Microsoft Corporation
June 1999
Summary: Developing Microsoft® Windows® CE–based applications for international markets need not require a large investment of resources. Using the tools provided by the Windows CE operating system at the right times in the development cycle makes the process of constructing localized software easy and inexpensive. Microsoft has over twenty years of experience producing software for international markets and has developed techniques for producing international versions of software at a small incremental cost. This article describes the techniques that Microsoft uses and the tools that the Windows CE operating system provides to produce international software. (19 printed pages)
Introduction
Internationalization vs. Localization
Language Families
Market-Specific Software Development
Comparing Windows CE with the Desktop Versions of Windows
Sample Internationalized and Localized Application
Summary
For More Information
Many people and corporations approach the international market for their software cautiously, thinking that developing software for markets other than their home market is expensive and difficult. However, if you are developing for Windows CE, you do not need to invest a lot of resources to get into international markets. You just need to use the Windows CE tools at the right times in the development cycle to make the process of constructing localized software easy and inexpensive. Windows CE provides the following tools:
Because Windows CE is a member of the Windows family of operating systems, it is possible to do significant amounts of development and testing on the desktop.
Microsoft has over twenty years of experience producing software for international markets and has developed techniques for producing international versions of software at a small incremental cost. This article describes the techniques that Microsoft uses and the tools that the Windows CE operating system provides to produce international software.
Microsoft distinguishes between three different phases in the process of producing international software: internationalization (or international enabling), localization, and market-specific development. Internationalization refers to the process of making the code base for an application ready to be translated, whereas localization is the actual translation of the software. Market-specific development is discussed later in this article.
Because it is often possible to sell an application that has simply been internationalized, even if the user interface (UI) for that application has not been translated, internationalization is the first and most important step in producing an application for international markets. If your software can conform to the cultural conventions of the market, called the locale, then you may be able to sell the software in that market without any further modification. Locale includes correct representation of the language, dates, times, currencies, and numbers, plus the correct sorting of strings.
An important point about the international marketplace is that you do not have to exceed your limits the first time. Frequently, you can move slowly into a market, acquiring facility as you go and developing the expertise necessary to support more languages and markets over time.
Writing language-dependent code that includes many #ifdef directives is a recipe for expensive and unstable localized versions. The key to successful internationalization is writing code that works in any language.
Executable files and DLLs for the Microsoft Win32® API—generically referred to as P32 executables—contain parts in addition to executable machine code. One part is the resource segment, which contains arbitrary noncode items used by the program. These items can be anything, although Win32 contains special APIs for loading many common resources, such as strings, dialog box templates, icons, and bitmaps. For more information about the P32 executable format, see Jeffrey Richter's book Advanced Windows or the Microsoft Developer Network Library (MSDN).
More important for the purposes of internationalization is that resources stored in one P32 executable can be accessed at run-time by any process, which means process A can display a dialog box that is stored in DLL B. In fact, the common dialog boxes work this way. The dialog box templates are stored in comdlg32.dll, along with the code for driving them. For example, when your program calls the GetOpenFileName API to display the Open File dialog box, resources in comdlg32.dll are loaded to display the dialog box. This process of choosing the file from which resources are loaded based on the language and making sure that strings are constructed in a language-sensitive fashion makes it possible to build all localized versions of a product from a single code base.
By writing code that works in any language, Microsoft shares the test resources between the U.S. core team and the localization teams, to the benefit of both. The obvious benefit to the localization teams is that bugs are fixed earlier in the process, not after the code is complete, when developers have frequently lost interest or left the project. The benefit to the core team is a cohesive set of real-world stress cases against which to test the software. Although many bugs that show up during localization are localization bugs, almost as many bugs are core code bugs that were masked because the testers did not come up with a test case that evoked the bugs. Paradoxically, building a single common code base for your U.S. and localized versions almost always improves all of your versions, including the U.S. version.
In contrast, separating language-specific code in different compiles almost always introduces bugs. A basic rule of development is that the amount of testing for a given module needs to increase faster than the number of distinct code paths through that module. If you have code with #ifdef directives in a module for a localized version, then you have introduced a new set of code paths through that code. You might be able to guarantee that the only function of the version with #ifdef directives was to set the language-specific values of parameters, strings, or window properties. But if you did that, it would be better to move all of those items into the resources. And if you have made other changes, then you need to run an entire test pass for that language, which means that you have lost the leverage of your English test pass.
