July 11, 1998
Surajit Chaudhuri and Vivek Narasayya
Microsoft Corporation
Enterprise-class databases require database administrators (DBAs), who are responsible for performance tuning. One important task of a DBA is selecting a physical database design that is appropriate for the system workload. An important component of physical database design is selecting indexes. The index selection problem has been studied from the early 70s and the importance of the problem is widely acknowledged. In data-intensive applications, such as decision support and data warehousing, choosing the right set of indexes becomes crucial for performance. Moreover, the indexes chosen should track changes in the system workload.
In this white paper, we describe the Index Tuning Wizard for Microsoft® SQL Server™ 7.0, which automates this challenging administrative task while achieving performance competitive with that of manually indexed systems. The tool, conceived in the AutoAdmin research project at Microsoft, is the result of collaborative work with the SQL Server group. The goal of the AutoAdmin research project is to develop technology to build database systems with greatly reduced administration overhead and total cost of ownership.
Despite a long history of work in the area of index selection, there are no significant commercial automatic index selection products that are widely deployed. Several factors make the task of automating physical design extremely difficult. When viewed as a search problem, the space of alternatives for indexes is very large. A database may have many tables and each table may have many columns that need to be considered for indexing. An index may be clustered or nonclustered. Indexes may have different physical structures, such as B-tree, hash, or bitmap. When multicolumn indexes are considered, the search space increases even more dramatically, because for a given set of k columns, k! multicolumn indexes are possible.
Also, index selection tools of the past have frequently followed the "textbook solution" of taking semantic information, such as uniqueness, reference constraints, and rudimentary statistics ("small" versus "big" tables), to produce a database design. (For more information, see References at the end of this article.) Such designs may perform poorly because they ignore valuable workload information.
Even when index selection tools have taken the workload into account, they suffer from being disconnected from the query optimizer (for more information, see "References"). These tools adopt an expert-system–like approach, where the knowledge of "good" designs is encoded as rules and is used to come up with a design. This has adverse ramifications for two reasons. First, a selection of indexes is only as good as the optimizer that uses it. In other words, if the optimizer does not consider a particular index for a query, then its presence in the database does not benefit that query. Second, these tools operate on their private model of the query optimizer's index usage. While making an accurate model of the optimizer is difficult, ensuring consistency between the assumptions made by the tool and the query optimizer is a software-engineering nightmare. As we will explain, our tool uses the optimizer's cost estimate for the workload as the metric for comparing alternative designs, and sidesteps the above problem.
Finally, modern query optimizers use more complex strategies, such as index intersection and index-only access ("covered queries"). If an index selection tool does not take into account these properties of the optimizer, it can result in gross inefficiencies and poor quality of design.
In this section we describe the functionality of the Index Tuning Wizard that ships with the Beta 2 release of SQL Server 7.0. The tool takes as input a workload and recommends a set of indexes for the given workload. A workload may consist of one or more SQL statements (for example, SELECT, UPDATE, INSERT, DELETE). Therefore, when the tool starts up, it requests the user to provide a workload file as input. Such a workload file can be generated by logging activity on the database server over a period of time, using a utility like SQL Server Profiler. A workload file can also be "manually generated" by typing a set of queries (separated by the delimiter GO) into a .sql file. The tool reports the expected change in performance of the workload and the expected change in storage cost if the recommended indexes are created. If the user accepts the recommendation, the index creation/alteration step can be initiated immediately or can be scheduled at a specific date and time.
The Index Tuning Wizard can be customized in several ways, depending on the requirements of the user. One way to customize the tool is to specify which tables should be considered for indexing. This allows the user to focus the design on selected tables in the database without altering the indexes for the remaining tables. Another parameter that can be controlled by the user is the total amount of storage consumed by indexes recommended by the tool. The tool picks a set of indexes such that this storage constraint is not violated.
In the Beta 2 release of SQL Server 7.0, the Index Tuning Wizard can be activated in several ways. It can be launched from SQL Server Enterprise Manager or SQL Server Profiler by selecting the Index Tuning Wizard. The tool can also be run from SQL Server Query Analyzer, by selecting a query on the screen and choosing Perform Index Analysis under the Query menu. In this case, indexes are suggested only for the chosen query. In the future releases of the tool, it will be possible to perform more sophisticated quantitative analysis on the workload and the recommendations made by the Index Tuning Wizard. For example, the user will be able to compare the cost of an individual query for the current set of indexes with the proposed set of indexes. It will also be possible to estimate the expected index usage with the proposed set of indexes.
Because the index recommendations are made with respect to a workload, it is important to pick a workload that is representative of database system usage. Tools such as SQL Server Profiler can help the user generate such a workload by logging activity on the server over a specified period of time. For efficient use of the Index Tuning Wizard, make sure that the representative workload does not contain events or queries that are unnecessary or inappropriate. Another way to gain efficiency is to consider restricting the Index Tuning Wizard to recommend indexes over selected tables without considering any changes to indexes on the remaining tables. If you are interested in knowing what indexes to add to improve the performance of a single query, you should launch the Index Tuning Wizard through SQL Server Query Analyzer. Thus, by ensuring that the representative workload contains only the necessary queries and by launching the Index Tuning Wizard in the appropriate mode (as described earlier), the execution of the Index Tuning Wizard can be focused to the needs of the system administrator. Because the performance of the system can degrade if workload characteristics change over time, it is advisable to rerun the Index Tuning Wizard periodically. Finally, because the optimizer's cost estimate is only an approximation of the true execution cost, it is possible that the expected change in performance predicted by the tool is somewhat different from the actual improvement observed when the recommended indexes are created.
