Fred Pace
MSDN Content Development Group
May 1996
Click to copy the sample Microsoft Access database for this technical article.
In this article, I'll explain how a consistent programming style can be analyzed and broken into templates representing functional elements of a development project. Additionally, I'll show you how the structure of a database can be turned into a collection of entities and attributes, known as metadata, and used in conjunction with templates to generate code. The sample database that accompanies this article was created with Microsoft® Access 97 and is named intgendb.mdb.
This article is the first in a pair about the Interface Generator (IntGen). For the second part, see "Generating Code Using Templates and Metadata". The goal of this project is to come up with a means by which characteristics of a database can be stored and used to generate SQL table creation scripts and stored procedure scripts, as well as an application programming interface (API) that provides data services for that database. Oh yeah, the API can be generated in the language of your choice. It is important to understand, however, that the IntGen system is not a production tool to be used in the generation of production code. Instead it is an example of how such a system might be built to solve a variety of problems. Hopefully, after reading this article and the next one, you'll have a better understanding of the details involved in a project of this magnitude and perhaps find some interesting ways to solve problems that you may have run into in your own project
If I ask a dozen different developers to write a SQL CREATE TABLE script for an Author table, I'll probably get a dozen different answers. That's no problem—different people have different techniques for getting the job done. However, if I ask one programmer to write the same CREATE TABLE script a dozen different times and I get a dozen different answers, that programmer needs a lesson in consistency.
Consistency goes beyond using the same naming convention for all the variables and functions in your code (although this is a good place to start). Consistency is using the same approach over and over again to solve the same set of problems. Here in the MSDN Content Development Group, we have a set of standards in place that define how different types of code must be written. Not only does this prevent our readers from being confused by several different approaches to tackling the same problem, but it speeds up the entire development process. In a nutshell, we use a layered paradigm in all of our data access APIs. If you've read my recent articles, you are aware of the layered paradigm and how it can be implemented. If you don't know what the layered paradigm is, check out Ken Bergmann's Client/Server Solutions series, starting with “The Architecture Process”, or my article "Designing Intelligent Control Palettes".
Two data access APIs that I helped design, the Corporate Benefits Sample Component Object Model (COM) API, BenVB.dll, and the BankSrv.dll API referred to in my article "Designing Intelligent Control Palettes" are virtually identical in structure. The only major difference between the two is the data they are designed to act upon. Because the source code for the BankSrv.dll was written after Benefits was written, the developer simply had to take the basic functional model of Benefits and apply it to a different set of data. There was no need to spend time thinking up a design—it was almost as simple as a cut and paste. This level of consistency is almost wholly attributable to using a layered development methodology. Are your designs this consistent and reusable?
Now, imagine what you could do if you could take your consistent coding style and abstract it in such a way that a generation program could look at your code, look at the structure of a database, and then generate a data-access services API specific to your database. Sound cool? Read on.
In the MSDN Content Development Group, we generate data-access services APIs pretty much the same way every time, regardless of what language we are using. Sometimes we use different data access methods such as Remote Data Objects (RDO) or Active Data Objects (ADO), and sometimes we add bells and whistles, such as self-expanding objects. (For more on self-expanding objects, see "Self-Expansion of Objects: Smart Objects" in the Corporate Benefits Sample documentation in the MSDN Library.) For the most part, though, each API consists of individual data classes and an Admin class. The data classes have Get/Let methods that allow read/write access to member variables representing each field in the table. The Admin class has the following functions:
| ExecBoolean() | Executes a query against a data source. |
| ExecFillArray() | Fill a multidimensional array based on a query executed against a data source. |
| InsertX() | Builds a SQL statement for each table in the database that inserts a record using ExecBoolean(). |
| UpdateX() | Builds a SQL statement for each table in the database that updates a record ExecBoolean(). |
| DeleteX() | Builds a SQL statement for each table in the database that deletes a record using ExecBoolean(). |
| GetDomainX() | Publishes a domain of data. |
That's about it. Regardless of whether we use Microsoft Visual Basic®, C++, ATL, or Java, if we create a data-access API, the above functionality is in there. If you can describe your code in isolated terms, as I did above, there is a very good chance that your code is a candidate for generation. I didn't say that your code has to be constructed identically to what we use in MSDN in order to be a candidate—our style may not be your style. I'm only saying that if you build the same things the same way every time, generation may work for you. Of course, if you think back and realize that the last three data access techniques you've used are all different, your code may not be a very good candidate for generation. If you code differently every time, how are you going to isolate common functionality? Hang on though, rather than not reading this article because I just excluded your code, perhaps you should consider standardizing your development techniques. As I mentioned earlier, the techniques described in this article aren't the absolute standard for how code is to be written, but they might be a good place for you to start if you are trying to work out your own standardizing techniques.