Sometimes, avoiding locale-specific code is not possible. Perhaps a set of rules is language-dependent, and you cannot figure out how to represent these rules as data within your resources or within some other file. Alternatively, and more frequently, your code may depend on some external component, where the code within that external content varies from language to language, and you may have no way to force that external component to use a single binary. In that case, your best choice is to isolate that content in a separate code file, such as a DLL, and load it in a language-specific fashion. You do not receive all the advantages of a true single code base, but you will have gained as many as you can.
One of the subtleties of internationalization is that although language is one of the features of locale—and is the distinguishing feature of a localization pass—each language may be used in many locales, and it is critical not to confuse language with locale. A locale covers not only the words used in the UI, but also other, subtler things. Think of Standard French and Canadian French (Québecois). Although these two dialects of French are essentially identical as far as spelling is concerned, the two locales are different in terms of how dates are written, which currency is used, the format of telephone numbers, and how postal addresses are written. Moreover, since Canada is bilingual, a user with a French Canadian interface might want to adopt British Canadian representations of numbers or dates, which differ from those used in Quebec.
Windows CE provides a complete implementation of national language support (NLS, ISO 639). NLS is a set of APIs and tables for locale support. You do not need to know the currency symbol and format for a given locale; NLS handles date formats of varying lengths, currency formats, and numerical representation. You do not have to write a single line of extra code; using the correct NLS call takes care of everything for you.
After the internationalization process, you are ready to localize. The key to no-compile localization is using the operating-system-level support for resources provided by Windows CE. Just as with desktop applications for the Microsoft Windows NT® or Windows 95 or 98 operating system, applications and DLLs written and compiled for Windows CE are stored as P32 executables. A P32 executable has a fixed structure, which is described in Richter's Advanced Windows. The operating system has special operations for reading certain resources from a P32 executable and for treating them as dialog box templates, strings, icons, bitmaps, or other frequently used items.
For example, if you want to display a string from a P32 executable, you need to load that executable, and then you can access the string. You can load the executable using the LoadLibrary API, which returns a handle to the module. If hModule denotes the handle that LoadLibrary returned, you need only execute the following single line of code to load the string:
LoadString(hModule, MAKEINTRESOURCE(IDS_STRING), ...)
Notice that the call has no explicit language dependency. From looking at the code, you cannot tell if the string is in English, German, or Swahili. That information is entirely contained in the string table resource itself, which is not a part of the code. So if you replace the text in the string with text drawn from another language, then the string has been localized without changing any code.
This operation can be performed through any of several tools, the easiest of which is the Microsoft Visual C++® integrated development environment. To do this, open your executable in the Visual C++ development system, as a resource file on a computer running a version of Windows NT that is enabled for the language to which you are localizing your application. Then, you can edit your resources, changing languages and dimensions without affecting the code. Provided that you have preserved the resource identifiers, your application will still run as it used to, but you will have changed your user interface, achieving instant localization.
If you want to localize an application that runs on a processor other than the X86, this process still works. When you build your application, your resources are stored in an intermediate file with the extension .res. The contents of the .res file are processor-independent, so if you do the above operation before you link your executable, you can link an executable for any processor architecture supported by Windows CE without any change.
Similarly, you can use a string table to capture the content of any run-time constructed displayed string. The one subtlety here is that word order may change from language to language. For example, suppose the English UI of your application contained a message of the form "text text text %1 %2." That message would not work in Italian, where word order requires that "%1 and %2" be reversed, that is, "testo %2 testo %1 testo." For a localizer to change it, the string has to be properly stored in an .rc file. Windows CE provides a mechanism for handling such strings. The FormatMessage API uses format strings similar to those used in the C run-time function sprintf. FormatMessage allows parameters of the form %1, %2, and so forth, where %1 represents the value of the first parameter, %2 the value of the second, and so on. By changing the order of %1 and %2, the order in which the parameters appear in the formatted string is reversed.
