Robert Coleridge, Steve Kirk, Kevin Marzec, and Dale Smith
MSDN Content Development Group
February 1998
Midstream Design Changes for the HelpDesk Sample
MTS Deployment
Developing the HelpDesk Setup and Deployment
New Guy+Existing Project=New Challenges
by Robert Coleridge
When we first envisioned the HelpDesk sample, we saw a great use for the Telephony API (TAPI). Users would make requests for help by telephone, the request would be stored in a voice mail system, and then transcribed into a formal (textual) help request. Unfortunately, the changing state of the technology forced us to make a hard decision.
Because TAPI 2.1 was not developed along COM architectural lines, we decided that we would encapsulate TAPI 2.1 and create our own COM object for use with the HelpDesk sample. However, during development of this object, TAPI 3.0, fully COM-compliant, was announced and unveiled at the Professional Developer's Conference (PDC). We had to look seriously at whether or not to continue with our own model. HelpDesk is meant as a sample of technologies and methodologies that developers can use; with TAPI 3.0 near release, we realized that encapsulating TAPI 2.1 would not be the best use of our time, nor would it benefit our readers.
With this in mind we had to go back and remove code for voice storage and manipulation. The code to do this is fairly straightforward and would be easy to implement once TAPI 3.0 becomes available.
A project design must take into account changing technology. Any project that tries to keep up with technology will never be implemented. It is best to select a technology and implement it. This is assuming that the technology serves the required purpose and does not need to be "forced" into the project. If a technology must be forced into a project then it is either the wrong technology, or the project design needs to change. In our case we changed the design.
During development of the HelpDesk sample we realized that our self-expanding object model was not efficient enough for the project. Often, objects either needed more or less expansion than our model allowed. We had to go back and redesign the object expansion.
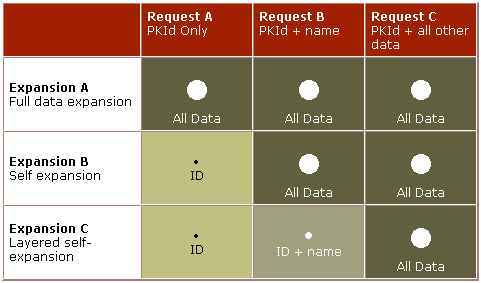
First, let me review the types of expanding objects: the fully expanding, the self-expanding, and what we came up with, the layered self-expanding object (Figure 1).
A fully expanded object carries all of its data with it, from instantiation to destruction. No matter how the data is retrieved, whether the object has a few simple atomic members or several thousand objects in collections, all the data is contained within the object. This type is great for speed of data access, unfortunately it is deadly when it comes to memory and network resources.
When a self-expanding object is instantiated, it only carries the information necessary to fully populate itself when its data is actually needed. Because it delays the actual self-population until necessary, the self-expanding object is much leaner than the fully-expanded object. This design has the advantage of less bulk to slow down the network, but it takes two hits to the database to fully populate the object. Once again, it is a tradeoff: speed or resources.
As a solution we developed a layered self-expanding object model. This differs from the "self-expanding" model only in when the expansion takes place and how much data is expanded at each layer. The layers are defined at design time and could be n layers deep.
For an example, let's look at the CTech object as it was originally implemented in the HelpDesk sample. When a technician object (CTech) was created from a database record, the object contained the Primary Key Id (PKId) of it's associated record. If the user requested any other data (such as Email alias), the entire record was pulled into the object and expanded.
To give the object a layered expansion, we have the initial loading of the object store the PKId of the technician record. When the technician's email alias, skill, or location records is requested the object is only partially expanded. The other fields ( for example, the collection of requests) are not contained in the object until they are requested, at which point the object is fully populated.
This design has the advantage of even less bulk to slow down the network, but it also takes three trips to the database to fully populate the object. Again, it is a case of speed vs. resources.
This model does take some extra work at the design phase but the improvements later on are definitely worth the effort.
Figure 1. Three types of expanding objects
Early in the design process we decided to use smart objects. As we moved through the project we began to realize that our sample, which was partially web oriented, needed thinner objects. With this in mind, we went back and turned our bulky smart objects into thinner dumb ones.
A dumb object is a simple part, destined for a greater whole (rather Zen, wouldn't you say!). It contains data only (and possibly constructor/destructor methods). The object does not contain any operational code and must be "cared" for by a larger administrative object, which manages the object and manipulates its data. Usually, the dumb object is created outside of the Administrator object.
If these objects are so dumb then why use them? Good question. Since the object carries data only, they are thinner than objects that contain code necessary to manipulate that data. Hence, they are ideal for Web or high-volume applications.
