from a region’s Home Page:
For Web servers that are not accessible through hotlinks that originate from a region's Home Page:
Ensure that the Administrative Access Account specified in the Catalog Build server’s Properties is a member of the local Administrators group and the Site Server Search Administrators group on the Search server to which the catalog will be propagated.
If the Catalog Build server is separated from the Search server by an unreliable or slow network connection, or a firewall or packet filter, the Site Server's content deployment features, with advanced scheduling and fault recovery capabilities, should be used to propagate the catalog. Refer to the Site Server online documentation for more information.
For a large, time-consuming crawl, you may consider configuring the Catalog Build server to propagate the catalog when a specified number of documents is reached. This way, the Search server can utilize the updated catalog before the crawl is completed.
Site Server offers unique security features that prevent users who do not have access to a file from seeing that file in the Results Page of a search. Search mechanisms from other vendors display a Results Page with the listing—and perhaps an abstract—of a file, even if the user does not have access permission. If a user attempts to access the file, they will be prompted for security information but they have already seen the listing, and maybe an abstract, of the file.
Site Server goes a step further by ensuring that unauthorized users will not even see secured documents on search results pages. To accomplish this, Site Server records the Windows NT Access Control Lists (ACLs) permissions for each file that it indexes when performing a crawl. Before showing query results, Site Server filters out all the documents for which a user does not have adequate credentials.
To use the security feature above, the directory that contains the Search Page must not have the Allow Anonymous Access enabled. The Search Page needs to authenticate the user (using either Basic or Windows NT C/R Authentication) in order to display the correct Results Page(s). This works for content gathered through file system and Exchange crawls only, not HTTP or database.
On the Search side, the user must be properly authenticated for the search results to get appropriately filtered based on the user’s identity and security permissions. To do this, anonymous access to the Search ASP page should be disabled so that appropriate user credentials are available. (Alternately, if you did not want security to be respected when searching the catalog, you can either crawl the content through a protocol that does not gather security credentials such as HTTP, or turn on anonymous access to the Search Page and use an appropriately privileged account as the anonymous account.)
Read the Search (under Site Server Knowledge) online documentation on optimizing performance and implement the relevant suggested actions.
Consider using INetLoad to stress test the Search server. You can download a free copy of InetLoad from http://www.microsoft.com/downloads/search.asp?.
For crawling over slow WAN links (for example, 128Kbps or less), set the Catalog Build server’s Timeouts (Wait for a connection, and Wait for request acknowledgement) to at least 60 seconds.
For the large company scenario, the minimum Search configuration consists of three Catalog Build/Search servers—one in Paris, one in Hong Kong S.A.R., and one in New York. However, given the large number of users in North America (spread over four time zones), implementing a dedicated Catalog Build server in New York eliminates any performance impact to the region’s Search server.
Set up the Catalog Build and Search servers as Windows NT stand-alone servers in the INTRANET domain.
Consider using a shared domain account instead of a machine-specific account for the Search service and the Site Server Search Administrator. This will ease account administration, especially when passwords need to be changed. However, if the account cannot be authenticated by a Windows NT Primary or Backup Domain Controller, then the Search service will not start.
Figure 4. Recommended Physical Server Placement. The Catalog Build servers crawl information sources on servers located in their respective regions. Lines with arrows denote catalog propagation activity.
Determine the appropriate time(s) and frequency for a full build (usually weekly) and an incremental build (usually daily).
Set up the Catalog Build servers to propagate their catalog(s) to all Search servers. Consider keeping some catalogs (for example, private/protected Web sites, foreign languages, and so on) localized or regionalized.
Use the sample Search Pages to build a master Search Page for each region on which users will be able to perform a search for all available information in the company’s intranet.
For the small company scenario, the minimum Search configuration consists of one Catalog Build/Search server in San Francisco.
The configuration is very straightforward. Just set up the catalogs to crawl the file servers, the NNTP server, and the Exchange Server public folders. However, due to the slow network connections between San Francisco and the sales offices, set the crawler to a less aggressive mode and increase its timeout value.
Use the sample Search Pages to build a master Search Page on which users will be able to perform a search on all available information in the company’s intranet.
Centralizing the catalogs on a server (though not necessarily a single server for the entire enterprise) allows for an integrated search of all information sources, and the results are collated and sorted together. Search can support up to 32 catalogs per search. The ability to build the catalog on one server (Catalog Build server) and propagate the catalog to another server (Search server) allows for maximum flexibility and scalability.
