
Microsoft Corporation
March 1999
Click here to download the sample associated with this article.
Summary: Provides Btrieve administrators and application developers with techniques for moving to Microsoft® SQL Server™ version 7.0. (75 printed pages) Compares the features of SQL Server 7.0 with those of Pervasive.SQL 7.0.
Introduction
Microsoft SQL Server Version 7.0 vs. Pervasive.SQL Version 7
First Strategy: Wrapping the Btrieve Application
Determining Which Functions to Wrap
Mapping Functions in a DEF File
Implementing the Btrieve Functions
Linking the Wrapper DLL to the Base Application
Addressing the Btrieve posBlock Handle
Establishing the ODBC Connections and Initializing Data Access
Understanding ODBC and SQL Implementation Within the Wrapper
Handling Errors
Second Strategy: Rewriting the Application
Server Cursor Differences
Server Cursor Performance Costs and Limitations
Determining the Rowset Size of a SQL Server Cursor
Emulating ISAM Processing and Locking Techniques with SQL Server
Recommendations for Creating Indexes
Database Index Guidelines
Moving Btrieve Data to Microsoft SQL Server
Conclusion
Finding More Information
Appendices
Many application vendors are finding that their products are at a critical point in the product life cycle. They have released with a solid level of success several versions that use indexed sequential access method (ISAM)–based database management systems (DBMS) like Btrieve.
Due to rapidly expanding customer needs and the powerful capabilities of relational database management system (RDBMS) offerings, these Independent Software Vendors (ISVs) are now converting their applications to RDBMSs. Applications based on an RDBMS can offer better performance and scalability and more replication features than ISAM-based solutions. Well-designed RDBMS solutions vary in size from a few megabytes to multiple terabytes.
Microsoft SQL Server version 7.0 is a powerful and flexible RDBMS solution. The ease of use and scalability of SQL Server 7.0 has made it attractive for thousands of application developers.
This document has been written for Btrieve administrators and application developers who are either considering a move to Microsoft SQL Server 7.0 or who are in the process of migrating applications to SQL Server. This document presents two strategies for converting Btrieve applications (or any ISAM-based application) to work with SQL Server. The first strategy enables you to continue to use your Btrieve application code to access data from a SQL Server database. The second strategy is to rewrite the Btrieve application to take advantage of additional performance enhancements offered by SQL Server and its development environment. Though the first strategy may seem to save development time initially, it is recommended that for optimal performance, you use it as an intermediate step and plan for a complete application rewrite. This paper assumes that the first strategy is used as an intermediate step.
Several underlying assumptions are made within this document.
For clarity and ease of presentation, the reference development and application platforms are assumed to be the Microsoft Visual C++® development system and Microsoft Windows NT® version 4.0 or Windows 2000®, or Microsoft Windows® 95 or Windows 98 operating systems. The Btrieve function and dynamic-link library (DLL) references throughout this document reflect this assumption. However, these techniques can also be applied to other compilers that create Microsoft Windows–based applications.
Several tables from the Microsoft SQL Server pubs sample database are used in both the sample applications and sample code referenced in this document. These tables were chosen because they are readily available to any SQL Server user and because their structure and entity relationships are presented in the SQL Server documentation.
The following sample applications and wrapper DLLs are referenced and included with this kit. Be sure to check the SQL Server Web site at http://www.microsoft.com/sql/ for updates to these resources.
| Resource | Description |
| Btrvapp.exe | Sample Btrieve application that references the Sales.btr and Titlepub.btr Btrieve data files. It is the starting point for the conversion strategy, and it is a simple data-entry and reporting application for a database that maintains information about publishing companies, the titles they manage, and current sales information for each title. |
| Mybtrv32.dll | Sample wrapper DLL that translates the Btrieve calls in Btrvapp.exe to ODBC and Transact-SQL calls. The wrapper provides a bare minimum conversion from a Btrieve ISAM implementation to a SQL Server client/server implementation. Using this wrapper DLL, Btrvapp.exe accesses nonnormalized tables from the SQL Server pubs database instead of the Btrieve data files. |
| Odbcapp.exe | Sample ODBC and SQL Server application that performs the same functionality as the Btrvapp.exe and Mybtrv32.dll combination by using ODBC and Transact-SQL only, and no Btrieve calls or references. |
| Morepubs.sql | Script file that creates the nonnormalized tables in the pubs database referenced by the wrapper DLL, as well as the stored procedures used by Odbcapp.exe for illustrative purposes. |
Microsoft offers many programs and resources for developers. The benefits to developers include training, comarketing opportunities, and early releases of Microsoft products. Benefits vary based on the programs. For more information, see MSDN Online at http://msdn.microsoft.com/developer/.
The database is the component that underlies the most critical business systems. It is one of the most important technologies that companies must consider. Businesses succeed and fail on the information stored within databases. The cost of losing that information as the result of an accident or malicious attack can be devastating to any company. The database should be considered a critical element.
When evaluating a database that will form the basis for your company's future and the core of its mission-critical business systems, you should consider the following:
For the small and medium business environment, a database must be easy to install, use, maintain, and grow.
As small businesses grow to medium and large businesses, their database and applications must be able to scale with them from the laptop to the enterprise environment. A scalable system helps the company preserve its Information Technology (IT) investments. A scalable application can support more users and can store more data without having to add disproportionate hardware resources.
The system must be reliable and allow the small business to easily protect its most valuable asset, data. The database must be able to perform backups and recoveries. The database must be able to recover data in a consistent state.
The database must be able to provide a robust and flexible security environment that is powerful and easy to maintain.
A vast network of trained and certified resources should be available to support the database both locally and globally.
The database must support wide integration with third-party tools such as report generators, bulk data movement and transformation, replication, and multidimensional analysis.
The database must support industry standards such as the Open Database Connectivity Standard, UNICODE, and SQL-92.
The cost of the database as a component of the application must be competitive.
To meet the needs of small- and medium-sized businesses, Microsoft delivers Microsoft SQL Server 7.0 in a database engine that scales from the laptop computer to terabyte-size databases using multiprocessor clusters. The memory and disk space requirements for SQL Server 7.0 are among the lowest in the industry.
SQL Server 7.0 lowers the total cost of ownership through features such as single-console management for multiple servers, event-based job execution and alerting, integrated security with Microsoft Windows 2000, and administrative scripting in multiple languages. SQL Server 7.0 reduces the need for a database administrator in small and medium companies by having the system automatically perform standard administrative tasks.
Pervasive.SQL is a combination of products designed for small, nonmission-critical applications. This product combines into one package Pervasive's Scalable SQL and Btrieve engines. The Btrieve engine provides navigational access, and the Scalable SQL engine provides relational access. Both products use Pervasive's Microkernel Database Engine.
Although Pervasive continues to promote the concept that having a relational and navigational engine in one package is an advantage, the only real value of the Btrieve engine and its navigational interface is in its support for legacy Btrieve applications. The majority of all new applications for the past 15 years have been built using relational, as opposed to navigational, techniques for data access.
For a chart comparing the functionality of SQL Server 7.0 and Pervasive.SQL 7.0, see Appendix A.
The installation process of SQL Server 7.0 is among the most efficient in the industry.
SQL Server 7.0 provides ease of administration that includes more than 40 wizards, many task pads, and numerous tools and utilities to aid the database administrator. For example, the Index Tuning Wizard can analyze how a Transact-SQL statement, or a group of statements, uses the existing indexes on a set of tables. The wizard makes recommendations for index changes that increase efficiency of Transact-SQL statements.
SQL Server Agent is a tool that allows the definition and scheduling of tasks that run on a scheduled or recurring basis. It also supports the alerting of administrators when certain warning conditions occur, and it can be programmed to take corrective action.
SQL Server Query Analyzer is a tool that enables programmers to develop and test Transact-SQL statements interactively. It provides a graphical display of the execution path of a Transact-SQL statement and color-codes syntax elements to increase the readability of the statements. By using SQL Server Query Analyzer, programmers and administrators can easily detect database bottlenecks.
SQL Server 7.0 uses the Microsoft Management Console interface for administration. Because other Microsoft and third-party products for administration use this tool, system administrators can leverage their existing skill set.
SQL Server 7.0 requires less administration than other relational databases; it automatically reconfigures itself. If SQL Server detects an increased number of logged on users, it can dynamically acquire additional resources, such as memory. As users log off, SQL Server frees those resources for the operating system. SQL Server also can increase or decrease the size of a database automatically as data is inserted or deleted. If data is removed from the database, SQL Server 7.0 automatically releases unused disk space to the operating system. SQL Server 7.0 automatically updates statistics on indexes to ensure optimum performance.
SQL Server 7.0 is well integrated with the Windows 2000 operating system. SQL Server fully integrates performance counters into Windows 2000 Performance Monitor, enabling administrators to monitor and graph the performance of SQL Server with the same tool used to monitor Windows 2000-based servers.
Pervasive.SQL claims to be a maintenance-free database, but it actually requires that a knowledgeable user maintain the system. Pervasive.SQL can adjust memory only within the context of a preallocated cache, which is defined at the time of installation. If the system outgrows the preallocated cache, an administrator must make the adjustments. Although Pervasive.SQL automatically expands the amount of disk space required as its files grow, the system provides no way for a user to manage the rate of growth. Pervasive.SQL also provides no way for the inexperienced user to understand or optimize index usage.
| Functionality | SQL Server 7.0 | Pervasive.SQL |
| Dynamic memory allocation | X | |
| Automatically allocate additional memory as resource requirements grow | X | |
| Automatically free memory as resource requirements shrink | X | |
| Automatically allocate additional disk space as tables grow | X | X |
| Automatically free allocated disk space | X | |
| Automatically update statistics | X | |
| Support for schedule operations | X | |
| Alerts and notifications | X | |
| Provides tools for importing data | X | X |
| Provides tools for exporting data | X | |
| Provides data modeling tools1 | X | |
| Supports roll forward/roll back recovery | X | X |
| Integrated online help | X | |
| Wizard-driven interfaces to common tasks | X |
1 Tools that will generate Entity Relationships
As your company grows, SQL Server grows with it. The source code for SQL Server runs on everything from Microsoft Windows 95 and Windows 98 to clustered Windows 2000-based systems; this provides instant compatibility. SQL Server 7.0 for Windows 95 and Windows 98 is perfect for embedded applications (applications that contain a database) because it requires not only a small memory footprint but also provides self-tuning and configuration, high performance, and complete compatibility with other SQL Server versions.
Because SQL Server can scale, it is also the ideal database for mobile applications. Developers can write one set of code and deploy it on different platforms. In addition, mobile clients are fully supported with merge replication and conflict resolution.
The SQL Server 7.0 query processor has been redesigned to support the large databases and complex queries found in decision support, data warehousing, and online analytical processing (OLAP) applications. The query processor includes several new execution strategies that can improve performance of complex queries.
Pervasive.SQL is a combination of products designed for small, nonmission-critical applications. Pervasive.SQL lacks many of the essential tools required for a critical system: integrated backup utility, automatic tuning of memory, support for distributed transactions, ability to scale from the laptop to large enterprises, access to details on query execution, and intraquery parallelism are just a few.
Currently, Pervasive is attempting to provide scalability by creating a set of interfaces that allow products written to Pervasive to run against Oracle. The Pervasive approach requires:
| Functionality | SQL Server 7.0 | Pervasive.SQL |
| Runs on Windows 95 and Windows 98, Windows 2000 Professional, Windows 2000 Server, and Windows 2000 Advanced Server. | X | X |
| Supports multiple INSERT, UPDATE, and DELETE triggers. | X | |
| Supports multiple processors. | X | X1 |
| Supports distributed transactions (through the 2-Phase Commit protocol). | X | |
| Supports heterogeneous queries. | X | |
| Partitioning of queries across processors (parallel queries). | X | |
| Row-level locking. | X | X |
| Dynamic escalation to page or table locking. | X | |
| Stored procedures. | X | X |
| Bulk loading of data. | X | X2 |
| Bi-directional, updateable, and scrollable cursors. | X | X |
| Supports both relational and ISAM (transactional) access methods. | X3 | X |
| Multiple index operations. | X |
1 Takes no advantage of the extra processors.
2 Supports loading of data only from Btrieve files or sequential files.
3 Support through cursors.
Transaction processing systems remain a key component of corporate database infrastructures. Companies are also investing heavily in improving understanding of their data. Microsoft's strategy is to reduce the cost and complexity of data warehousing while making the technology accessible to a wider audience.
Microsoft has established a comprehensive approach to the entire process of data warehousing. The goal is to make it easier to build and design cost-effective data warehousing solutions through a combination of technologies, services, and vendor alliances.
The Microsoft Alliance for Data Warehousing is a coalition that brings together the industry's leaders in data warehousing and applications. The Microsoft Data Warehousing Framework is a set of programming interfaces designed to simplify the integration and management of data warehousing solutions.
New product innovations in SQL Server 7.0 improve the data warehousing process with:
One of the goals when developing Microsoft SQL Server 7.0 was to provide leadership in distributed solutions for a variety of applications that require replication. Replication is built directly into SQL Server 7.0 and SQL Server Enterprise Manager.
The replication model continues to build on the "publish and subscribe" metaphor introduced in SQL Server version 6.0. New replication interfaces are available for custom third-party applications. Three major types of replication are available. The type used for an application depends upon requirements for transactional consistency, site autonomy, and the ability to partition the data to avoid conflicts.
Takes a snapshot of current data in a publication at a Publisher and replaces the entire replica at a Subscriber on a periodic basis.
Distributes transactions to Subscribers as incremental changes are made.
Allows sites to make autonomous changes to replicated data and, at a later time, merge changes made at all sites. Merge replication does not guarantee transactional consistency.
One notable new feature is update replication, in which data replicated by SQL Server 7.0 can be modified at multiple sites. This is a relatively advanced topic, with varying solutions appropriate for different applications. SQL Server 7.0 replication offers many usability improvements and enhancements, making replication significantly easier to set up, administer, deploy, monitor, and troubleshoot.
Wizards are included for the most common replication tasks. SQL Server 7.0 also includes enhancements for Internet replication. Anonymous subscriptions and built-in support for Internet distribution simplify data replication to the Internet. SQL Server 7.0 also includes COM interfaces that open up the store-and-forward replication services, which allow heterogeneous data providers to use the SQL Server 7.0 replication infrastructure to publish their data.
Pervasive.SQL currently has no support for replication, although it has announced that a third-party application will provide this functionality in the near term.
| Functionality | SQL Server 7.0 | Pervasive.SQL |
| Supports transactional replication. | X | |
| Supports merge replication. | X | |
| Supports snapshot replication. | X |
The backup and restore component of Microsoft SQL Server 7.0 provides an important safeguard for protecting critical data stored in SQL Server databases. Backing up and restoring a database allows the complete restoration of data over a wide range of potential system problems:
If one or more of the disk drives holding a database fails, you are faced with a complete loss of data unless you can restore an earlier copy of the data.
If a user or application either unintentionally or maliciously makes many invalid modifications to data, you can restore the data to a point in time before the modifications were made.
If a server is permanently disabled or a site is lost in a natural disaster, you may need to activate a warm standby server or restore a copy of a database to another server.
To protect your data from loss or corruption, SQL Server 7.0 provides wizards to simplify executing and scheduling backup tasks. SQL Server enables you to perform the following types of backups:
Backs up the entire database, including the transaction log.
Backs up recently changed data between full database backups. This data is collected from transaction logs. This functionality enables you to increase the speed of your backup operations and reduce the time required to create backups. Incremental backups record only those data changes made to the database since the last full database backup. An incremental database backup is smaller than a full database backup and takes less time to complete. By performing frequent incremental database backups, you can decrease the amount of data at risk at any given point in time.
Backs up each transaction that has been run since the last transaction log backup. Transaction log backups provide up-to-the-second recovery of lost databases.
Backs up an individual file or set of files.
Pervasive.SQL provides no capability to perform backups or restore databases other than by manually copying the files using either a third-party product or the operating system's file management system.
| Functionality | SQL Server 7.0 | Pervasive.SQL |
| Incremental database backup and restore. | X | |
| Backup/restore can be restarted. | X | |
| Allows online backup and restores. | X | |
| File copy. | X1 | X |
1 Not the recommended technique for data backups
The new SQL Server security model supports Windows 2000 users and groups and introduces SQL Server roles.
By providing better integration with Windows 2000, SQL Server provides increased flexibility. Database permissions can be assigned directly to Windows 2000 users or groups. You can define SQL Server roles to include SQL Server users and roles as well as Windows NT users and groups.