Windows CE, like all members of the Windows family of operating systems, permits resources to be stored in the executable file that uses them, or in any other P32 executable or DLL on the system. This leads to a clever way to save a lot of time and money: resource-only DLLs. If you store your resources in your executable and localize that executable, and then need to release a quick bug fix, you need to release a complete new executable for each language. If, on the other hand, you store all of your resources in a resource-only DLL that contains no executable code, then you need only release the new binaries for your application, because the resources are already on the user's system. This greatly reduces the complexity of your re-release process.
The other advantage of this approach is that you can start producing your satellite DLLs for all languages you are going to support as soon as the product's UI freezes (visual freeze). Since visual freeze usually precedes code freeze by several weeks or months, this makes it possible to ship in many languages simultaneously. It also allows some direct testing of localized versions other than the pilot language versions, which lets you catch any bugs in the core code that would have been exposed by using a different set of pilot languages. A final advantage of this arrangement is that you can have more than one satellite DLL on a given system and can change the display language for your application simply by changing a registry setting.
Microsoft divides the world's markets into geographic areas for the purpose of localization. Languages within these areas share features with one another, and enabling an application for one of the languages in each group usually handles most of the issues raised by any of the other languages in the group. The following groups are identified:
There is nothing special about English as it is written and spoken in the United States. However, Microsoft is a U.S. company, and most of its developers are first-language speakers of U.S. English. So, they think in that language and develop for that language.
The Western European languages draw all their characters from the same set of Unicode code points that English uses. A standard keyboard can easily accommodate text entry in these languages. Words are separated by spaces, and the languages are read from left to right. Dialog box designs are similar to English, but they use different numeric formats and different currency and date conventions from the U.S., so some internationalization is necessary.
However, two languages in this group are difficult to localize. Finnish and Hungarian have word structures that make the construction of localized user interfaces particularly challenging. If you intend to localize into these languages, you need to be aware throughout the internationalization process and make sure that the UI has enough space to support the text.
Eastern European languages include languages that use Cyrillic—for example, Russian—Greek, Turkish, and other Slavic languages. These languages draw their characters from portions of the Unicode code point range other than those covered by the Western European alphabet, which means that software using them looks quite different from software for the Western European languages. However, other than looking different, these languages are similar to the Western European languages: words are separated by spaces, strings are read from left to right, and letters have both uppercase and lowercase. Standard keyboard layouts make sense. It is usually not difficult to support the Eastern European locales if you can support the Western European locales.
The character sets used in Japan, China, Taiwan, and Korea are much larger than those used in European languages. Each character set has several thousand characters. Chinese characters are ideographic, not phonetic, and each character roughly represents a single word. Japanese has three different alphabets, two systems of characters that represent syllables (syllabaries)—hiragana and katakana—and one ideographic alphabet, Kanji. Many Japanese words consist of a short string of Kanji, possibly with a few hiragana appended. Spaces are not used to separate words, and line breaks can occur between most characters. Japanese and Chinese are normally written left to right, but are sometimes written top to bottom. Korean is written mostly in a phonetic system called Hangeul. Individual characters represent the syllables that make up the language, and the words are separated by spaces.
Because of the size of the character sets in these languages, direct keyboard input is not possible. Instead, one of two shortcuts is used: either an intermediate application called an Input Method Editor (IME), or handwriting recognition that identifies characters that the user draws on a touch pad. On the desktop, the IME is the preferred approach. Users type individual characters to either spell or construct characters from their constituent parts. Then the IME intelligently guesses which characters might be intended and presents a list of possible alternatives, from which the user selects one. However, because the character sets are so different and the way that western letters map to characters varies from language to language, different languages require different IMEs. For more information, see Nadine Kano's book Developing International Software for Windows 95 and Windows NT.
For a Windows CE–based device that supports a touch pad, handwriting is a compelling interface medium for text input. Individual characters in a given language are drawn similarly. Stroke order and position is taught as part of handwriting, with a right way and a wrong way to draw a character. As a consequence, algorithms for inferring the identity of a character from the sequence of strokes that represents it are highly accurate.
Windows CE was designed to work with either an IME or handwriting recognition. The input method identifies the content of the user's input, and passes the resulting text to the application. The interface to the input method can vary, but that is not relevant to the application, which receives a set of character codes, and does not have to be concerned about how they were obtained.