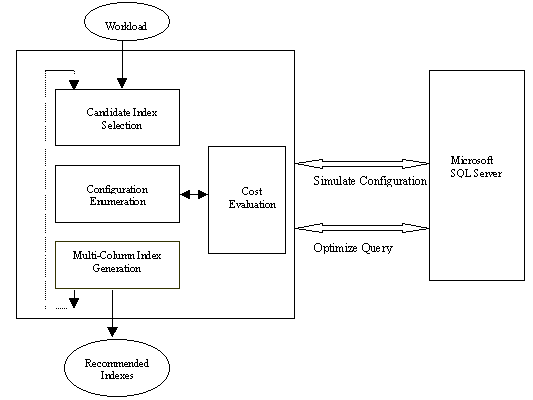
The illustration provides an architectural overview of the Index Tuning Wizard and its interaction with SQL Server. The Index Tuning Wizard takes as input a workload on a specified database. The tool iterates through several alternative configurations (sets of indexes), and picks the configuration that results in lowest cost for the given workload. Clearly, the obvious approach of evaluating a configuration by physically materializing the configuration is not practical because materializing a configuration requires adding and dropping indexes, which can be extremely resource-intensive and can affect operational queries on the system. Therefore, the Index Tuning Wizard needs to simulate a configuration without materializing it. The Index Tuning Wizard uses the optimizer's cost estimate for the workload for comparing alternative configurations. We have extended SQL Server 7.0 to support (a) the ability to simulate a configuration and (b) the ability to optimize a query for the simulated configuration.
Figure 1. Architecture of the Index Tuning Wizard
The Index Tuning Wizard may have to evaluate the cost of many alternative configurations by calling the optimizer. Invoking the optimizer can be a relatively expensive operation because it involves crossing process boundaries from the tool to the server. The cost evaluation module significantly reduces the number of optimizer invocations by exploiting the commonality among configurations. For example, consider the query Q: SELECT * FROM person WHERE city = "Seattle." Let C1 be a configuration consisting of two single-column indexes on 1) city 2) birthdate. Let C2 be a different configuration consisting of two single-column indexes on 1) city 2) age. We observe that both C1 and C2 have the same cost for query Q since indexes on birthdate and age cannot affect the cost of Q. Thus, if C1 has already been evaluated for Q, then the cost of C2 can be computed without invoking the optimizer.
We will now describe the strategy used by the Index Tuning Wizard to pick single column indexes. As mentioned earlier, the tool also considers multicolumn indexes, and we will discuss later how we deal with the combinatorial explosion resulting from multicolumn indexes. Note that an enterprise database may have many tables, and queries in the workload may reference many columns of these tables. Therefore, if the Index Tuning Wizard were to consider an index on each column referenced in the workload, the search would quickly become intractable because the tool has to consider combinations of these indexes. The candidate index selection module addresses this problem by examining each query in the workload one by one and then eliminating from further consideration a large number of indexes that provide no tangible benefit for any query in the workload. The indexes that survive candidate index selection are those that potentially provide significant improvement to one or more queries in the workload (referred to as candidate indexes). The configuration enumeration module intelligently searches the space of subsets of candidate indexes and picks a configuration with low total cost. The tool uses a novel search algorithm that is a hybrid of greedy and exhaustive enumeration. By being selectively exhaustive, the algorithm captures important interactions among indexes. However, the basic greedy nature of the algorithm results in a computationally tractable solution.
Multicolumn indexes are an important part of the physical design of a database, increasingly so with modern query processors. First, a multicolumn index can be used in a query that has conditions on more than one column. Second, for a query where all the required columns of a table are available in a multicolumn index, scanning the index can be more attractive than scanning the entire table (index-only access). However, the number of multicolumn indexes that need to be considered grows exponentially with the number of columns. For a given set of k columns, k! multi-column indexes are possible. The Index Tuning Wizard deals with this complexity by iteratively picking multicolumn indexes of increasing width. In the first iteration, the tool considers only single-column indexes; in the second iteration it considers single and two-column indexes, and so on. The multicolumn index generation module determines the multicolumn indexes to be considered in the next iteration based on indexes chosen by the configuration enumeration module in the current iteration. For a more detailed description of index selection algorithms, see References at the end of this article.
Unlike most other index tuning tools, the Index Tuning Wizard is in step with the optimizer because it uses the optimizer's cost estimate of the workload to evaluate the "goodness" of a configuration. The tool uses workload information and is therefore able to tune the selection of indexes to the expected workload. By taking into account the large space of multicolumn indexes, the tool can find indexes appropriate for index-only access and queries that have multiple selections. The Index Tuning Wizard is scalable and can handle large schema as well as a large workload.
Chaudhuri, S. and Narasayya, V., "An Efficient, Cost-driven Index Tuning Wizard for Microsoft SQL Server," Proceedings of the 23rd International Conference on Very Large Databases, Athens, Greece, pp. 146-155.
Hobbs, L. and England, K., "Rdb/VMS: A Comprehensive Guide," Digital Press, 1991.
Peter, C. and Gurry, M., "ORACLE Performance Tuning," O'Reilly & Associates, Inc. 1993.
-------------------------------------------
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.