With the functionality of our API isolated into specific functions and methods, we can now describe our project as follows:
If we could give these rules to a generation program along with templates representing the isolated functional tasks (for example, Insert, Update, and ExecBoolean), this API could be generated. The trick now is to store the metadata that describes the tables and fields we want our API to be based on.
If data structures are broken down and described in an abstract fashion, it is possible for those structures to be regenerated in a number of different languages. For instance, a database field can be described in terms of a field name, a field type, and a field length. By breaking the field into these properties, it can be described in much more specific terms. These properties are known as metadata. Simply put, metadata is data that describes other data.
Storing a field's metadata allows us to regenerate this field whenever we want. Knowing the field's name, type, and length allows us to slip it into a SQL statement easily. But can't we also use the field's metadata to assist in building structures related to the field? Couldn't we build a structure such as a Visual Basic property procedure using the same metadata? The following table illustrates some sample metadata for a database field.
| Field Name | Type | Length |
| String | 12 |
Let's assume that the field is both readable and writable. We'll need a Property Get procedure and either a Property Set or a Property Let procedure. In this case, the field type is String, so we know we'll be using a Property Let procedure. The following code illustrates a skeleton of a Property Let procedure:
Public Property Let(New_<SomeField> as <SomeType>)
m_<SomeVar> = New_<SomeField>
End Property
Notice that the bracketed place holders in the code could be replaced with elements from the field's metadata. When replaced, the code now looks like the following:
Public Property Let(New_Email as String)
m_Email = New_Email
End Property
As you can see, the metadata of a field is much more valuable than a mere field creation line in a SQL statement.
The replacement technique illustrated above is really the heart and soul of the Interface Generator project; templates (described later in this article) will store source code with placeholder tags similar to the <SomeField> tag. Meanwhile, metadata describing the application data and template information is stored in a Microsoft Access .mdb file.
Of course, data modeling and normalization issues are a bit more complicated than a simple field name, type, and size, so read on and I'll show you how it's done.
In order to be able to generate code from a set of metadata, the metadata schema must be carefully designed. Every characteristic of an object that is required to properly recreate that object must be represented in the schema. In the case of IntGen, the concept of tables and fields, as well as the properties of these tables and fields, needs to be modeled. The core structures of the IntGen database are the Entity and Attribute tables. The metadata that is to describe these tables and their fields will need to be granular enough to handle a number of different possibilities, including indexes, checks, default values, and entry validation masks; therefore, other support tables also need to be created.
Entities are the base objects that will be stored in intgendb.mdb. A good example of a base object is a table. Metadata for a table includes a name, description, a flag to indicate whether the table is a domain table or not, and of course fields. (Since a table can have more than one field, however, normalization rules require a separate table for these.)
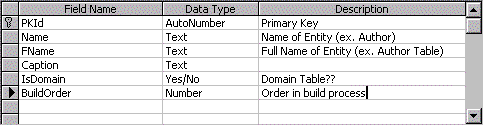
The metadata stored in the Entity table needs to be generalized enough so that code can be generated from the metadata using a number of different naming conventions. For instance, if a table name is stored in the database as tbAuthor, it becomes difficult for that piece of metadata to be used in the generation of anything beyond a table. For this reason, all data stored in the IntGen database should not have naming prefixes. As you'll see later in this article, naming conventions can also be resolved through the use of metadata. Figure 1 illustrates a sample of an Entity table structure.
Figure 1. Example of an Entity table structure
Attributes are the elements that make up entities. The fields in a database table are a good example of attributes—fields are elements of a table. As I mentioned earlier, metadata for a field could include a field name, length, and type. Of course, unless you are trying to generate only the most basic of SQL statements, you may want a bit more detail to your metadata. Figure 2 defines some basic metadata for field attributes.
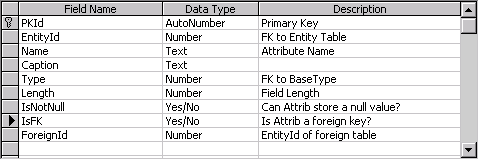
Figure 2. Attribute table structure
As with the Entity table, data that is entered into the attribute table should not include any naming convention prefixes. Prefixes for attributes are stored in the database in the VarType table, which will be discussed later. The data in the Attribute table should be as language neutral as possible to accommodate output to a number of different formats.
With the Entity and Attribute tables, we now have enough metadata to build basic tables and fields. Figures 3 and 4 list some sample metadata for the Entity and Attribute tables.
