Sara Willliams and Charlie Kindel, Developer Relations Group
Microsoft Corporation
Created: October, 1994
This paper is adapted from an article appearing in Dr. Dobb's Journal, the newsstand special edition, December, 1994.
Note For a complete example of a working component object, please see the COMPPR sample that accompanies this article.
Click to open or copy the files in the COMPPR sample application for this technical article.
This article describes the Component Object Model (COM), a software architecture that allows the components made by different software vendors to be combined into a variety of applications. COM defines a standard for component interoperability, is not dependent on any particular programming language, is available on multiple platforms, and is extensible. This article focuses on the interoperability that COM provides, that is, how components and their clients interact. The sample code provided with this article provides an example of a working component object.
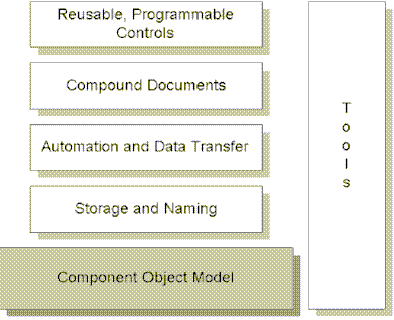
The Component Object Model (COM) is a component software architecture that allows applications and systems to be built from components supplied by different software vendors. COM is the underlying architecture that forms the foundation for higher-level software services, like those provided by OLE. OLE services span various aspects of component software, including compound documents, custom controls, inter-application scripting, data transfer, and other software interactions.
Figure 1. High-level OLE application services are built on the common Component Object Model foundation.
These services provide distinctly different functionality to the user; however, they share a fundamental requirement for a mechanism that allows binary software components, supplied by different software vendors, to connect to and communicate with each other in a well-defined manner. This mechanism is supplied by COM, a component software architecture that:
In addition, COM provides mechanisms for the following:
It is important to note that COM is a general architecture for component software. While Microsoft is applying COM to address specific areas such as controls, compound documents, automation, data transfer, storage and naming, and others, any developer can take advantage of the structure and foundation that COM provides.
How does COM enable interoperability? What makes it such a useful and unifying model? To address these questions, it will be helpful to first define the basic COM design principles and architectural concepts. In doing so, we will examine the specific problems that COM is meant to solve and how COM provides solutions for these problems.
The most fundamental question COM addresses is: How can a system be designed such that binary executables from different vendors, written in different parts of the world, and at different times are able to interoperate? To solve this problem, we have to find solutions to four specific problems:
Additionally, high performance is a requirement for a component software architecture. While cross-process and cross-network transparency is a laudable goal, it is critical for the commercial success of a binary component marketplace that components interacting within the same address space be able to utilize each other's services without any undue "system" overhead. Otherwise, the components will not realistically be scalable down to very small, lightweight pieces of software equivalent to C++ classes or graphical user-interface (GUI) controls.
The Component Object Model defines several fundamental concepts that provide the model's structural underpinnings. These include:
For any given platform (hardware and operating system combination), COM defines a standard way to lay out virtual function tables (vtables) in memory, and a standard way to call functions through the vtables. Thus, any language that can call functions via pointers (C, C++, Small Talk®, Ada, and even Basic) all can be used to write components that can interoperate with other components written to the same binary standard. The double indirection (the client holds a pointer to a pointer to a vtable) allows for vtable sharing among multiple instances of the same object class. On a system with hundreds of object instances, vtable sharing can reduce memory requirements considerably.
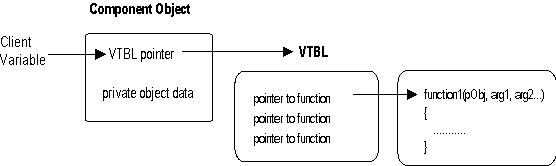
Figure 2. Diagram of a vtable
The word object tends to mean something different to everyone. To clarify, in COM, an object is some piece of compiled code that provides some service to the rest of the system. To avoid confusion, it is probably best to refer to a COM object as a "component object" or simply a "component." This avoids confusing COM objects with source-code object-oriented programming (OOP) objects such as those defined in C++. component objects support a base interface called IUnknown (described below), along with any combination of other interfaces, depending on what functionality the component object chooses to expose.