A SQL Server user can be a member of multiple SQL Server roles. This allows database administrators to manage SQL Server permissions by using Windows 2000 groups or SQL Server roles, rather than by assigning them to individual user accounts directly. System-defined server and database roles such as dbcreator, securityadmin, and sysadmin provide flexibility and improved security.
A user passes through two stages of security when working in Microsoft SQL Server: authentication and permissions validation. The authentication stage identifies the user with a login account and verifies only the ability to connect with SQL Server. If authentication is successful, the user connects to SQL Server. The user then must have permissions to access databases on the server. Permissions are assigned by using an account in each database mapped to the user's login. The permissions validation stage controls the activities the user is allowed to perform in the SQL Server database. You can bypass this account mapping by granting permissions directly to Windows 2000 groups or users.
When users connect to Microsoft SQL Server, the activities they can perform are determined by the permissions granted to their security accounts, Microsoft Windows 2000 groups, or role hierarchies to which their security accounts belong. The user must have the appropriate permissions to perform any activity.
Pervasive.SQL provides a limited security implementation. The Btrieve engine provides only the file-system security defined by the specific operating system. Scalable SQL supports the GRANT keyword with the ability to secure the INSERT, DELETE, ALTER, REFERENCES, SELECT, CREATE TABLE and UPDATE commands. The user must be experienced with SQL to administer Scalable SQL's security. However, if both the Btrieve and Scalable SQL engines are used, the Scalable SQL GRANT security does not apply to database access originating from the Btrieve engine. This requires the user to administer both the operating system security and the Scalable SQL security.
| Functionality | SQL Server 7.0 | Pervasive.SQL |
| Provides a wizard-based interface for security administration and setup. | X | |
| Supports integration with operating system. | X | |
| Supports the SQL GRANT keyword. | X | X |
| Supports unified logon. | X |
SQL Server offers native support for many common database APIs, including OLE DB, ODBC, and Embedded SQL for C. This gives programmers control over the interaction between the application and database. SQL Server also supports APIs such as ADO that support Rapid Application Development (RAD) by using the OLE DB API. Through its support of ODBC, SQL Server also supports applications written to the Remote Data Objects (RDO) and Data Access Objects (DAO) APIs. These are object APIs that encapsulate ODBC.
SQL Server also offers OLE Automation objects that can be used to write customized applications to fully administer a SQL Server: SQL-DMO, SQL Namespace, Data Transformation Services (DTS), and replication components. These objects were used by Microsoft to build SQL Server Enterprise Manager, the primary tool used to perform administrative tasks on SQL Server 7.0.
Additionally, SQL Server 7.0 provides SQL-92 entry-level compliance and support for the XA/Open transaction standard.
Although Pervasive.SQL meets entry-level compliance with the SQL-92 standard, development is performed through either proprietary interfaces or ODBC. No support is provided for ADO or OLE DB.
| Functionality | SQL Server 7.0 | Pervasive.SQL |
| ANSI SQL 92 (ENTRY) | X | X |
| XA/OPEN | X | |
| 32-Bit ODBC DRIVER | X | X |
| OLE DB/ADO | X | |
| COM/ACTIVEX Automation | X | |
| TCP/IP | X | X |
Converting an application from one database environment to another takes time, patience, and resources. Because of the differences between platforms, a multiple-step conversion process is recommended. This approach provides multiple analysis points and makes the overall project development process more flexible.
This strategy provides a framework you can use when converting an application from a Btrieve-based implementation to a full ODBC and structured query language (SQL) implementation that accesses Microsoft SQL Server. Converting the application in several steps creates separate checkpoints that allow you to evaluate the status and direction of the conversion process at each stage of the project life cycle. The conversion strategy addresses the following areas:
The following illustration presents the application architecture implemented at each stage of the conversion process. The components of this illustration will be analyzed in detail throughout the next three sections of this document.
Btrvapp.exe is a simple data-entry and reporting application that maintains information about book titles, the publishers that own the titles, and sales information for each title. The Btrieve application accesses two Btrieve files, Sales.btr and Titlepub.btr, through the Btrieve microkernel engine. The Sales file contains sales information for each title, and the Titlepub file maintains the title and publisher information for each title. The Sales file and the Titlepub file each has two keys that correspond to a publisher and a title ID. The Btrieve application uses these keys to position itself within these files when it performs all searches. The Btrieve application uses ISAM row-at-a-time searching techniques and result processing to perform its operations, and Btrieve concurrent transactions to manage the locks in the data file while information is updated, inserted, or deleted. The Btrieve application provides the following functionality:
The goal of this stage in the conversion process is to provide a layer of abstraction between the base application and Microsoft SQL Server. Using the concept of a wrapper DLL, the base application, Btrvapp.exe, can access SQL Server data without modification. Essentially, the wrapper disguises the SQL Server data and responses as Btrieve data and responses. The wrapper uses Btrieve-like result set processing techniques to access two nonnormalized tables, bsales and titlepublisher. These tables are structured to maintain the same details as the Sales and Titlepub files accessed by Btrvapp.exe. Although the ODBC and SQL Server implementation techniques presented in the wrapper DLL are not optimal, they present an initial access methodology that is similar to Btrieve.
Odbcapp.exe is a full ODBC and SQL Server application that accesses SQL Server data directly and more efficiently than the techniques implemented by the wrapper DLL. The ODBC application accesses data in the three normalized tables (titles, publishers, and sales), taking advantage of the relational model provided by SQL Server. Odbcapp.exe also uses several of the performance-enhancing features of SQL Server such as indexes, default result sets, and stored procedures to process result sets.
A wrapper DLL is a dynamic-link library that intercepts external library function calls made to an application. After a function call has been intercepted, the DLL controls the application or process that instantiated the DLL. The DLL can be designed to perform any task or set of tasks, or to do nothing at all. The developer can add to, change, or remove functionality or scope from the DLL without modifying the source code of the calling process or application.
For example, in the case of this conversion strategy, a wrapper DLL can intercept Btrieve calls made to an application and change them to use ODBC to access Microsoft SQL Server. This technique leaves the base application code intact while changing the scope and/or targets of the operation. The initial investment made in the application is preserved even though the application's capabilities have been extended to access SQL Server data.
Alternatively, the wrapper DLL could retrieve data from SQL Server into buffers maintained on the client or another computer. The application then fetches data from the buffers instead of from SQL Server directly by using ISAM-like processing techniques. Although this implementation enables the unmodified base application to access SQL Server, it is complex and can be difficult to implement. It is best suited for those instances when you do not want to use set operations or to develop a full ODBC- and SQL-based application. This methodology will not be discussed here.
Note The wrapper approach allows existing Btrieve applications to operate on SQL Server data without fully porting the Btrieve applications to SQL Server. This should be considered an intermediate approach. For best performance, the Btrieve application should be fully ported to SQL Server and the Btrieve database should be rearchitected to take best advantage of the features in SQL Server 7.0.
Four steps are involved in creating the wrapper DLL:
The wrapper DLL must cover all the functions that the base application imports from the Btrieve library Wbtrv32.dll. Use a binary file dumping utility to list the functions imported from the various external link libraries and referenced by the application. In Microsoft Visual C++, the equivalent of the dumping utility is called Dumpbin.exe.
Use DUMPBIN /IMPORTS application_file_name to obtain the list of imported symbols for Wbtrv32.dll. In the following sample output, the function symbols in Btrvapp.exe imported from Wbtrv32.dll are ordinals 3, 2, and 1:
DUMPBIN /IMPORTS BTRVAPP.EXE
Microsoft (R) COFF Binary File Dumper Version 4.20.6164
Copyright (C) Microsoft Corp 1992-1997. All rights reserved.
Dump of file BTRVAPP.EXE
File Type: EXECUTABLE IMAGE
Section contains the following Imports:
wbtrv32.dll
Ordinal 3
Ordinal 2
Ordinal 1
Use DUMPBIN /EXPORTS DLL_file_name to obtain the list of exported symbols for the DLL in question. The symbols appear in the name column of the table whose headings are "ordinal," "hint," and "name." In the example, these correspond to BTRCALL, BTRCALLID, and WBRQSHELLINIT.
DUMPBIN /EXPORTS WBTRV32.DLL
Microsoft (R) COFF Binary File Dumper Version 4.20.6164
Copyright (C) Microsoft Corp 1992-1997. All rights reserved.
Dump of file wbtrv32.dll
File Type: DLL
Section contains the following Exports for wbtrv32.dll
0 characteristics
31D30571 time date stamp Thu Jun 27 15:04:33 1996
0.00 version
1 ordinal base
10 number of functions
10 number of names
ordinal hint name
1 0 BTRCALL (000014EC)
8 1 BTRCALLBACK (00003799)fs
2 2 BTRCALLID (00001561)
9 3 DBUGetInfo (00008600)
10 4 DBUSetInfo (000089E8)
3 5 WBRQSHELLINIT (00002090)
4 6 WBSHELLINIT (00002A6A)
7 7 WBTRVIDSTOP (00001812)
5 8 WBTRVINIT (00002A4F)
6 9 WBTRVSTOP (000017D2)
The information presented in these output excerpts is used to create the definition file for the wrapper DLL. You need to implement only the exported functions from Wbtrv32.dll that are used by the base application in the wrapper DLL. This eliminates the need to implement exported functions that are never used by the base application.
After you have identified the Btrieve import functions and symbols in the base application as well as the exported symbols for the DLL, map these import functions to export functions in the wrapper DLL by using a definition (DEF) file for the wrapper DLL.
Create a DEF file that contains an EXPORTS section with the names of the functions listed in the name column of the DUMPBIN output.
The exact import/export combination varies depending on what Btrieve functionality is used in the application.
The next step is to develop the basic framework within the wrapper so that all of the Btrieve operations are implemented properly. Most of the Btrieve operations are performed by using the BTRCALL and BTRCALLID functions. Their equivalent functions within the wrapper must be designed to address the operations used by the base applications. Each of these functions has all of the data necessary to perform the operations by using the input parameters it receives.
The following code fragment shows how the B_GET_EQUAL operation is handled by the BTRCALL function within Mybtrv32.dll:
DllExport int __stdcall BTRCALL (BTI_WORD operation, BTI_VOID_PTR
posBlock,
BTI_VOID_PTR dataBuffer, BTI_ULONG_PTR dataLen32,
BTI_VOID_PTR keyBuffer, BTI_BYTE keyLength, BTI_CHAR ckeynum)
{
SQLRETURN rc; // Btrieve operation return code
/*Perform tasks based on operation used in the calling application */
switch(operation){
case B_GET_EQUAL:
// Get the first Title-Publisher record that matches the search
// criteria
if (!strcmp(posBlock, "titlepub.btr")){//Are we accessing title-publisher
info
rc = GetTitlePublisher(henv1, hdbc1, hstmt, B_GET_EQUAL,
ckeynum,keyBuffer);
if (rc != B_NO_ERROR)
return rc;
//Copy title-publisher data to titlepub record structure tpRec
memcpy(dataBuffer, &tpRec, sizeof(tpRec));
}
else { // Accessing sales info
rc=GetSales(henv1, hdbc2, hstmt2, B_GET_EQUAL, keyBuffer);
if (rc != B_NO_ERROR)
return rc;
//Copy sales data to sales record structure salesRec
memcpy(dataBuffer, &salesRec, sizeof(salesRec));
}
break;
The most important parameters are the posBlock, operation, dataBuffer, keyBuffer, and ckeynum parameters. The posBlock parameter is discussed in "Addressing the Btrieve posBlock Handle," later in this document. The operation parameter designates what operation is to be performed. The contents of the dataBuffer, keyBuffer, and ckeynum parameters depend on the operation being performed. You must use these parameters in the same way they would be used if the function was being processed by Btrieve.
The posBlock parameter in the preceding code fragment determines the target SQL Server table. After the target has been determined, a function is called to retrieve the first data record that matches the keyBuffer and ckeynum values from the appropriate SQL Server cursor.
The same methodology is used throughout the wrapper DLL. The following illustration shows the wrapper DLL concept.

The base application, Btrvapp.exe, requests the title and publisher information for TitleID "BU1032." While the wrapper DLL processes this request, the Btrieve application calls the Btrieve function BTRCALL to get the next record from the Titlepub.btr file. The wrapper DLL mimics BTRCALL but accesses SQL Server data instead. It examines the opcode parameter and then performs the appropriate ODBC and Transact-SQL operations to satisfy the request. In this example, the wrapper DLL retrieves the record for TitleID "BU1032" from the titlepub table in the database. The wrapper DLL returns the retrieved data to the base Btrieve application by using the record data buffer passed as part of the original BTRCALL function call.
After the wrapper DLL has been created, the original application must reference the wrapper DLL instead of the Btrieve DLL.
Link the application with the wrapper DLL and ODBC library files (LIB) rather than with the Btrieve library file. You do not have to recompile the base code. The base application will access SQL Server and not the Btrieve microkernel.
The base application, Btrvapp.exe, can now use the wrapper DLL to access SQL Server data. Essentially, the wrapper makes SQL Server look like Btrieve to Btrvapp.exe. The next step is to consider how ODBC and Transact-SQL will access SQL Server data within the scope of the wrapper DLL. The wrapper is designed to use ISAM processing techniques to access SQL Server. Although this implementation successfully accesses SQL Server data without making changes to the base application code, the data is not accessed optimally.
In the Btrieve environment, posBlock is a unique area of memory that is associated with each open file and that contains logical positional information to access records. The Btrieve libraries initialize and use this memory area to perform data functions. The Btrieve application inserts a pointer to the posBlock into every Btrieve call.
The wrapper DLL does not need to maintain any Btrieve-specific data within the posBlock, so it is free to use this memory area for other operations. In the example DLL wrapper, the memory area stores the unique identifier for the SQL Server data affected by the requested operation. Regardless of the contents of the posBlock maintained by the wrapper DLL, each memory block must be unique to each corresponding SQL Server table set.
For example, Btrvapp.exe references two Btrieve files, Sales.btr and Titlepub.btr, where Sales.btr contains sales information for each title and Titlepub.btr maintains the title and publisher for each title. These files correspond to the bsales and titlepublishers tables that were created in the pubs database by the sample script, Morepubs.sql. In Btrvapp.exe, the B_OPEN operation opens the requested Btrieve file and creates its corresponding posBlock.
In the wrapper, the same posBlock now references a particular table by name. The wrapper DLL can be designed to store any form of a unique identifier that represents the SQL Server data that it accesses. Table names are used in the context of this migration strategy for ease of presentation. The keyBuffer parameter contains the file name of the Btrieve file to be opened when B_OPEN is called. The wrapper DLL implementation of the B_OPEN function sets the posBlock equal to this file or table name. The following code fragment, taken from the wrapper DLL B_OPEN implementation (see source file "Mybtrv32.c" for more details), demonstrates this concept:
/*Step1:*/
if (strlen((BTI_CHAR *) keyBuffer) <= MAX_POSBLOCK_LEN)
memcpy((BTI_CHAR *) posBlock, (BTI_CHAR *) keyBuffer, keyLength);
else
memcpy((BTI_CHAR *) posBlock, (BTI_CHAR* ) keyBuffer,
MAX_POSBLOCK_LEN -1);
In the example, the Sales.btr posBlock is set to "Sales.btr" and the Titlepub.btr posBlock is set to "Titlepub.btr." Btrvapp.exe always knows what SQL Server table set is being referenced based on the file name referenced in the posBlock.
The same data record structure formats are used in both the base application and the wrapper DLL. This allows the wrapper DLL to transport record data between SQL Server and Btrvapp.exe in the same format as if the data were coming from Btrieve. The data record structures used in Btrvapp.exe and Mybtrv32.dll are presented in the following example.
/************************************************************
Data Record Structure Type Definitions
************************************************************/
//titlepub record structure
struct{
char TitleID[7]; //string
char Title[81]; //string
char Type[13]; //string
char PubID[5]; //string
float Price; //money
float Advance; //money
int Royalty; //integer
int YTD_Sales; //integer
char PubName[41]; //string
char City[21]; //string
char State[3]; //string
char Country[31]; //string
}tpRec;
//sales record structure
struct
{
char StorID[5]; //string
char TitleID[7]; //string
char OrdNum[21]; //string
int Qty; //integer
char PayTerms[13]; //string
}salesRec;
Within the sample wrapper implementation, the B_OPEN operation establishes a connection to SQL Server for each table set referenced by the base application Btrvapp.exe. The operation also creates and opens the cursors used to reference the SQL Server tables. The cursors are opened on the entire table without a WHERE clause to restrict the number of rows returned. These connections and cursors are used throughout Mybtrv32.dll to reference the SQL Server tables. To avoid the time and processing overhead associated with making or breaking connections to the server, the connections are not terminated until the application is closed.