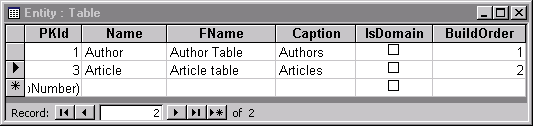
Figure 3. Sample Entity table data
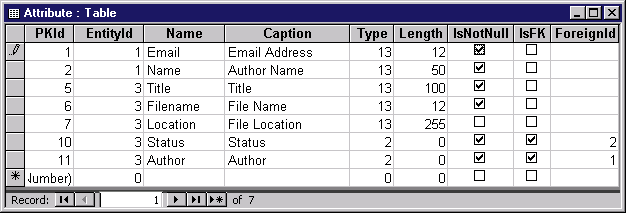
Figure 4. Sample Attribute table data
The following code illustrates a sample CREATE TABLE SQL statement using the metadata shown in Figures 3 and 4. The metadata used to generate the script is shown in bold:
CREATE TABLE tbAuthor
(
-- File: c:\work\projects\devtech\db\tb\objs\tbauthor.sql
-- Date: 04.17.97
PKId int Identity(1,1) PRIMARY KEY CLUSTERED
,Email varchar(12) NOT NULL
,Name varchar(50) NOT NULL
)
go
Pretty cool, huh? Now, what if the Email attribute is a unique index in the Author table? There is no metadata to handle a situation like that, so it can't be done with this simple a schema. Indexes are a pretty important element of a SQL table, however, so the schema should be designed to handle them.
Consider, for a moment, just what an index is. Is it a property of the fields of a database or a property of the table? Let's examine both options. If we add two more columns to our Attribute table, IsIndexed and IsUnique, it would appear that we can determine whether a field is to be indexed or not, as well as whether it is to be indexed uniquely. A generation program could rip through the attributes and, while examining the metadata for each attribute, know whether to index it or not. There is a problem with this solution, however. What if an index is composed of two or more fields? This solution limits you to single field indexes. Now, let's make indexes an attribute of a table just as we did with fields. Figure 5 depicts a model of indexes as an attribute of a table entity.
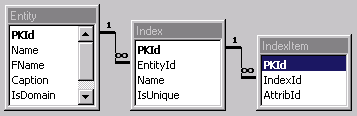
Figure 5. Indexes as an attribute of a table entity
With this schema, each table can have as many indexes as it needs, composed of one or more fields. Granted, the schema is a bit more complex, but flexibility is significantly improved.
Up to this point, I've been telling you that the data in the Entity and Attribute tables should be language independent. That is, the tables should not contain data formatted for a specific language, such as tbAuthor or sEmail. Additionally, data should not be typed to a specific language's data types; after all, an Integer in Microsoft SQL Server™ 6.5 is not an Integer in Visual Basic 5.0—it's a Long.
So, how can metadata that describes tables and fields go from the following T-SQL code . . .
,Email varchar(12) NOT NULL
to the following Visual Basic 5.0 code?
Public Property Let(sNew_Email as String)
m_sEmail = sNew_Email
End Property
The solution to a problem like this lies in three tables: Language, BaseType, and VarType. The Language table is a domain that contains a row for each language to be targeted. The BaseType table is a domain containing the core set of allowable variable types. Finally, the VarType table maps a language and a base type to a specific data type required for a language.
The structure of the VarType table is as follows:
| PKId | Primary Key |
| LangId | A foreign key to the Language table. |
| BaseId | A foreign key to the BaseType table. |
| Def | A definition of this BaseType for this language. For example, if the BaseType was Integer and the Language was Visual Basic, this Def would be Integer. |
| Prefix | A prefix to be added in front of attributes of this type. For example, if this VarType was an integer, the prefix might be "I" or "int" depending on the naming convention I wanted to use. |
Figure 6 illustrates the relationship of the Language, BaseType, VarType, and Attribute tables.
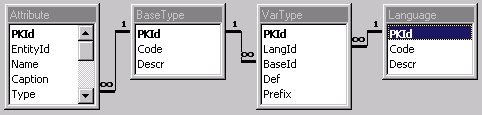
Figure 6. Mapping the base types
Now, when entering data for field attributes, the attribute can be typed as a generic base type. A generation program derives the correct data types for each language simply by knowing what language is being generated. At the same time, the data in the VarType table is capable of adding, for instance, my naming convention of "s" in front of string variables or your naming convention of "str".
Is this the only way in which metadata can and should be stored? Absolutely not. You may need more or less metadata in your project. This is only an example of the type of questions you should consider when modeling your own metadata.
So, now we arrive at the other end of the Interface Generator. In case you didn't notice, nowhere did I mention tables that would store the whole of the Visual Basic language or Java or T-SQL. So, how am I going to turn metadata that describes tables and fields into a SQL CREATE TABLE script, or a Visual Basic or Java data services API? The answer is templates. Templates are simply text files that contain code in a specific programming language interspersed with placeholders called tags. Tags are markers that indicate a specific point within a template where a specific piece of metadata should be inserted.