Component objects usually have some associated data, but unlike C++ objects, a given component object will never have direct access to another component object in its entirety. Instead, component objects always access other component objects through interface pointers. This is a primary architectural feature of the Component Object Model, because it allows COM to completely preserve encapsulation of data and processing, a fundamental requirement of a true component software standard. It also allows for transparent remoting (cross-process or cross-network calling) since all data access is through methods that can exist in a proxy object that forwards the request and vectors back the response.
In COM, applications interact with each other and with the system through collections of functions called interfaces. Note that all OLE services are simply COM interfaces. A COM interface is a strongly-typed contract between software components to provide a small but useful set of semantically related operations (methods). An interface is the definition of an expected behavior and expected responsibilities. OLE's drag-and-drop support is a good example. All of the functionality that a component must implement to be a drop target is collected into the IDropTarget interface; all the drag source functionality is in the IDragSource interface.
Interface names begin with "I" by convention. OLE provides a number of useful general purpose interfaces (which generally begin with "IOle"), but because anyone can define custom interfaces as well, we expect customers will develop their own interfaces as they deploy component-based applications. Incidentally, a pointer to a component object is really a pointer to one of the interfaces that the component object implements; this means that you can use a component object pointer only to call a method, but not to modify data, as described above. Here is an example of an interface ILookup with two member methods:
interface ILookup : public IUnknown
{
public:
virtual HRESULT __stdcall LookupByName( LPTSTR lpName,TCHAR **lplpNumber) = 0;
virtual HRESULT __stdcall LookupByNumber(LPTSTR lpNumber, TCHAR **lplpName) = 0;
};
Given that an interface is a contractual way for a component object to expose its services, there are four very important points to understand:
It is convenient to adopt a standard pictorial representation for objects and their interfaces. The adopted convention is to draw each interface on an object as a "plug-in jack."
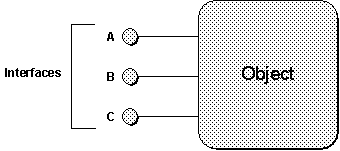
Figure 3. A typical picture of a component object that supports three interfaces A, B, and C.

Figure 4. Interfaces extend toward the clients connected to them.
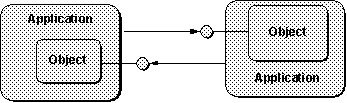
Figure 5. Two applications may connect to each other's objects, in which case they extend their interfaces toward each other.
The unique use of interfaces in COM provides five major benefits:
COM uses globally unique identifiers—128-bit integers that are guaranteed to be unique in the world across space and time—to identify every interface and every component object class. These globally unique identifiers are UUIDs (universally unique IDs) as defined by the Open Software Foundation's Distributed Computing Environment. Human-readable names are assigned only for convenience and are locally scoped. This helps ensure that COM components do not accidentally connect to "the wrong" component, interface, or method, even in networks with millions of component objects. CLSIDs are GUIDs that refer to component object classes, and IID are GUIDs that refer to interfaces. Microsoft supplies a tool (uuidgen) that automatically generates GUIDs. Additionally, the CoCreateGuid function is part of the COM API. Thus, developers create their own GUIDs when they develop component objects and custom interfaces. Through the use of defines, developers don't need to be exposed to the actual 128-bit GUID. For those who want to see real GUIDs in all their glory, the example below shows two GUIDs. CLSID_PHONEBOOK is a component object class that gives users lookup access to a phone book. IID_ILOOKUP is a custom interface implemented by the PhoneBook class that accesses the phonebook's database:
DEFINE_GUID(CLSID_PHONEBOOK, 0xc4910d70, 0xba7d, 0x11cd, 0x94, 0xe8, 0x08, 0x00, 0x17, 0x01, 0xa8, 0xa3);
DEFINE_GUID(IID_ILOOKUP, 0xc4910d71, 0xba7d, 0x11cd, 0x94, 0xe8, 0x08, 0x00, 0x17, 0x01, 0xa8, 0xa3);
The GUIDs are embedded in the component binary itself and are used by the COM system dynamically at bind time to ensure that no false connections are made between components.
COM defines one special interface, IUnknown, to implement some essential functionality. All component objects are required to implement the IUnknown interface, and conveniently, all other COM and OLE interfaces derive from IUnknown. IUnknown has three methods: QueryInterface, AddRef, and Release. In C++ syntax, IUnknown looks like this:
interface IUnknown {
virtual HRESULT QueryInterface(IID& iid, void** ppvObj) = 0;
virtual ULONG AddRef() = 0;
virtual ULONG Release() = 0;
}
AddRef and Release are simple reference counting methods. A component object's AddRef method is called when another component object is using the interface; the component object's Release method is called when the other component no longer requires use of that interface. While the component object's reference count is nonzero, it must remain in memory; when the reference count becomes zero, the component object can safely unload itself because no other components hold references to it.