This connection and cursor implementation were chosen for two reasons. First, they simulate a Btrieve application accessing a Btrieve file: one posBlock for every open file referenced by the application. Second, they demonstrate the inefficient use of connection management when SQL Server is accessed. Only one connection is needed in the context of this wrapper implementation because multiple server cursors can be opened and fetched concurrently on a single connection. Thus, the second connection is only creating overhead within the application. A more efficient connection management methodology uses only a single connection with multiple cursors opened on that connection.
There are many different ways to access SQL Server data with ODBC and SQL. The wrapper Mybtrv32.dll uses server-side cursors. Cursors were chosen for several reasons:
Each Btrieve operation that is performed in the base application is ported to an ODBC and SQL equivalent within the wrapper DLL. Some of the operations, like the B_SET_DIR operation, are not applicable to the SQL Server environment and do nothing within the wrapper DLL. Optimal implementation strategies of ODBC and SQL for both the wrapper DLL and the final application port are discussed in "Rewriting the Application" later in this document.
The wrapper DLL must use Btrieve return codes when exiting each function. Each wrapper function must return B_NO_ERROR or a Btrieve error code corresponding to the type of error that was encountered. By using a valid Btrieve return code, the base application code does not know that its library function is accessing SQL Server instead of Btrieve. You must return the Btrieve return codes that are expected by the base application in order for the wrapper DLL to work properly.
However, there is no direct mapping of SQL Server to Btrieve error codes. You must translate all SQL Server errors encountered in the ODBC code of the wrapper DLL to a Btrieve return code equivalent. The following example taken from the MakeConn function in the wrapper DLL source file Mybtrv32.c demonstrates this concept:
// Allocate a connection handle, set login timeout to 5 seconds, and
// connect to SQL Server
rc = SQLAllocHandle(SQL_HANDLE_DBC, henv, hdbc);
// Set login timeout
if (rc == SQL_SUCCESS || rc == SQL_SUCCESS_WITH_INFO)
rc=SQLSetConnectAttr(*hdbc, SQL_LOGIN_TIMEOUT,(SQLPOINTER)5, 0);
else{
// An error has been encountered: notify the user and return
ErrorDump("SQLAllocHandle HDBC", SQL_NULL_HENV, *hdbc,
SQL_NULL_HSTMT);
return B_UNRECOVERABLE_ERROR;
}
In case an error is encountered, the SQL Server error code must be mapped to an applicable Btrieve error code. For example, the preceding code fragment allocates a connection handle for use in the wrapper DLL. Because Btrieve does not have the concept of connection handles, it does not have a corresponding error code. The solution is to choose a Btrieve return code that closely matches the severity or context of the message. The connection handle error was severe enough to the application to warrant the Btrieve return code B_UNRECOVERABLE_ERROR. You can choose any Btrieve return code provided that the base application is designed to address it.
To produce a high-performance Microsoft SQL Server application, it is important to understand some of the basic differences between the SQL Server relational and the Btrieve ISAM models. The wrapper DLL discussed in the previous section successfully disguises SQL Server as Btrieve. However, this implementation is inefficient in the way that it accesses SQL Server data. In fact, the wrapper DLL implementation is likely to perform significantly worse than the original Btrieve application.
The wrapper DLL accesses two nonnormalized tables instead of taking advantage of the relational model capabilities that SQL Server provides. It also does not process result sets by using any of the powerful application performance-enhancing features like effective Transact-SQL syntax, stored procedures, indexes, and triggers to process result sets.
This section is designed to help developers understand the architectural differences between Btrieve and Microsoft SQL Server 7.0. Developers who must rearchitect their Btrieve applications for best performance on SQL Server 7.0 will benefit from understanding these concepts. The assumption of this section is that developers have chosen to port their Btrieve applications fully. That is, Btrieve calls will be recoded to a database API that supports SQL Server 7.0, such as ADO, ODBC, and OLE DB.
Additionally, this section focuses on optimizing database, index, and query design using ODBC and SQL. Implementation comparisons between the Btrieve and SQL Server processing models will be made frequently to demonstrate the advantages that SQL Server provides.
Relational Database Management Systems (RDBMS) are designed to work best with normalized databases. One of the key differences between an indexed service access method database and a normalized database is that a normalized database has less data redundancy. For example, the file and table record formats used by Btrvapp.exe and Mybtrv32.dll for the Titlepub.btr file and the titlepublisher table have redundant data. Specifically, the publisher information is stored for every title. Therefore, if a publisher manages more than one title, its publisher information will be stored for every title entry it manages. An ISAM-based system such as Btrieve neither provides join functionality nor groups data from multiple files at the server. Therefore, ISAM-based systems such as Btrieve require that developers add the redundant publisher data to the Titles table to avoid manual join processing of two separate files at the client.
With a normalized database, the titlepublisher table is transformed into two tables: a Title table and a Publisher table. The Title table has a column that contains a unique identifier (consisting of numbers or letters) that corresponds to the correct publisher in the Publisher table. With relational databases, multiple tables can be referenced together in a query; this is called a join.
The Data Transformation Services (DTS) feature used in the data migration stage can help you automate the migration and transformation of your data from a source database to a destination database. A data transformation consists of one or more database update statements. Each software application requires specific data transformations. These migration and transformation routines should be designed and saved for reuse by the Independent Software Vendor (ISV) or application developer who understands the business logic of the database. DTS helps to ensure that the data transformations occur in the right order and can be repeated hundreds of times for different ISV customers.
Consider using DTS to automate the migration and normalization of your customers' databases. The ability of DTS to save routines helps you repeat the migration process easily for many customers. DTS can migrate any data that can be accessed through ODBC drivers or OLE DB providers and move the data directly into another ODBC/OLE DB data store.
Legacy systems commonly have a navigational database system. Some vendors refer to this type of system as a transactional database, but it is really record-oriented access rather than set-oriented access.
Traditionally, a navigational database stores its data in separate physical files. Each of these files is a collection of records whose fields are related. To locate a specific record (client #343) in a navigational database, the application must perform these operations:
To pull additional information from a second table (Client Addresses), the application must perform these operations:
The user then navigates between each record that matched the "find" criteria using a "Move Next" or "Move Previous" command. As each of these commands is executed, all of the data that is retrieved as part of the record is sent over the network to the client. This is known as record-oriented access.
In a relational system, queries are passed to the database engine in the form of Structured Query Language (SQL). Whereas most navigational databases use a data access language that is proprietary to the programming language (for example, Btrieve's APIs), SQL is the industry standard database manipulation language. SQL was developed as a way to manipulate relational data, but has expanded in the past few years to the standard way to query databases. Data retrieval in a relational database using SQL is accomplished through the execution of simple commands, all of which share the same core syntax.
The SQL commands for retrieving the client information in the previous example are:
SELECT ClientNumber, ClientName, Address
FROM Client, ClientAddresses
WHERE Client.ClientNumber = 343
and ClientAddresses.ClientNumber = Client.ClientNumber
The application passes this SQL statement to the relational database management system (RDBMS). The RDBMS runs this command and selects only those records that meet the selection criteria. Only the data pertaining to the columns list (ClientNumber, Address, and ClientName) and the specific row (client 343) are returned across the network to the client. This reduces the workload on the application and the network.
The second big difference between traditional navigational and relational databases is the way they manipulate stored records. In navigational systems, the engine is responsible only for reading, writing, and updating the stored information. The application tells the navigational engine where to move within the file and how to change the data. In a relational system, the application makes a request to the RDBMS to change the data. The RDBMS then takes the request and performs the update. The client application has no detailed knowledge of how the records are physically stored. Additionally, this abstraction within the RDBMS allows additional business rules and data integrity definitions to be stored centrally in the database and applied to all data regardless of who wrote the client application.
The advantages of using a relational database rather than a navigational database:
The method for accessing a data store through a navigational interface is almost always proprietary to that database. The basic syntax of SQL does not change when the database structure or database itself changes.
The end user does not need to know the steps for linking tables together or how to navigate those linkages.
Because queries are set-based, network traffic is minimized because the amount of information transferred has been reduced.
Because the query language is standard throughout the industry, finding development and training resources is easy.
Another item to consider in the comparison of relational databases to navigational databases is that the popularity of RDBMSs and SQL means that many resources are available for system development and support.
Choose the implementation methodologies for data retrieval, modification, insertions, and deletions based on how the data is used in the application. Microsoft SQL Server is a powerful and flexible RDBMS. While many of the aspects of processing data in Btrieve can be applied to the SQL Server environment, you should avoid using Btrieve ISAM-like, client-side, result-set processing techniques and take full advantage of the server processing that SQL Server provides. The following discussion compares the result-set processing models of both Btrieve and SQL Server. The goal is to briefly expose the differences in these processing models and to show you how to design this functionality effectively and, in many cases, more efficiently in the SQL Server environment.
Btrieve processes result sets based on the navigational data processing model. The navigational model accesses a single data file at a time; any operation involving multiple files must be performed in the application itself. When the data file is searched, all of the record data is returned to the client regardless of the number of record attributes needed to satisfy the requests. The navigational model is characteristic of positional-based operations. The application and the Btrieve engine maintain a position within the data file, and all operations that are performed against this file are based upon this position. All updates in Btrieve are positional, requiring the application to search for and lock the record to be updated. Because the operations are position-based, the application cannot change or delete database records based on search criteria.
In most cases, you use an index to perform the searches. You must know all of the fields that are indexed within each data file that the application references. (Non-index fields can be filtered using the extended get call). The Btrieve navigational model is capable of simple search arguments using the =, <>, >, <, >=, and <= comparison operators to filter the records retrieved from the data file. These search arguments are normally performed between a single indexed field and a constant. Btrieve offers an extended fetch call that can set up a search filter composed of multiple search arguments that are combined using the logical AND or OR operators, but the logical combinations of criteria in these filters are limited.
The structured query language of SQL Server is called Transact-SQL. Transact-SQL is rich and robust and, if used effectively, can make application development easy and efficient. Transact-SQL can reference both nonnormalized and normalized tables. Transact-SQL also allows you to query specific columns needed to satisfy a request, instead of returning all of the columns. Query capabilities are not limited to indexed fields; you can query any column in any table referenced in the FROM clause. To increase the speed of an operation, the query optimizer chooses among existing indexes to find the fastest access path. More details on indexes can be found later in this document.
Transact-SQL provides advanced searching capabilities in addition to the basic comparison operators also provided by Btrieve. Using Transact-SQL, you can perform complex joins, aggregate functions such as SUM, MAX, and MIN, and data grouping and ordering. One of the strengths of Microsoft SQL Server is its ability to rapidly access and process data at the server. Processing query results at the server reduces the client workload and the number of trips between the client and the server needed to process data.
Transact-SQL uses joins to combine information from multiple tables on the server concurrently. The following example taken from the GetTitlePubRec function Odbcapp.exe demonstrates this; the function calls a stored procedure to return all of the title and publisher information for a particular TitleID.
/********************************************************************
Returns Title and Publisher information for @titleID. The query in
this stored procedure performs a join between the Titles and the
Publishers table based on Publisher ID
********************************************************************/
CREATE PROCEDURE GetTPByTitleId @titleid char(6) AS
SELECT T.TITLE_ID, T.TITLE, T.TYPE, T.PUB_ID, T.PRICE, T.ADVANCE,
T.ROYALTY, T.YTD_SALES, P.PUB_NAME, P.CITY, P.STATE,
P.COUNTRY
FROM TITLES T, PUBLISHERS P
WHERE T.TITLE_ID = @titleid AND T.PUB_ID = P.PUB_ID
After the client issues the call to the stored procedure GetTPByTitleID, the server executes the stored procedure, retrieves all of the requested columns for all of the records that match the criteria in the WHERE clause, and sends the result set back to the client.
To take advantage of these server-side resources and to reduce performance problems and overhead, application developers should use Transact-SQL fully, rather than create Transact-SQL statements underneath an ISAM-like interface. With direct access to the tables using Transact-SQL, you have complete control over the way data is processed throughout the application. You can fine-tune individual data requests to optimize performance and maximize throughput and data concurrency. You may find that optimizing the most frequently used queries improves performance drastically.
In order to provide a better understanding of how the available database application programming interfaces (APIs) work with SQL Server 7.0, a high-level view of their operations will be presented here. Basic operations that the database APIs perform with SQL Server 7.0 will be discussed and compared with Btrieve. This provides a familiar context for Btrieve developers who plan to fully port their Btrieve applications over to database APIs supported by SQL Server 7.0.
The available database APIs for SQL Server 7.0 include ADO, ODBC, and OLE-DB.
The ActiveX Data Object (ADO) API can be used from applications written in any automation-enabled language, such as Microsoft Visual Basic®, Microsoft Visual C++, Microsoft Visual J++™, and Microsoft Visual FoxPro®. ADO encapsulates the OLE DB API in a simplified object model that reduces application development and maintenance costs. The Microsoft OLE DB Provider for SQL Server is the preferred provider to use in ADO applications that access SQL Server. ADO, like OLE DB, can access data from many sources, not just SQL databases. ADO is the API most recommended for general purpose data access from SQL Server because ADO:
The OLE DB database API is a strategic, low-level API for database application development in the COM environment. Use OLE DB with the Microsoft OLE DB Provider for SQL Server to develop your high-performance data access infrastructure in the COM environment.
The ODBC database API is used to access data in relational or indexed sequential access method (ISAM) databases. SQL Server supports ODBC as one of the native APIs for writing C, C++, and Visual Basic applications that communicate with SQL Server. ODBC aligns with the following open industry specification and standard for relational SQL database CLI definitions:
SQL Server 7.0 includes an updated SQL Server ODBC 3.7 driver, which is compliant with the Open Database Connectivity 3.51 specification and the ODBC 3.7 Driver Manager. The SQL Server ODBC driver fully supports SQL Server 7.0 and 6.x servers. It is recommended that you use ODBC for high-performance, low-level development (outside of the COM environment) of SQL Server database applications.
SQL Server 7.0, like earlier versions, includes the following APIs, supported at the version 6.5 level. They are not enhanced for SQL Server 7.0:
ADO, OLE DB, and ODBC differ in their implementation and how they expose functionality to applications, but are quite similar in what they are trying to accomplish with SQL Server when viewed from a high level. The APIs are all designed to read and write data to SQL Server. To operate on SQL Server, each API first requires that some form of connection context be created. This connection context contains information that is important for keeping track of which SQL Server is being communicated with, security information, and other information. ADO presents the concept of a Connection object, whereas ODBC requires the creation of a connection handle and OLE DB requires a Data Source object to be created. These operations are analogous to the OPEN or BTRV (0,…) operation in Btrieve that opens a Btrieve database file for access. At the connection context level, there may be options that can be set to affect items such as the time outs, cursor selection, lock type, or other behaviors of the connection that will affect the performance of the connection. Many of these options can also be set later within the statement context.
After connection context is established, the identifier related to the connection context (whether it be an object or a handle) is used to create a statement context in which to execute SQL statements. Again, the database APIs have different names and levels of functionality for what they establish as statement context, but the overall idea of what is accomplished is the same. ODBC creates a statement handle, whereas ADO creates either Command or Recordset objects and OLE DB creates either Command or Rowset objects.
After the statement context is established, there may be a large number of options available that can be configured within the statement context. Options may include async behavior, network packet size, transaction isolation behavior, cursor selection, lock types, SQL query time-outs, debug information logging, and more. With respect to execution of SQL statements within a statement context, there are a few key decisions to be discussed. This includes potential use of SQL statement preparation, SQL Server stored procedures, and the choice of whether to employ a cursor.
For a survey of common Btrieve GET operations, see Appendix C.
You must decide whether a statement will be executed with either the Prepare/Execute model or directly. If a SQL statement needs to be executed only once, do not prepare the statement prior to execution because the preparation of the SQL statement requires some computing resources. Preparing a statement for re-execution should be considered an investment that pays for itself best if an SQL statement is to be re-executed many times; re-executing a prepared statement is faster than starting again and executing the statement. ADO, OLE DB, and ODBC support statement preparation and execution.