Earlier, you saw how code can be analyzed and broken down into functional elements. Each of these elements could be represented by a template. In order to turn code such as an Insert function or a SQL CREATE TABLE script into a template, any specific references to tables or fields should be replaced with generic tags representing pieces of metadata. The resulting template can then be used with any set of metadata you'd like.
In order to generate a full-blown API, templates need to be generated for each piece of functionality present in your API. Once done, a generation program could simply rip through the templates you have created, as well as the metadata for the database, and output the source files for your API. Want to generate the API in different languages or SQL scripts for your database? The process is the same. (Figure 7.)
Figure 7. Moving code to templates
Let's pull this all together now and examine what can be done with our metadata and templates full of tags. Two templates are shown below, one for a Visual Basic Insert function and one for a SQL CREATE TABLE script.
A Visual Basic Insert function template:
Public Function Insert(Optional o<Table> As C<Table>) As Boolean
...
'Inserting a <Table>?
If Not (o<Table> Is Nothing) Then
' validate o<Table> object
...
' build SQL statement
sQry = "Execute " & "pcIns_<Table>" & " "
sQry = sQry & "'" & Trim$(Left$(DoQuotes(.<Field>), <FLen>)) & "'" & " , "
sQry = sQry & "'" & Trim$(Left$(DoQuotes(.<Field>), <FLen>)) & "'"
End With
' Execute SQL statement
If m_oAdmin.ExecBoolean(sQry) Then
...
End If
End If
...
End Function
A SQL CREATE TABLE script template:
PRINT 'CREATING - tb<Table> ...'
go
CREATE TABLE tb<Table>
(
- File: <OutPath>\tb<Table>.sql
- Date: <GenDate>
PKId int Identity(1,1) PRIMARY KEY CLUSTERED
,<Field> <FType><FLen> <IsNull>
,<Field> <FType><FLen> <IsNull>
)
go
A generation program opens a template up, determines what language is being generated, and begins reading through it line by line. Every time a tag is encountered, the tag is replaced with the metadata it corresponds to. Naming conventions and data typing issues are resolved with the VarType table. The code below is the end result: two source files created from the same metadata. The following code is for Visual Basic—named and typed properly:
Public Function Insert(Optional oAuthor As CAuthor) As Boolean
...
'Inserting an Author?
If Not (oAuthor Is Nothing) Then
' validate oAuthor object
...
' build SQL statement
sQry = "Execute " & "pcIns_Author" & " "
sQry = sQry & "'" & Trim$(Left$(DoQuotes(.Email), 12)) & "'" & " , "
sQry = sQry & "'" & Trim$(Left$(DoQuotes(.Name), 50)) & "'"
End With
' Execute SQL statement
If m_oAdmin.ExecBoolean(sQry) Then
...
End If
End If
...
End Function
And this code is for SQL, also named and typed properly:
PRINT 'CREATING - tbAuthor ...'
go
CREATE TABLE tbAuthor
(
- File: c:\work\projects\devtech\db\tb\objs\tbauthor.sql
- Date: 04.17.97
PKId int Identity(1,1) PRIMARY KEY CLUSTERED
,Email varchar(12) NOT NULL
,Name varchar(50) NOT NULL
)
go
So, now you know that metadata is good and powerful and can be used to generate code. Pretty cool, huh? What other stuff can metadata be used for? Hmmm, how about dynamic Web sites?
Have you checked out The Microsoft Network (http://www.msn.com/) or Seattle Sidewalk™ city guide (http://seattle.sidewalk.com) lately? Do you think that these sites are just a bunch of static Hypertext Markup Language (HTML) pages that some poor author has to hand code meticulously one by one? No way! These pages are generated. Metadata is stored in Microsoft SQL Server databases and presented to the user through Active Server Page (ASP) scripts. Imagine how much work is saved by coding once in ASP and then simply entering metadata as content changes. The principle is exactly the same as that of the Interface Generation project. Enter metadata once, and then generate to your heart's content instead of hand coding!
If you write good, consistent code, using the same basic techniques in everything that you build, the IntGen sample should fill your head with all kinds of cool ideas about what you can do with metadata and templates. If you don't use consistent development techniques, then this should be your wakeup call to get with the program.
Are you interested in code generation but don't want to wait for us to get this sample built? Why not try building your own? Start small and build a SQL script generator or an API generator unique to the language you use. If you need more or less metadata than the sample includes, create your own schema. There are no hard-and-fast laws as to how metadata should be stored or how generation should be done. If you are sure that you'll never be generating a particular structure (for example, multifield indexes), you don't need to plan for them in your model. Along those same lines, every system needn't be template driven. If you want a simple system that simply generates SQL statements, perhaps you'll want to hard code the structures that comprise your SQL directly into your front-end program. It's your party and you can cry if you want to . . . whoops, I mean it's your system and you can build it the way you want to—as complex or simple as you like.