The complex script languages are characterized by nonlinear cursor motion. Hebrew and Arabic, together with several languages written in either the Hebrew or Arabic character sets, are bi-directional. The default direction of text for these languages is right to left; however, embedded left-to-right text is written left to right. So, for example, if an Arabic article discussed "Windows CE," then this term would appear exactly as it is in English, written left to right, but surrounded by Arabic text written right to left.
This bi-directional text means that text selection and display is significantly more complicated than in unidirectional languages. In English, the RIGHT ARROW key moves the cursor forward to the right one letter at a time. In Hebrew or Arabic, the LEFT ARROW key moves the cursor forward to the left, usually one character at a time, but sometimes more than one character, or it may even move the cursor backwards to the right. This is because the "next" character can be far away when the text direction changes or it can be to the right, not the left, of its predecessor.
Two other significant complex script languages are Thai and the Indic languages (Hindi, Bengali, Kannada, and so forth). In these languages, cursor movement is left to right, but not steady. Pressing the arrow key may not move the cursor at all, or it may move the cursor by several characters. In the Indic languages, words are separated by spaces, but not in Thai, which also lacks punctuation.
Windows CE has complete support for languages in the Western European, Eastern European, and Far Eastern language families. On the desktop, Windows NT provides complete support for all of the languages listed, although it does not yet provide support for some complex script languages such as Mongolian. Windows CE plans to provide support for complex script languages in the future.
You do not want to limit yourself when you are writing software. You want to write software that can run everywhere, or at least you want to maximize the number of copies of software that you can sell for each dollar invested. The concept of a language family supports that idea. Every time you write software for a member of a given language family, the other members of that language family are free, apart from translation costs.
Let's say that you have a business case to sell a product in Germany. Germany is a big market, but writing code that works only in Germany is probably not a good idea. With the same effort that you use for the German market, you can also target all the other Western European countries, such as France, Italy, and Spain, plus a large part of North and South America, including Mexico and Brazil. In one product, you have covered many of the largest economies, and each new market costs only the amount required to localize the resources in the application. That amount is trivial compared to the development costs of even the smallest application.
Microsoft has adopted the idea of a pilot language for each language family. For each product that is to be localized, Microsoft picks one language from each family and makes the support of that language the responsibility of the core team. Localization into that language takes place concurrently with the development of the core U.S. English product. Then, after the UI has frozen, the software is localized into the other languages in each family. Because the pilot language already works, new bugs almost never occur in the core code for any of the nonpilot languages in each family.
Historically, German has been Microsoft's pilot language for the Western European family, Japanese has been the pilot language for the Far Eastern languages, and Hebrew has been the pilot language for the bi-directional languages. In each case, the pilot language is that of the largest single market in the language family.
The exception to the rule that international products should be compilation-free localizations of a product initially developed for a specific market occurs when you can extend the reach of a product by adding features to it. For example, suppose that you were developing a telephone. For the U.S. or Canadian markets, you might employ specific features such as phone number parsing based on a standard 3-3-4 representation. Once you have parsed the telephone number, you can tell a user the shortest way to dial that number from their current location. That feature will not work in the rest of the world, since phone number formats are more fluid outside of the U.S. and Canada. The use of a 3-3-4 representation is an example of a market-specific feature. On the other hand, for a phone that would ship in Europe, you need to support the Global System for Mobile Telecommunication (GSM), instead of the Time Division Multiple Access (TDMA) you need in the United States.
Market-specific development is usually more expensive than compilation-free localization, but it can have a significant impact on the acceptance of the product. Often, such features are traded off during the development cycle; if the product will thrive in its core market, then any international sales are an extra bonus. Occasionally, this approach is a bad idea; if a critical feature is missing in a given market, then you may damage your corporate image in that market. It is important to build your product so that such features can be cut or, perhaps, added post-ship.
On Windows CE, cutting or adding features is fairly straightforward. Because Windows CE supports Component Object Model (COM), you can define a COM interface for extensions and support all such extensions through this interface. That way, you can ship with the extensions, if they are finished, or ship the extensions as part of a later update. You can even publish the API for your COM interface, and encourage third-party developers to write add-ons of their own. That approach is frequently an excellent way to get both advanced features and free word-of-mouth advertising.