For example, consider the statement "select * from table1 where col1 = 1000" and suppose that this statement will be re-executed many times within a connection context with different search values for col1. This would make the SQL statement a good candidate for statement preparation. ADO, OLE DB, and ODBC provide ways of preparing this SQL statement such that the value '1000' is replaced by a parameter. Use of parameterization in a prepared SQL statement allows substitution and re-execution of the SQL statement with other values placed into the parameter. The SQL statement effectively takes the form "select * from table1 where col1 = <parameter marker>." The database APIs can describe the parameter marker in terms of the data type and other attributes that the parameter represents. In addition, SQL Server recognizes the parameter marker and caches in memory the query plan associated with the SQL statement along with a future query plan associated with different values substituted for the parameter marker. Thus, some of the statements that could be serviced by this prepared statement might include "select * from table1 where co1 = 3000," "select * from table1 where col1 = 1," and "select * from table1 where col1 = 1000000." All of these SQL statements would be re-executed with the same prepared statement with 3000, 1, and 1000000 being substituted for the parameter marker.
In addition to SQL statements prepared explicitly at the database API level, the SQL Server 7.0 relational database engine provides an intelligent procedure cache that retains the most frequently executed SQL statements and stored procedures in memory. Query plans generated during the compilation of SQL statements are saved in the SQL Server procedure cache (in memory) so that subsequent execution of the same SQL statement will not have to recompile a query plan prior to execution. This reduces database server resource consumption.
SQL Server 7.0 can parameterize simpler forms of queries automatically. The sample queries presented earlier would have been recognized as SQL statements that would benefit from prepared and parameterized execution. Upon initial execution of one of the queries, the SQL Server 7.0 relational database engine would cache the query plan as a parameterized query so that subsequent executions of SQL statements with the form "select * from table1 where col1 = <parameter marker>" would use the cached query plan. This autoparameterization takes place without any explicit work from the database APIs.
SQL Server 7.0 follows certain rules to determine whether to autoparameterize. Autoparameterization may occur only on statements in which the WHERE clause involves constant values, column names, the AND operator or the '=' (equal) operator.
Statements that can be autoparameterized by SQL Server 7.0 include:
INSERT <tablename> VALUES ( { <constant> | NULL | DEFAULT },... )
DELETE <tablename> WHERE <key-expression>
UPDATE <tablename> SET <colname> = <constant> WHERE <key-expression>
SELECT {* | <column>, ...,<column>} FROM <tablename> WHERE <key-
expression>
<key-expression> may involve only : column names , constants, AND-
operator, =-operator
Examples of SQL statements that can be autoparameterized:
Select * from tablename where col2 = 'a'
Select * from tablename where col1 = 1 and col2 = 'a'
Examples of SQL statements that can not be autoparameterized:
Select * from tablename where col1 < 1000
Select * from tablename where col1 = 1 or col2 ='a'
The autoparameterization capability of SQL Server 7.0 enhances performance of the database server in environments in which many of the SQL statements submitted are ad hoc in nature. In situations where it is known ahead of time that a set of queries will benefit from prepared and parameterized execution, the prepare/execute model from the database API level should be used explicitly. SQL Server 7.0 autoparameterization is a performance-enhancing bonus, speeding up unpredictable ad hoc queries that could not be prepared and parameterized during application development. Autoparameterization is not a substitute for preparation and parameterization of SQL statements frequently reused during application development.
Btrieve does not provide an equivalent functionality for prepared and parameterized execution of SQL statements. Btrieve database developers who are new to SQL Server are encouraged to study this form of performance optimization because the performance benefit of query plan reuse can be significant. For more information, see SQL Server Books Online and the ADO, OLE DB, and ODBC documentation available from MSDN Library and at www.microsoft.com/data/.
SQL Server enables you to process data within your application by using both set-based operations (called default result sets) and row-at-a-time techniques with server cursors (processed similarly to Btrieve operations). Each of these processing models has its own distinct role in the application development process. In the following section, these processing options are compared and contrasted to help you choose the one that satisfies the data processing requirements within your application.
For a survey of common Btrieve GET operations and their potential translations to SQL Server 7.0, see Appendix C.
If SQL Server cursors are used, results from the SQL statement associated with that cursor can be returned to the client in application defined blocks (often one row at a time). If cursors are not used, SQL Server returns rows that resulted from an SQL query as a default result set.
When an application uses Transact-SQL effectively to request only the rows it needs from the server, the most efficient way to retrieve these rows is a default result set. Default result set is a SQL Server term that refers to the way SQL Server handles communication of query result data from the SQL Server computer back to the client application in the default case (no SQL Server cursor is used). In the default result set scenario, after SQL Server receives an SQL statement request from the client application, it processes the statement, fetches the appropriate data, and packs as much data as possible into each network packet being sent back to the client application. The efficient use of network packets and minimal number of network round trips makes using default result sets the fastest method for returning data to client applications from SQL Server.
SQL Server operations that do not need to maintain a logical position in the table for future navigational movement across the rowset (for example, Get Next or Get Previous type operations) should be processed as default result sets.
An application requests a default result set by leaving the ODBC statement options at their default values prior to executing SQLExecute or SQLExecDirect. For a default result set, the server returns the rows from a Transact-SQL statement as quickly as possible and maintains no position within this set of rows. The client application is responsible for immediately fetching these rows into application memory. Most data processing activity within an application can and should be accomplished using default result sets. Default result sets offer several distinct advantages:
For more information about how results are handled for default result sets and cursors, see SQL Server Books Online.
SQL Server 7.0 provides static, dynamic, keyset server-side cursors. Static cursors retrieve the entire result set at the time the cursor is opened, and stores the copy of data in the tempdb database. Keyset-driven cursors retrieve the keys of each row of the result set at the time the cursor is opened and stores the copy of data in tempdb. Keyset and static cursors that are defined over a large number of rows may consume significant resources from tempdb and require a significant amount of time to open in comparison to other types of cursors. Dynamic cursors (including regular forward-only cursors) do not require resources from tempdb. Dynamic cursors do not require as much time to open over large rowsets as keyset and static cursors do. But as more rows of the dynamic cursor are fetched, the processing cost of the dynamic cursor will add up to a similar level of cost of the keyset and static cursors. This makes SQL Server dynamic cursors a good choice in situations where a cursor needs to be maintained on a large rowset and there will likely not be a need to retrieve most of the rowset (for example, fetches from the cursor will likely pull back only a few of the rows available in the cursor). Fast forward-only cursors, new to SQL Server 7.0, are optimized forward-only cursors designed to open and fetch the first scrollable view of a cursor rowset very quickly. Each of these cursor types vary in how much data they need to fetch in order to open, and their use, if any, of temporary disk storage (in tempdb) of the cursor data.
Cursors can be created that consume resources on either the client or SQL Server. Choosing between client and server cursors requires a decision about how much data a client application will typically need and how often a client application will need that data refreshed. Opening a client cursor is recommended when there is a small set of data that needs to be scrolled through by a client application for read purposes, and the data is not updated. If the cursor needs to span a larger number of rows, it may be better to create a server-side cursor so that there is less network traffic associated with the cursor operations. Opening a client cursor consumes no ongoing resources from SQL Server, only the initial cost of gathering the required data for the client cursor and then passing that data onto the client application. However, creating and maintaining server cursors is resource intensive. Opening a server-side cursor is recommended when there is an absolute requirement by the application to maintain a logical view of data from a SQL Server table accessed in the logical order of a given key.
Most data retrievals and modifications can be performed using SQL Server default result sets. However, in some cases, an application must use row-at-a-time capabilities to satisfy a certain application request. For example, the user may have to examine information one row at a time to make a decision or to use the information from the row to proceed with another task. SQL Server provides this functionality with server cursors.
Btrieve follows a navigational model for access to Btrieve data files. Btrieve operations such as GET FIRST or BTRV (12,…), GET NEXT or BTRV(6,…), GET EQUAL or BTRV(5,…) and GET LAST or BTRV(13,…) are typical of database operations performed. Like the Btrieve navigational model, server cursors maintain a position at the server. Server cursors act like an ISAM interface, except you cannot perform seek or find operations within the cursor result set. Cursors require that you perform this functionality within the client application.
The Btrieve database engine is optimized for positional file access, whereas the SQL Server database engine is optimized for relational data access. While the most direct mapping of Btrieve navigational functionality into SQL Server functionality is using SQL Server cursors, Btrieve developers should consider exactly what their existing Btrieve application is trying to accomplish before they map the Btrieve calls directly to SQL Server cursor operations. It may be beneficial for performance if the functionality required by the existing Btrieve application can be achieved with more efficient SQL Server operations. This leverages the strengths of the SQL Server 7.0 relational database engine, which may not necessarily use cursor operations. Examples of SQL Server cursor usage, using the ADO database API and some alternative coding techniques that do not use cursors, are presented in Appendix D.
Server cursors can be opened on the full table or any subset of a table just like default result sets. However, cursors differ from default result sets in the following distinct ways:
Depending on the type of cursor chosen (static, keyset-driven, forward-only, dynamic, and so on), the application can perform a variety of different fetching operations (FETCH FIRST, NEXT, PREVIOUS, ABSOLUTE, RELATIVE, and so on) within the scope of the cursor result set at the server. With a default result set, an application can fetch only in a forward direction.
When an application uses default result sets, shared locks may remain in effect until the client application processes the entire result set or cancels the operation. This can be a problem if the application waits for user input before it finishes fetching. If the application does not immediately fetch all data requested, the shared locks may be held for a long time, preventing others from updating or deleting. Because server cursors do not hold locks by default, they are unaffected by this application behavior.
Default result sets, because of their set-based nature, do not provide this functionality. If a client application needs to update or delete a row retrieved from a default result set, it must use an SQL UPDATE or DELETE statement with a WHERE clause containing the row's primary key or call a stored procedure that takes the primary key and new values as parameters.
By using ODBC, server cursors allow you to have multiple active statements on a single connection. An application that uses default result sets must fetch result rows entirely before a connection can be used for another statement execution.
Server cursors within SQL Server are powerful, flexible, and useful for ISAM-like, row-at-a-time processing and for positional updates. However, server cursors incur some cost and have some limitations:
Opening a server cursor is more expensive than using default result sets within SQL Server in terms of parse, compile, and execute time and tempdb resources. The additional cost of a server cursor varies by query depending on the number of tables involved (for example, single table or join) and type chosen (static, keyset-driven, forward-only, dynamic, and so on).
Server cursors cannot be opened on Transact-SQL batches or stored procedures that return multiple result sets or involve conditional logic.
Fetching from a server cursor requires one round trip from client to server to open the cursor and retrieve the rowset number of rows specified within the application. In ODBC terms, this means one round trip per call to SQLFetchScroll (or SQLExtendedFetch in ODBC 2.0).
The rowset size that is used to process a server cursor affects the processing throughput of your application. In ODBC, you can communicate the number of rows to fetch at a time by using the ROWSET SIZE statement option. The size you choose for the rowset depends on the operations performed by the application. Screen-based applications commonly follow one of two strategies: Setting the rowset size to the number of rows displayed on the screen or setting the rowset size to a larger number. If the user resizes the screen, the application changes the rowset size accordingly. Setting the rowset size low causes unnecessary fetching overhead. Setting the rowset size to a larger number, such as 100, reduces the number of fetches between the client and the server needed to scroll through the result set. Setting the rowset size high requires a larger buffer on the client, but minimizes the number of round trips needed to return the result set between the client and server. An application that buffers many rows at the client enables the application to scroll within the client-side buffer instead of repeatedly requesting data from the server. In that case, the application only fetches additional rows when the user scrolls outside of the buffered portion of the result set.
After careful consideration, you may determine that using a cursor is the best way to handle a set of operations. It is important to know that there are conditions under which SQL Server may implicitly convert a cursor type requested by a database API to a different one. These conditions can include how a query defined the cursor, any triggers present on the base table, and other conditions. For more information about the conditions under which implicit cursor conversions can occur, see SQL Server Books Online.
You should carefully analyze the scope of each task within the application to decide whether default result sets or server cursors should be used. Default result sets should be used as much as possible. They require fewer resources, and their result sets are easier to process than those of server-side cursors. When a data request will retrieve a small number of rows or only one, and the application does not require positional updates, be sure to use a default result set.
Server cursors should be used sparingly and should be considered only for row-at-a-time processing within the application. If your application requires server cursors despite their performance disadvantages, make sure that the rowset size is set to a reasonably high value.
Now that several different data processing implementation techniques have been compared, the next step is to use these methods to access SQL Server data effectively. The proper implementation of these concepts eliminates application overhead.
Some third-party application development controls and objects provide properties and methods for accessing and retrieving data. These objects and controls expedite the development process by creating a simple interface that allows you to access tables while minimizing or eliminating the need to use Transact-SQL. This abstraction layer can put you at a disadvantage, however, because you will reduce your ability to tune the data-access operations.
By using Transact-SQL statements and stored procedures, you have direct access to the tables involved with your application. This allows you to determine how, and in what order, the data operations are performed. By accessing the tables directly, your application can issue Transact-SQL statements that are tuned for optimal performance.
In addition, stored procedures written in Transact-SQL can be used to encapsulate and standardize your data access.
You may be tempted to use server cursors to implement data seek operations at the client to emulate the ISAM-like processing techniques used in the Btrieve environment. However, using this method to implement data retrieval greatly diminishes the performance advantages of using SQL Server.
SQL Server incorporates an intelligent, cost-based query optimizer that quickly determines the best access plan for executing a Transact-SQL statement. The query optimizer is invoked with every Transact-SQL statement that is sent to the database server. Its goal is to minimize execution time, which generally minimizes physical data access within the database. The query optimizer chooses from among the indexes you create on the tables. For more information about indexes, see "Recommendations for Creating Indexes," later in this document.
Use table joins on the server rather than processing nested iterations of result set data on the client to reduce the amount of processing required at the client and the number of round trips between the client and the server to process a result set.
Data concurrency and lock management are critical implementation issues in database application development. Effective lock management can have a substantial impact on data concurrency, scalability, and the overall performance of a database application system.
The row-level locking functionality of Microsoft SQL Server 7.0 resolves most application developers' database concurrency and locking issues. Nevertheless, a comparison of Btrieve (explicit) locking mechanisms and SQL Server (implicit) row-level locking capabilities ensures a smooth migration of the Btrieve application to SQL Server.
In the Btrieve model, records can be locked by the application automatically. You can lock records automatically inside the scope of a transaction or manually on the statement level. Locks can be placed on a row, page, or the entire file; however, the decision of when and how to lock is left to you.
Because you are responsible for lock management, you must choose an optimistic or pessimistic locking concurrency approach in multiuser scenarios. Hard coding your locking scheme reduces the flexibility and scalability of the application. One locking scheme may not be optimal in all user environments due to varying database sizes and user-concurrency conditions. You must carefully examine each transaction and data modification made within the application to determine what locks are needed to satisfy its requirements.
Regardless of the locking scheme you choose in Btrieve, record reading, record writing, and the locks corresponding to each action are not implemented as an atomic unit. You must first read a record with a lock before it can be updated or deleted. This requires at least two round trips between the client and the server for each data modification or deletion. For example, the following code retrieves a single record from Titlepub.btr by its TitleID with a single-row, wait-record lock (Btrieve lock bias 100) and then updates the record:
/* GET TITLE/PUBLISHERS RECORD WITH op and lock bias 100*/
memset( &tpRec, 0, sizeof(tpRec) );
dataLen = sizeof(tpRec);
tpStat = BTRV( op+100, tpPB, &tpRec, &dataLen, keyBuf, keyNum );
if (tpStat != B_NO_ERROR)
return tpStat;
.
.
.
// Update with -1 key value because key for the record is not to be
// changed
tpStat = BTRV(B_UPDATE, tpPB, &tpRec, &dataLen, TitleID, -1 );
if (tpStat != B_NO_ERROR){
printf( "\nBtrieve TitlePublishers UPDATE status = %d\n", tpStat );
return B_UNRECOVERABLE_ERROR;
}
Because multiple round trips are required to process these types of requests, their associated locks are maintained longer. This may reduce the concurrency and scalability of the application. SQL Server performs the locks and data modification or deletion in one step, reducing both the round trips and the lock maintenance overhead. SQL Server can also automatically perform optimistic concurrency locking by using cursors.
SQL Server 7.0 supports row-level locking, which virtually eliminates the locking problems that added complexity to ISAM and RDBMS programming in the past. This drastically reduces the development time and complexity of the client application.