Whether it’s a search box or a hotlink on your intranet home page, having a Master Search Page that can search all of the catalogs encourages users to “go there first” when they need to search for information. Your Search Page can be completely customized using ASP scripts to provide from the simplest to the most sophisticated search capabilities. Use the Search sample pages provided as part of Site Server to develop your first Search Page quickly and easily.
People search for information in different ways. Solicit and seriously consider their feedback so that your Master Search Page remains not only the first but the best place they can go to search for information.
Let information authors and publishers know that (among other things) the use of descriptive <TITLE> and <ALT> tags can significantly improve searchability. Encourage them to work with you on developing or improving a content tagging strategy by determining the appropriate <META> tags to use, such as categories and keywords, which, when indexed will improve searchability even more. Use Site Server content management features and the tag tool to implement your new strategy. If your company uses the Microsoft FrontPage® 98 Web site creation and management tool, the tag tool can be invoked from within the FrontPage 98 interface, to make tagging even easier.
If your intranet contains a number of ad-hoc sites created by end users, consider separating higher value corporate/maintained information from the rest of the intranet on the Search Page. For instance, add a drop-down box that scopes the search to "corporate information only," "departmental sites," or "entire intranet." This allows users to search for information that comes from, say, HR or Finance separately from one of the established product teams, and separately from End User Joe’s Web Site.
Consider providing an Information Sources Registration Page to which authors can submit URLs of their information sources. The process simply writes the URLs to an HTML file, which acts as a crawl seed for a Search catalog.
The goal is to make your employees more productive and effective. As more and more information sources become cataloged and easier to find, authors will feel more compelled to publish their information on the intranet. And the people who use your intranet will find more relevant information faster.
Many times it’s useful to index content that is dynamically generated by an external program or reporting tool. There are two approaches to this: the first is to simply add the URLs that generate reports to the list of crawl seeds (i.e., http://reportserver/generatereport.asp?argument1=1000), and let the report generator create a report for the gatherer. Depending on the format of the report and the types of queries that people may run to find the report, this may or may not work effectively. If the report doesn’t contain these keywords (or any textual data at all), then this approach won’t work well.
Another approach that can be used in these cases is to create a "stub" file that simply includes a description of the report that will be generated, as well as any metadata, and a URL link to the report generator. The gatherer crawls these "stub" files and indexes the contents; users then get the stub file in response to their queries and can click the link to generate the desired report. (A minor variation is to include the link as a client redirect in the "stub," so that the end user doesn’t even know that the intermediate "stub" file exists).
Anonymous access
Preserving NTFS Security Permissions (especially for private/protected Web sites)
This mapping can be automated using the virtual root mapping tool, Vrootmap.exe. This tool sets the URL mapping in a catalog definition based on the virtual root mappings of your Web server. See the Site Server documentation for more information.
Anonymous access
Preserving Security Permissions (especially for private/protected Web sites)
This mapping can be automated using the virtual root mapping tool, Vrootmap.exe. This tool sets the URL mapping in a catalog definition based on the virtual root mappings of your Web server. See the Search documentation for more information.
The objective is to include content on the Internet with the content on your intranet, so search hits can be ranked and sorted together.
Limit the Internet content to Web pages that contain information your users will find valuable—for example, pages that contain your company name, your trademark, and so on, content important and relevant enough to be included with your intranet content for integrated searching.
Currently, the system works best with Microsoft SQL Server™ and Microsoft Access accessed as ODBC data sources.
Note You may wish to consider hosting (or migrating) NNTP newsgroups as Exchange Server public folders. This provides all the features of an Exchange Public Folder crawl, and has the same requirements (regarding, for instance, security).
To create a catalog of news articles stored on a Microsoft Commercial Internet System news server:
Note You must have a news client (such as Outlook Express) installed in order to follow news links; also, news clients must have permission to read the news server.
For an example of how to create a results page that sdisplays news links correctly, please see the "Multiple Columns" sample page in the Search samples.
Start addresses let the gatherer know where to begin its crawl. You set page hops or site hops on a start address to give the crawl a range of pages/sites to crawl. Without this, your crawl has the potential to go on indefinitely. So how does this relate to site rules and path rules? Setting specific site and path rules allows you to explicitly define the scope of the crawl, which can significantly increase its speed.
You can also set a start address and specify to use the site rules only. This means the gatherer will compare any link it discovers from the start address to the site rules, and if a rule does not exist for that link, it will not crawl it.
