As you troubleshoot or perform cluster maintenance, it may be possible to keep resources available on one of the two nodes. If you are able to use at least one of the nodes for resources while troubleshooting, you may be able to keep as many resources available to users during administrative activity. In some cases, it may be desirable to run with some unavailable resources rather than none at all.
The most likely causes for one or all nodes to be down are usually related to the shared SCSI bus. If only one node is down, check for SCSI-related problems or for communication problems between the nodes. These are the most likely sources of problems that lead to node failures.
If the entire cluster is down, try to bring at least one node online. If you can achieve this goal, the affect on users may be substantially reduced. When a node is online, gather event log data or other information that may be helpful to troubleshoot the failure. Check for the existence of a recent Memory.dmp file that may have been created from a recent crash. If necessary, contact Microsoft Product Support Services for assistance with this file.
If a single node is unavailable, make sure that resources and groups are available on the other node. If they are, begin troubleshooting the failed node. Try to bring it up and gather error data from the event log or cluster diagnostic logfile.
If you're applying service packs or hotfixes, avoid applying them to both nodes at one time, unless otherwise directed by release notes, Knowledge Base articles, or other instructions. It may be possible to apply the updates to a single node at a time to avoid rendering both nodes unavailable for a short or long duration. More information on this topic may be found in Microsoft Knowledge Base article Q174799, "How to Install Service Packs in a Cluster."
If one or more servers are not responding but have not crashed or otherwise failed, the problem may be related to configuration, software, or driver issues. You can also check the shared SCSI bus or connected disk devices.
If the servers are installed as member servers (nondomain controllers), it is possible that one or both nodes may stop responding if connectivity with domain controllers becomes unavailable. Both the cluster service and other applications use remote procedure calls (RPCs). Many RPC-related operations require domain authentication. As cluster nodes must participate in domain security, it is necessary to have reliable domain authentication available. Check network connectivity with domain controllers and for other network problems. To avoid this potential problem, it is preferred that the nodes be installed as backup domain controllers (BDC). The BDC configuration allows each node to perform authentication for itself despite problems that could exist on a wide area network (WAN).
There are a variety of conditions that could prevent the Cluster Service (ClusSvc) from starting. Many of these conditions may be the result of configuration or hardware related problems. The first things to check when diagnosing this condition are the items on which the Cluster Service depends . Many of these items may be referenced in Chapter 1: Preinstallation. Common causes for this problem with error messages are noted below.
Check the service account under which ClusSvc runs. This domain account needs to be a member of the local adminstrators group on each server. The account needs the Logon as a service and Lock pages in memory rights. Make sure the account is not disabled and that password expiration is not a factor. If the failure is because of a problem related to the service account, the Service Control Manager (SCM) will not allow the service to load, much less run. As a result, if you've enabled diagnostic logging for the Cluster Service, no new entries will be written to the log, and a previous logfile may exist. Failures related to the service account may result in Event ID 7000 or Event ID 7013 errors in the event log. In addition, you may receive the following error message:
"Could not start the Cluster Service on \\computername. Error 1069: The service did not start because of a logon failure."
Check to make sure the quorum disk is online and that the shared SCSI bus has proper termination and proper function. If the quorum disk is not accessible during startup, the following error message may occur:
"Could not start the Cluster Service on \\computername. Error 0021: The device is not ready."
Also, if diagnostic logging for the Cluster Service is enabled, the logfile entries may indicate problems attaching to the disk. See Appendix B for more information and a detailed example of the logfile entries for this condition, Example 1: quorum disk turned off.
If the Cluster Service is running on the other cluster node, check the cluster logfile (if it is enabled) on that system for indications of whether or not the other node attempted to join the cluster. If the cluster logfile did try to join the cluster, and the request was denied, the logfile may contain details of the event. For example, if you evict a node from the cluster, but do not remove and reinstall MSCS on that node, when the server attempts to join the cluster, the request to join will be denied. The following are sample error messages and event messages:
"Could not start the Cluster Service on \\computername. Error 5028: Size of job is %1 bytes."
For examples of logfile entries for this type of failure, see the Example 4: evicted node attempts to join existing cluster section in Appendix B of this document.
If the Cluster Service won't start, check the event log for Event ID 7000 and Event ID 7013. These events may indicate a problem authenticating the Cluster Service account. Make sure the password specified for the Cluster Service account is correct. Also make sure that a domain controller is available to authenticate the account, if the servers are nondomain controllers.