Three different classes of 32-bit Windows kernels are currently available in the consumer market:
Contrary to common belief, these kernels are quite different from one another internally. To a remarkable extent, however, Microsoft has managed to preserve the Win32 API among all of the kernels, so that a developer who is familiar with coding for one kernel can quickly pick up and understand the conventions used by the others. This section discusses the similarities and differences among the different kernels.
The biggest difference between Windows CE and the other kernels is that the Windows 9x and Windows NT kernels are monolithic: if you know which version of the operating system you are working on, then you know exactly what the kernel API is. The Windows CE kernels are not monolithic, because the APIs that a given device exposes depend on the parameters from which the kernel was initially compiled. These original equipment manufacturer (OEM) settings mean that the behavior of certain internationally significant functions depends on the device.
Modern computer systems use two predominant encodings for characters: American National Standards Institute (ANSI) or Unicode. Systems with significant legacy overhead use the older standard that is based on ANSI code pages of 255 characters each. An ANSI code page is a mapping between bytes or sequences of bytes and characters. For languages with relatively small alphabets, such as the European languages, Arabic, Hebrew, and most others, all of the characters appearing in the alphabet can be represented with eight bits. These code pages are single-byte character sets (SBCS).
For code pages representing languages with large character sets (Chinese, Japanese, and Korean), a complicated system of encoding using a combination of some single-byte characters and a large class of double-byte characters—each comprising a lead byte and a trailing byte—is used to cover the entire alphabet. These code pages are referred to as double-byte character sets (DBCS). Text operations, including cursor movement, require a lot of memory in standard DBCS ANSI code pages. In addition, not all languages have ANSI code pages.
Modern operating systems with fewer legacies to support use Unicode. There are two forms of Unicode: two-byte and four-byte. Currently, the two-byte form of Unicode covers all modern-day languages. Unicode text is slightly less dense than single-byte ANSI, but Unicode is so much easier to process that the advantages of speed overwhelm the minor costs of sparser representation. In addition, for those cases where density is overwhelmingly significant, denser representations of Unicode are available that avoid these problems.
Windows system APIs that involve characters can appear in two forms: an ANSI form and a Unicode form. For example, the native Win32 function for comparing two strings, CompareString, is represented twice in the Win32 software development kit, once in its ANSI form, CompareStringA and once in its Unicode form, CompareStringW. CompareString is a macro that expands to one or the other of these forms, depending on the compilation environment.
The Windows 9x kernels are essentially ANSI-based. They support few of the Unicode character functions beyond those that convert to and from Unicode. Among the Unicode APIs not supported in the 9x kernels is CompareStringW.
Windows NT is Unicode-based at the file-system level and internal storage level, but the NT kernels support a broad array of text processing APIs using conversion. Generally, however, the Unicode APIs are faster than their ANSI homologues. In the case of CompareString, for example, CompareStringW and CompareStringA are both supported under Windows NT, but CompareStringW can be as much as three times faster than CompareStringA.
Windows CE is Unicode-based and supports only the Unicode text and file-system APIs. Predictably, Windows CE supports only CompareStringW, and not CompareStringA. In addition, Windows CE supports only restricted forms of the ANSI-Unicode conversion APIs.
Two different APIs normally perform conversions between ANSI and Unicode: MultiByteToWideChar converts ANSI text to Unicode text, and WideCharToMultiByte converts Unicode text to ANSI text. Each of these APIs depends on a number of parameters, including the ANSI code page to which or from which the text is to be converted. On the desktop, installing a code page is simply a matter of copying a single file to a particular directory. On a Windows CE–based device, the code pages on the system are among the items controlled by the OEM during system generation. An OEM can include any code pages that it needs, but no others can be added later. Thus, if a user wants to convert ANSI Hebrew to Unicode, but does not have the code page on his or her Windows CE–based device, MultiByteToWideChar will fail.