QueryInterface is the mechanism that allows clients to dynamically discover (at run time) whether or not an interface is supported by a component object; at the same time, it is the mechanism that a client uses to get an interface pointer from a component object. When an application wants to use some function of a component object, it calls that object's QueryInterface, requesting a pointer to the interface that implements the desired function. If the component object supports that interface, it will return the appropriate interface pointer and a success code. If the component object doesn't support the requested interface, then it will return an error value. The application will then examine the return code; if successful, it will use the interface pointer to access the desired method. If the QueryInterface failed, the application will take some other action, letting the user know that the desired method is not available.
The example below shows a call to QueryInterface on the component PhoneBook. We are asking this component, "Do you support the ILookup interface?" If the call returns successfully, then we know that the component object supports the ILookup interface, and we've got a pointer to use to call methods contained in the ILookup interface (either LookupByName or LookupByNumber). If not, then we know that the component object PhoneBook does not implement the ILookup interface.
LPLOOKUP *pLookup;
TCHAR szNumber[64];
HRESULT hRes;
// Call QueryInterface on the component object PhoneBook, asking for a pointer
// to the Ilookup interface identified by a unique interface ID.
hRes = pPhoneBook->QueryInterface( IID_ILOOKUP, &pLookup);
if( SUCCEEDED( hRes ) )
{
pLookup->LookupByName("Daffy Duck", &szNumber); // use Ilookup interface pointer
pLookup->Release(); // finished using the IPhoneBook interface pointer
}
else
{
// Failed to acquire Ilookup interface pointer.
}
Note that AddRef is not explicitly called in this case because the QueryInterface implementation increments the reference count before it returns an interface pointer.
The Component Object Library is a system component that provides the mechanics of COM. The Component Object Library provides the ability to make IUnknown calls across processes; it also encapsulates all the "legwork" associated with launching components and establishing connections between components. Typically when an application creates a component object, it passes the CLSID of that component object class to the Component Object Library. The Component Object Library uses that CLSID to look up the associated server code in the registration database. If the server is an executable, COM launches the .EXE file and waits for it to register its class factory through a call to CoRegisterClassFactory (a class factory is the mechanism in COM used to instantiate new component objects). If that code happens to be a dynamic-link library (DLL), COM loads the DLL and calls DllGetClassFactory. COM uses the object's IClassFactory to ask the class factory to create an instance of the component object and returns a pointer to the requested interface back to the calling application. The calling application neither knows nor cares where the server application is run; it simply uses the returned interface pointer to communicate with the newly created component object. The Component Object Library is implemented in COMPOBJ.DLL for Windows and OLE32.DLL for Windows NT and Windows 95.
To summarize, COM defines several basic fundamentals that provide the underpinnings of the object model. The binary standard allows components written in different languages to call each other's functions. Interfaces are logical groups of related functions—functions that together provide some well-defined capability. IUnknown is the interface that COM defines to allow components to control their own life span and to dynamically determine another component's capabilities. A component object implements IUnknown to control its life span and to provide access to the interfaces it supports. A component object does not provide direct access its data. GUIDs provide a unique identifier for each class and interface, thereby preventing naming conflicts. And finally, the Component Object Library is implemented as part of the operating system and provides the "legwork" associated with finding and launching component objects.
Now that we've got a good understanding of COM's fundamental pieces, let's look at how these pieces fit together to enable component software.
COM addresses the four basic problems associated with component software:
In addition, COM provides a high-performance architecture to meet the requirements of a commercial component market.
Basic interoperability is provided by COM's use of vtables to define a binary interface standard for method calling between components. Calls between COM components in the same process are only a handful of processor instructions slower than a standard direct function call and no slower than a compile-time bound C++ object invocation.
A good versioning mechanism allows one system component to be updated without requiring updates to all the other components in the system. Versioning in COM is implemented using interfaces and IUnknown::QueryInterface. The COM design completely eliminates the need for things like version repositories or central management of component versions.