When should smart objects be used? When you want objects that can be "torn off" from somewhere and used on their own. This is their greatest strength, but it is also their greatest weakness. Due to the extra contained code, the smart object tends to be bulkier than its dumb object cousin. In a scenario where network bandwidth is high or the volume of objects transferred is low, smart objects could be the way to go. When there is going to be significant network traffic, you should consider the smaller, lighter "dumb objects."
by Steve Kirk
The HelpDesk API hides transaction details from all parts of the application except the business and data services layers. In fact, the only difference, above the business layer, between the Microsoft Transaction Server (MTS) and Non-MTS versions of the application is in the naming of the two component families. This version similarity allowed us to develop the bulk of the application using the Non-MTS version with the expectation that there would be few surprises when deploying the MTS version as a distributed application. When we finally tested the system under MTS we had a couple of surprises, which I’ll cover here.
By misinterpreting the meaning of controls in the Transaction Server Explorer user interface (MTS Version 1.1), I created an easy-to-remedy but effective show stopper that prevented the client applications from instantiating remote objects. You won’t encounter this problem if you follow the instructions for setting up an MTS package in "MSDN HelpDesk Sample Installation" to the letter, but if you use those instructions only as a general guide, you may repeat my experience.
The HelpDesk server setup installs components that provide data and business services on the computer. You then use the Transaction Server Explorer to create a package that contains these components (based on your distribution scenario) and you export the package so that it can be installed on remote computers.
I made the mistake when I added components to the package. The two available options are to Install new component(s) or to Import component(s) that are already registered. I reasoned that either option would result in an equivalent package since the components were installed on the computer on which I built the package. I thought that either method of selection would cause MTS to extract the type library data from the component and to add this type library to the package. However, I found that importing does not examine the components to get type library information (even for local components) and that the resulting package only allows a remote client to instantiate objects using late binding. Check for this error if you receive "can’t create object" errors from HelpDesk MTS clients.
The next surprise is more interesting for developers of MTS components in Visual Basic because it involves API architecture, Visual Basic data types, COM, and MTS. I found that a few methods failed in the MTS versions while, in the non-MTS versions, everything worked fine. As Fred Pace explains in "Designing the Transaction-Processing Object Model for the HelpDesk," the HelpDesk components use dynamic arrays as data containers that are passed between objects. When the workflow object needs data, it passes an array by reference to the business layer object which, in turn, passes the array on to the data-access layer where it is resized and filled with data. I found that the failures were limited to code that expands technician and user objects in multiple stages. See Robert Coleridge’s discussion of self expanding objects. The technician objects within the collection returned by HDClient.CAdmin.GetTechnicians are initially populated with only the PKId of the corresponding technician. Property get procedures on the technician test for and trigger object expansion as required. Two stages of expansion are used: the first stage populates the primary properties of the technician (alias, skill and location) and the second stage populates the collection of requests assigned to the technician. The refresh procedure performs this property population at the depth specified by the bExpandFull parameter. The following code segment shows that he sData() array is filled by GetTech() and, if necessary, it is resized and filled by GetRequests(). The code was failing on the second call to oTrans during a full expansion. The problem ceased when I eliminated the ReDim array before the second oTrans call.
Private Sub Refresh(bExpandFull As Boolean)
Dim oTrans As HDServer.CTrans
Dim oReq As CRequest
Dim sData() As String
…
‘ Initialize object properties
Clear
‘ Get business services object
Set oTrans = New HDServer.CTrans
‘ Get first stage data and populate member variables
If oTrans.GetTech(m_lPKId, sData) Then
m_lLocId = CLng(sData(icTechLocId, icZeroDim))
m_lSkillId = CLng(sData(icTechSkillId, icZeroDim))
m_sAlias = Trim$(sData(icAlias, icZeroDim))
‘ Perform second stage expansion if requested
If If bExpandFull Then
‘ Initialize Details list
Set m_cReqs = New Collection
‘ Resize the array (causes GetRequests to fail under MTS)
ReDim sData(0)
‘ Get request data and populate list
If oTrans.GetRequests(m_lPKId, sData) Then
…
End Sub
Although the array is owned in one way by the refresh procedure (due to scope), the array is resized by an object under MTS. Because the ByRef array is modified within the scope of an MTS transaction, the refresh procedure loses ownership of the right to resize the array. Although coding conventions often call for explicitly initializing a variable before each use even where this leads to multiple initializations, this situation, where the size of the array is determined from within component code under MTS, dictate that you only resize at the layer of the object within MTS rather than from either place.
by Kevin Marzec
While putting the HelpDesk setup program together, we ran into some areas that caused us problems. The first, involving Microsoft Transaction Server, was probably the easiest to overcome, as most of the issues dealt with user error more than anything else. When building an MTS application, I highly recommend reading the MTS documentation, especially those topics about package creation and export. Here are a few tips and tricks for the uninitiated:
We also ran into some difficulties with the registry, that mystical place that can unreservedly bring your system to a halt if you don't treat it right. Before you reregister a component, you want to be sure that you first remove any existing registry entries associated with it, especially if you are registering it through Microsoft Transaction Server, and even more especially if you are registering it through an exported MTS package. Components registered through an exported package will have an entry in the Add/Remove Programs utility of the Control Panel. This entry, listed as Remote Applications—<package name>, is created when you execute an MTS package. Using the Add/Remove Programs utility to remove a component will clear it from the registry.
