If you try to administer the cluster from a remote workstation, the most common way to do so would be to use the network name you defined during the setup process as Cluster Name. This resource is located in the Cluster Group. Cluster Administrator needs to establish a connection using RPC. If the RPC service has failed on the cluster node that owns the Cluster Group, it will not be possible to connect through the Cluster Name or the name of the computer. Try to connect, instead, using the computer names of each cluster node. If this works, this indicates a problem with either the IP address or Network Name resources in the Cluster Group. There may also be a name resolution problem on the network that may prevent access through the Cluster Name.
Failure to connect using the Cluster Name or computer names of either node may indicate problems with the server, with RPC connectivity, or with security. Make sure that you are logged on with an administrative account in the domain, and that the account has access to administer the cluster. Access may be granted to additional accounts by using Cluster Administrator on one of the cluster nodes. For more information on controlling administrative access to the cluster, see "Specifying Which Users Can Administer a Cluster" in the MSCS Administrator's Guide.
If Cluster Administrator cannot connect from the local console of one of the cluster nodes, check to see if the Cluster Service is started. Check the system event log for errors. You may want to enable diagnostic logging for the Cluster Service. If the problem occurs after recently starting the system, wait 30 to 60 seconds for the Cluster Service to start, and then try to run Cluster Administrator again.
The Cluster Administrator application uses RPC communications to connect with the cluster. If you use the Cluster Name to establish the connection, Cluster Administrator may appear to stop responding during a failover of the Cluster Group and its resources. This normal delay occurs during the registration of the IP address and network name resources within the group, and the establishment of a new RPC connection. If a problem occurs with the registration of these resources, the process may take extended time until these resources become available. The first RPC connection must time out before the application attempts to establish another connection. As a result, Cluster Administrator may eventually time out if there are problems bringing the IP address or network name resources online within the Cluster Group. In this situation, try to connect using the computer name of one of the cluster nodes, instead of the cluster name. This usually allows a more real-time display of resource and group transitions without delay.
To move a group from one node to another, you must have administrative rights to run Cluster Administrator. The destination node must be online and the cluster service started. The state of the node must be online and not Paused. In a paused state, the node is a fully active member in the cluster, but cannot own or run groups.
Both cluster nodes should be listed in the Possible Owners list for the resources within the group; otherwise the group may only be owned by a single node and will not fail over. While in some configurations, this restriction may be intentional, in most it would be a mistake as it would prevent the entire group from failing over. Also, to move a group, resources within the group cannot be in a pending state. To initiate a Move Group request, resources must be in one of the following three states: online, offline, or failed.
To properly delete a group from the cluster, the group must not contain resources. You may either delete the resources contained within the group, or move them to another group in the cluster.
Resources are usually easy to add. However, it is important to understand various resource types and their requirements. Some resource types may have prerequisites for other resources that must exist within the same group. As you work with MSCS, you may become more familiar with these and what they are. You may find that a resource depends on one or more resources within the same group. Examples might include IP addresses, network names, or physical disks. The resource wizard will typically indicate mandatory requirements for other resources. However, in some cases, it may be a good idea to add resources to the dependency list, as they are related. While Cluster.exe may allow the addition of resources and groups, the command-line utility does not impose the dependency or resource property constraints like the Cluster Administrator, because these activities may consist of multiple commands.
For example, suppose you want to create a network name resource in a new group. If you try to create the network name resource first, the wizard will indicate that it depends on an IP address resource. The wizard lists available resources in the group from which you select. If this is a new group, the list may be empty. Therefore, you will need to create the required IP address resource before you create the network name.
If you create another resource in the group and make it dependent on the network name resource, the resource will not go online without the network name resource in an online state. A good example might be a File Share resource. Thus, the share will not be brought online until the network name is online. Because the network name resource depends on an IP address resource, it would be repetitive to make the share also dependent on the same IP address. The established dependency with the network name implies a dependency on the address. You can think of this as a cascading dependency.
You might ask, "What about the disk where the data will be? Shouldn't the share depend on the existence or online status of the disk?" Yes, you should create a dependency on the physical disk resource, although this dependency is not required. If the resource wizard did impose this requirement, it would imply that the only data source that could be used for a file share would be a physical disk resource on the shared SCSI bus. For volatile data, shared storage is the way to go, and a dependency should be created for it. This way, if the disk experiences a momentary failure, the share will be taken offline and restored when the disk becomes available. However, without a requirement for dependency on a physical disk resource, this grants the administrator additional flexibility to use other disk storage for holding data. Use of nonphysical disk data storage for the share implies that for it to be moved to the other node, equivalent storage and the same drive letter with the same information must also be available there. Further, there must be some method of data replication or mirroring for this type of storage, if the data is volatile. Some third parties may have solutions for this situation. Use of local storage in this manner is not recommended for read/write shares. For read-only information, the two data sources can remain in sync, and problems with out-of-sync data are avoided.
If you use a shared drive for data storage, make sure to establish the dependency with the share and with any other resources that depend on it. Failure to do so may cause erratic or undesired behavior of resources that depend on the disk resource. Some applications or services that rely on the disk may terminate as a result of not having the dependency.
