Robert Coleridge
MSDN Content Development Group
August 1997
Updated: February 2, 1998
Many organizations today want to incorporate the concept of the World Wide Web into an internal Web, or intranet, yet are held back, not by a lack of technology, but by a lack of good examples of Web-based applications. The HelpDesk sample is designed to demonstrate how to put together a Web-based application that is fast, practical, and fully extensible.
The HelpDesk sample implements a problem-resolution system based on three steps. The first step involves the user entering a request for help into the system. The second step involves the automated determination and assignment of an appropriate technician to the request, and the third step involves the response cycle required to bring the request to resolution.
The HelpDesk sample follows the layered-paradigm approach. There are four layers to this sample:
This sample, developed using Microsoft Visual Studio, uses Microsoft® Transaction Server to manage the transaction processing, Microsoft SQL Server™ for database management, Microsoft Internet Information Server, and Microsoft Windows NT® 4.0. Additionally, the following "glue" technologies are used:
Although there are many problem-resolution systems available, this sample uses a Web-based system and an object-oriented approach, enhanced by "glue" technologies, to demonstrate how to simplify some reasonably complex problem-resolution tasks.
This system is designed such that, with a few minor modifications, it could easily be used as a bug tracking system. In such a system, the help request becomes the bug report, and the technician becomes the developer.
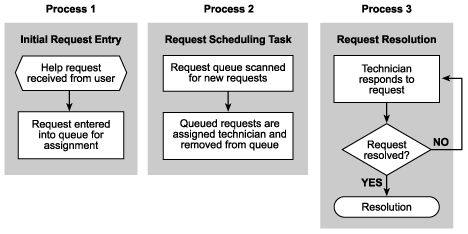
The HelpDesk sample can be broken down into three distinct processes:
These processes are illustrated in Figure 1.
Figure 1. Processes
By using a system status or control table and by monitoring certain values dynamically, we can dynamically affect any of the system's processes. We could, for instance, suspend any step, perform some maintenance function, update a module, and then resume that step and the user would not notice any interruption—all by merely setting flags in the table.
As the system is running, it accumulates performance and resolution statistics. The HelpDesk sample is set up to accumulate the following:
As requests are made and resolved, a knowledge base of resolutions is accumulated. The technician could point a requestor, via a request's tracking number, to a previous request/resolution scenario, if appropriate.
Figure 2 provides a detailed diagram of the first process of the HelpDesk sample. Note that we have not specified how the request gets into the system. The actual method of entering data is open-ended. What the HelpDesk sample provides, as a sample, is several possible forms of input. The request could come from a Web page, from a stand-alone application, etc. In the diagram, there are several gray boxes; these indicate other possible input methods.
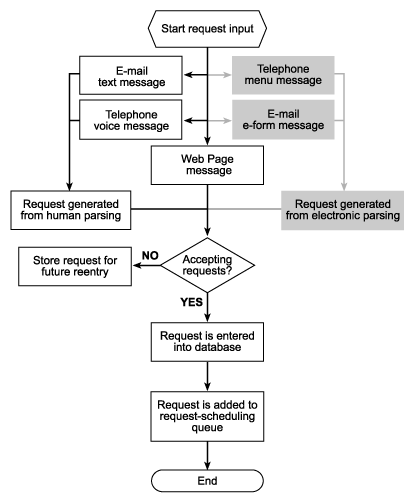
Figure 2. Input
Note that half way through this process there is a check to see whether requests are being accepted. If requests are not being accepted, they are stored for future retrieval. If requests are being processed, the request is entered into the request table and a request-queue record is generated. The request queue holds all outstanding requests and is scanned periodically by the scheduling task.
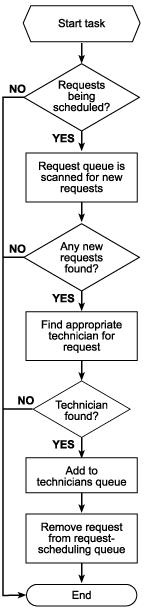
Figure 3. Assignment and scheduling
Once a request is entered into the system and has entered the request queue, that request is available for scheduling. This process assumes that all records in the request queue have not been scheduled.
For the purposes of the HelpDesk sample, the scheduling process takes into account the following factors when assigning a technician:
Once the request has been matched with an appropriate technician, the request is removed from the request queue. If for any reason the request queue were destroyed, it could be rebuilt simply by scanning the request data for unresolved requests.
This process is the core of the HelpDesk sample. A request may be resolved in a single technician call or it may require multiple interactions with the requestor. At some point, the technician flags the request as resolved. A parallel set of steps then occurs: the system sends out a confirmation request, and it starts an internal confirmation-received timer. The request is closed when the requestor sends back confirmation of the resolution or when the predetermined time expires.
If the requestor sends back a negative confirmation, further action is undertaken to resolve the request and the above steps are taken again. This process is shown in Figure 4.
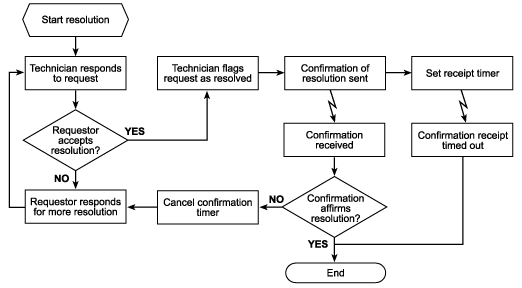
Figure 4. Resolution
Be sure to read all the articles in the HelpDesk series, check out the source code, and of course, install the sample and play around with it.