David Willson
Microsoft Developer Network
August 1999
Summary: Follows the transformation of data as it passes from one layer to the next through the Duwamish Books, Phase 4 system. (12 printed pages)
Overview
Importing Data
Using OSQL Instead of ISQL
Scrubbing Source Files
Importing Records into the Duwamish Books Database
Providing Search Context
Searching for a Book
Category Search
Keyword Search
Natural-Language Search
Conclusion
The Duwamish Books system at Phase 4 is an online bookseller. As customers use the search engine, the system relays the customer's message from one component to the next. How is the data transformed as it passes from one layer to the next? What actions are taken to preserve the content? This article is a discussion of how content is preserved as data moves through the Duwamish Books system.
To find out more about the Duwamish Books, Phase 4.0 system see our online articles at http://msdn.microsoft.com/voices/sampleapp.asp.
A data entity's entry into the system is through the data import process. From the start, we need to pay close attention to multilingual data issues and preservation of content.
The Duwamish Books database has been designed to accommodate multilingual data through several elective design choices. From one country to the next, there are slight variances in proper form of an address. Rather than imposing a standard based on one nation, we chose a freeform address format in a single column that will work for most countries. The number of names, or the importance of first or last name, varies from one culture to the next. Using a singular column to represent the name preserves the format that is most important to the user. Also, choosing the nvarchar data type for all strings was an important design consideration. The nvarchar data type is one of three national language data types used to store Unicode characters in the Microsoft® SQL Server™ 7.0 database.
Until the release of SQL Server 7.0, the isql command-line utility was the tool to use to execute script files on a server. The foundation for the isql utility was the DB-Library API, which remains at the SQL Server 6.5 level of functionality. The database scripts that build the Phase 4 Duwamish Books database sample install some multilingual records. This means the isql utility can no longer be used to fully support the functionality of an SQL Server 7.0 database.
New in SQL Server 7.0 is the osql command-line utility, which was developed using the SQL Server 7.0-compatible ODBC database API. The osql utility was modeled after the design of isql, so most of the arguments are the same. The osql utility can accommodate the higher character limit for varchar columns as well as the national language data types nvarchar, nchar, and ntext.
Data can arrive in many formats and conditions. It takes a skilled database professional to begin the data import process by identifying and correcting potential problems with the data in a source file. Once this work is done, an efficient method suitable for the quantity of data needs to be employed to finally move the database from the source file to the database.
Source files potentially contain invalid records, coded information, records that have no bearing on our work, and misspellings. Scrubbing is the process of removing or changing the unwanted qualities of an original source file into a format that can be imported directly into the database.
There are other potential problems with the data in source files. We will need to pay close attention to quoted strings and the use of commas in strings. We will need to watch out for incompatible data types and overloaded columns, duplications, or perhaps mixed-case words that should otherwise match data that is already in the database.
The Duwamish Books database is a highly normalized relational database. It is possible to insert records directly into the proper tables when great care is taken to identify object dependencies and the business logic. This approach is both time-consuming and error-prone, so it is not advised.
Rather, it is far easier to use the Business Logic Layer (BLL) to distribute the records to the correct location. The BLL isolates the details of the business logic and the database structure and connectivity from the user.
We can use the SQL Server 7.0 DTS Import Wizard to import most source files directly into a temporary work table on the database server. Once the data is installed on the database server we can use the BLL methods to move the data from the work table directly into the proper tables. Another method is to write a program that interprets the source file and uses the BLL COM interface to move the data into the proper tables. Either method involves some programming work.
The category structure is not restricted to a specific number of subcategories; rather, each category has a reference to a parent category. In the database there is a many-to-many relationship between books and categories. This means any single category may have a reference to any of the books. Similarly, any single book can be found in any of the categories.
To insert a new category, use the BLL InsertCategory method. To insert a relationship between an item into an existing category, use the BLL InsertItemCategory method.
The keyword search is designed to store distinct singular words. Just like the relationship between books and categories, there are many-to-many relationships between books and keywords to describe author keywords, subject keywords, and title keywords for a book.
The BLL automatically installs author, title, and subject keywords when a book is inserted using the InsertItem methods. However, there are globalization issues with the approach we have adopted. For example, to get the title keywords from a book's title we locate the breaks between words where we find spaces or punctuation. This does not work for some languages, such as Japanese, where words are not separated by spaces or English punctuation. To insert keywords directly it is necessary to modify the way the InsertSubjectKeywords, InsertAuthorKeywords, and InsertTitleKeywords stored procedures interpret word break locations.
The Duwamish Books Web site includes seven specific search types. In this part of the article we will explore the transformation of data as it passes through category, subject keyword, and the natural-language search.
The category search is simple by comparison. Clicking one of the links in the category either sends you to another category or to a detail page. The keyword search and natural-language search begin from the advanced search page. Both of these search types require a specific format for user input and yield the same search result page. However, these searches function in very different ways.
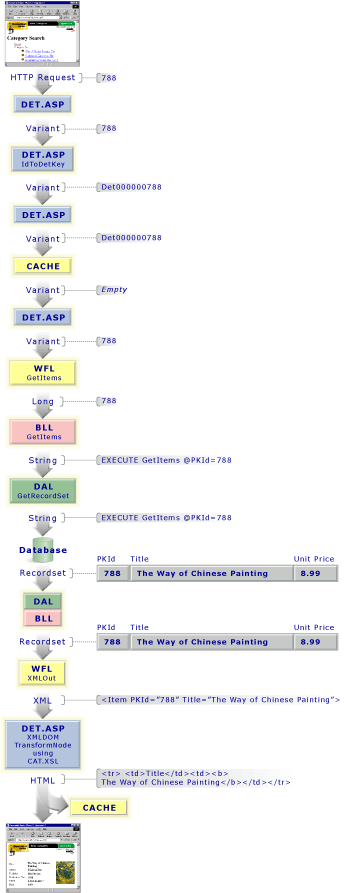
Shown here is a sample of the part of the HTML code from the Approach 1 category search used to display the books and other categories that can be accessed from a specific category:
<a href="cat.asp?1">
Books
</a>
<a href="det.asp?788">
The Way of Chinese Painting
</a>
In this case, "Books" is a label for a link to another category. This is followed by a link to the detail page for a book that has the title "The Way of Chinese Painting." Notice that the links are expressed with a file name followed by a question mark and then a number. The part of the expression that follows the question mark is known as the QueryString. There will be more discussion on the QueryString in the next section.
The cat.asp file contains Microsoft Visual Basic® Scripting Edition (VBScript) code. This code will ultimately produce the HTML code used by the browser to construct another category search page.
Saving category pages to the cache is an important aspect of the way the Duwamish Books system works. If the system can obtain the HTML without returning to the database, the speed of producing the next category search page will increase dramatically.
The first part of the code for cat.asp determines if the category that is to be displayed can be found in the cache. If it is not found, it will then be necessary to go to the database to find information related to the category.
CatId = Clng(request.QueryString)
CatKey = IdToCatKey(CatId)
CatHTML = Application("Cache")(CatKey)
In these three lines of code we search the QueryString in the HTTP Request object to determine the numeric category identifier (CategoryId) we are searching for. The cache object uses an alphanumeric key rather than the CategoryId to address cached objects. This means we need to convert the CategoryId expressed in the QueryString to a key that is or would be used to indicate the cached category page in the cache object.
If the page is present, we will save a lot of time. The HTML code from the cache will be sent directly to the browser, requiring no further interaction with the system. However, if the category is not in the cache it will be necessary to query the database to retrieve the proper information about the subcategory, generate the HTML code, and then store the HTML in the cache object. (This process is described to follow.)
The det.asp file contains nearly identical VBScript code to that of cat.asp. Just like the code in the cat.asp file, the code in the det.asp file will ultimately produce the HTML code the browser uses to construct a detail page for a specific book.
If the HTML code for the category page cannot be found in the cache, it is necessary to query the database for the content. To do this, the VBScript code in the cat.asp file uses the Duwamish Books Workflow object. The GetCategory method in the Workflow object sends the CategoryId that was obtained from the HTTP Request object, and in turn transforms the resultset returned by the database into XML code.
There are a few exceptions to the way that this happens. When the numeric identifier is not passed to the Workflow object, the code in the Workflow object will locate the starting node for the category search.
Call oBll.GetCategories(oRs)
If oRs.RecordCount Then
oRs.MoveFirst
oRs.Filter = scFLT_PKID & CategoryId
End If
sCategory = XMLOut(oRs, scCATEGORY, icATTRIBUTED)
Because the number of categories tends to be relatively small compared to the number of books or the number of orders, all categories are returned in the recordset. A filter is applied so that only the categories we are interested in will be displayed (the parent category, the current category, and any subcategories). In the preceding code we execute the BLL GetCategories method to produce a complete recordset of all categories. (We will explore the BLL in the next section.) Once the recordset is filtered, the recordset is transformed into XML code using the XMLOut function.
After the parent category, current category, and subcategories are transformed from recordset format into XML code, we need to identify the books that are to be listed in the category. A second pass to the database, through the BLL, is required to accomplish this. The GetItems procedure returns a recordset of the books in a specific category when we supply the numeric identifier for the category. Just as we used the XMLOut function to transform the category recordsets to XML code, we use the same function to transform book records to XML code.
The BLL object gathers information about the database using the Data Access Layer (DAL). The DAL acts as a buffer between the BLL and the database, shielding the BLL from the details of establishing a connection. However, all knowledge of how the database is formed is stored in the Business Logic Layer. This means in a BLL function like GetCategory, the DAL GetRecordset function requires a valid SQL statement that will build the needed recordset. In the case of the BLL function GetCategory, the string "EXECUTE GetCategory @CategoryId=23" will be relayed through the DAL to the database.
Not all browsers are capable of displaying XML code. Also, the XML code returned by the Workflow object methods is essentially raw data. For these reasons we use another file, known as an XSL style sheet, to convert our raw data in XML code format into presentation-quality data in HTML code format.
Dim CatId
Dim CatXML
Dim CatHTML
Set XMLDoc = Server.CreateObject("Microsoft.XMLDOM")
Set XSLDoc = Server.CreateObject("Microsoft.XMLDOM")
Set WFL = Server.CreateObject("d4Wflow.cWorkflow")
CatId = CLng(request.QueryString)
CatXML = WFL.GetCategory(CatId)
XMLDoc.loadXML(CatXML)
XSLDoc.load(Server.MapPath("cat.xsl"))
CatHTML = XMLDoc.documentElement.transformNode(XSLDoc.documentElement)
In the abbreviated VBScript code for cat.asp just shown, two instances of the XML Document Object Model (DOM) object are used to transform the raw-data XML code into presentation-quality HTML code. The first XML DOM object is loaded with the XML code generated by the Workflow object. The second XML DOM object is loaded with the cat.xsl style sheet we designed for the Duwamish Books system. The last line is where the transformation takes place. The transformNode function accepts the style sheet XML DOM object as an input parameter and outputs the presentation-quality HTML code.
The main difference between category search and the advanced search types is that the advanced search accepts variable user input. For these search types we will ensure the user-provided content is preserved as it is passed from one component to the next.
There are three types of keyword searches on the advanced search page. The three types refer to different attributes of the book: author, title, and subject. The code for each of these types of searches uses nearly identical code.
Let's observe what happens when the user performs a subject keyword search. To begin, we will choose the subjects "france" and "revolution." The following string is entered in the Subject Keyword input box:
France,revolutionNote that there are limitations to the keyword search. The search string requires a comma-delimited list of keywords without spaces. Multiple keywords are only joined using "or" logic, yet search results are ordered by the number of closest matches. With some work, stored procedures and BLL class methods can be added to the system to allow more customized search capability.
While we are on the advanced search page we can review the HTML source code from the browser's menu (In Microsoft Internet Explorer 5.0, click View and then Source). Here is the segment of HTML source code that relates to the construction of the natural-language search part of the page:
<FORM action="sresults.asp" method=post>
<P>Subject Keyword Search<BR>
<INPUT type="hidden" name=SearchType value=SearchSubjectKeyword>
<INPUT name=SearchText style="HEIGHT: 50px; WIDTH:50%">
<INPUT type="Submit" value=Go style="HEIGHT: 24px; WIDTH: 27px">
</P>
</FORM>
Reviewing the HTML source code, we can see how the subject keyword query is entered into the system. The first line of the code identifies that the action to take when the user clicks the Go button is to load the file called sresults.asp. (The sresults.asp file is the VBScript code we will explore next). The second item on the first line is method=post. This means we will be posting information to the sresults.asp code. Specifically, we will post the content the user provided in the input text box.
There are three inputs in the code example just shown, but each input is of a unique type. The third input shown is the Go button next to the Subject Keyword Search input box on the advanced search Web page. The other two inputs have a name-value attribute pair that will be passed to the VBScript code in the sresults.asp file as part of the post method.
The first input parameter is a hidden type. This means no controls will be drawn on the Web page for this input. However, the attribute-value pair, which in this case is SearchType=SearchSubjectKeyword, will be transmitted to the VBScript code in the sresults.asp file through the HTTP Request buffer. All advanced search queries are rendered using the code in sresults.asp. This means in order to distinguish the current search request as a subject keyword query, the type of search must be made available to the sresults.asp code.
The second input parameter is the default input type. HTML builds an input text box to the dimensions indicated, and then passes the string the user entered into the text box along to the VBScript code in the sresults.asp file as SearchText.
The VBScript code identifies the search type by using the Request.Form property of the HTTP Request object. In this code module, the subject keyword query is passed along to the oWFL Workflow object. The following code is an abbreviated version of sresults.asp:
<%
Set XMLDoc = Server.CreateObject("Microsoft.XMLDOM")
Set XSLDoc = Server.CreateObject("Microsoft.XMLDOM")
Set oWFL = Server.CreateObject("d4Wflow.cWorkflow")
Dim sXML
XMLDoc.async = false
Select Case Request.Form("SearchType")
Case "SearchTitle"
...
Case "SearchSubjectKeyword"
sXML = oWFL.GetItemsBySubjectKeyword(Request.Form("SearchText"))
XMLDoc.loadXML(sXML)
XSLDoc.async = false
XSLDoc.load(Server.MapPath("sresults.xsl"))
Response.BinaryWrite(Chrw(&HFEFF) & XMLDoc.documentElement.transformNode(XSLDoc.documentElement))
End Select
%>
On the fourth line of the preceding VBScript code, the Workflow object is instantiated using the CreateObject method. Farther down in the code, on the line highlighted in bold, the subject keyword query the user entered into the input box is passed as a parameter to the GetItemsBySubjectKeyword method of the Workflow object. (We will discuss what becomes of the query in the next section). The output of this Workflow object method is XML code.
The remaining lines of code are used to prepare the XML code for display. First, the XML code generated by the Workflow object is loaded into the XML DOM object. Next, a custom style sheet is loaded. Setting the async property to false forces the VBScript code to wait for the style sheet to finish loading before continuing to the next statement. The sresults.xsl file is a custom style sheet used to convert XML code into HTML code that the browser will use to construct the search results Web page. The actual conversion takes place when the transformNode method is executed.
The Response.BinaryWrite command is what causes the HTML code to be sent to the browser. The browser will, in turn, interpret the HTML and build the search results page that the user sees. Typically, we might have used the Response.Write command to send the HTML code to the browser. However, the Response.Write command decodes strings using the ANSI standard, which would destroy the Unicode HTML code.
The character represented by hexadecimal FEFF is the Unicode byte order mark. Here we prefix the Unicode output of the HTML code rendered by the Workflow object with the Unicode byte order mark so the browser will be able to decode the Unicode character string correctly.
The GetItemsBySubjectKeyword method forwards the user's subject keyword query along to the BLL GetItems method. In the GetItems method the user's query is incorporated into an SQL EXECUTE statement in the following format:
EXECUTE GetItems @SubjectKeywordList='France,revolution'
As in the category search, the database returns a recordset, which is relayed through the DAL to the BLL and finally to the Workflow object, where the contents are converted from a recordset format into XML code.
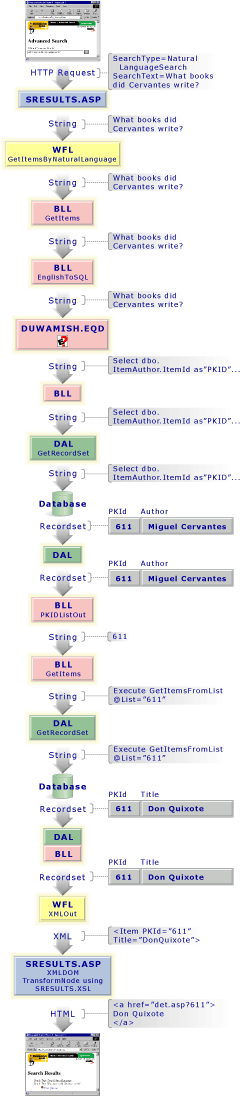
A natural-language search also begins with the advanced search page. This search option uses the English Query engine, which is a component of SQL Server 7.0.
The English Query engine is not a fully globalized component of the system. For instance, if we issue a query in Spanish, "¿Qué libros Cervantes escribió?", the English Query engine will not be able to interpret the Spanish grammar. The English equivalent, "Which books did Cervantes write?", will work just fine.
The binary English Query domain file (.eqd file) contains the information describing the relationship between the words the user might use in a natural-language query and some carefully chosen objects in the database. These are known as entity relationships and they are defined by creating sample phrasings. Here are the phrasings we incorporated into the Duwamish Books .eqd file:
Author names are the names of authors
Books are published
Books cost
Books are published in publication years
Publication years indicate how new books are
Books have authors
Authors write books
Books are by authors
Books have descriptions
Books have isbns
Books have publishers
Books are published by publishers
Prices indicate how expensive books are
Books have prices
Books cost prices
Publisher names are the names of publishers
Subject names are the names of subjects
Subjects have books
Books have subjects
Books are about, on subjects
Books have titles
So, how does the natural-language search work in Duwamish Books? Let's explore this by entering a sample question. Observing the preceding list of phrasings, we can choose a question the engine should be able to answer, such as:
Which books are about France and cost less than 10 dollars?
The Workflow object passes the natural-language query to the BLL object. The BLL then relays the query to the English Query object, which yields an SQL select statement. Ultimately, the BLL returns a recordset containing a list of books that match the criteria specified by the user. (We will describe this in greater detail in the section to follow.) However, due to the way we limited the selection list for English Query-generated SQL select statements, we can only rely on the numeric identifier—the PKId column—to be present in the resultset. For this reason, the recordset is returned to the BLL object in a second pass to get the book details. This action also returns a recordset.
After the second recordset is returned, the XMLOut Workflow object method is used to translate the recordset into the XML code that will represent the list of books that satisfy the user's criteria.
Public Function GetItemsByNaturalLanguage( _
ByVal SearchText As String) As String
...
If SearchText <> vbNullString Then
Call oBll.GetItems( _
oRs, NatLangIn:=SearchText, _
NatlangOut:=sRestated)
sIdList = PKIdListOut(oRs)
If sIdList <> vbNullString Then
Call oBll.GetItems( _
oRsItems, PKIdList:=sIdList, _
ItemTemplateType:=icCATALOG_4)
sItems = XMLOut(oRsItems, "Item", icATTRIBUTED)
End If
Set oRs = Nothing
End If
GetItemsByNaturalLanguage = _
"<Search Type=""SearchNaturalLanguage"" SearchText=""" & _
SearchText & """>" & vbCr & _
"<Restated>" & sRestated & "</Restated>" & vbCr & _
sItems & vbCr & _
"</Search>"
End Function
In the preceding Visual Basic Workflow object code, the two calls to the BLL are highlighted in bold. The line of code following the second call to the BLL method GetItems is where the recordset returned by the BLL is transformed into XML code.
The GetItems method is used to produce a recordset of items specified by some set of criteria. To follow the previous example, we are first performing a natural-language search. To do this, the BLL accesses the English Query engine to convert the natural-language query to a valid SQL expression. The following code is from the BLL EnglishToSQL function:
Dim oNatlanguage As New cNatlanguage
Call oNatlanguage.EnglishToSQL(sNLIn, sNLOut, sRspOut, sSqlOut)
When we supply this function, the natural-language user query:
Which books are about France and cost less than 10 dollars?
Is rephrased by the English Query engine as:
List the france books that cost less than 10 dollars.
The English Query engine then interprets the sentence. Parts of the sentence are compared to the entities and relations phrasings we have defined in the .eqd file. For this query, the English Query engine identifies three entities and three phrasings that can be used to translate the English phrase into an SQL query. They are as follows.
| Entity or phrasing | Location in query |
| Price | 10 dollars |
| Subject | france |
| Book | List the books |
| Books cost prices | books that cost less than 10 dollars |
| Subject names are the names of subjects | france |
| Books are about, on subjects | france books |
Which produces the SQL select statement:
select dbo.Items.PKId as "PKId",
dbo.Keywords.Keyword as "Keyword",
dbo.Items.UnitPrice as "UnitPrice",
from dbo.Items, dbo.Keywords, dbo.ItemSubjectKeyword
where dbo.Items.UnitPrice < 10
and dbo.Keywords.Keyword = 'FRANCE'
and dbo.Keywords.PKId = dbo.ItemSubjectKeyword.KeywordId
and dbo.Items.PKId = dbo.ItemSubjectKeyword.ItemId
Once the SQL code is generated, the BLL code passes the SQL select statement to the Data Access Layer. In the DAL, the statement is sent to the database and is returned in the form of an ADO Recordset.
As mentioned earlier, the recordset generated by the English Query-generated SQL select statement just shown contains the correct records that need to be displayed, but not enough content. For example, at a minimum we will want to display the title of the book. All that is returned by the preceding query is the PKId (the numeric identifier for the book), the Keyword that was used to identify this book (in this case, France), and the Unit Price of the Book. For this reason, we need to return to the database one more time to identify at least the title for each book that was returned in the first recordset.
The GetItems method in the BLL can return a recordset with the details we are interested in if the items are supplied in a comma-delimited list of numeric identifiers. So, to produce the recordset we are interested in, we need to convert our first recordset into a comma-delimited list of the numeric identifiers from the PKId column. Once all records in the recordset are represented in the comma-delimited list, the list is passed to the GetItems method and a full recordset is returned.
There are many other data transformation and globalization issues to consider, including date and time conversions, currency translations, and localization of the interface. The discussion of how to globalize a system involves the whole system. For successful data transfer, we must ensure that the content passed from one component is decoded properly in the next component.
{kind=link}
{kind=link}
{kind=link}
{kind=link}