Other restrictions arise from the way in which the Windows CE operating system handles resources. Because of the limited memory available on many Windows CE–based devices, some high-memory options available on the desktop are not supported in Windows CE. For example, a resource file on the desktop can contain resources from a number of different languages simultaneously. On Windows CE, a resource file can contain resources from only one language. If a program needs resources from more than one language, it must load resources from more than one resource file at run time. Generally, this is not a significant restriction. Multi-language resource files are usually large and difficult to create. In addition, fixing a multi-language file requires reshipping all the languages in the file, and not just the one or two where fixes were applied, which in a large file can constitute significant overhead. Most applications, even on the desktop, find it better to ship individual language DLLs.
This restriction does lead to some consequences. In particular, Windows CE does not support the FindResourceEx API, and the FormatMessage API ignores the language identifier passed to it. FindResourceEx differs from FindResource only in including a language identifier that determines which resource language should be sought. Since Windows CE has only one language, that is the one you are going to get. FormatMessage is similar: it uses a string resource to format a message, and it uses the language identifier to choose the instance of the string. Again, Windows CE has only one instance.
One feature offered by Windows CE and not available on the desktop has to do with resources that are loaded from a file. Because all programs on the system are resident in either system ROM or in RAM, a number of resource-loading functions offer the developer the option of loading a resource in-place. For example, the LoadStringW API takes a parameter that specifies where to copy the string. If that address is NULL under Windows CE, then the API returns the address in ROM or RAM where that resource lives, rather than returning the number of characters copied. This approach has the advantage of being both fast and efficient, with fewer bytes of program memory consumed by this operation than would be consumed by copying the resource directly. In addition, since DLL memory is shared, a resource can be loaded in place from a DLL, thus allowing many programs to share that data in a read-only fashion without allocating space in any one of them. On a memory-constrained system, such as a portable device or an embedded device, this is a significant advantage.
Suppose that you wanted to write an application that displayed the time and date at which it was run and that also displayed an amount of currency and a numerical value. You could create a window and use hard-coded strings to display those items. That approach would suffice if you did not plan to sell this application in any market other than the United States, but it would not work, even if you wanted to sell the application in Canada. Even if you could get an English-only application into the Canadian market, your numerical and currency displays would be wrong. This section describes a simple application that uses resources, satellite DLLs, and National Language Services to display these items with a single code base.
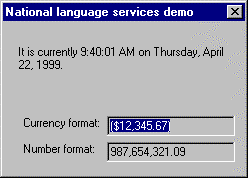
This application, called NLSDemo, uses a simple dialog-box-based interface. It displays three items: the current time and date, a negative amount of currency, and a relatively large number. What is significant about this display is that it is sensitive to the language to which the application is localized and to the locale in which a user's system is operating. Figure 1 shows the English UI of this demonstration when run with U.S. English settings. Figure 2 shows the same English application, running with French Canadian settings. Figure 3 shows the Italian UI of this demonstration when run with standard Italian settings. Figure 4 shows the Japanese UI of the demonstration when run with Japanese settings. Notice that the format of dates, times, numbers, and currency amounts depends on both locale and program language. Also note that the size of the dialog box changes to accommodate each language.
Figure 1. U.S. English dialog box
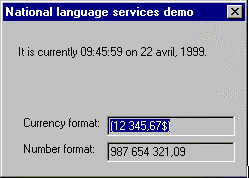
Figure 2. French Canadian dialog box for English application
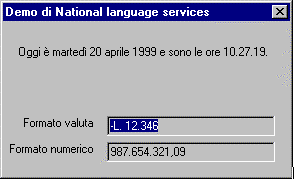
Figure 3. Italian dialog box
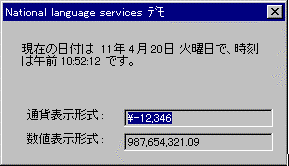
Figure 4. Japanese dialog box
NLSDemo consists of two pieces: a main executable (NLSDemo.exe) and a resource-only satellite DLL (NLSRsrc.dll). At startup, NLSDemo.exe calls the LoadLibrary API with a fixed value. That value is stored as a hard-coded string inside the program and does not vary from language to language. The value could have been stored as a string resource in NLSDemo.exe, but since the value was a constant, it was left in the code. This case is the only one in which a hard-coded string should ever appear in internationalized code—if the value is used only by the program, is never shown to the user, and does not vary among languages. After LoadLibrary is called, the handle it returns is saved for future reference.