The gatherer compares every link to the site and path rules before crawling it. Rules are followed in the order listed. If a site rule contains path rules, the link is compared to any path rules if it matches the site rule.
Site and path rules can make use of wildcards.
Let's say you only want to crawl a portion of a very large Web site, for example, http://www.microsoft.com/com. You would begin by specifying a start address of http://www.microsoft.com/com and set site hops to 0 and page hops to unlimited. However, this is too general. If HRWEB contains a pointer to www.microsoft.com, the gatherer will crawl the root http://www.microsoft.com so unless you set some site and path rules you will still end up crawling www.microsoft.com and all of its additional paths.
Site rules allow you to specify sites that will be (or are likely to be) hit by the start address and set a rule for the gatherer to crawl or avoid that site. Path rules allow you to specify which directories under a given site to crawl or avoid. To only crawl http://www.microsoft.com/com you would need to set a site rule to crawl http://www.microsoft.com/, a path rule to crawl http://www.microsoft.com/com, and a path rule to avoid http://www.microsoft.com/*.
If you wanted to crawl all of MSN™ online service and used a start address of http://www.msn.com with the default page hops and site hops, you would notice in the gatherer logs that a lot of MSN sites were excluded. MSN hosts many different Web sites. While www.msn.com is a valid host, so are encarta.msn.com, investor.msn.com, and a slew of others. In these situations, where you have one domain and various host names, you have several different options for setting up your crawl.
If you want to crawl all of the hosts on a given domain but you do not know all the host names, or you do not want to enter a start address for every single host you can use the site rules list.
A Catalog Definition with these settings starts a crawl at http://msn.com and causes the gatherer to compare every link it comes across to the site rule. If the link fits the rule, it is added to the list of links to crawl; if not, it is excluded.
If you only want to crawl a few of the hosts on a given domain and avoid all others, you have a couple of ways to set that up. You could set up each host as its own start address and set one site rule to avoid all others. Alternatively, you could set up one start address and set site rules for each site that you wish to crawl and one site rule to avoid all others.
Multiple start addresses:
Single start address:
On many sites the host you want to crawl might not always appear in the same segment of the URL. What might be host.domain.com when you start your crawl, could link to www.host.domain.com, host.support.domain.com, and host.software.domain.com. If you want to crawl everything that applies to a specific host you can set up your crawl to use site rules with wildcards:
This tells the gatherer to compare every link to the rule. If the link does not contain the host you are looking for, then it is not crawled. If there are portions of the site you do not wish to crawl, you can add a link to avoid them.
Many of the sample Search ASP pages include script commands that save information to the IIS 4.0 log about the queries that have been executed and the results that have been returned. The Usage Analysis feature of Site Server can generate reports based on the information in the IIS log.
There are two standard Analysis reports available in the Site Server section of the Analysis report catalog that can help to refine your query pages. The Search Top Query report provides information on the most common queries, and the most common problem queries. It contains the following information:
The Search Trends report provides information about how search use varies over time. It contains the following information:
These reports allow you to fine tune the search experience you offer. For example, you can use this information to select new sites to add to your catalog definitions, modify the search options you include in your query page, or create some predefined queries to offer your site visitors the most common search options directly.
Site Server's tag tool inserts Meta tags into HTML documents. When Search catalogs these documents, users can query based on the tags, rather than based on the contents. For example, if an author or editor tags a document with CATEGORY=MEDICINE, a site visitor can search for documents where CATEGORY=MEDICINE and retrieve results relevant to his search. This avoids having to retrieve every document that contains the word 'medicine' in it’s content, and then filtering through to find only the relevant documents. See the section on the Tag Tool in the Site Server online documentation.
Knowledge Manager is an ASP-based application that provides a central location for finding information and receiving updates when information is added or changed. Knowledge Manager uses Search for much of its functionality and extends Search through integration with Site Server's Personalization & Membership and Push features. It also makes use of tags applied to documents with the Tag Tool.
Supports ad hoc searching, and browsing through predefined categories (tags). Searches can be limited to a single category. Useful searches can be saved to be periodically re-executed.
A brief is a collection of useful information, usually on a single subject. Users can create Private Briefs, or an expert on a subject can create a Shared Brief, to which users can subscribe. In addition to containing static text and URLs, sections of Briefs can be populated using saved searches.
Provides a list of the available Push Channels that users can subscribe to.
For enterprises large and small, the Search features of Site Server provide a powerful yet flexible solution for users to easily and quickly find the right information.