SQL Server escalates lock granularity automatically based on the constraints of the query or data modification that is issued. SQL Server does not require you to perform a separate read and lock before the application can update or delete a record. SQL Server reads and performs the required lock in a single operation when an application issues an UPDATE or DELETE statement. The qualifications in the WHERE clause tell SQL Server exactly what data will be affected and ultimately locked. For example, the following stored procedure and ODBC code perform the same update of a record based on its TitleID as the preceding Btrieve example:
/****** Object: Stored Procedure dbo.UpdtTitlesByPubID ******/
CREATE PROCEDURE UpdtTitlesByPubID @PubID char(4) AS
UPDATE TITLES SET YTD_SALES = YTD_SALES +
(SELECT SUM(QTY) FROM SALES WHERE TITLES.TITLE_ID =
SALES.TITLE_ID)
WHERE PUB_ID = @PubID
GO
// Bind the PubID input parameter for the stored procedure
rc = SQLBindParameter(hstmtU, 1, SQL_PARAM_INPUT, SQL_C_CHAR, SQL_CHAR,
4, 0,
choice, 5, &cbInval);
if (rc!=SQL_SUCCESS && rc!=SQL_SUCCESS_WITH_INFO) {
ErrorDump("SQLBIND SELECT TITLEPUB 1", SQL_NULL_HENV,
SQL_NULL_HDBC, hstmtU);
SQLFreeStmt(hstmtU, SQL_RESET_PARAMS);
SQLFreeStmt(hstmtU, SQL_CLOSE);
return FALSE;
}
// Execute the UPDATE
rc=SQLExecDirect(hstmtU, "{call UpdtTitlesByPubID(?)}", SQL_NTS);
if ((rc != SQL_SUCCESS && rc != SQL_SUCCESS_WITH_INFO)){
ErrorDump("SQLEXECUTE UPDATE TITLEPUB", SQL_NULL_HENV,
SQL_NULL_HDBC, hstmtU);
return FALSE;
}
The numbers of operations needed to perform a task are reduced because SQL Server handles the row-level locking.
If you are accustomed to the nonrelational ISAM model, you may want to use ISAM data locking and concurrency management techniques within your SQL Server application code. These techniques, however, eliminate the performance-enhancing advantages that SQL Server provides. The following list presents two fundamental locking and concurrency implementation challenges that result from using ISAM processing and locking techniques, and a brief description of how each issue can be avoided.
SQL Server provides a mechanism for eliminating this overhead. The SQL Server system variable @@ROWCOUNT indicates the number of rows that were affected by the last operation. Use this variable when you issue an UPDATE or DELETE statement within the application to verify how many records were affected. If no records exist that match the qualifications you specify in the WHERE clause, @@ROWCOUNT will be set to zero, and no records will be affected. The following example demonstrates the use of @@ROWCOUNT for this purpose:
UPDATE PUBLISHERS SET PUB_NAME = 'Microsoft Press', City = 'Redmond',
State= 'WA', Country = 'USA' WHERE = TITLE_ID = 'BU1032'
/* Verify that record was updated */
IF @@ROWCOUNT <1
/* Record does not exist so create it with correct values */
INSERT PUBLISHERS VALUES ('BU1032', 'Microsoft Press',
'Redmond', 'WA', 'USA') WHERE TITLE_ID = 'BU1032'
In the preceding example, the UPDATE is performed, and @@ROWCOUNT is set to the number of records it affected. If no records were modified, then a new record is inserted.
Database and query design have a dramatic impact on the performance of your SQL Server application. Successful planning and design at this stage can positively influence your application's performance.
The first step in effective query design is to limit the amount of data transferred between the client and the server by limiting the columns specified in a Transact-SQL statement to the values required by the application (for example, through the efficient use of the SELECT and FROM clauses), and by limiting the number of rows fetched from the database (for example, through the efficient use of the WHERE clause).
After reviewing the Transact-SQL statements to ensure that they request only the required rows and columns, a database developer must consider the use of indexes, stored procedures, and efficient coding to improve application performance.
In the Btrieve environment, most operations retrieve every column or attribute for each record involved in an operation. With SQL Server, this technique can be inefficient, especially in cases where only a small number of columns are actually required. For example, the GetSales function in Btrvapp.exe retrieves all of the sales record attributes from Sales.btr even though only the TitleID and Qty attributes are needed to complete the task. The following is the code fragment from the GetSales function in Mybtrv32.c that exhibits this behavior:
/* Get TITLE/PUBLISHER with OPERATION*/
// Copy the desired TitleID to the keyBuffer for use by Btrieve and
// initialize parameters
strcpy(TitleID, keyBuf);
memset( &salesRec, 0, sizeof(salesRec) );
dataLen = sizeof(salesRec);'
// Retrieve the sales record
salesStat = BTRV( op, salesPB, &salesRec, &dataLen, keyBuf, 1 );
if (salesStat != B_NO_ERROR)
return salesStat;
The same design inefficiency can be implemented in the SQL Server environment by selecting all of the columns from tables, views, or cursors involved in an operation. For example, the following code fragment from the GetSales function retrieves all of the sales record attributes from the BSALESCURSOR even though only TitleID and Qty are needed to complete the task.
// Bind result set columns to buffers
SQLBindCol(hstmt, 1, SQL_C_CHAR, salesRec.StorID, 5, &cbStorID);
SQLBindCol(hstmt, 2, SQL_C_CHAR, salesRec.TitleID, 7, &cbTitleID);
SQLBindCol(hstmt, 3, SQL_C_CHAR, salesRec.OrdNum, 21, &cbOrdNum);
SQLBindCol(hstmt, 4, SQL_C_SLONG, &salesRec.Qty, 0, &QtyInd);
SQLBindCol(hstmt, 5, SQL_C_CHAR, salesRec.PayTerms, 13, &cbPayTerms);
// Fetch records one-at-a-time from the server until the desired
// record is found
while(!found)
{
memset(&salesRec, 0, sizeof(salesRec)); // Initialize the record buffer
// Fetch the record from the server cursor
rc = SQLFetchScroll(hstmt, FetchOrientation, FetchOffset);
if ((rc != SQL_SUCCESS && rc != SQL_SUCCESS_WITH_INFO))
.
.
.
You can avoid design inefficiency by accessing only the record attributes required to satisfy a particular task. Odbcapp.exe demonstrates a more efficient design concept in its GetSales function. The GetSales function in Odbcapp.exe calls the GetSales stored procedure from the SQL Server pubs database to retrieve only the TitleID and Qty columns for the desired title. The following code fragment presents the GetSales stored procedure. It demonstrates how the stored procedure is executed and its results processed in the Odbcapp.exe GetSales function.
/*Get Sales stored procedure */
CREATE PROCEDURE GetSales @titleid char(6) AS
SELECT TITLE_ID, QTY FROM SALES WHERE TITLE_ID = @titleid
GO
// Execute the stored procedure and bind client buffers for each
// column of the result
rc = SQLExecDirect(hstmtS, "{callGetSales(?)}", SQL_NTS);
.
.
.
SQLBindCol(hstmtS,1, SQL_C_CHAR, TitleID, 7, &cbTitleID);
SQLBindCol(hstmtS, 2, SQL_C_SLONG, & Qty, 0, &QtyInd);
// Fetch result set from the server until SQL_NO_DATA_FOUND
while( rc == SQL_SUCCESS || rc == SQL_SUCCESS_WITH_INFO)
{
rc = SQLFetch(hstmtS);
.
.
.
Use WHERE clauses to restrict the quantity of rows returned. Using WHERE clauses reduces the total amount of data affected by the operation, reduces unnecessary processing, and minimizes the number of locks needed to process the request. By using the WHERE clause to reduce the result set, you can avoid table contention, reduce the amount of data transferred between the client and the server, and increase the processing speed of the request.
For example, the following cursor code was taken from the CreateCursor function of Mybtrv32.c:
// Creates the BSALESCURSOR
if (!strcmp(curname, "BSALESCURSOR"))
rc=SQLExecDirect(*hstmt2,
"SELECT STOR_ID, TITLE_ID, ORDNUM, QTY, PAYTERMS FROM
BSALES", SQL_NTS);
The BSALESCURSOR is created without using a WHERE clause. As a result, the server creates a cursor that retrieves all rows in the bsales table. This cursor results in more resources and processing at the client than it needs.
The application actually requires that the query obtain the sales information for a particular TitleID column. It would be more efficient to use a WHERE clause that defines the exact TitleID or even a range of TitleIDs. This would reduce the amount of data sent for client-side examination and the number of round trips between the client and the server. This example is illustrated below. Notice that the cursor is more efficient because it only requests the TitleID and Qty columns from the bsales table; in this application, only those columns are used by the business logic.
if (!strcmp(curname, "BSALESCURSOR")){
SQLBindParameter(hstmtU, 1, SQL_PARAM_INPUT, SQL_C_CHAR,
SQL_CHAR, 6, 0, inval, 7, &cbInval);
rc=SQLExecDirect(*hstmt2,
"SELECT TITLE_ID, QTY FROM BSALES WHERE TITLE_ID LIKE ?",
SQL_NTS);
A singleton SELECT returns one row based on the criteria defined in the WHERE clause of the statement. Singleton SELECTs are often performed in applications and are worthy of special attention. Because only one row is returned, you should always use a default result set SELECT statement rather than a server-side cursor to retrieve the record. The default result set SELECT statement retrieves the record faster and requires far fewer resources on both the client and the server. The following code fragment is an example of a singleton SELECT that returns the Pub_ID and Title for a single Title_ID:
SELECT PUB_ID, TITLE FROM TITLES WHERE TITLE_ID = 'PC8888'
Because singleton SELECTs are performed frequently in applications, consider creating stored procedures to perform these SELECT statements. By using a stored procedure rather than issuing a SELECT statement directly, you can reduce the parse, compile, and execute time necessary to process the request. The following code, taken from the GetTitlePubRec function in Odbcapp.exe, executes a singleton SELECT through the GetTPByTitleId stored procedure. Notice the small amount of processing needed in Odbcapp.exe to execute this stored procedure.
switch(key)
{
case 1: // Title_ID search
strcpy(StoredProc, "{call GetTPByTitleID(?)}");
// Identify stored procedure to call
// Bind the input parameter buffer
SQLBindParameter(hstmtU, 1, SQL_PARAM_INPUT,
SQL_C_CHAR,
SQL_CHAR, 6, 0, inval, 7, &cbInval);
break;
.
.
.
// Execute the stored procedure and bind result set row columns to variables
memset( &tpRec, 0, sizeof(tpRec) ); // Initialize buffer record
// structure
rc=SQLExecDirect(hstmtU, StoredProc, SQL_NTS );
.
.
.
SQLBindCol(hstmtU, 1, SQL_C_CHAR, tpRec.TitleID, 7,
&cbTitleID);
SQLBindCol(hstmtU, 2, SQL_C_CHAR, tpRec.Title, 81, &cbTitle);
.
.
.
SQLBindCol(hstmtU, 12, SQL_C_CHAR, tpRec.Country, 31,
&cbCountry);
// Process the results until SQL_NO_DATA_FOUND
while (rc==SQL_SUCCESS || rc==SQL_SUCCESS_WITH_INFO)
{
rc=SQLFetch(hstmtU);
if (rc==SQL_SUCCESS || rc==SQL_SUCCESS_WITH_INFO) {
.
.
Good query performance requires the proper use of indexes when operating over large datasets. This is true for both Btrieve and SQL Server. With Btrieve, indexes must be explicitly mentioned during an operation; the number of the Btrieve index file needs to be provided in most Btrieve calls. With SQL Server, the query optimizer makes intelligent and flexible decisions about the best index or indexes to use for a query. If the SQL Server query optimizer does not use a particular index, it most likely means that the index is not as helpful as other indexes present on the table.
SQL Server clustered indexes enforce the physical ordering of a table because the leaf level of clustered index B-trees hold the data pages of the table. Due to this physical ordering, it is advantageous to define clustered indexes on tables such that database operations that access that table using large-range scans will be querying based on the clustered index. In situations where there are multiple columns on a table being migrated from Btrieve that will be heavily used in range-scan queries, it may make sense to break up that table into smaller tables that each contain one of the columns that need a clustered index. Joins can then be used to bring the data from various tables back together efficiently.
SQL Server nonclustered indexes enforce the physical ordering on only the columns that are contained in the nonclustered index because the leaf level of the nonclustered index B-tree structure holds the columns in the nonclustered index. In order to retrieve the remaining row data from the associated table, a nonclustered index entry needs to follow a pointer that leads to a data page containing the associated data row. This requirement for an additional page read is the reason why clustered indexes are slightly faster than nonclustered indexes for single row fetches. Nonclustered indexes are not as good a choice as clustered indexes for large-range scans because of the additional pointer de-references that nonclustered indexes need to perform in order to retrieve data that is not contained in the index. Nonclustered indexes define only the physical order for the columns contained in the nonclustered index. Clustered indexes define physical ordering for the whole row, which provides for optimal (sequential) disk access. Nonclustered indexes are a good choice for queries that need to retrieve or operate one or a small number of rows in a table.
For more information about designing SQL Server indexes, see SQL Server Books Online and the "SQL Server 7.0 Performance Tuning Guide".
Users of Microsoft SQL Server 7.0 can benefit from the new graphical SQL Server Query Analyzer and Index Tuning Wizard. These tools remove the guesswork from index creation.
Nevertheless, understanding some basic index design recommendations can be useful to developers new to RDBMS.
A proper implementation of a normalized table in an RDBMS usually results in several indexes. The query optimizer can use any of the index types described below to increase query performance:
The system creates a unique index on a column or columns referenced as a primary key in a CREATE TABLE or ALTER TABLE statement. The index ensures that no duplicate values are entered in the column or columns that make up the primary key. SQL Server does not require you to declare a primary key for every table, but it is considered good programming practice for RDBMS developers.
You can optionally create unique or nonunique indexes on tables. These indexes can improve the performance of queries against the table.
Unique indexes improve performance and ensure that the values in the specified columns are unique.
Clustered indexes physically order the table data on the indexed column or columns. Because the table can be physically ordered in only one way, only one clustered index can be created per table. If you have only one index on a table, it should be a clustered index. PRIMARY KEY constraints create clustered indexes automatically if no clustered index already exists on the table and a nonclustered index is not specified when you create the PRIMARY KEY constraint.
The following are a few database index guidelines:
The column(s) listed in the WHERE clause of a Transact-SQL statement is a possible candidate for an index. For each table, consider creating optional indexes based on the frequency with which the columns are used in WHERE clauses, and take into account the results of the graphical SQL Server Query Analyzer.
Single-column indexes are often more effective than multicolumn indexes. First, they require less space, allowing more index values to fit on one data page. Second, the query optimizer can effectively analyze thousands of index-join possibilities. Maintaining a large number of single (or very few)-column indexes provides the query optimizer with more options from which to choose.
The SQL Server Query Analyzer helps you determine which clustered indexes to create. Appropriate use of clustered indexes can significantly improve performance.
For more information on indexing and performance, see SQL Server Books Online and Knowledge Base (support.microsoft.com/support).
Stored procedures enhance the power, efficiency, and flexibility of Transact-SQL and can dramatically improve the performance of Transact-SQL statements and batches. They also provide application development flexibility. Stored procedures differ from individual Transact-SQL statements because they are precompiled. The first time a stored procedure is run, the SQL Server query engine creates an execution plan and stores the procedure in memory for future use. Subsequent calls to the stored procedure run almost instantaneously since most of the preprocessing work has already been completed. The Odbcapp.exe application demonstrates how stored procedures are called using ODBC within an application.
If there are groups of SQL statements that must be executed repeatedly, it is recommended that you contain these SQL statements in a stored procedure. The execution plan associated with the stored procedure is created and reused each time the stored procedure is executed. This reduces server resource consumption and enhances performance. Performance is also enhanced because network traffic is reduced. Only a single statement executing the stored procedure must be sent from the client to SQL Server rather than all of the individual SQL statements contained in the stored procedure. Security settings can be assigned to SQL Server stored procedures so that access to the business logic indicated by the SQL statements contained in the stored procedures can be limited to the appropriate parties.
Stored procedures also provide a method for dividing the functionality of a database application into logical components that help to ease application development. These logical components allow application developers to leverage the functionality of the SQL statements contained in the stored procedures without needing to know how to program in the SQL language; database APIs can merely call the stored procedure. Programmers familiar with SQL programming will also benefit from the use of these logical components because they can call the stored procedure versus having to recode business logic repeatedly with individual SQL statements. This helps to reduce programming errors because the encapsulation of SQL statements in the stored procedures means that there is less code to test. Stored procedure code is thoroughly tested; it can be reused in application programming with fewer programming errors than what would result from programming with individual SQL statements.