When a software module is updated, it is generally to add new functionality or to improve existing functionality. In COM, you add new functionality to your component object by adding support for new interfaces. Since the existing interfaces don't change, other components that rely on those interfaces continue to work. Newer components that know about the new interfaces can use those newly exposed interfaces. Because QueryInterface calls are made at run time without any expensive call to some "capabilities database" (as used in some other system object models), the current capabilities of a component object can be efficiently evaluated each time the component is used; when new features become available, applications that know how to use them will begin to do so immediately.
Improving existing functionality is even easier. Because the syntax and semantics of an interface remain constant, you are free to change the implementation of an interface, without breaking other developers components that rely on the interface. For example, say you have a component that supports the (hypothetical) IStack interface, which would include methods like Push and Pop. You've currently implemented the interface as an array, but you decide that a linked list would be more appropriate. Since the methods and parameters do not change, you can freely replace the old implementation with a new one, and applications that use your component will get the improved linked list functionality "for free."
Windows and OLE use this technique to provide improved system support. For example, in OLE today, structured storage is implemented as a set of interfaces which currently use the C run-time file input/output functions internally. In Windows 2000 (the next version of Windows NT), those same interfaces will write directly to the file system. The syntax and semantics of the interfaces remain constant; only the implementation changes. Existing applications will be able to use the new implementation without any changes; they get the improved functionality "for free."
The combination of the use of interfaces (immutable, well-defined "functionality sets" that are extruded by components) and QueryInterface (the ability to cheaply determine at run time the capabilities of a specific component object) enable COM to provide an architecture in which components can be dynamically updated, without requiring updates to other reliant components. This is a fundamental strength of COM over other proposed object models. COM solves the versioning/evolution problem where the functionality of objects can change independently of clients of that object without rendering existing clients incompatible. In other words, COM defines a system in which components continue to support the interfaces through which they provided services to older clients, as well as support new and better interfaces through which they can provide services to newer clients. At run time old and new clients can safely coexist with a given component object. Errors can only occur at easily handled times: bind time or during a QueryInterface call. There is no chance for a random crash such as those that occur when an expected method on an object simply does not exist or its parameters have changed.
Components can be implemented in a number of different programming languages and used from clients that are written using completely different programming languages. Again, this is because COM, unlike an object-oriented programming language, represents a binary object standard, not a source code standard. This is a fundamental benefit of a component software architecture over object-oriented programming (OOP) languages. Objects defined in an OOP language typically interact only with other objects defined in the same language. This necessarily limits their reuse. At the same time, an OOP language can be used in building COM components, so the two technologies are actually quite complementary. COM can be used to "package" and further encapsulate OOP objects into components for widespread reuse, even within very different programming languages.
It would be relatively easy to address the problem of providing a component software architecture if software developers could assume that all interactions between components occurred within the same process space. In fact, other proposed system object models do make this basic assumption. The bulk of the work in defining a true component software model involves the transparent bridging of process barriers. In the design of COM, it was understood from the beginning that interoperability had to occur across process spaces since most applications could not be expected to be rewritten as DLLs loaded into shared memory. Also, by solving the problem of cross-process interoperability, COM also solves the problem of components communicating transparently between different computers across a network, using the exact same programming interface used for components communicating on the same computer.
The Component Object Library is the key to providing transparent cross-process interoperability. As discussed in the last section, the Component Object Library encapsulates all the "legwork" associated with finding and launching components and managing the communication between components. As shown earlier, the Component Object Library insulates components from the location differences. This means that component objects can interoperate freely with other component objects running in the same process, in a different process, or across the network. The code you use to implement or use a component object in any case is exactly the same. Thus, when a new Component Object Library is released with support for cross-network interaction, existing component objects will be able to work in a distributed fashion without requiring source-code changes, recompilation, or redistribution to customers.
COM is designed to allow clients to transparently communicate with components regardless of where those components are running, be it the same process, the same machine, or a different machine. What this means is that there is a single programming model for all types of component objects for not only clients of those component object, but also for the servers of those component objects.
From a client's point of view, all component objects are accessed through interface pointers. A pointer must be in-process, and in fact, any call to an interface function always reaches some piece of in-process code first. If the component object is in-process, the call reaches it directly. If the component object is out-of-process, then the call first reaches what is called a "proxy" object provided by COM itself, which generates the appropriate remote procedure call to the other process or the other machine. Note that the client from the start should be programmed to handle RPC exceptions; then it can transparently connect to an object that is in-process, cross-process, or remote.