However, even the best of us make mistakes every now and then, and the kind folks at Microsoft have invented a nifty little utility that will help you deal with mangled registry situations. REGBACK is included in the Microsoft Windows NT® Resource Kit. It will back up your registry so that, in case of problems with configuration, you can restore it and try again. In general, as with any critical data, it is a good idea to back up your registry often, especially before you install and test applications whose stability may be unknown.
Imagine that you have built your application and have created and run a setup program for it. You attempt to run the application and you receive an error such as "Error 046 – ActiveX component can't create object". And the application closes. Before you run screaming out into the night, there are a few things you can try. (However, remember that prevention is the best cure, and there is nothing like good error handling and reporting to avoid cases like this.)
Even a problem as ambiguous as this can be dealt with in a rational way. It is often difficult to distinguish between a configuration problem and a "real" bug (application problem). When in doubt, use Microsoft Visual Basic® to walk through the code and see where the failure is occurring. The easiest way to do this is to create a new project that will instantiate a top-level object as follows:
Private Sub Form_Load()
Dim oAdmin As New CAdmin
Dim oTech As CTech
For Each oTech In oAdmin.GetTechnicians
Debug.Print oTech.Alias
Next
End Sub
Next, add each of the components to this project (making sure that your references are set correctly), and step through it. When doing this, make sure that you are not using MTS-based components. Because MTS requires that MTS-aware objects be instantiated within the MTS process space, attempting to create an MTS object while in Visual Basic design mode will cause an error. In order to step through the HelpDesk source code in design mode, you must use the non-MTS code.
In the case of the HelpDesk sample application, there is a bUseMTS compiler flag, which, when set to 0, will disable MTS from your code. If you disable MTS from your code and everything runs flawlessly, the problem is most likely due to a misconfiguration of one or more of your MTS components. However, if you still get the same problem as before, you can walk through the code step by step and determine what is failing. Hopefully this method will isolate any problem that you are having. If it doesn't, maybe running screaming out into the night isn't such a bad idea after all.
by Dale Smith
A new team member has many issues to deal with, like locating the lunchroom or, for that matter, figuring out how to get out of the building when it is time to go home. Add to that, coming in late in the development cycle of an existing project, and the task can seem daunting. Well, I recently joined the MSDN Content Development team toward the end of development of the HelpDesk sample. This created some very interesting and maybe not so unique challenges. I needed to learn new technologies. I needed to learn new methodologies and approaches to design. I needed to become familiar with the existing project and coding standards. And I needed to learn it all yesterday.
Coming late into the development cycle of a project requires you to quickly learn unfamiliar technologies. In trying to come up to speed, I discovered that I faced two obstacles. First, I only had time to skim through books while gleaning the most important points. Second, the other developers were busy with their own issues and didn't have time to spend on my "learning curve." This meant that I had to learn from the existing code, using the project itself as a textbook.
One of the best resources for learning new technologies is other developers' code. Keep an open mind as you view the code and learn from the experience of other people; and be careful not to arrogantly criticize the techniques used in a belief that some things could be done better. Remember that while you are coming in with a set of technologies that you are comfortable with, you may not completely understand the needs of the project.
For someone who has spent a considerable amount of time developing desktop applications, entering the emerging world of distributed computing via the Internet requires a whole new way of thinking. A client-server design on one or two machines is one thing, but a distributed component architecture, or n-tier design, is a different one altogether. After spending some time looking at the HelpDesk code it became clear that there were four distinct components or layers. What I discovered could help you understand this new development paradigm. You could look at these as if you were peeling layers from an onion. The outer layer is the presentation layer or what the user sees. The next layer, or workflow layer, acts as the middleman between the next layer down, the business layer, and the presentation layer. The workflow layer determines what is required in order for an operation to be completed. It contains the rules that determine what parameters are passed to the business layer to be able to process a request. The next layer, or business logic layer, determines how the request is to be handled. It contains the rules that validate the parameters used to process the request. And finally, the bottom data layer "talks" to the database, retrieving and making changes to the data. This layered approach helps to isolate the components and make development easier by separating the components into manageable self-contained units that can be distributed among several computers across a network or around the world.
In trying to adapt quickly to the team, some old habits needed to be changed quickly. Inheriting someone else's code required me to adapt my coding technique to what had already been written. Again, using the other parts of the project as a guide allowed me to adapt and discover what needed to be done to the code I was working on.
No matter when you join a project, timing is critical. It's easy to get distracted by going off on tangents—there are a lot of new and exciting technologies out there. Don't take time from the existing project to chase after them. Define your goals clearly and focus your attention strictly on achieving them. As with any venture, the best approach is to plan ahead and proceed with attainable goals. Above all, be open minded and enjoy the experience!