Btrieve does not provide statement caching and reuse functionality similar to SQL Server stored procedures. Btrieve developers porting their applications to SQL Server 7.0 are encouraged to study the use of SQL Server stored procedures because of the performance enhancements and application design flexibility they bring. For more information about stored procedures, see SQL Server Books Online.
Short and efficient transactions decrease the number of row-level locks managed by the system at any given point in time and are considered to be good programming practice. This is especially true in mixed-decision support and online transaction processing (OLTP) environments.
SQL Server Query Analyzer provides valuable I/O statistics from each query executed in the query window. This is commonly referred to in the SQL Server documentation as STATISTICS IO. Use the query I/O statistics on all of the example queries described in this document to help you see the I/O cost of each SQL statement. Use I/O statistics to evaluate how well an SQL query is running, and use I/O statistics as a guide when performance tuning slow- running SQL queries. To enable this functionality, you can either execute a Transact-SQL command or set SQL Server Query Analyzer menu options.
To use the SET STATISTICS IO option using Transact-SQL commands (Query Analyzer):
set statistics io on
To use the SET STATISTICS IO option using menu options (Query Analyzer):
Note The I/O statistics are run-specific. While on one run of a query, all reads may come out of buffer cache and be counted as logical reads. On other runs, it is possible that the exact same query needs to use read-ahead reads and/or physical reads to satisfy the I/O requirements of the query. This fluctuation in I/O statistics may be due to many factors, the most common of which is the fact that other connections may be performing queries and bringing data into the buffer cache, which displace data pages being used by the monitored query. When analyzing queries, it is helpful to run the query several times with I/O statistics turned on, and then compare the results.
Use the WHERE clause to implement UPDATE and DELETE as set-based operations, restricting the data involved with the operation to that which matches a specific criteria. By implementing these operations using this methodology, you only update or delete the rows you intend to UPDATE or DELETE, reduce the total amount of data affected by processing the operations, and reduce the number of row-level locks needed to process them.
These operations should be performed only by using server cursors if the criteria for determining the rows for the UPDATE or DELETE operations cannot be specified in the Transact-SQL statement itself.
The following two examples demonstrate the difference between a set-based update and a positional update using a cursor. Both of these examples update the YTD_Sales for each title covered by a specific PubID. The first example is a stored procedure used by Odbcapp.exe. It demonstrates the use of a default result set update that uses a WHERE clause.
/****** Object: Stored Procedure dbo.UpdtTitlesByPubID ******/
CREATE PROCEDURE UpdtTitlesByPubID @PubID char(4) AS
UPDATE TITLES SET YTD_SALES = YTD_SALES + (SELECT SUM(QTY) FROM
SALES WHERE TITLES.TITLE_ID = SALES.TITLE_ID)
WHERE PUB_ID = @PubID
GO
The preceding example is efficient and uses the server to perform the processing and row selection for the UPDATE.
The following example taken from Mybtrv32.exe demonstrates the inefficient use of a positional update through a cursor. This example must fetch through the cursor, updating each record that has the desired PubID. Notice the amount of fetching (round trips between the client and the server) needed to process this request.
// The following code is taken from the GetTitlePublisher function in
// Mybtrv32.c
// Scroll through the cursor a row-at-a-time until the row needing
// updated is found.
while (!found)
{
memset( &tpRec, 0, sizeof(tpRec) ); // Initialize
// the client row buffer
// Fetch the record
rc=SQLFetchScroll(hstmt8, FetchOrientation, FetchOffset);
if ((rc != SQL_SUCCESS && rc != SQL_SUCCESS_WITH_INFO))
{
if (rc!=SQL_NO_DATA_FOUND){
// Error encountered before end of cursor notify the user and return
ErrorDump("SQLFetchScroll TitlePub", SQL_NULL_HENV,
SQL_NULL_HDBC, hstmt8);
return B_UNRECOVERABLE_ERROR;
}
else {
return B_END_OF_FILE;} // End of cursor
// found. Record does not exist
}
// Check to see if this is the record we want to update
if (!strcmp(keyBuffer, tpRec.PubID))
found=1;
}
// The record to be updated has been found. The next step is to
// update it.
// The following code is taken from the CursorUPD function in
// Mybtrv32.c
// Initialize the client record buffer
memset( &tpRec, 0, sizeof(tpRec) );
memcpy(&tpRec, dataBuffer, sizeof(tpRec));
// Initialize the tpRec data structure
memset( &tpRec, 0, sizeof(tpRec) );
memcpy(&tpRec, dataBuffer, sizeof(tpRec));
/* Update the current row within the cursor. We rebind the columns
/* to update the length of the NULL terminated string columns. We
/* are using 0 for the the numRows parameter to affect all rows in
/* the rowset. Since we have a rowset size of 1 only the positioned
/* row will be affected. The key value of the current record is not
/* changing so we issue the positioned update using SQLSet
/* Pos(SQL_UPDATE, SQL_LOCK_NO_CHANGE)*/
SQLBindCol(hstmtS, 1, SQL_C_CHAR, tpRec.TitleID, 7, &cbTitleID);
.
.
.
rc=SQLSetPos(hstmtS, numRows, SQL_UPDATE, SQL_LOCK_NO_CHANGE);
if ((rc != SQL_SUCCESS && rc != SQL_SUCCESS_WITH_INFO))
{
ErrorDump("SQLSetPos SQL_UPDATE for TITLEPUBLISHER FAILED",
SQL_NULL_HENV, SQL_NULL_HDBC, hstmtS);
return B_UNRECOVERABLE_ERROR;
}
return B_NO_ERROR;
You can maximize the benefits of Microsoft SQL Server server-side resources. There are several areas on the server side that relate closely to the overall performance of your application system. Although these topics fall out of the scope of mainstream application development, when used effectively they provide benefits important to the overall performance of the system.
Three of the most versatile and powerful server-side resources are triggers, declarative referential integrity (DRI), and views. Triggers, DRI, and views are often used to reduce the complexity of the client and application. Used effectively, these features can improve the performance of your application.
In a SQL Server database, triggers are special stored procedures that take effect when data is modified in a specific table. Business rule consistency is enforced across logically related data in different tables by using triggers. Triggers are executed automatically when data modification occurs, regardless of the application interface that is used.
Referential integrity refers to the way in which an RDBMS manages relationships between tables. Referential integrity is implemented in the database using the CREATE TABLE or ALTER TABLE statements, with a clause that starts with FOREIGN KEY. For example, in a scenario with Orders and OrderLineItems, records should not exist in the OrderLineItems table if there is no corresponding record in the Orders table. Because Btrieve does not offer this feature, the Btrieve application performs all referential integrity at the client. Enforcing referential integrity at the server eliminates this processing from the client and can provide slight performance improvements.
Triggers and foreign key constraints also eliminate the need to change the application in multiple places if table schemas or relationships change. These modifications can be made at the server.
A view is an alternate way of looking at data resulting from a query of one or more tables. Views allow users to focus on data that fits their particular needs. Views simplify the way users can look at the data and manipulate it. Frequently used joins and selections can be defined as views so that users can avoid respecifying conditions and qualifications each time additional data operations are performed. Views also provide logical data independence because they help to shield users from changes in the structure of the base tables. In many cases, if a base table is restructured, only the view has to be modified, rather than each individual reference to the table.
For more information about views and triggers, see SQL Server Books Online and Knowledge Base (support.microsoft.com/support).
The Data Transformation Services Wizard (DTS Wizard) can help you move your data from Btrieve to SQL Server. First, you create a data source name (DSN) by using an ODBC driver or an OLE DB provider. Then the wizard leads you through the steps required for data migration.
Note Before you can begin migrating Btrieve data, you must have a Pervasive Btrieve ODBC driver. You can use the ODBC driver included with the Pervasive Btrieve product or a third-party driver.
First, you must create a Pervasive ODBC data source:
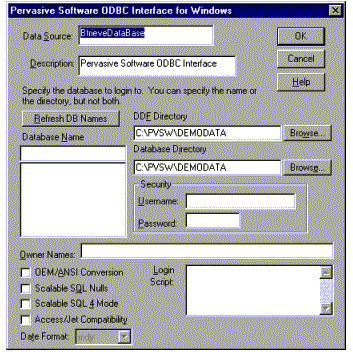

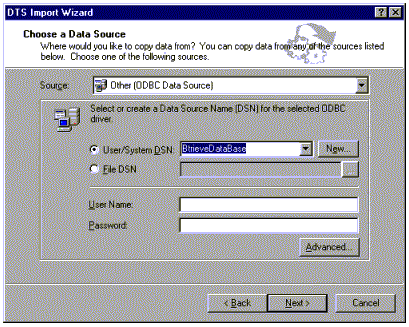

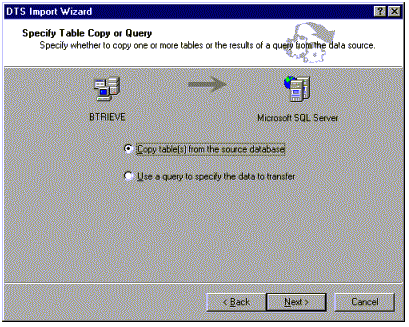


You can use this functionality to help you check for potential Y2K problems, and to change data to reflect standard coding such as country codes, state names, or phone number formatting.

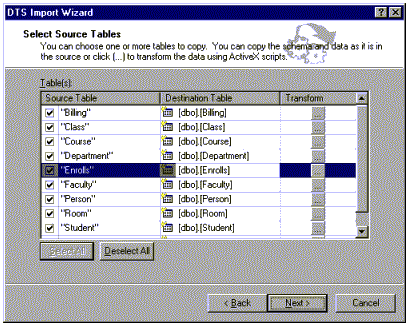
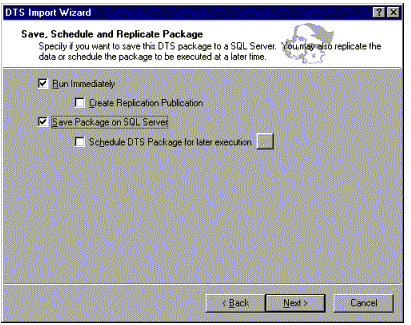

Microsoft SQL Server 7.0 is the clear solution for small to medium businesses with mission-critical applications. Microsoft SQL Server 7.0 helps small to medium businesses by:
The "SQL Server 7.0 Performance Tuning Guide" provides valuable information about creating SQL Server indexes, tuning disk I/O, RAID, and the use of SQL Server 7.0 performance tools. Database administrators and developers porting Btrieve applications to SQL Server are strongly encouraged to review this document in order to obtain maximum performance with SQL Server 7.0.
Database developers and administrators porting very large Btrieve databases or planning to build very large SQL Server 7.0 databases should review the information found in "SAP R/3 Performance Tuning Guide for SQL Server 7.0". While the information in this document is tailored toward SAP R/3 sites running SQL Server 7.0 as the database server, the SQL Server concepts apply to any large database running on SQL Server 7.0.
SQL Server documentation provides information about SQL Server architecture and database tuning along with complete documentation of command syntax and administration. Install SQL Server Books Online on the hard disk drives of computers running SQL Server.
For the latest information about SQL Server, visit the SQL Server Web site at http://www.microsoft.com/sql/ and Microsoft TechNet's SQL Server content on the TechNet CD Online at http://technet.microsoft.com/cdonline/default.asp.
The Hitchhiker's Guide to Visual Basic® and SQL Server™, Sixth Edition by William R. Vaughn covers valuable information and is up to date for SQL Server 7.0 and Visual Basic 6.0. It is available from Microsoft Press®. For more information, visit http://www.microsoft.com/mspress.
You can download the documentation for ADO, OLE DB, and ODBC from http://www.microsoft.com/data/. The Programmer's References for both OLE DB and ODBC are available from Microsoft Press at http://www.microsoft.com/mspress.
Btrieve 6.15.430 Developers Toolkit for Windows NT. Pervasive Software Inc.
| SQL Server 7.0 | Pervasive.SQL 7.0 | |
| Ease of Use, Installation, and Maintenance | XXX | |
| Dynamic memory allocation. | X | |
| Automatically allocates additional memory as resource requirements grow. | X | |
| Automatically frees memory as resource requirements shrink. | X | |
| Automatically allocates additional disk space as tables grow. | X | X |
| Automatically frees allocated disk space. | X | |
| Supports online backup. | X | X1 |
| Automatic update of statistics. | X | |
| Support for scheduled operations. | X | |
| Alerts and notifications. | X | |
| Provides tools for importing data. | X | X |
| Provides tools for exporting data. | X | |
| Provides Data Modeling Tools.2 | X | |
| Supports roll forward/roll back recovery. | X | X |
| Integrated context-sensitive Online Help. | X | |
| Wizard-driven interfaces to common tasks. | X |
1 Backups in Pervasive are performed by copying the individual file that holds the tables, using operating systems commands.
2 Tools that will generate Entity Relationship models.
| SQL Server 7.0 | Pervasive.SQL 7.0 | |
| Scalability | XXX | |
| Supports multiple INSERT, UPDATE, and DELETE triggers. | X | |
| Supports multiple processors. | X | X1 |
| Supports nested transactions (Check/Save Points). | X | X2 |
| Supports distributed transactions (through the 2-Phase Commit protocol). | X | |
| Supports heterogeneous queries. | X | |
| Partitioning of queries across processors. | X | |
| Row-level locking. | X | X |
| Dynamic escalation to page or table locking. | X | |
| Stored procedures. | X | X |
| Bulk loading of data. | X | X3 |
| Bidirectional, updateable, and scrollable cursors. | X | X |
| Supports both relational and ISAM Access methods. | X4 | X |
| Multiple indexes operations. | X | |
| Data Integrity | X | |
| Referential integrity. | X | X |
| Referential integrity during restores. | X | |
| Supports constraints. | X | |
| Supports user-defined data types (Domains). | X | |
| Differential database backup and restore. | X | |
| Backup/restore can be restarted. | X | |
| Security | XXX | |
| Integrated with operating system security. | X5 | |
| Supports the SQL GRANT keyword. | X | X |
1 Takes no advantage of the extra processors
2 Only in SQL 4 mode
3 Supports loading of data only from Btrieve files or sequential files
4 Support through cursors
5 Microsoft SQL Server integrates with Windows NT Security to allow a standard place and interface to administer database access privileges
| SQL Server 7.0 | Pervasive.SQL 7.0 | |
| Technical Support/Resources | XXX | |
| Certification testing for developers. | X1 | |
| Certification testing for support engineers. | X2 | |
| Product certification/logo programs. | ||
| Standards | XXX | |
| ANSI SQL-92 (ENTRY). | X | X |
| XA/OPEN. | X | |
| 32-Bit ODBC DRIVER. | X | X |
| OLE DB/ADO. | X | |
| COM/ActiveX Automation. | X | |
| TCP/IP. | X | X |
| Runs on Windows 95, Windows 98, Windows 2000 Server, and Windows 2000 Advanced Server. | X | X |
| Integration | XXX | |
| Integrated support for debugging stored procedures. | X | |
| Automatic generation of HTML (Web) pages based on SQL queries. | X | |
| Integration with Microsoft Office. Excel provides desktop multidimensional analysis to analyze gigabytes and terabytes of data. | X | |
| Tools to view SQL query optimization/execution plan. | X | |
| Provides an Online Analytical Processing (OLAP) engine. | X | |
| Provides natural language interface to database (English Query). | X |
1 Microsoft Certified Solution Developer
2 Microsoft Certified Systems Engineer
The following SQL Server script may be used to construct a 100,000 row SQL Server table with which to follow the example queries provided in this document. The script will create a table named btrieve_test. The row size has been defined to be 312 bytes. Be sure to experiment with this script, adding different data types and increasing the number of rows generated, in order to create test data that is as representative as possible of your current Btrieve database environment that needs to be ported to SQL Server 7.0.
To create the sample data (SQL Server Query Analyzer):
create table btrieve_test (
col1 char(4) not null default '000',
col2 char(4) not null default 'zzzz',
col3 int not null, filler char(300) default 'abc' )
declare @counter int
set nocount on
set @counter = 1
while (@counter <= 100000)
begin
if (@counter % 1000 = 0)
PRINT 'loaded ' + CONVERT (VARCHAR(10),@counter)
+ ' of 100000 record'
if (@counter % 100 = 0)
begin
insert btrieve_test (col2,col3) values ('a',@counter)
end
else
insert btrieve_test (col3) values (@counter)
set @counter = @counter + 1
end
create clustered index clustered_key1 on btrieve_test (col3)
This appendix addresses some of the common Btrieve operations and describes how the same functionality may be implemented for SQL Server 7.0.