The code for NLSDemo.exe is shown at the end of this section. There are two points of interest in the code. First is the creation of the dialog box itself. The CreateDialog API takes four parameters:
Usually, the handle to the current module is passed as the first argument to this function, but here the handle to the resource DLL is passed instead, along with a coded form of the dialog box template resource identifier as it appears in the resource DLL. That causes the resource for the dialog box to be drawn from the resource DLL at the specified identifier.
Second, note the process of filling in the header line and the two edit boxes. The generation of the header line is a multistage process. First, the date and time as they would be represented in the current system locale are extracted from the system by calls to GetDateFormat and GetTimeFormat. Then, the template string for incorporating them into the dialog box is extracted from the resources in the satellite DLL. Finally, FormatMessage is called to produce the final displayed string. Similarly, the display of the edit boxes is done indirectly: strings representing the two amounts are kept inside the program. These strings are formatted for output by calls to GetCurrencyFormat and GetNumberFormat, and the resulting strings are then displayed.
There are two options to localize the program. You can create a different .rc (resource) file for each language, and compile them into separate language DLLs. This requires a translator to translate the .rc file, and a developer to recompile the DLL.
The second option is to open NLSRsrc.dll directly with the Visual C++ resource editor, and then edit it. When you open the DLL, you must select Resources in the Open As list box that appears at the bottom of the Open dialog box. The resource file can then be edited and translated. If necessary, at the end of the editing and resizing, the file can simply be saved. The advantage of this technique is that it is possible to generate additional localized versions without recompiling, even months after the U.S. product has been shipped. If you are targeting more than one processor type, this operation needs to be repeated once for each target, or it might be more convenient to edit the .rc file directly and recompile.
//////////////////////////////////////////////////////
// © 1999 Microsoft Corporation. All rights reserved.
//////////////////////////////////////////////////////
#ifndef STRICT
#define STRICT
#endif
#include <windows.h>
#include <resource.h>
// Constants
// Maximum length of the string representation of the currency amount
#define MAX_CURRENCY_LEN 32
// The maximum length of the string representation of the number
#define MAX_NUMERIC_LEN 32
// Global variables
HINSTANCE g_hMain = NULL; // Handle to the main program
HINSTANCE g_hRsrc = NULL; // Handle to the satellite resource DLL
DWORD g_dwCurLcid; // Lcid relative to which to display strings
// global constants
TCHAR k_szRsrcLibFileName[] = TEXT("NLSRsrc"); // Language-
\\invariant name of the resource DLL
TCHAR k_szCurrencyAmount[] = TEXT("-12345.67"); // Currency amount
TCHAR k_szNumericAmount[] = TEXT("987654321.09"); // Numerical value
// InitGlobals -- initialize global variables
void InitGlobals(HINSTANCE hMain)
{
// NLS will format items according to the default user locale.
// On Windows CE, this is the same as the system locale.
g_dwCurLcid = GetUserDefaultLCID();
// Save away the handle to the global instance
g_hMain = hMain;
// Load the satellite resource DLL
g_hRsrc = LoadLibrary(k_szRsrcLibFileName);
}
// UninitGlobals -- clean up any globals that might persist.
void UninitGlobals()
{
FreeLibrary(g_hRsrc); // Good practice, in general
}
// InitRsrcDlg -- set up the dialog contents for the
// dialog box represented by hWnd.
void InitRsrcDlg(HWND hWnd)
{
TCHAR szTemplate[256];
TCHAR szDate[32];
TCHAR szTime[32];
PVOID pvBuffer;
PVOID pvArgs[] = {szTime, szDate};
TCHAR szCurrency[MAX_CURRENCY_LEN];
TCHAR szNumber[MAX_NUMERIC_LEN];
// First, initialize the startup time string.