From a server's point of view, all calls to a component object's interface functions are made through a pointer to that interface. Again, a pointer only has context in a single process, and so the caller must always be some piece of in-process code. If the component object is in-process, the caller is the client itself. Otherwise, the caller is a "stub" object provided by COM that picks up the remote procedure call from the "proxy" in the client process and turns it into an interface call to the server component object.
As far as both clients and servers know, they always communicate directly with some other in-process code, as illustrated in Figure 6.
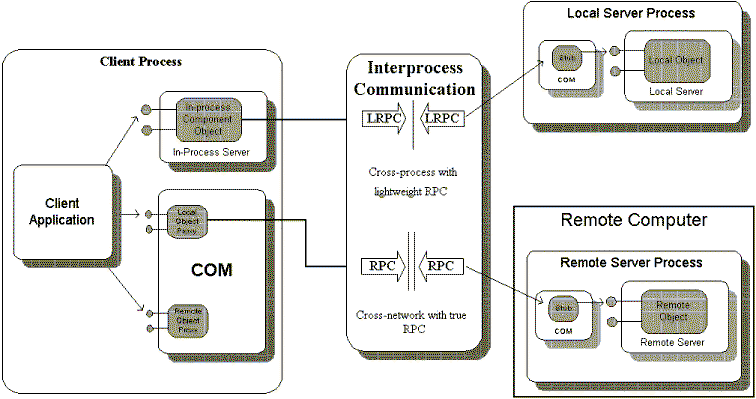
Figure 6. Clients always call in-process code; component objects are always called by in-process code. COM provides the underlying transparent RPC.
The bottom line is that dealing with local or remote component objects is transparent and identical to dealing with in-process component objects. This local/remote transparency has a number of key benefits:
The interaction between component objects and the users of those component objects in COM is in one sense based on a client/server model. We have already used the term "client" to refer to some piece of code that is using the services of an component object. Because a component object supplies services, the implement of that component is usually called the "server"—the component object that serves those capabilities. A client/server architecture in any computing environment leads to greater robustness: If a server process crashes or is otherwise disconnected from a client, the client can handle that problem gracefully and even restart the server if necessary. As robustness is a primary goal in COM, a client/server model naturally fits. Because COM allows clients and servers to exist in different process spaces (as desired by component providers), crash protection can be provided between the different components making up an application. For example, if one component in a component-based application fails, the entire application will not crash. In contrast, object models that are only in-process cannot provide this same fault tolerance. The ability to cleanly separate object clients and object servers in different process spaces is very important for a component software standard that promises to support sophisticated applications.
But unlike other object models we know of, COM is unique in allowing clients to also represent themselves as servers. In fact, many interesting designs have two (or more) components using interface pointers on each other, thus becoming clients and servers simultaneously. In this sense, COM also supports the notion of peer-to-peer computing and is quite different and, we think, more flexible and useful than other proposed object models where clients never represent themselves as objects.
In general a "server" is some piece of code that implements some component object such that the Component Object Library and its services can run that code and have it create component objects.
Any specific server can be implemented in one of a number of flavors depending on the structure of the code module and its relationship to the client process that will be using it. A server is either "in-process," which means its code executes in the same process space as the client (as a DLL), or "out-of-process," which means it runs in another process on the same machine or in another process on a remote machine (as a .EXE file). These three types of servers are called "in-process," "local," and "remote."
Component object implementers choose the type of server based on the requirements of implementation and deployment. COM is designed to handle all situations from those that require the deployment of many small, lightweight in-process components (like OLE Controls, but conceivably even smaller) up to those that require deployment of a huge components, such as a central corporate database server. And as discussed, all component objects look the same to client applications, whether they are in-process, local, or remote.
When a developer defines a new custom interface, he can create an interface definition using the interface definition language (IDL). From this interface definition, the Microsoft IDL compiler generates header files for use by applications using that interface, source code to create proxy, and stub objects that handle remote procedure calls. The IDL used and supplied by Microsoft is based on simple extensions to the Open Software Foundation distributed computing environment (DCE) IDL, a growing industry standard for RPC-based distributed computing.