The Btrieve GET operations provide record retrieval from a Btrieve database file based upon a Btrieve index. This is indicated by the inclusion of a Btrieve Key Number and, potentially, a Btrieve Key Buffer value during the call to BTRV(<op code>,…) with the appropriate Btrieve <op code> associated with the GET operation. The Btrieve Key Number specifies which Btrieve index will be used for the GET operation. The Btrieve Key Buffer is supplied to the BTRV() call when the GET operation requires a value to be specified so that key values from the records in the data file may be compared to the value in the Key Buffer in order to determine which records from the data file satisfy the query.
Abstract the Btrieve GET operation for a moment. The Btrieve database engine is provided with the name of the file from which data will be retrieved, the name of the index used for retrieving that data, and a value or set of values to compare against the data. This abstraction indicates that the GET operation maps well to SQL Server without using cursors. SQL queries can be constructed to match the operation of the Btrieve GET operation. All that is required are properly designed SQL Server indexes. With the proper indexes in place, it may be possible to define well-performing SQL statements that access rows from a table, based on an index with a key value or set of key values provided.
The most common GET operations and their potential translations to SQL Server 7.0 follow. For information about creating the btrieve_test table referenced in the examples, see Appendix B. For information about using SQL Server Profiler to monitor the performance of the ADO code samples, see Appendix E.
The Btrieve GET FIRST (op code 12) operation retrieves the first logical record in a Btrieve file based upon a Btrieve Key Number which tells Btrieve which index to use for the retrieval. While a cursor could be defined such that the SQL Server computer could process a FETCH FIRST statement on a SQL Server table to achieve the same effect as the Btrieve GET FIRST operation, it is worthwhile to consider an alternative method that does not require a cursor. Consider the sample data table btrieve_test and suppose that col3 is the data column on which an SQL query needs to determine which row is the first row. The following SQL statements would retrieve the first row:
declare @i int
select @i = min(col3) from btrieve_test
select * from btrieve_test where col3 = @i
and return the following results:
Table 'btrieve_test'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.
col1 col2 col3 filler
---- ------ ---------- --------
000 zzzz 1 abc
Table 'btrieve_test'. Scan count 1, logical reads 5, physical reads 0,
read-ahead reads 0.
The I/O statistics show that the operation of finding the first row of the btrieve_test table by the index on the col3 column is a very lightweight operation without the use of a cursor. A total of seven I/O operations from buffer cache to find the first row of a 100,000 row table is pretty good. This operation could be kept to one network round trip between the client and the SQL Server computer by putting the three SQL statements into a stored procedure:
To create a stored procedure (SQL Server Query Analyzer):
create procedure GetFirst as
begin
declare @i int
select @i = min(col3) from btrieve_test
select * from btrieve_test where col3 = @i
end
Exec GetFirst
It is possible to call the GetFirst stored procedure from Visual Basic with an equal amount of performance and efficiency with ADO.
In the earlier example, it costs the same number of logical reads to retrieve data that was required by the GetFirst stored procedure whether it was executed in ADO or in SQL Server Query Analyzer. It might take two or three runs of the ADO program to obtain the same seven logical I/O numbers as stated in the earlier SQL Server Query Analyzer example. This technique of comparing the I/O statistics from the execution of SQL statements in SQL Server Query Analyzer versus the database APIs is a good way to ensure that the I/O performance of database application code is within an acceptable range.
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim cmdSQL As ADODB.Command
Dim rsSQL As ADODB.Recordset
Set conn1 = New ADODB.Connection
'Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for
SQL Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
Set cmdSQL = New ADODB.Command
cmdSQL.CommandText = "GetFirst"
cmdSQL.CommandType = adCmdStoredProc
Set cmdSQL.ActiveConnection = conn1
Set rsSQL = cmdSQL.Execute
Do While Not rsSQL.EOF
Debug.Print rsSQL!col1
Debug.Print rsSQL!col2
Debug.Print rsSQL!col3
Debug.Print rsSQL!filler
rsSQL.MoveNext
Loop
rsSQL.Close
conn1.Close
End Sub
The Btrieve GET LAST (op code 13) operation retrieves the last logical record in a Btrieve file based upon a Btrieve Key Number. Similar to the Btrieve GET FIRST operation described earlier, the GET LAST operation could be mapped to a SQL Server cursor-oriented FETCH LAST operation. But GET LAST could also be represented in SQL Server with the use of the MAX () function when there is an index placed on the column that contains the key value defining the last record. Consider the sample data table btrieve_test and suppose that col3 is the data column on which an SQL query must determine which row is the last row. The following SQL statements would retrieve the last row in btrieve_test:
declare @i int
select @i = max(col3) from btrieve_test
select * from btrieve_test where col3 = @I
and return the following results and I/O statistics:
Table 'btrieve_test'. Scan count 1, logical reads 2, physical reads 0,
read-ahead reads 0.
col1 col2 col3 filler
---- ---- ----- ------
000 a 100000 abc
Table 'btrieve_test'. Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0.
The Get by Percentage operation (op code 44) fetches a record from a Btrieve file base on a percentage.
The SQL Server database APIs support operations that can help developers implement functionality similar to Get By Percentage. ADO provides the ability to move to a position in a cursor based on record number (referred to as absolute positioning), and the ability to fetch rows from an absolute position within the cursor using the .GetRows method of the RecordSet object. The row to start at and the number of rows to fetch are provided to the .GetRows method using the Start and Rows parameters respectively. OLE DB provides the direct ability to fetch into a cursor based on percentage using the IRowSetScroll::GetRowsAtRatio. And ODBC provides SQLFetchScroll API with the SQL_FETCH_ABSOLUTE value for the FetchOrientation parameter, which allows movement into a defined cursor by row number.
An alternative approach for migrating Get By Percentage calls is to calculate the record number(s) (based upon percentage), and then use a singleton or range select in order to retrieve the record(s).
If a cursor is used, it is best for performance if the size of the cursor is limited to the minimal amount of data possible. As an example, the following ADO code sample illustrates fetching of the 50 percent to 51 percent records from the sample table btrieve_test.
In this example, the ADO Recordset object is built upon a select statement that is calculated to be one percent of the 100,000 row table. It was important to keep the number of rows contained in the cursor to a minimum in order to maintain acceptable performance. In this example, it is helpful to define the clustered index for the table btrieve_test to be on col3. After the cursor is created, the .GetRows method can be used to fetch the first 30 rows from the cursor into an array called resultsetArray.
In order to simulate the Btrieve GET BY PERCENTAGE functionality, the application may calculate the key values that matched the desired percentage of the table to fetch. In this example, the assumption was that the fetch would operate on the table starting at 50 percent and then fetching the next 1 percent and that the hardcoded values of 50000 and 51000 that represent the 50 percent and 1 percent, respectively, were calculated previously.
For improved performance of scrollable data windows, open the cursor on only the number of rows that would be likely to be required by the user. If the user needs more, a new cursor can be created that spans the newly requested rowset. Smaller cursors are easier to open and manipulate. You can experiment with the following ADO source code, increasing the number of rows upon which the cursor is built, and noting the resource consumption difference in SQL Server Profiler.
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim rsSQL As ADODB.Recordset
Dim SQLString As String
Dim resultsetArray As Variant
Dim intRecord As Integer
Set conn1 = New ADODB.Connection
'Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for
SQL Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
Set rsSQL = New ADODB.Recordset
SQLString = "select * from btrieve_test where col3 > 50000
and col3 < 51000"
rsSQL.Open SQLString, conn1, adOpenDynamic, _
adLockOptimistic, adCmdText
resultsetArray = rsSQL.GetRows(30)
For intRecord = 0 To UBound(resultsetArray, 2)
Debug.Print " " & _
resultsetArray(0, intRecord) & " " & _
resultsetArray(1, intRecord) & ", " & _
resultsetArray(2, intRecord) & ", " & _
resultsetArray(3, intRecord)
Next intRecord
rsSQL.Close
conn1.Close
End Sub
As an alternative, you can choose not to use the SQL Server cursor to retrieve the range of rows. The following ADO code sample uses a SQL Server default result set to return the 1,000 rows. The sample code takes advantage of a SQL Server stored procedure named GetRows, and gains the performance benefit of precompilation. The benefits of precompilation are greater if the stored procedure will be re-executed many times.
This example illustrates a very simple method of calling a SQL Server stored procedure. The entire call to the stored procedure, including the two required parameters, is formatted as a single Visual Basic string variable, which is assigned to the ADO Command object's .CommandText property. The ADO Command object's CommandType property is set to adCmdText so that the string will be interpreted as a Transact-SQL command batch and sent directly to SQL Server instead of being interpreted by ADO as a stored procedure.
An alternative method of calling a SQL Server stored procedure from ADO would be to take advantage of the Parameters collection of the ADO Command object. The two parameters specifying the lower and upper bounds of the range (50000 and 51000 respectively) would be associated with the stored procedure by using the .Append method of the Parameters collection. For more information about using the Parameters collection of the ADO Command object, see the Microsoft Data Access Software Development Kit (DASDK) download available at http://www.microsoft.com/data/.
SQL Server Profiler indicates that the code sample using the server-side cursor requires approximately 10 times as much CPU and 100 times as many logical reads as the code sample that uses a default result set. Also, in SQL Server Profiler, the code sample using the dynamic cursor needs to send a sp_cursorfetch to SQL Server for every row retrieved from the cursor. In order to see SQL Server cursor operations in SQL Server Profiler, it is necessary to add cursor operations to the list of operations monitored by SQL Server Profiler.
To configure SQL Server Profiler to capture server-side cursor operations
create procedure GetRows @key1 int,@key2 int as
begin
select * from btrieve_test where col3 >= @key1 and col3 <= @key2
end
Notice the following line of code that is commented out (conn1. CursorLocation = adUseClient). If you were to remove the comment indicator ('), it would cause the 1,000 row result set to be stored locally on the client. This allows you to navigate the 1,000 rows with ADO recordset operations such as .MoveLast, .MovePrevious, and so on. Without the specification of the adUseClient, the result set will allow forward operations only (.MoveNext). The specification of adUseClient will increase resource consumption on the client in order to store the ADO Recordset object but will not increase resource consumption or execution time on SQL Server. Regardless of whether a local ADO recordset is created, SQL Server executes the stored procedure and sends the results back to the client as a default result set:
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim cmdSQL As ADODB.Command
Dim rsSQL As ADODB.Recordset
Set conn1 = New ADODB.Connection
'Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for
SQL Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
'conn1.CursorLocation = adUseClient
Set cmdSQL = New ADODB.Command
cmdSQL.CommandText = "exec GetRows 50000,51000"
cmdSQL.CommandType = adCmdText
Set cmdSQL.ActiveConnection = conn1
Set rsSQL = cmdSQL.Execute
Do While Not rsSQL.EOF
Debug.Print rsSQL!col1
Debug.Print rsSQL!col2
Debug.Print rsSQL!col3
Debug.Print rsSQL!filler
rsSQL.MoveNext
Loop
rsSQL.Close
conn1.Close
End Sub
The GET NEXT (op code 6) operation retrieves the next logical record in a Btrieve file based upon a specified key value.
When porting these GET NEXT calls from Btrieve to SQL Server, it is important to consider why the logical operation of fetching the next logical record is taking place. If it is possible to update or delete rows with a provided key value using SQL queries instead of cursors, performance will be enhanced. If there will be batches of updates, inserts, and delete operations, consider batching the operations together into a single Visual Basic String variable to be sent to SQL Server.
Sometimes it is critical to maintain positioning within a large SQL Server table in order to determine where database operations will occur. In this case, consider the use of a SQL Server dynamic cursor that retrieves just the key values from the table and then uses SQL queries to perform the remaining database operations outside of the SQL Server cursor. The dynamic cursor is a reasonably lightweight method of extracting a small percentage of the rows from a cursor defined over a large rowset. Transact-SQL statements that use the key values retrieved with dynamic cursors provide best performance for the update, delete, and insert operations into the SQL Server database.
The GET PREVIOUS (op code 7) operation retrieves the next logical record in a Btrieve file based upon a specified key value.
Use development strategies similar to GET NEXT as described earlier.
The following code example illustrates one approach that can be taken if it is determined that it is absolutely critical to maintain GET NEXT and GET PREVIOUS styles of database access with a Btrieve application being ported to SQL Server. The code updates the last ten records of btrieve_test.
The use of the SQL Server dynamic cursor provides quick access to the last 10 records of a 100,000 row dynamic cursor defined over the btrieve_test table.
An integer array named KeyArray is used to hold the values of col3 that are retrieved using the dynamic cursor. These ten values will be used as the key values with which updates are made. After the array has been built, it is iterated through once in order to construct a Visual Basic String called SQLCommandBatch. SQLCommandBatch will be sent to SQL Server with a single network round trip by opening a second ADO Connection object, named conn2, and using the .Execute method to execute the Transact-SQL command batch on SQL Server.
The code uses a SQL Server stored procedure named UpdateRow. Performance is improved because the query plans associated with the update operations are precompiled and reused from the SQL Server procedure cache.
create procedure UpdateRow @key int
as
update btrieve_test set filler = 'Updated' where col3 = @key
With this approach, SQL Server Profiler reported that the operations required 90 milliseconds of CPU, 302 logical reads, six physical writes, and 750 milliseconds of execution time. You should experiment with this code, using different cursors and database sizes, and note the differences in SQL Server Profiler:
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim rsSQL As ADODB.Recordset
Dim KeyArray(10) As Variant
Dim SQLCommandBatch As String
Dim i As Integer
Dim RecordsUpdated As Integer
Set conn1 = New ADODB.Connection
'Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for SQL Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
Set rsSQL = New ADODB.Recordset
rsSQL.Open "select * from btrieve_test order by col3", _
conn1, adOpenDynamic, adLockOptimistic, _
adCmdText
' Use a cursor to find the keys for the rows that need to be updated
rsSQL.MoveLast
For i = 1 To 10
KeyArray(i) = rsSQL!col3
rsSQL.MovePrevious
Next
' Create a second connection to SQL Server so that the command
' batch will not be executed through a cursor.
Dim conn2 As ADODB.Connection
Set conn2 = New ADODB.Connection
'Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for SQL Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
' Build up the Transact-SQL command batch to update the 10 rows
' with one SQL command batch
Dim cmd1 As Command
Set cmd1 = New ADODB.Command
Set cmd1.ActiveConnection = conn2
For i = 1 To 10
SQLCommandBatch = SQLCommandBatch & " exec UpdateRow " &
KeyArray(i)
Next
' Send the batch to SQL Server.
cmd1.CommandText = SQLCommandBatch
cmd1.Execute
rsSQL.Close
conn1.Close
conn2.Close
End Sub
The Get Equal operation retrieves any record(s) in a Btrieve file that match the key value supplied to the call. The SQL Server "=" comparison operator provides equivalent functionality when used in the WHERE clause of SQL queries.
It is best for performance if a default result set is used to retrieve the data. If the query will retrieve many rows, a clustered index on the column that is associated with the key value will help performance. If there will just be one row returned for the query, a nonclustered index on the column will be sufficient. If queries of the same pattern will likely be re-executed many times, use SQL Server stored procedures to precompile the queries and use parameters to supply key values to the stored procedures.
The GET GREATER THAN operation retrieves all records in a Btrieve file that have a key value which is greater than the key value supplied to a call. The SQL Server ">" comparison operator provides equivalent functionality when used in the WHERE clause of SQL queries.
It is best for performance if a default result set is used to retrieve the data and if there is a clustered index present on the column that is associated with the key values in the case where a large number of records are retrieved. For example, if on a given table, it is important to retrieve order records based upon a date range, it will help performance to place the clustered index on the date column. If queries of the same pattern will likely be re-executed many times, use SQL Server stored procedures to precompile the queries and use stored procedure parameters to supply key values to the stored procedures.
The GET GREATER THAN OR EQUAL operation retrieves all records in a Btrieve file that have a key value which is greater than or equal to the key value supplied to a call. The SQL Server ">=" comparison operator provides equivalent functionality when used in the WHERE clause of SQL queries. The same performance rules as in GET GREATER THAN apply here.
The GET LESS THAN operation retrieves all records in a Btrieve file that have a key value which is less than the key value supplied to a call. The SQL Server "<" comparison operator provides equivalent functionality when used in the WHERE clause of SQL queries. The same performance rules as in the case of GET GREATER THAN will apply here.
The GET LESS THAN OR EQUAL operation retrieves all records in a Btrieve file that have a key value which is less than the key value supplied to a call. The SQL Server "<=" comparison operator provides equivalent functionality when used in the WHERE clause of SQL queries. The same performance rules as in the case of GET GREATER THAN will apply here.