If you use Cluster.exe to create the same resources, note that it is possible to create a network name resource without the required IP address resource. However, the network name will not go online, and will generate errors from such an attempt.
While some third-party service may require modification for use within a cluster, many services may function normally while controlled by the generic service resource type as provided with MSCS. If you have a program that runs as an application on the server's desktop that you want to be highly available, you may be able to use the generic application resource type to control this application within the cluster.
The parameters for each of these generic resource types are similar. However, when planning to have MSCS manage these resources, it is necessary to first be familiar with the software and with the resources that software requires. For example, the software might create a share of some kind for clients to access data. Most applications need access to their installation directory to access DLL or INI files, to access stored data, or, perhaps, to create temporary files. In some cases, it may be wise to install the software on a shared drive in the cluster, so that the software and necessary components may be available to either node, if the group that contains the service moves to another cluster node.
Consider a service called SomeService. Assume this is a third-party service that does something useful. The service requires that the share, SS_SHARE, must exist, and that it maps to a directory called DATA beneath the installation directory. The startup mode for the service is set for AUTOMATIC, so that the service will start automatically after the system starts. Normally, the service would be installed to C:\SomeService, and it stores dynamic configuration details in the following registry key:
HKEY_LOCAL_MACHINE\Software\SomeCompany\SomeService
If you wanted to configure MSCS to manage this service and make it available through the cluster, you would probably take the following actions.
To configure MSCS:
Note If you evict a node from the cluster at any time, and have to completely reinstall a cluster node from the beginning, you will likely need to repeat steps 10 through 12 on the node if you add it back to the cluster. The procedure described here is generic in nature, and may be adaptable to various applications. If you are uncertain how to configure a service in the cluster, contact the application software vendor for more information.
Applications follow a similar procedure, except that you must substitute the generic application resource type for the generic service resource type used in the above procedure. If you have a simple application that is already installed on both systems, then you may adapt the following steps to the procedure previously described:
Some cluster-aware applications may not require this type of setup, and they may have setup wizards to create necessary cluster resources.
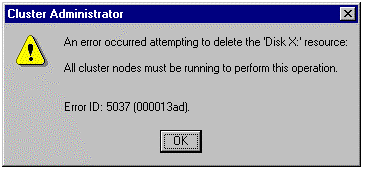
Some resources may be difficult to delete if any cluster nodes are offline. For example, you may be able to delete an IP address resource if only one cluster node is online. However, if you try to delete a physical disk resource while in this condition, an error message dialog box may appear, similar to the following:
Figure 5. Deleting Resources Error Message
Physical disk resources affect the disk configuration on each node in the cluster and must be dealt with accordingly on each system at the same time. Therefore, all cluster nodes must be online to remove this type of resource from the cluster.
If you attempt to remove a resource on which other resources depend, a dialog box listing the related resources will be displayed. These resources will also be deleted, as they are linked by dependency to the individual resource chosen for removal. To avoid removal of these resources, first change or remove the configured dependencies.
To move resources from one group to another, both groups must be owned by the same cluster node. Attempts to move resources between groups with different owners may result in the following error message:
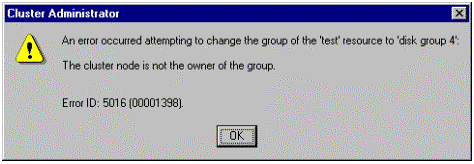
Figure 6. Moving Resources Error Message
To move resources between groups, the groups must have the same owner. This situation may be easily corrected by moving one of the groups so that both groups have the same owner. Equally important is the fact that resources to be moved may have dependent resources. If a dependency exists between the resource to be moved and another resource, a prompt may appear that lists related resources that need to move with the resource:
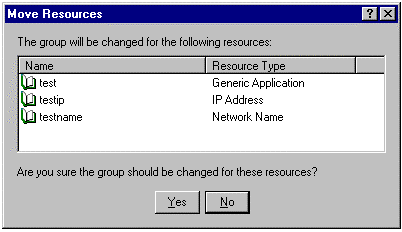
Figure 7. Moving Resources Dialog Box
Problems moving resources between groups other than those mentioned in this section may be caused by system problems or configuration-related issues. Check event logs or cluster logfiles for more information that may relate to the resource in question.
Disks attached to the shared SCSI bus interact differently with Chkdsk and the companion system startup version of the same program, Autochk. Autochk does not perform Chkdsk operations on shared drives when the system starts up, even if the operations are needed. MSCS performs a file system integrity check for each drive, when bringing a physical disk online. MSCS automatically launches Chkdsk, as necessary.
If you need to run Chkdsk on a drive, consult the Microsoft Knowledge Base articles in Table 4:
Table 4. Chkdsk Articles
| Reference Number | Article |
| Q174617 | Chkdsk Runs while Running Microsoft Cluster Server Setup |
| Q176970 | Chkdsk /f Does Not Run on the Shared Cluster Disk |
| Q174797 | How to Run CHKDSK on a Shared Drive |