IDL is simply a tool for the convenience of the interface designer and is not central to COM's interoperability. It really just saves the developer from manually creating header files for each programming environment and from creating proxy and stub objects by hand. Note that IDL is not necessary unless you are defining a custom interface for an object; proxy and stub objects are already provided with the Component Object Library for all COM and OLE interfaces. Here is the IDL file used to define the custom interface, ILookup, which is implemented by the PhoneBook object:
[
object,
uuid(c4910d71-ba7d-11cd-94e8-08001701a8a3), // Use the GUID for the Ilookup interface
pointer_default(unique)
]
interface ILookup : IUnknown // ILookUp interface derives from IUnkown
{
import "unknwn.idl"; // Bring in the supplied IUnkown IDL
// Define member function LookupByName:
HRESULT LookupByName( [in] LPTSTR lpName, [out, string] WCHAR **lplpNumber);
// Define member function LookupByNumber:
HRESULT LookupByNumber( [in] LPTSTR lpNumber, [out, string] WCHAR ** lplpName);
}
COM is not a specification for how applications are structured: It is a specification for how applications interoperate. For this reason, COM is not concerned with the internal structure of an application—that is the job of programmer and also depends on the programming languages and development environments used. Conversely, programming environments have no set standards for working with objects outside of the immediate application. C++, for example, works extremely well with objects inside an application, but has no support for working with objects outside the application. Generally, other programming languages are the same. COM, through language-independent interfaces, picks up where programming languages leave off, providing network-wide interoperability of components to make up an integrated application.
The core of the Component Object Model is a specification for how components and their clients interact. As a specification, it defines a number of other standards for interoperability of software components:
In addition to being a specification, COM is also an implementation contained in the Component Object Library. The implementation is provided through a library (such as a DLL on Microsoft Windows/Windows NT) that includes:
In general, only one vendor needs to—or should—implement a COM Library for any particular operating system. For example, Microsoft is implementing COM on Windows, Windows NT, and the Apple Macintosh. Other vendors are implementing COM on other operating systems, including specific versions of UNIX. Also, it is important to note that COM draws a very clean distinction between:
Therefore, developers are not constrained into new and specific models for the services of different operating systems, yet they can develop components that interoperate with components on other platforms.
All in all, only with a binary standard on a given platform and a wire-level protocol for cross-machine component interaction can an object model provide the type of structure necessary for full interoperability between all applications and among all different machines in a network. With a binary and network standard, COM opens the doors for a revolution in innovation without a revolution in programming or programming tools.
Implementation inheritance—the ability of one component to "subclass" or inherit some of its functionality from another component—is a very useful technology for building applications. Implementation inheritance, however, can create many problems in a distributed, evolving object system.
The problem with implementation inheritance is that the "contract" or relationship between components in an implementation hierarchy is not clearly defined; it is implicit and ambiguous. When the parent or child component changes its behavior unexpectedly, the behavior of related components may become undefined. This is not a problem when the implementation hierarchy is under the control of a defined group of programmers who can make updates to all components simultaneously. But it is precisely this ability to control and change a set of related components simultaneously that differentiates an application, even a complex application, from a true distributed object system. So while implementation inheritance can be a very good thing for building applications, it is not appropriate for a system object model that defines an architecture for component software.
In a system built of components provided by a variety of vendors, it is critical that a given component provider be able to revise, update, and distribute (or redistribute) his product without breaking existing code in the field that is using the previous revision or revisions of his component. In order to achieve this, it is necessary that the actual interface on the component used by such clients be crystal clear to both parties. Otherwise, how can the component provider be sure to maintain that interface and thus not break the existing clients?
From observation, the problem with implementation inheritance is that it is significantly easier for programmers not to be clear about the actual interface between a base and derived class than it is to be clear. This usually leads implementers of derived classes to require source code to the base classes; in fact, most application framework development environments that are based on inheritance provide full source code for this exact reason.
The bottom line is that inheritance, while very powerful for managing source code in a project, is not suitable for creating a component-based system where the goal is for components to reuse each other's implementations without knowing any internal structures of the other objects. Inheritance violates the principle of encapsulation, the most important aspect of an object-oriented system.
The following C++ example illustrates the technical heart of the robustness problem:
class CBase
{
public:
void DoSomething(void) { ... if (condition) this->Foo(); ...}
virtual void Foo(void);
};
class CDerived : public CBase
{
public:
virtual void Foo(void);
};
This is the classic paradigm of reuse in implementation inheritance: A base class periodically makes calls to its own virtual functions, which may be overridden by its derived classes. In practice in such a situation, CDerived can become—and therefore often will become—intimately dependent on exactly when and under what conditions Foo will be invoked by the class CBase.