// GetDateFormat is the NLS routine that formats a time in a
// locale-sensitive fashion. In this case, the current date is
// being displayed in the long date format
if (0 == GetDateFormat(g_dwCurLcid, DATE_LONGDATE, NULL, NULL,
szDate, 32)) {
return;
}
// GetTimeFormat is the NLS routine that formats a time in a
// locale-sensitive fashion. In this case, the current time is
// being displayed in the default format
if (0 == GetTimeFormat(g_dwCurLcid, 0, NULL, NULL, szTime, 32)) {
return;
}
// Load the formatting string for the date and time entry from the
// satellite DLL, not the main program. This resource is in
// whatever language is represented in the resource DLL; it is not
// directly sensitive to the operational language.
if (0 == LoadString(g_hRsrc, IDS_THETIMEIS, szTemplate, 256)) {
return;
}
// Use FormatMessage to create a single string which contains these
// items in the correct order. FormatMessage will allocate the
// output buffer containing the formatted message itself, but
// we will be responsible for freeing it when we're done.
FormatMessage(FORMAT_MESSAGE_FROM_STRING |
FORMAT_MESSAGE_ALLOCATE_BUFFER |
FORMAT_MESSAGE_ARGUMENT_ARRAY,
szTemplate,
0, // Ignored
0, // Ignored
(LPTSTR) &pvBuffer,
256,
(va_list *) pvArgs);
// Display the string in the dialog box.
SetDlgItemText(hWnd, IDC_DATETIME, (LPCTSTR) pvBuffer);
// Release the buffer.
LocalFree(pvBuffer);
// Now, display the currency amount and the number using NLS.
// GetCurrencyFormat is the NLS routine that formats a currency
// amount in a locale-sensitive fashion.
if (0 != GetCurrencyFormat(g_dwCurLcid, 0, k_szCurrencyAmount, NULL,
szCurrency, MAX_CURRENCY_LEN)) {
SetDlgItemText(hWnd, IDC_CURRENCY, szCurrency);
}
// GetNumberFormat is the NLS routine which formats a number in a
// locale-sensitive fashion.
if (0 != GetNumberFormat(g_dwCurLcid, 0, k_szNumericAmount, NULL,
szNumber, MAX_NUMERIC_LEN)) {
SetDlgItemText(hWnd, IDC_NUMBER, szNumber);
}
}
// NLSDemoDlgProc -- Main dialog proc for the window
BOOL CALLBACK NLSDemoDlgProc(HWND hWnd,
UINT uMsg,
WPARAM wParam,
LPARAM lParam)
{
switch(uMsg) {
case WM_INITDIALOG:
InitRsrcDlg(hWnd); // Initialize the dialog box.
return TRUE;
case WM_COMMAND:
switch (LOWORD(wParam)) {
case IDCANCEL:
EndDialog(hWnd, 0); // Finished; return 0
return TRUE;
}
}
return FALSE;
}
// wWinMain -- main program.
// Notice that this is a wide character entry point; this is a Windows
// CE program, and all API interfaces are Unicode-based. The usual
// entry point, WinMain, is an ANSI function.
LRESULT WINAPI wWinMain(HINSTANCE hMain,
HINSTANCE /* Ignored */,
LPWSTR /* Ignored */,
INT nCmdShow)
{
// Initialize globals
InitGlobals(hMain);
// Show the window
return DialogBox(g_hRsrc, MAKEINTRESOURCE(IDD_NLSDEMODLG), NULL,
NLSDemoDlgProc);
}Using the tools provided by Windows CE and drawing from the experience of Microsoft in developing international applications, you can start to develop international applications for Windows–CE based devices without a large initial investment. The key to successful internationalization is developing code that can work in all languages. It is important to know the requirements of each language and locale for which you want to localize; however, providing localized applications expands the market for your software and improves the worldwide image of your company.
Kano, Nadine. Developing International Software for Windows 95 and Windows NT, Redmond, WA: Microsoft Press, 1995
Richter, Jeffrey. Advanced Windows, 3rd Edition, Redmond, WA: Microsoft Press, 1996.
For general information about designing, building, and testing international applications, see: www.microsoft.com/GlobalDev/gbl-gen/default.htm.
For the latest information about Windows CE, see the Microsoft Windows CE Web site at: www.microsoft.com/windowsce/default.asp.
--------------------------------------------
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication. This document is for informational purposes only.
This article is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.
Microsoft, ActiveX, Visual Basic, Visual C++, Visual J++, Win32, Windows, and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Java is a trademark of Sun Microsystems, Inc.
Other product and company names mentioned herein may be the trademarks of their respective owners.