If the Services utility in Control Panel indicates that the service is running, and you cannot connect with Cluster Administrator to administer the cluster, the problem may be related to the Cluster Network Name or to the cluster IP address resources. There may also be RPC-related problems. Check to make sure the RPC Service is running on both nodes. If it is, try to connect to a known running cluster node by the computer name. This is probably the best name to use when troubleshooting to avoid RPC timeout delays during failover of the cluster group. If running Cluster Administrator on the local node, you may specify a period (.) in place of the name when prompted. This will create a local connection and will not require name resolution.
If you can connect through the computer name or using the period, check the cluster network name and cluster IP address resources. Make sure that these and other resources in the cluster group are online. These resources may fail if a duplicate name or IP address on the network conflicts with either of these resources. A duplicate IP address on the network may cause the network adapter to shut down. Check the system event log for errors.
Examples of logfile entries for this type of failure may be found in the Example 3: duplicate cluster IP address section in Appendix B of this document.
The typical reason that a group may not failover properly is usually because of problems with resources within the group. For example, if you elect to move a group from one node to another, the resources within the group will be taken offline, and ownership of the group will be transferred to the other node. On receiving ownership, the node will attempt to bring resources online, according to dependencies defined for the resources. If resources fail to go online, MSCS attempts again to bring them online. After repeated failures, the failing resource or resources may affect the group and cause the group to transition back to the previous node. Eventually, if failures continue, the group or affected resources may be taken offline. You can configure the number of attempts and allowed failures through resource and group properties.
When you experience problems with group or resource failover, evaluate which resource or resources may be failing. Determine why the resource won't go online. Check resource dependencies for proper configuration and make sure they are available. Also, make sure that the "Possible Owners" list includes both nodes. The "Preferred Owners" list is designed for automatic failback or initial group placement within the cluster. In a two-node cluster, this list should only contain the name of the preferred node for the group, and should not contain multiple entries.
If resource properties do not appear to be part of the problem, check the event log or cluster logfile for details. These files may contain helpful information related to the resource or resources in question.
Problems with physical disk resources are usually hardware related. Cables, termination, or SCSI host adapter configuration may cause problems with failover, or may cause premature failure of the resource. The system event log may often show events related to physical disk or controller problems. However, some cable or termination problems may not yield such helpful information. It is important to verify the configuration of the shared SCSI bus and attached devices, whenever you detect trouble with one of these devices. Marginal cable connections or cable quality can cause intermittent failures that are difficult to troubleshoot. BIOS or firmware problems might also be factors.
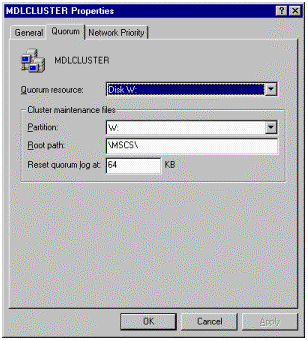
If the Cluster Service won't start because of a quorum disk failure, check the corresponding device. If necessary, use the -fixquorum startup option for the Cluster Service, to gain access to the cluster and redesignate the quorum disk. This process may be necessary if you replace a failed drive, or attempt to use a different device in the interim. To view or change the quorum drive settings, right-click the cluster name at the top of the tree, listed on the left portion of the Cluster Administrator window, and select Properties. The Cluster Properties window contains three different tabs, one of which is for the quorum disk, as shown in Figure 4. From this tab, you may view or change quorum disk settings. You may also redesignate the quorum resource. More information on this topic may be found in Microsoft Knowledge Base article Q172944, "How to Change Quorum Disk Designation."
Figure 4. MDLCluster Properties
Failures of the quorum device while the cluster is in operation are usually related to hardware problems, or to configuration of the shared SCSI bus. Use troubleshooting techniques to evaluate proper operation of the shared SCSI bus and attached devices.
For a file share to reach online status, the dependent resources must exist and be online. The path for the share must exist. Permissions on the file share directory must also include at least Read access for the Cluster Service account.
If you attempt to access a shared drive through the drive letter, it is possible that you may receive the Incorrect Function error. The error may be a result of the drive not being online on the node you're accessing it from. The drive may be owned by another cluster node and may be online. Check Cluster Administrator for ownership of the resource and online status. If necessary, consult the Physical Disk Resource Problems section of this document. The error could also indicate drive or controller problems.