If, presently, all such Foo invocations by CBase are intended long term as hooks for the derived class, there is no problem. There are two cases, however. Either the implementation of CBase::Foo is implemented as:
void CBase::Foo(void)
{
//Do absolutely nothing
}
or it is not empty.
If the implementation of CBase::Foo is not empty, it is carrying out some useful and likely needed transformation on the internal state of CBase. Thus, it is very questionable whether all of the invocations of Foo are for the support of derived classes; some of them instead are likely to be only for the purpose of carrying out this transformation. That transformation is part of current implementation of CBase.
Thus, in summary, CDerived becomes coupled to details of that current implementation of CBase; the interface between the two is not clear and precise.
Further coupling comes from the fact that the implementation of CDerived::Foo, in addition to performing its own role, must be sure to carry out the transformation carried out in CBase::Foo. It can do this by itself, reimplementing the code in CBase::CBase, but this causes obvious coupling problems. Alternatively, it can itself invoke the CBase::Foo method:
void CDerived::Foo(void)
{
[Do some work]
...
CBase::Foo();
...
[Do other work]
}
However, it is very unclear what is appropriate or possible for CDerived to do in the areas marked "Do some work" and "Do other work." What is appropriate depends, again, heavily on the current implementation of CBase::Foo.
If, in contrast, CBase::Foo is empty, we are not likely in immediate danger of surreptitious coupling. In the implementation of CBase, invoking Foo clearly serves no immediately useful purpose, and so it is likely that, indeed, all invocations of Foo in CBase are only for the support of CDerived. Consider, however, the case that the CDerived class is reused:
class CAnother : public CDerived
{
public:
virtual void Foo(void);
};
Though CBase::Foo had a trivial implementation, CDerived::Foo will not. (Why override it if otherwise?) The relationship of CAnother to CDerived thus becomes as problematic as the CDerived-CBase relationship in the previous case.
This is the architectural heart of the problem observed in practice that leads to a view that implementation inheritance is unacceptable as the mechanism by which independently developed binary components are reused and refined.
COM provides two other mechanisms for code reuse called containment/delegation and aggregation. Both of these reuse mechanisms allow objects to exploit existing implementation while avoiding the problems of implementation inheritance. See "Appendix 2: COM Reusability Mechanisms" of this article for an overview of these alternate reuse mechanisms.
The key point to building reusable components is black-box reuse, which means the piece of code attempting to reuse another component knows nothing—and does not need to know anything—about the internal structure or implementation of the component being used. In other words, the code attempting to reuse a component depends upon the behavior of the component and not the exact implementation. As illustrated in "Appendix 1: The Problem with Implementation Inheritance," implementation inheritance does not achieve black-box reuse.
To achieve black-box reusability, COM supports two mechanisms through which one component object may reuse another. For convenience, the object being reused is called the inner object and the object making use of that inner object is the outer object.
These two mechanisms are illustrated in Figures 7 and 8. The important part to both these mechanisms is how the outer object appears to its clients. As far as the clients are concerned, both objects implement interfaces A, B, and C. Furthermore, the client treats the outer object as a black box, and thus does not care, nor does it need to care, about the internal structure of the outer object—the client only cares about behavior.
Containment is simple to implement for an outer object. The process is like a C++ object that itself contains a C++ string object. The C++ object would use the contained string object to perform certain string functions, even if the outer object is not considered a string object in its own right.
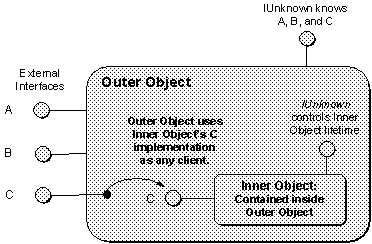
Figure 7. Containment of an inner object and delegation to its interfaces
Aggregation is almost as simple to implement. The trick here is for COM to preserve the function of QueryInterface for component object clients even as an object exposes another component object's interfaces as its own. The solution is for the inner object to delegate IUnknown calls in its own interfaces, but also allow the outer object to access the inner object's IUnknown functions directly. COM provides specific support for this solution.
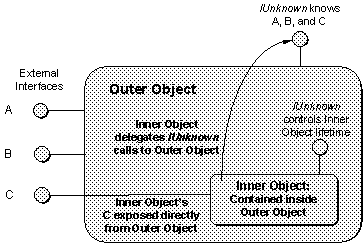
Figure 8. Aggregation of an inner object where the outer object exposes one or more of the inner object's interfaces as its own.
Note The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.