Nevertheless, Search is only one piece of the total Knowledge Management solution that a company needs and that Site Server provides. The other pieces are:
For the latest information on Site Server, go to our World Wide Web site at http://www.microsoft.com/siteserver.
The best place to look for any errors that might occur during any phase of the crawl or search is the Windows NT Event Viewer. Search provides a wide variety of events to help users find out what is happening with the crawl or search. Any abnormal event (as well as many normal "informational" events) are logged to the Application event log, and are viewable using the Event Viewer. The event sources that are relevant to Search are: gthrsvc, Gatherer, NlIndex, NlCi, Netlibrary DSO, and SSSEARCH. The kinds of events to watch out for are warnings and errors. The informational events from Search describe the routine events such as starting a crawl, end of a crawl, end of an incremental crawl, propagation, accepting a propagation, successfully enabling a catalog, and starting or stopping services. These events are very helpful for knowing when the error events actually occurred.
Refer to the Site Server online documentation for the latest troubleshooting tips on common problems.
By looking at the Event Viewer, you can find out immediately if the build/crawl started successfully.
If a full build is already started, then you cannot start another build of the same catalog definition. The Event Viewer lets you know that the start crawl (build) command has been ignored. The only situation it allows you to start a build is when an incremental build is in progress, and you start a full build.
Check if the catalog definition is a notification type. If it is, you cannot start a build on a notification catalog definition. You can change the catalog definition type to Crawl and start a build.
Check if there are start addresses configured to start the crawl with.
You may have an invalid start address; verify that you have the right start address and try to start the build again. An error is logged in the Event Viewer.
If your registry is corrupt, then Search is unable to start a build. See your guide to troubleshooting Windows NT for details.
If you have not set or have deleted your e-mail address or User Agent information, then you will not be able to start an HTTP build.
The build will not start if there is some partially formed or ill-formed catalog definition. The administrative interface itself does not allow this to happen; the only way it could happen is if the catalog definition configuration in the registry itself was modified incorrectly. In this case, the admin can delete the invalid catalog definition through the admin and recreate it. In cases where the catalog definition becomes corrupt, the admin detects and delete the offending catalog definition.
By looking into the Gatherer logs, you can find out immediately whether the crawl completed prematurely for some reason.
Search is unable to access any of the start addresses: Verify that when using the account the Gatherer is using to access the pages, you are able to access the start addresses through Internet Explorer browser software, or from Windows Explorer in case of UNC file system start addresses. If you cannot access the start address, Search cannot access it either. If w3svc or IIS or the WebServer service is not running or is having problems on the remote server you are accessing, then you will not be able to access the content there.
Search gets an access denied on all the start addresses: Verify that the Gatherer has adequate privileges on the content you are trying to access. If not, you can set up accounts so that Search can access the content using those accounts.
Check that the start address is not excluded by an extension restriction, Robots.txt restriction, site restriction, path restriction, or protocol restriction or filter not registered or found for the start page extension.
If the start address is a UNC or local path (\\server\share or [drive]:\path), verify that you have the start address type as Follow Sub-directories and not Follow Links; if you have selected to follow links, verify that you do have an appropriate URL mapping.
If the start address is an HTTP address, verify that you have the start address properties configured as Follow Links and not Follow Sub-directories.
Check to see if you have enough disk space on the drive where you installed Search, as well as the drive of your catalog build server temporary files location.
If your start address is a complex URL (contains “?”), the default setting is to not follow URLs with “?” and Search will not start the build, as the start address is excluded. From the catalog definition properties URL tab turn check Follow complex URLs.
If Fltrdmn.exe (one of the binaries shipped in our product) is corrupt, or a protocol becomes unregistered or is not available, then Search cannot do the build. Search gives a bad Fltrdmn.exe error and the build cannot complete. In this case, reinstalling the product to restore Fltrdmn.exe may fix the problem. Uninstall is not necessary here.
If you are crawling through a proxy, verify that both in Search admin and in the Internet control panel applet you have the right settings for the proxy.
If the start address is redirected to a server that you have restricted or you don't have privileges to access, you will not crawl beyond the start address. If it is redirected to a bad URL, Search will not be able to access it. If an HTML robots tag excludes following and indexing the content, you will not go beyond the start address.
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
© 1999-2000 Microsoft Corporation. All rights reserved.
This white paper is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.
Microsoft, FrontPage, MSN, Outlook, Windows, and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries/regions.
Other product and company names mentioned herein may be the trademarks of their respective owners.