The following examples are designed to help illustrate how ADO interacts with SQL Server cursors for simple select, insert, and update statements. All of the examples perform database operations on the sample data defined for the SQL Server table named btrieve_test. Dynamic cursors were used in the examples. You are encouraged to experiment with the sample code to test the other types of cursors available.
Note The performance statistics reported for in this document were gathered from the code samples run on a single processor, single hard drive laptop. Because different computer environments can vary greatly, use only the I/O and time statistics presented here to make relative comparisons among the different programming styles. Also, in order to keep the code samples as compact as possible, no error handling code has been included.
For information about creating the btrieve_test table, see Appendix B. For information about using SQL Server Profiler to monitor the performance of the ADO code samples, see Appendix E.
The following sample code creates a SQL Server dynamic cursor based on the data in the SQL Server table named btrieve_test and ordered by the index on the column named col3. SQL Server Profiler indicated that the database operations performed using the cursor (.MoveFirst, .MoveLast, .MoveNext and .MovePrevious) required a total of 214 logical reads from SQL Server buffer cache and six physical disk writes. This is a reasonable amount of I/O cost to pay for the database operations involved. Query execution time was less than one second. Try the different cursor options with this code sample in your environment to see the different performance levels of cursors for this operation. This example favors the performance characteristics of a SQL Server dynamic cursor because it opens a cursor over a fairly large set of rows (100,000), but only performs operations on a small percentage (four) of these rows. Dynamic cursors do not store rowset data in tempdb and do not consume resources corresponding to the fetching of a given row until that row is actually read from or written to. As a larger percentage of the cursor rowset is operated upon, the resource consumption of a dynamic cursor will fall more into line with other forms of SQL Server cursors.
If you were to substitute adOpenKeySet, adForwardOnly, or adOpenStatic for adOpenDynamic in the .Open call of the recordset object named rsSQL, you would notice a very significant performance difference between the dynamic cursor and the other types of cursors on this 100,000 row table. The performance difference is due to the fact that other cursor types need to retrieve much larger amount of data during the opening of the cursor and involve varying amounts of tempdb activity. For the other cursors, you also need to increase the .CommandTimeout property of the connection object named conn1 because the default of 30 seconds might be insufficient for allowing the recordset .Open operation to complete. To set the time-out, uncomment the line "conn1.CommandTimeout = 360". This sets a 360 second time-out for the SQL queries. If desired, you may also increase the time-out to be infinite by setting the .CommandTimeout property of the recordset object to zero. For more information about ADO, see http://www.microsoft.com/data/. and the MSDN Library.
In this example, all of the other types of cursors besides the dynamic cursor required up to one hundred times the amount of I/O to complete the required database operations. Dynamic cursors provide best performance when operating over large rowsets, and when it is known that you will search only for a few of the rows in the cursor.
The following code sample was written in Visual Basic 6.0, Enterprise Edition with the ADO 2.0 library.
To compile the code example (Visual Basic):
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim rsSQL As ADODB.Recordset
Set conn1 = New ADODB.Connection
'conn1.CommandTimeout = 300
'Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for SQL Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
Set rsSQL = New ADODB.Recordset
rsSQL.Open "select * from btrieve_test order by col3", _
conn1, adOpenDynamic, adLockOptimistic, _
adCmdText
rsSQL.MoveLast
Debug.Print rsSQL!col1
Debug.Print rsSQL!col2
Debug.Print rsSQL!col3
Debug.Print rsSQL!filler
rsSQL.MoveFirst
Debug.Print rsSQL!col1
Debug.Print rsSQL!col2
Debug.Print rsSQL!col3
Debug.Print rsSQL!filler
rsSQL.MoveNext
Debug.Print rsSQL!col1
Debug.Print rsSQL!col2
Debug.Print rsSQL!col3
Debug.Print rsSQL!filler
rsSQL.MovePrevious
Debug.Print rsSQL!col1
Debug.Print rsSQL!col2
Debug.Print rsSQL!col3
Debug.Print rsSQL!filler
rsSQL.Close
conn1.Close
End Sub
You can execute the following SQL statements as a single SQL command batch in SQL Server Query Analyzer to compare the performance with the ADO code samples. In this case, SQL Server Profiler reported that the statements in the command batch required 6,300 logical reads, 50 physical disk writes, and approximately four seconds of execution time to complete the operation.
To execute the insert statements (SQL Server Query Analyzer):
declare @i int
set nocount on
set @i = 200000
while (@i < 201000)
begin
insert btrieve_test (col3) values (@i)
set @i = @i + 1
end
The following code uses a SQL Server dynamic cursor to insert 1,000 rows into btrieve_table. SQL Server Profiler reported that when the dynamic cursor was used, the required amount of time to complete the inserts was approximately 34 seconds, with 50,528 logical reads and 57 disk writes. Static, keyset, and forward-only cursors required more I/O and approximately double the execution time than the dynamic cursor required.
The processing cost associated with a cursor is approximately eight times slower than if the SQL statements were executed without the use of cursors. The dynamic cursor is again the best performing cursor option, but not by the same degree as was noted in the previous ADO example with database reads:
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim rsSQL As ADODB.Recordset
Set conn1 = New ADODB.Connection
' Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for SQL
Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
Set rsSQL = New ADODB.Recordset
rsSQL.Open "select * from btrieve_test order by col3", _
conn1, adOpenDynamic, adLockOptimistic, _
adCmdText
rsSQL.AddNew
rsSQL!col1 = "000"
rsSQL!col2 = "b"
rsSQL!col3 = 200000
rsSQL!filler = "Test row from ADO."
rsSQL.Update
' generate 1000 new records to
' insert into the table with .UpdateBatch
Dim i As Integer
For i = 1 To 1000
rsSQL.AddNew
rsSQL!col1 = "000"
rsSQL!col2 = "c"
rsSQL!col3 = 200000 + i
rsSQL!filler = "Test rows from ADO."
Next i
rsSQL.UpdateBatch
rsSQL.Close
conn1.Close
End Sub
This example demonstrates the use of ADO client-side static cursors using an ADO recordset object with the adUseClient option enabled for the RecordSet.CursorLocation property. Use of the adLockBatchOptimistic option during the recordset object open is also required so that the .UpdateBatch method will work correctly.
The code sample fetches a single row of data into the static client-side cursor and opens the cursor. By fetching only a single row into the client-side cursor for the cursor open, the client-side cursor open time is minimized. As an experiment, you can change the static cursor so that more of the table is fetched during the cursor open time. The more data that is fetched by the SQL statement contained in the rsSQL.Open call, the slower the client side cursor opens. SQL Server Profiler can be used to observe the CPU, Read, and Duration counters for the cursor open time.
After the client-side cursor is open, more data is added to the recordset using the .AddNew method. During the .AddNew operations, no round trips are used to communicate with SQL Server. New data is added to the local client-side cursor. Next, the .UpdateBatch method is called so that all inserts that were generated on the ADO client-side cursor are sent to SQL Server. ADO packs as many insert calls as it can into command batches sent to SQL Server. No SQL Server cursor operations are used. This command batching helps minimize network traffic. In this example, 67 command batches using sp_executesql are required to execute the 1,000 inserts. ADO creates the command batches automatically. This code sample performs well because very little data is fetched into the ADO client-side cursor initially, and because of the ADO automatic command batching of the inserts.
With 3,500 logical reads, 34 physical writes, and 8.6 seconds of execution time required, the performance of this code sample is quite good. This is four seconds slower than the SQL Server Query Analyzer example and two seconds slower than the following ADO code example, which uses no cursors. Instead, it constructs SQL command batches manually within ADO code to reduce the number of command batches to three instead of 67.
The decision of whether to use an ADO client-side cursor versus manual command batch construction depends on whether you are willing to sacrifice some performance for the convenience of ADO constructing SQL Server command batches for you automatically:
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim rsSQL As ADODB.Recordset
Set conn1 = New ADODB.Connection
' Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for SQL
Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
Set rsSQL = New ADODB.Recordset
rsSQL.CursorLocation = adUseClient
rsSQL.Open "select * from btrieve_test where col3 = (select max(col3)
from btrieve_test)", _
conn1, adOpenStatic, adLockBatchOptimistic, adCmdText
' generate 1000 new records to
' insert into the table with .UpdateBatch
Dim i As Integer
For i = 1 To 1000
rsSQL.AddNew
rsSQL!col1 = "000"
rsSQL!col2 = "c"
rsSQL!col3 = 200000 + i
rsSQL!filler = "Test rows from ADO."
Next i
rsSQL.UpdateBatch
rsSQL.Close
conn1.Close
End Sub
As stated earlier, SQL Server Query Analyzer requires approximately four seconds of execution time to complete the 1,000 inserts. Given that ADO is the recommended database API for general database application development, it would be desirable to achieve performance close to this number, but from within ADO. The following ADO code performs 1,000 row inserts into the test table, but uses a different technique from the dynamic cursor example.
In this case, the connection object named conn1 is used to execute an SQL statement batch. The SQL statement batch is stored in the Visual Basic String variable named SQLString. One thousand insert statements are built, one by one, with Visual Basic code on the client side. The insert statements are sent to SQL Server in batches of 400 insert statements or less per batch. The Mod (modulo operator) is used in the following code to detect the point at which SQLString contains 400 insert statements. At that point, SQLString is sent as one SQL Server command batch to SQL Server, and then SQLString is emptied in preparation for the next SQL batch construction.
Sending 400 SQL statements as one batch is much more efficient than sending each insert to SQL Server individually because it greatly reduces the number of network round trips required to submit all of the statements. In this example, there will be three batches constructed and sent to SQL Server: the first two with 400 statements, and the last one with 200 statements.
With the reduction of network round trips and using insert statements versus cursor operations, SQL Server Profiler reported that this code sample was able to perform the required operation in 6.5 seconds, which is more in line with how fast SQL Server Query Analyzer was able to perform the operations. The logical and physical I/O statistics for this code example were very close to the I/O statistics for the SQL Query Analyzer case:
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim SQLString As String
Dim i As Long
Set conn1 = New ADODB.Connection
conn1.CommandTimeout = 0
'Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for SQL
Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
For i = 200001 To 201000
SQLString = SQLString + "insert btrieve_test (col3) values" & _
" (" & i & ");"
If ((i Mod 400) = 0) Then
conn1.Execute (SQLString)
SQLString = ""
End If
Next i
conn1.Execute (SQLString)
conn1.Close
End Sub
In this situation, dynamic cursors performed at the same level as the other cursor types. SQL Server Profiler reported approximately 65,000 logical reads and 75 seconds of execution time for all of the runs with this code sample. Dynamic cursors require slightly fewer physical writes (eight) than the other cursor types, which required approximately fifty. However, this lower number of writes did not help the dynamic cursor update any faster than the rest of the cursor types. In fact, the dynamic cursor was marginally slower than the other cursors in this update example, which may have been due to the higher level of CPU consumed by the dynamic cursor for the operation:
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim rsSQL As ADODB.Recordset
Dim SQLString As String
Set conn1 = New ADODB.Connection
'Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for SQL Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
Set rsSQL = New ADODB.Recordset
SQLString = "select * from btrieve_test where " & _
"col3 > 49999 and col3 < 51000 order by col3"
rsSQL.Open SQLString, conn1, adOpenDynamic, _
adLockOptimistic, adCmdText
rsSQL.MoveFirst
Do While Not rsSQL.EOF
rsSQL!filler = "Updated"
rsSQL.Update
rsSQL.MoveNext
Loop
rsSQL.UpdateBatch
rsSQL.Close
conn1.Close
End Sub
You can execute the following SQL statements as a single SQL command batch in SQL Server Query Analyzer in order to compare the performance with the ADO code samples. In this case, SQL Server Profiler reported that the statements in the command batch required five seconds, 6012 logical reads, and 50 physical writes to complete.
To execute the update statements (SQL Server Query Analyzer):
declare @i int
set nocount on
set @i = 49999
while (@i < 51000)
begin
update btrieve_test set filler = 'Updated' where col3 = @i
set @i = @i + 1
end
Similar to the earlier ADO 1000 row insert code sample, this code sample takes advantage of an ADO client-side cursor by reading the 1,000 rows from SQL Server that need to be updated. Modifications to the local copy of the rows are performed by ADO within the client-side cursor. After modifications to the 1,000 rows are completed, all of the required SQL Server update statements are generated and packaged into SQL Server command batches. Each command batch uses sp_executesql to send 15 parameterized update statements to SQL Server. In total, the 1,000 updates require sending 67 command batches.
Operations required a total of 10.5 seconds and 3145 logical reads. This code sample was run several times so that all required data pages were already in the SQL Server buffer cache. This meant that updates occurred as writes to cache pages rather than as physical writes to SQL Server files on disk. SQL Server Profiler watches physical writes instead of cache writes. Cached writes are one reason why these code samples report different performance results depending on whether data pages are cached.
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim rsSQL As ADODB.Recordset
Dim SQLString As String
Set conn1 = New ADODB.Connection
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
Set rsSQL = New ADODB.Recordset
rsSQL.CursorLocation = adUseClient
SQLString = "select * from btrieve_test where " & _
"col3 > 49999 and col3 < 51000 order by col3"
rsSQL.Open SQLString, conn1, adOpenStatic, _
adLockBatchOptimistic, adCmdText
rsSQL.MoveFirst
Do While Not rsSQL.EOF
rsSQL!filler = "Updated"
rsSQL.Update
rsSQL.MoveNext
Loop
rsSQL.UpdateBatch
rsSQL.Close
conn1.Close
End Sub
Like the earlier insert example, better performance is achieved if the update statements are submitted from ADO to SQL Server as SQL command batches instead of using a cursor. SQL Server Profiler reported that the operations required eight seconds, 15670 logical reads, and approximately 50 physical writes to complete the operation.
Private Sub Form_Load()
Dim conn1 As ADODB.Connection
Dim SQLString As String
Dim i As Long
Set conn1 = New ADODB.Connection
conn1.CommandTimeout = 0
'Connect to SQL Server with SQLOLEDB - Microsoft OLE DB Provider for
SQL Server
conn1.Open "Provider=sqloledb; Data Source=(local);" & _
"Initial Catalog=pubs;User Id=sa;Password=; "
For i = 49999 To 51000
SQLString = SQLString + "update btrieve_test set filler =
'Updated'" & _
" where col3 = " & i & ";"
If ((i Mod 400) = 0) Then
conn1.Execute (SQLString)
SQLString = ""
End If
Next i
conn1.Execute (SQLString)
conn1.Close
End Sub
To monitor the SQL Server resource usage of the ADO code examples presented in this document, take advantage of the SQL Server Profiler.
To set up SQL Server Profiler:
At this point SQL Server Profiler displays performance information about all of the queries sent to SQL Server. Run the ADO sample code two or three times, and pay particular attention to the Reads column of the SQL Server Profiler display. It is worthwhile to set a break point in the sample code (click the point at which you want to stop at in the code, and then press F9) and toggle between the ADO code in Visual Basic and SQL Server Profiler (Press ALT + TAB to toggle between Visual Basic and SQL Server Profiler quickly). Note the Profiler information generated at each point in the code sample. The Reads column indicates the number of logical reads required by the database operation. Logical reads are 8 KB page reads that are satisfied from the SQL Server buffer cache (in memory). Your performance tuning objective in porting Btrieve applications to SQL Server is to be able to run the ported application with the values indicated in SQL Server Profiler for Reads, Writes, and CPU as low as you can get them. Use SQL Server Profiler regularly to check your database API development work.
Note It is also possible to log the information that the SQL Server Profiler displays on the screen into a log. These logs are referred to as Profiler trace files, or .trc files. It is also possible for SQL Server Profiler to log information into a SQL Server table. After SQL Server Profiler information is placed into a SQL Server table, it is possible to index and query a large amount of SQL Server Profiler information with SQL statements. This makes it easy to record a large amount of Profiler information over an extended period of time, and then search this information to find out which database operations consumed the most resources. The "SQL Server 7.0 Performance Tuning Guide," contains an example of how to load a SQL Server table with SQL Server Profiler information, and how to perform a query on the information. The guide also contains an example of how to use .trc files generated by SQL Server Profiler in the SQL Server Index Tuning Wizard to analyze the current indexes defined on the SQL Server database, and make recommendations as to whether there may be other indexes that would help performance. SQL Server Index Tuning Wizard also generates the required SQL statements for index creation, if desired.
To stop SQL Server Profiler: