Margaret Li and Frank Pellow
Microsoft Corporation
March 1999
Summary: This article discusses facets of Microsoft SQL Server 7.0 textual searches such as: how SQL queries can be used on file systems lacking tables; how to use SQL extensions to make full-text queries; and how to work with a combination of file and database information. This article also discusses how BackOffice products (including: SQL Server distributed queries, Window NT Server's built-in Web Server, Internet Information Server (IIS), and Index Server 2.0) support textual searches in SQL Server 7.0. (25 printed pages)
Textural Search Features Overview
File Content Searches
Microsoft Internet Information Services (IIS) and Indexing Service
SQL Server Distributed Queries
SQL Extensions for Indexing Service Full-Text Queries
SQL Extensions for Site Server Full-Text Queries
Uses for Textual Search Features
Microsoft® SQL Server™ version 7.0 introduces facilities that support textual queries on data in SQL Server as well as on data in the file system. This article describes searches on data in the file system. Several products and features have been brought together to support this capability, including SQL Server distributed queries, Windows NT® Server built-in Web server, Microsoft Internet Information Services (IIS) version 4.0, and Microsoft Index Server version 2.0. This article is for those who are familiar with SQL Server but not necessarily familiar with its textual search features and products.
This article introduces the types of textual searches supported by SQL Server and illustrates the roles performed by both the IIS and Indexing Service technologies. It also introduces SQL Server distributed queries and describes their use in the processing of textual searches. It then addresses the question of how SQL queries can be written against the file system when there are no tables in the file system. Finally, the SQL extensions to support full-text queries are described, and several examples, including examples that combine file data with database data, are provided.
This article provides an overview of how to incorporate file data into SQL queries and of how the various components of SQL Server and other software interact to provide support for such queries.
A large portion of digitally stored information is in the form of unstructured data, primarily text, which is stored in the file system. This data is often related to data within the database, and there are requirements to support searches that include both sources. However, it is often inappropriate to import this data into the file system. SQL Server 7.0 distributed queries, coupled with extensions to the SQL language, make it possible to write such queries without the data. This capability is called file content search.
There are two major types of textual searches:
This search technology first applies filters to documents to extract properties such as author, subject, type, word count, printed page count, and time last written, and then issues searches against those properties.
This search technology first creates indexes of all non noise words in the documents, and then uses these indexes to support linguistic searches and proximity searches.
File content search supports both these types of textual searches and couples them with the ability to incorporate such searches into a query that includes relational operations against database data. For example, the following search selects the names, sizes, and authors of all Microsoft Word files on drive D that contain the phrase "SQL Server" in close proximity to the word "text." It then joins this result with the writers table to obtain the author's citizenship.
SELECT Q.FileName, Q.Size, Q.DocAuthor, W.Citizenship
FROM OpenQuery(MyLinkedServer,
'SELECT FileName, Size, DocAuthor
FROM SCOPE('' "D:\" '')
WHERE CONTAINS(''"SQL Server"
NEAR() text'')
AND FileName LIKE ''%.doc%'' '
) AS Q,
writers AS W
WHERE Q.DocAuthor = W.writer_name
File content search relies on the Microsoft OLE DB Provider for Indexing Service. It also relies on Indexing Service for support of underlying filters and full-text indexes.
Notice that the OLE DB Provider gives Index Server 2.0 the ability to support SQL queries against data in the file system independent of SQL Server. The core extensions to the SQL language that support such queries are the same in Indexing Service and SQL Server.
This document has the following purposes:
Only a small percentage of the facilities available in the supporting products are introduced in this document, and even when a facility is discussed, many of its options are not discussed. For more information, see the SQL Server documentation and the Indexing Service topic in the Windows NT Server documentation.
Microsoft Internet Information Services (IIS) 4.0 and Index Server 2.0 (both part of the Microsoft Windows NT 4.0 Option Pack) combine to provide property filtering and searching as well as full-text indexing and searching of file data. Windows NT 4.01 Service Pack 4 must be installed for proper interaction between Indexing Service and SQL Server.
All of these capabilities are available completely independent of SQL Server. In particular, there are at least two ways to search that do not use SQL Server. One of these employs an Indexing Service specific query language; the other supports SQL-based queries within ActiveX® Data Objects (ADO). Neither alternative will be discussed in this document except to say that the SQL language used in ADO queries is consistent with the SQL extensions outlined here. This article will discuss property filtering and full-text indexing.
Indexing Service provides filters for several file formats, including Microsoft Word, Microsoft PowerPoint®, Microsoft Excel, and HTML. Filters are also available for plain-text documents. Filters can be written by customers and third-party vendors for other formats such as Adobe Acrobat. Filters provide support for non-plain-text documents and capture property values both from the file content and about the files. Assuming that every file is a document, examples of properties include each document's title, the number of pages with notes in each PowerPoint presentation graphics program document, the number of paragraphs in each document, the last date and time each file was accessed, and the physical path to each file. For more information, see the Indexing Service documentation.
Full-text indexes are created by scanning file content. The process consists of tracking which significant words are used and where they are located. For example, a full-text index might indicate that the word "Canada" is found at word number 227, word number 473, and word number 1,017 in a given file. This index structure supports an efficient search for all items containing indexed words, as well as advanced search operations such as phrase searches and proximity searches. An example of a phrase search is looking for "white elephant," where "white" is immediately followed by "elephant." An example of a proximity search is looking for "big," where "big" occurs near "house."
To prevent the full-text index from becoming bloated, noise-words (words that are too common to expedite the search, such as "a," "and," "the," and "therefore") are ignored. Noise-word lists for many languages are available in the directory \Mssql\Ftdata\Sqlserver\Config. And the set of supported languages is growing. The choice of a particular noise-word list is based on the language of the material that is file-format dependent during the filtering process. Some files set the language per section or paragraph; some specify it for the entire document. These noise-word lists should be sufficient for most operations, but they can be modified. Administrators can use a regular text editor to modify the contents of a list. For example, a computer company can add the word "computer" to its noise-word list.
Indexing Service stores indexes and property values in a text search catalog. By default, a text search catalog named Web is created when Indexing Service is installed. It is possible to specify more than one text search catalog, but this article confines itself to the use of Web and does not discuss the process used to create additional text search catalogs.
A given text search catalog references one or more IIS virtual directories. A virtual directory references one or more physical directories and, optionally, other virtual directories. Once a real file is linked to the text search catalog by means of a virtual directory, Indexing Service is notified of any new files that need to be indexed and begins filtering and indexing the properties and content associated with those files. Indexing Service is also notified of any subsequent changes to the files and will refilter and reindex any updated files.
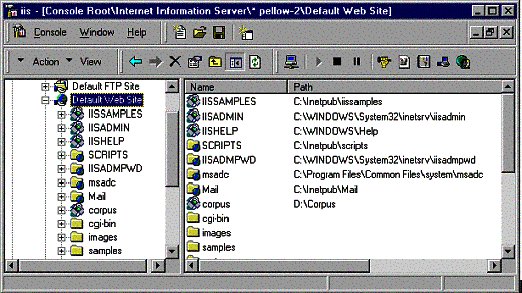
The following screen fragment (figure 1) shows a directory for the default Web site on the computer Pellow-2. Notice that /Corpus is listed in both panes. /Corpus is the alias of a virtual directory that, in turn, points to the real directory, D:\Corpus. All the files in D:\Corpus have their properties and full-text indexes maintained in the Web text search catalog.
Figure 1. Directory for the default Web site on the computer Pellow-2
This second screen fragment (figure 2) demonstrates how the Virtual Directory Wizard can be invoked to insert new virtual directories into the tree.
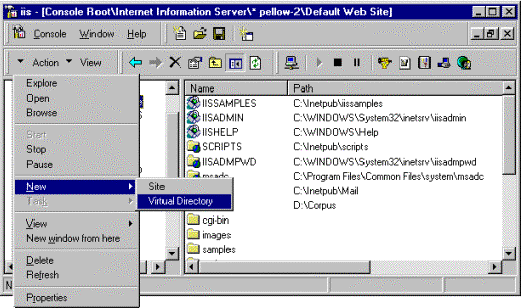
Figure 2. Using Virtual Directory Wizard to insert virtual directories in the tree
This third screen fragment (figure 3) demonstrates the result of using the Virtual Directory Wizard to add the /SQL_standards virtual directory, which contains two virtual directories and one real directory.
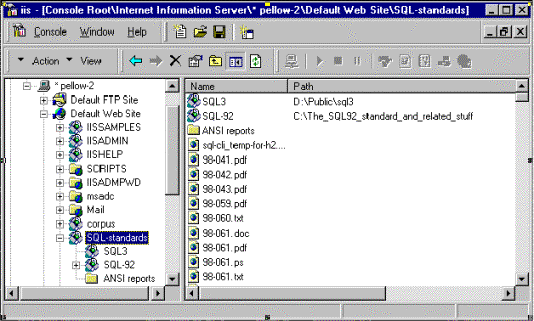
Figure 3. Using the Virtual Directory Wizard to add the /SQL_standards virtual directory
SQL Server 7.0 supports access to data in multiple, heterogeneous data sources, which can be on either the same or different computers. The data can be stored in various relational and nonrelational data sources for which there is either an OLE DB provider or ODBC driver. OLE DB provider exposes its data in tabular objects called rowsets. SQL Server 7.0 allows a rowset from an OLE DB provider to be referenced in the FROM clause of an SQL query just as if it was a SQL Server table.
In the examples discussed in this document, OLE DB provider is supplied by Indexing Service.
The sp_addlinkedserver stored procedure may be used to register data sources that will be referenced in distributed queries. In order to register OLE DB Provider for Indexing Service for the Web text search catalog on the same machine that SQL Server is running on, execute this statement:
EXECUTE sp_AddLinkedServer FileSystem,
'Indexing Service',
'MSIDXS',
'Web'
Here are the definitions of the syntax terminology:
The linked_server_name assigned to this particular linked server.
The product_name of the data source.
The provider_name (PROGID) of OLE DB Provider for Indexing Service.
The name of the text search catalog that will be used for this linked server.
The OLE DB provider can now be referenced using the FileSystem linked_server_name in the new OPENQUERY() result-set-valued function. For example:
SELECT *
FROM OpenQuery(FileSystem,
'SELECT Directory, FileName, DocAuthor, Size, Create
FROM SCOPE()
WHERE CONTAINS( Contents, ''Distributed'' ) ' )
Notice that there are two SELECT statements. The inner SELECT statement (within the OPENQUERY() function) returns a result set as a table that can then be used like any other table in the FROM clause. In this case, the outer SELECT statement is a simple SELECT *, which passes on all the rows from the inner SELECT statement. Also notice that because the inner SELECT statement is specified as a constant parameter value within single quotes, all single quote characters within the inner SELECT statement must be doubled. That is why ''Distributed'' appears as it does. Two adjacent single quote marks (' ') are not the same as one double quote mark (").
In general, SQL Server distributed queries support both read and update access to the data source. In the case of Indexing Service, only read access is appropriate. Generally, distribution is supported to remote computers; however, the SQL Server file content search feature has been tested only with all components and all data residing in the same computer.
Notice that OPENQUERY() does not work when running with a compatibility mode earlier than SQL Server 7.0. The compatibility mode can be set using the sp_dbcmptlevel stored procedure.
There are special security considerations with OLE DB Provider for Indexing Service on the Windows NT operating system. SQL Server supplies a username and password on the current SQL Server login and on the login mapping set up in SQL Server of the form (current login, linked server) -> (remote login, remote password). However, OLE DB Provider for Indexing Service ignores the username and password and instead uses the Windows NT security context of the client (as if the client asked for a Windows NT Authentication mode connection). This means that OLE DB Provider for Indexing Service uses the Windows NT account under which SQL Server is running. Since this account is likely to be powerful, it can expose information about files to which the original SQL Server login has no privileges.
This concern has been addressed by giving SQL Server administrators full control over who has access to OLE DB Provider for Indexing Service through SQL Server. The administrator can control the login mappings so that no one other than those who have explicit login mappings can gain access to the server (for example, an Indexing Service linked server). The administrator can also disable ad hoc access against a given provider so that no one can access Indexing Service through the ad hoc route without using a linked server.
For example, if SQL Server is running under the Windows NT account sqlaccount, consider a linked server called mytextfiles that has been configured to point to a particular Indexing Service text search catalog. On Windows NT 4.0, when a SQL Server user executes a distributed query against mytextfiles, this query is executed under the privileges of the Windows NT account under which SQL Server is running (sqlaccount). Given this, the SQL Server security administrator must decide which SQL Server logins should have access to mytextfiles.
This can be done by performing the following steps:
Remove login mappings for all logins (by specifying NULL value for the
@locallogin parameter)
exec sp_droplinkedsrvlogin 'MyTextFiles', NULL
-- Add a self mapping for local login to itself
exec sp_addlinkedsrvlogin 'MyTextFiles, true, 'local_login'
At least one defined table must be specified in every SQL query. A defined table is a table where the number and types of columns is either known in advance or specified as part of the query. A relational database usually contains a number of defined tables, and metadata about the columns of these tables is stored in a schema.
The collection of files in a file system does not generally have a predefined structure. The closest thing to columns are the properties of a file, but there is no deterministic set of properties for files. The closest thing to a row is a file, but files are usually not grouped in a homogeneous collection akin to rows in a table. Thus, in this case, the table concept is unclear, SELECT * is meaningless, and both the rows and columns are unbounded. Another way of looking at this is that a file system effectively has a universal schema consisting of every possible file property, both known and unknown.
Indexing Service solves this problem by providing the SCOPE function as a means of defining the set of rows that makes up a virtual table and by providing file properties that substitute for columns.
The SCOPE function is specified in the FROM clause of the Indexing Service query. It specifies the set of files that make up a virtual table.
The syntax of the SCOPE function, simplified for this document, is as follows in figure 4:
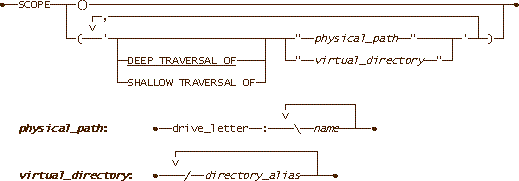
Figure 4. The SCOPE function syntax
Here follows the definitions of the syntax terminology:
The virtual table consists of all the files that have been registered in the text search catalog and data source for the linked server specified in the OPENQUERY() function.
The virtual table consists of all the files in the directory at the specified path or virtual directory as well as all the files in all the subdirectories (to any level) that are considered to be part of the virtual table. DEEP is the default.
The virtual table consists only of the files in the top-level directory at the specified path or virtual directory that are considered to be part of the virtual table.
A path to a real directory. If a real directory is specified, the filtering and indexing is done as part of the query processing, which can be time-consuming.
The alias (or chain of aliases) assigned to a virtual directory that has been registered in the text search catalog and data source for the linked server specified in the OPENQUERY() function. In this case, the filtering and indexing will probably already have been done and, thus, the query will be much faster than when a physical path is specified.
Indexing Service filters and maintains an excess of 50 file properties. All these can be specified in text file search queries. From the perspective of writing a SELECT statement, there are three types of file properties:
Table 1 below outlines some of these file properties:
Table 1. File Properties filtered and maintained by Indexing Service
| Property name | SQL data type | Description | Use in ORDER BY clause | Use in select _list |
| Access | datetime | Most recent date and time that the file was accessed. | Yes | Yes |
| Characterization | nvarchar or ntext | Abstract of the contents of the file. In Index Server 2.0, this is usually the first paragraph or first section of a document. In future releases, it is planned to be a real summary. | – | Yes |
| Contents | nvarchar or ntext | Main contents of the file. | – | – |
| Create | datetime | Date and time that the file was created. | Yes | Yes |
| Directory | nvarchar | Physical path to the file, not including the file name. | Yes | Yes |
| DocAuthor | nvarchar | Document author. | Yes | Yes |
| DocComments | nvarchar | Comments about the document. | Yes | Yes |
| DocLastAuthor | nvarchar | Most recent user that edited the document. | Yes | Yes |
| DocLastPrinted | datetime | Date and time that the document was last printed. | Yes | – |
| DocPageCount | integer | Number of pages in the document. | Yes | – |
| DocPartTitles | array of varchar | Names of the document parts: in Microsoft PowerPoint (slide titles). in Microsoft Excel (spreadsheets). in Microsoft Word (documents). |
– | – |
| DocSubject | nvarchar | Subject of the document. | Yes | Yes |
| DocTitle | nvarchar | Title of the document. | Yes | Yes |
| DocWordCount | integer | Number of words in the document. | Yes | – |
| FileIndex | decimal (19,0) | Unique identifier of the file. | Yes | Yes |
| FileName | nvarchar | Name of the file. | Yes | Yes |
| HitCount | integer | Number of words matching the query. | Yes | Yes |
| Path | nvarchar | Full physical path to the file, including the file name. | Yes | Yes |
| Rank | integer | Value from 0 through 1,000, indicating how well this row matches the selection criteria. | Yes | Yes |
| Size | decimal (19,0) | Size of the file (in bytes). | Yes | Yes |
| Write | datetime | Most recent date and time that the file was written. | Yes | Yes |
Customers and third-party vendors can write filters to add to this set of file properties. They can also add properties, for example, by adding tags to an HTML document. In addition, to permit the query and retrieval of such user-defined file properties, the SQL extensions to Indexing Service include support for a SET statement that allows the specification of new file property names and their associated types.
It is possible to specify a query with the equivalent of a table in the file system, resulting in the select list and the FROM clause. For other parts of a SELECT statement, the properties can be used in place of columns in the WHERE and ORDER BY clauses. However, the GROUP BY and HAVING clauses are not supported by OLE DB Provider for Indexing Service. The following examples illustrate the use of all supported clauses.
This query selects the full physical path and the file creation timestamp of all files in the /SQL-standards virtual directory and all its subdirectories, where the document contains the phrase "overloaded function."
SELECT *
FROM OpenQuery(FileSystem,
'SELECT Path, Create
FROM SCOPE('' "/SQL-standards" '')
WHERE CONTAINS(Contents, '' "overloaded function" '')
'
)
This query is similar to the previous query, except that only files directly in the /SQL-standards virtual directory are considered.
SELECT *
FROM OpenQuery(FileSystem,
'SELECT Path, Create
FROM SCOPE('' SHALLOW TRAVERSAL OF "/SQL-standards" '')
WHERE CONTAINS(Contents, '' "overloaded function" '')
'
)
This query is also similar, except that only files directly in the /SQL3 virtual subdirectory are considered.
SELECT *
FROM OpenQuery(FileSystem,
'SELECT Path, Create
FROM SCOPE('' "/SQL-standards/SQL3" '')
WHERE CONTAINS(Contents, '' "overloaded function" '')
'
)
This query selects author, title, subject, and file name of documents in all files that are either in the /Corpus virtual directory and its subdirectories or in the \Temp directory on drive C, where the document is at least 5,000 words, the author is either Wendy Vasse or Anas Abbar, and the rows representing those documents with the most pages are ordered highest.
SELECT *
FROM OpenQuery(FileSystem,
'SELECT DocAuthor, DocTitle, DocSubject, FileName
FROM SCOPE('' "/corpus" '',
'' "C:\temp" '' )
WHERE DocWordCount >= 5000 AND
( DocAuthor = ''Wendy Vasse'' OR
DocAuthor = ''Anas Abbar'' )
ORDER BY DocPageCount DESC
'
)
This diagram below (figure 5) illustrates the part that each component plays in the processing of a typical query:
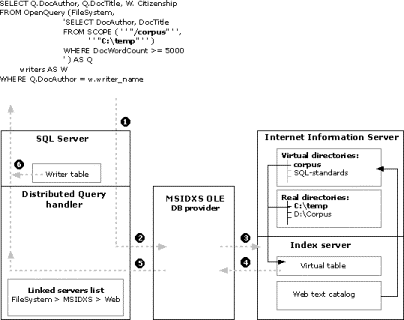
Figure 5. Component roles in typical query processing
These items relate to the numbered items depicted in figure 5:
A point worth repeating is that the SQL extensions for Indexing Service are consistent with the SQL language supported for full-text search against relational database data. Furthermore, SQL support for full-text searching follows the SQL-3 functional methodology for full-text syntax extensions.
The primary SQL extension consists of the CONTAINS and FREETEXT predicates. These predicates are used to find column values that match special full-text query criteria.
To be consistent with similar features in other products and to make these predicates more extensible, functional notation is used. The high-level syntax is as follows in figure 6:
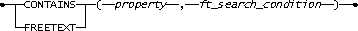
Figure 6. The high-level syntax
The flexibility of the functional style of these two predicates allows easy, upward-compatible future extensions for a third parameter to designate the language used for the query.
The CONTAINS predicate determines whether the content of files contains certain words and phrases.
The CONTAINS predicate syntax is as follows in figure 7:
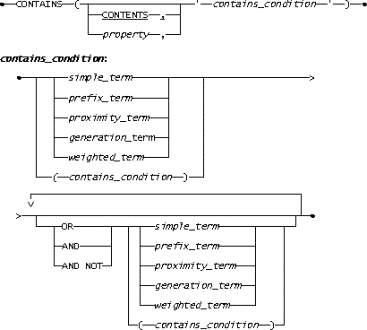
Figure 7. The CONTAINS predicate syntax
Here are the definitions of the syntax terminology:
The property to be searched, whose data type is character-based. If property is not specified in the CONTENTS clause, then property is assumed. The value of the CONTENTS clause is the contents of the file after conversion to plain text (if necessary) by a filter. It is good practice to explicitly code the CONTENTS clause, rather than to accept it as a default.
The Boolean operators used to join, or combine, terms.
The term used to match the exact word or phrase being searched for.
The simple_term syntax is as follows in figure 8, where word refers to one or more characters without spaces or punctuation, and phrase refers to multiple words with spaces in between. Asian languages can have phrases made up of multiple words without any spaces in between.

Figure 8. The simple_term syntax
In keeping with the standard for full-text products, the search function is always case-insensitive.
Here are some examples of simple terms used in the context of the CONTAINS predicate in a WHERE clause.
WHERE CONTAINS( Contents, 'hockey' )
WHERE CONTAINS( Contents, ' "ice hockey" ')
For example, there is one file with a value of "This is a dissertation on the use of ice-cream sandwiches as hockey pucks" and another file with the value "Dissertation on new ways of splitting the atom." Since "this," "is," "a," and so on are noise words, they are not stored in the full-text index. Therefore, a query with this CONTAINS predicate:
CONTAINS( Contents, ' "this is a dissertation" ' )
is the same as this query:
CONTAINS( Contents, 'dissertation' )
Both rows will be returned as hits because in the first query, the noise words are removed before processing the query.
As with other SQL search conditions, more complex conditions can be specified by linking individual operands with Boolean operators. In this case, the operands are any of the types of terms being discussed. Except for the restriction that the OR NOT combination is not supported and that NOT cannot be specified before the first term, the rules are exactly the same as those used to combine individual predicates to form search conditions. For example, parentheses may be used to change the default priority order in which the operators are applied.
Here are some examples of simple terms being combined within a CONTAINS predicate in a WHERE clause.
WHERE CONTAINS( Contents, 'hockey OR curling' )
WHERE CONTAINS( Contents, 'hockey AND NOT field')
WHERE CONTAINS( Contents,
' ("ice hockey" OR curling) AND NOT Canada '
)
prefix_term is used to match words or phrases that begin with the specified text.
The prefix_term syntax is as follows in figure 9:
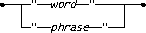
Figure 9. The prefix_term syntax
A prefix term consists of a simple term appended with an asterisk (*) to activate prefix matching on a word or phrase. All text that starts with the material before the * is matched. The wildcard symbol (*) in this case is similar to the % symbol in the LIKE predicate in that it matches zero, one, or more characters of the root words in a word or phrase. In a phrase, each word within the phrase is considered to be a prefix; for example, the term "local bus*" matches "locality busy," "local bush," and "locale bust."
Here are some examples of prefix terms used in the context of the CONTAINS predicate in a WHERE clause:
WHERE CONTAINS( Contents, ' "atom*" ' )
This matches values that contain the word "atom," "atomic," "atomism," "atomy," and so on.
WHERE CONTAINS( Contents, ' "wine*" OR "vine*" ')
This matches values that contain the word "wine," "vine," or words such as "winery," "wines," "vineyard," or "vinegar."
proximity_term is used when the words or phrases being searched for must be close to one another.
The proximity_term syntax is as follows in figure 10:

Figure 10. The proximity_term syntax
A proximity term is similar to an AND operator in that more than one word or phrase must exist in the value being searched. It differs from AND because the relevance of the match increases as the words appear closer together.
The syntax is designed to be extensible for possible future support for specification of units of proximity such as words, sentences, paragraphs, chapters, and so on.
NEAR, NEAR(), and ~ share the same meaning: the first word or phrase is close to the second word or phrase. "Close" is a purposefully vague term that can mean "within 50 words," but the algorithm is complicated. While words within the same sentence are one word distance apart, larger distances are assigned between units such as sentences, paragraphs, and chapters. Even if words or phrases are very far apart, the query is still considered to be satisfied; the row just has a low (zero) rank value. However, if the contains condition consists of proximity terms only, then SQL Server will not return rows with a rank value of zero. This can be avoided by specifying RANK > 0 as one of the predicates in the WHERE clause.
It is possible to chain-code the proximity matching. For example," a ~ b ~ c " means that a should be near b, which should be near c. Because of the fuzzy nature of full-text searches, it is often desirable to see the rank values. This can be done by including the RANK property in the select list of the query. Here are some examples of proximity terms used in the context of the CONTAINS predicate in a WHERE clause:
WHERE CONTAINS( Contents, ' hockey ~ player ' )
This matches values that contain the word "hockey" in close proximity to the word "player."
WHERE CONTAINS( Contents, ' hockey ~ "play*" ')
This matches values that contain the word "hockey" in close proximity to a word that starts with "play."
WHERE CONTAINS( Contents, ' "great*" ~ "Mike Nash" ') AND Rank > 0
This matches values that contain words starting with "great" in close proximity to the phrase "Mike Nash." Values that meet the criteria but have a ranking of 0 do not have rows returned.
generation_term is used when the words being searched for need to be expanded to include the variants of the original word.
The generation_term syntax is as followsin figure 11:

Figure 11. The generation_term syntax
he INFLECTIONAL predicate means that plural and singular forms of nouns and the various tenses of verbs will be matched. A single term will not match both exclusive noun and exclusive verb forms. The syntax is designed to be extensible enough to handle other linguistically generated forms, such as derivational, soundex, and thesaurus.
Here is an example of a generation term used in the context of the CONTAINS predicate in a WHERE clause:
WHERE CONTAINS(' FORMSOF (INFLECTIONAL, skate) ' )
This matches values that contain words such as "skate," "skates," "skated," and "skating."
weighted_term is used for queries that match a list of words and phrases, each optionally given its own weighting. Matching values must match only one element in the list.
The weighted_term syntax is as follows in figure 12, where n.nnn represents a decimal constant from zero through one:
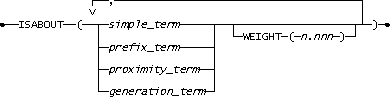
Figure 12. The weighted_term syntax
A row is returned if there is a match on any one of the ISABOUT elements.
Each component in the vector can be optionally weighted. The assigned weight forces a different measurement of the rank value that is assigned to each row that matches the query.
Here are some examples of weighted terms used in the context of the CONTAINS predicate in a WHERE clause:
WHERE CONTAINS( Contents, ' ISABOUT(hockey, puck, goalie) ' )
This matches article values that contain any of the words "hockey," "puck," or "goalie." The better matches will contain more than one of the words.
WHERE CONTAINS( Contents, 'ISABOUT("Canadian ice hockey" WEIGHT(1.0),
"ice hockey" WEIGHT(.5),
hockey WEIGHT(.2) )
' )
This matches article values that may have information about Canadian ice hockey, with higher rank values assigned to articles that have more words from the phrase.
The FREETEXT predicate determines whether or not a value reflects the meaning, rather than the exact words, specified in the predicate.
The FREETEXT predicate syntax is as follows in figure 13:

Figure 13. The FREETEXT predicate syntax
This is a simple form of natural language query, where the index engine internally breaks the freetext string into a number of search terms, generates the stemmed form of the words, assigns heuristic weighting to each term, then finds the matches.
Here is an example of a FREETEXT predicate used in a WHERE clause.
WHERE FREETEXT( Contents, ' Who have been the most valuable ice hockey players from
1975 through 1982? ' )
The search_condition supported by Indexing Service is slightly different from the search_condition supported by SQL Server. Because these queries are distributed to the OLE DB provider for processing, the queries must follow the rules of the provider. The main difference is that OLE DB Provider for Indexing Service does not support the QUANTIFIED COMPARISON, BETWEEN, EXISTS, IN, or NULL predicates, but it does support two other predicates: MATCHES and ARRAY COMPARISON. These predicates are not yet directly supported by SQL Server.
Following is an introduction to the search_condition syntax as supported by Indexing Service. Some aspects have been omitted, and the syntax of other aspects is incomplete.
The search_condition syntax is as follows in figure 14:
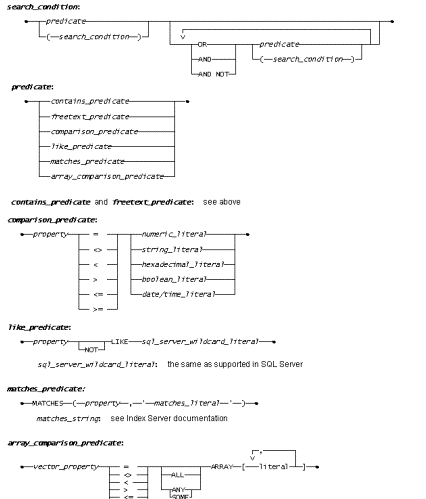
Figure 14. The search_condition syntax
This section briefly introduces the MATCHES and ARRAY COMPARISON predicates. The MATCHES predicate provides more extensive pattern matching than the LIKE predicate. This added functionality bears the burden of a more complicated set of rules. The complete syntax and rules are not described here; rather, here are some examples to illustrate the use of this predicate.
Here is a grouped match against more than one pattern, where it is known that the author's first name is Peggy, but the spelling of her second name is uncertain:
WHERE MATCHES( DocAuthor, 'Peggy |(MacK|,McK|,MacC|,McC|)arson' )
Here, it is uncertain if Pellow is spelled with one "l" or two:
WHERE MATCHES( DocAuthor, '* Pel|{1,2|}ow' )
The ARRAY COMPARISON predicate is for use with the Indexing Service Vector properties. Some of the property values filtered by Indexing Service are multivalued. The data type of such values is a variable size array. SQL Server does not yet support such data types, but SQL-3 does. The SQL extension supported by OLE DB Provider for Indexing Service is consistent with that in SQL-3.
For example, the virtual table contains a number of PowerPoint presentations, and you want to know the path to the presentations that contain any slide called "CONTAINS predicate," "FREETEXT predicate," or "Query Transformation."
SELECT *
FROM OpenQuery(FileSystem,
'SELECT Path
FROM SCOPE('' "/slide_presentations" '')
WHERE DocPartTitles = SOME ARRAY[ ''CONTAINS predicate'',
''FREETEXT predicate'',
''Query Transformation'' ]
')
This section provides several examples that answer queries by combining database data and file data.
The following query returns the title and publication year of qualifying books that are represented by files in the virtual directory that has the /Pubs alias. In order to qualify, a book must cost less than $20.00, and text in the Characterization property must indicate that the book is about ice hockey. It is known that the year portion of the Create property is always the publication year of the book. The customer has defined the BookCost property (of type money), which filters out the cost of each book:
SELECT Q.DocTitle, DATEPART(year, Q.Create)
FROM OpenQuery(FileSystem,
'SELECT DocTitle, Create
FROM SCOPE('' "/pubs" '')
WHERE BookCost <= 20.00
AND CONTAINS( Characterization, '' "ice hockey" '' )
') AS Q
Notice that the table alias value of Q has been assigned to the table returned by the OPENQUERY() function. This alias is then used to qualify the items in the outer select list. Previous examples specified the SELECT * statement and passed on all values returned by the inner SELECT statement. Here, the SQL Server DATEPART() function is used to pass on only the year portion of the create datetime value.
The following query returns the same information as the previous query. The difference is that the price of the book is obtained from the document_cost column in the BookCost table in the database, rather than from a property in the file system. The primary key of the BookCost table is the combination of the document_author and document_title columns:
SELECT Q.DocTitle, DATEPART(year, Q.Create)
FROM OpenQuery(FileSystem,
'SELECT DocTitle, Create, DocAuthor, DocTitle
FROM SCOPE('' "/pubs" '')
AND CONTAINS( Characterization, '' "ice hockey" '' )
') AS Q,
BookCost as B
WHERE Q.DocAuthor = B.document_author
AND Q.DocTitle = B.document_title
AND B.document_cost <= 20.00
The table returned by the OPENQUERY() function is joined to the real BookCost table in the database, then rows with a suitable cost are filtered for inclusion in the outer SELECT statement.
This query also joins data from the file system and the database, and this time, data from both appears in the outer SELECT list. Furthermore, the Rank property, which indicates how well the selected rows met the selection criteria, appears in the select list and is used to ensure that higher-ranking rows appear before lower-ranking rows in the outer SELECT statement. In this example, the wording on the plaques in the Hockey Hall of Fame is recorded on files. There is a file for each plaque, and the plaque number can be obtained through the DocSubject property. The HockeyHall table contains PlaqueNo, PlayerName, StartYear, and LastYear columns, with the primary key in the PlaqueNo column. You want to return the PlayerName and PlaqueNo columns from the table and the Rank and DocComments properties from the file. Only players who might have played for Canadian or U.S. teams in the early 1900s are to be returned.
SELECT HH.PlayerName, HH.PlaqueNo, Q.Rank, Q.DocComments
FROM OpenQuery(FileSystem,
'SELECT DocSubject, DocComments, Rank
FROM SCOPE('' "/hall_of_fame" '')
WHERE CONTAINS( Contents, '' Canada OR "United States" '' )
') AS Q,
HockeyHall as HH
WHERE Q.DocSubject = HH.PlaqueNo
AND HH.StartYear < 1915 AND HH.EndYear < 1899
ORDER BY Q.Rank DESC
In this example, an international construction company stores a large number of onsite progress reports in a Microsoft Word document in a central site. All the documents have been registered within the /Site_report virtual directory. Each document can be identified by its unique FileIndex property. These documents are tracked in the database. The following tables in the database are of interest:
Projects: project_number char(8) primary key,
project_name nvarchar(40),
project_leader smallint, --employee number
budgeted money,
spent money,
...
Employees: employee_number smallint primary key,
employee_name nvarchar(40),
nationality nvarchar(20),
...
Reports: project_number char(8),
file_index decimal(19,0), --link to the file
...
primary key is project_number and file_index
A rush order has been issued for 5,000 saunas in a heavily forested area with no electricity. The salesperson vaguely recalls a similar, successful project about 10 years ago. He issues a query that returns the project number, the paths to the onsite reports, and the ranking value of the projects managed by someone from a Scandinavian country that came in under budget between 8 and 12 years ago.
The highest ranking is given if the report contains the phrase "wood burning" in close proximity to "sauna." Points are also given if the document contains the phrase "Northern Ontario" or the word "island."
The following is an example of what the query could look like:
SELECT P.project_number, Q.path, Q.Rank
FROM OpenQuery(FileSystem,
'SELECT FileIndex, Path, Rank, Write
FROM SCOPE('' "/site_reports" '')
WHERE CONTAINS( Contents,
'' ISABOUT( Sauna ~ "wood burning" WEIGHT (.9),
"Northern Ontario" WEIGHT (.4),
Ontario WEIGHT (.2),
island WEIGHT (.2) )
'' )
AND Rank > 5
') AS Q,
Projects AS P,
Employees AS E,
Reports AS R
WHERE Q.FileIndex = R.file_index
AND R.project_number = P.project_number
AND P.project_leader = E.employee_number
AND E.nationality IN ('FINNISH', 'DANISH', 'SWEDISH', 'NORWEGIAN')
AND P.spent < P.budgeted
AND YEAR(Q.Write) > 1986 AND YEAR(Q.Write) < 1992
Microsoft Site Server version 3.0 also ships an OLE DB provider, the primary purpose of which is to allow users to write ADO application programs to query Web data. The OLE DB Provider for Site Server has not yet been tested with the SQL Server 7.0 query processor for distributed queries, and there is no official support for interoperability with SQL Server 7.0. However, users who wish to experiment with this configuration will find the following information useful.
As with the OLE DB Provider for Indexing Service, the sp_addlinkedserver stored procedure is used to register OLE DB Provider for Site Server. For example, in order to register this provider for the WebTest text search catalog on the same machine that SQL Server is running on, the following statement will need to be executed:
EXECUTE sp_addlinkedserver WebData, 'Site Server', 'MSSEARCHSQL', 'WebTest'
The following are the definitions of the syntax terminology:
The linked server name assigned to this particular linked server.
The product name of the data source.
The provider name (PROGID) of OLE DB Provider for Site Server.
The name of the text search catalog that will be used for this linked server.
Notice that Site Server has additional syntax to support the union of results generated by a query across multiple catalogs.
The textual search features supported by Microsoft SQL Server 7.0 are basic but serve many useful full-text searching purposes. Even this basic level allows inclusion of data both inside and outside the database. The SQL Server 7.0 query processor for distributed queries enables advanced capabilities by joining full-text searching results in the database with results generated by queries in the file system against Index Server 2.0. An excellent foundation has been laid during the integration of Microsoft information retrieval technologies into SQL Server 7.0, technologies that have already shipped in several Microsoft products and that will serve as the basis for other Microsoft products that support textual search.
The component reuse strategy benefits the customer by providing seamless upgrade capability in the underlying index and search engine, and cross-product consistency.
---------------------------------------------
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.
Companies, names, and/or data used in screens and sample output are fictitious, unless noted otherwise.
© 1998 Microsoft Corporation. All rights reserved. Microsoft, ActiveX, the BackOffice logo, PowerPoint, and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. Other product and company names mentioned herein may be the trademarks of their respective owners.
Microsoft Part Number: 098-81378