Henry Lau
Microsoft Corporation
Last revised: August 1998
Introduction
Top Performance Items to Review for Initial SQL Server Configuration
More on Memory Tuning
Understanding the Functions of LazyWriter, Checkpoint, and Logging
Read-Ahead Manager
Disk I/O Performance
Clustered Indexes
Nonclustered Indexes
Covering Indexes
Index Selection
RAID
Creating as Much Disk I/O Parallelism as Possible
Tips for Using ShowPlan
Tips for Using Windows NT/SQL Performance Monitor
Monitoring Processors
Disk I/O Counters
Tips for Using SQLTrace
Tempdb in RAM?
Deadlocking
Join Order Importance
SQL to Avoid If at All Possible
Use ShowPlan to Detect Queries That Are Not Using Indexes
Smart Normalization
A Special Disk I/O Tuning Scenario: EMC Symmetrix
Some General Tips for Performance Tuning SQL Server
References
This performance-tuning quick reference is designed to help database administrators configure Microsoft® SQL Server™ for maximum performance and help determine the cause of poor performance in a SQL Server environment. It also provides SQL Server application developers guidance on how to use SQL Server indexes and SQL Server tools for analyzing the input/output (I/O) performance efficiency of SQL queries.
This document is organized into two parts: The first two sections are designed to quickly introduce the most critical performance-tuning items to focus on. The rest of the document expands upon SQL Server I/O performance topics. In order for the reader to become an expert in the topics described in this document, references to several excellent information sources have been included in the "References" section at the end of this document.
Maximizing I/O speed is a critical factor in SQL Server performance. Increasing SQL Server's memory allocation reduces I/O requirements. The more in-memory data caching capability that can be provided to SQL Server, the better. Give SQL Server as much random access memory (RAM) as possible without causing Microsoft® Windows NT® to page frequently.
Be careful not to crowd Windows NT by leaving too little RAM. While it's good to give SQL Server plenty of memory, percent performance improvement is typically small for incremental changes in data cache. For example, if a 500-megabyte (MB) data cache gives a 90 percent cache-hit ratio, going to 550 MB may only give 91 percent. SQL Server performance may not visibly improve. Also, for large servers with gigabytes (GB) of memory, hundreds of SQL threads, and so on, remember that Windows NT may need substantially more memory to support such a configuration. The motto: don't crowd Windows NT too much.
Windows NT paging is indicated by the Windows NT/SQL Performance Monitor counter: "Memory: Pages/Sec > 0." It can be normal to see some level of paging activity, due to working set trimming and other Virtual Memory Manager operations that move seldom-used pages to the Windows NT standby and free list. See the section "Memory: Page Faults/Sec > 0" for more information on reducing working set adjustments.
To set memory for SQL Server, use the command "sp_configure memory, <value>" where <value> is expressed in 2-kilobyte (KB) memory blocks. On dedicated Windows NT–based servers with larger amounts of RAM (500 or more MB) running SQL Server only, start by leaving 50 MB for Windows NT and commit the rest to SQL Server. Calculate <value> as (<amount of total RAM available on the Windows NT-based server, expressed in bytes> - 50,000,000) / 2000. Watch Windows NT/SQL Performance Monitor for signs of soft or hard paging (see the section to follow, "Performance Monitor Counters to Watch in Relation to Memory Tuning Issues"). There are recommendations in SQL Server Books Online for setting memory on servers with less than 500 MB of RAM.
Each time the SQL Server memory value changes, SQL Server automatically adjusts the "free buffers" configuration option to 5 percent of memory. After adjusting SQL Server memory, database administrators (DBAs) may want to set free buffers to what is needed. The section to follow, "Understanding the Functions of LazyWriter, Checkpoint, and Logging," will go into more detail about what LazyWriter is doing, how it relates to free buffers and the adjustments that might need to be made to free buffers, and maximize LazyWrite I/O.
Example: Consider a Windows NT-based server with 2 GB of RAM that is dedicated to SQL Server operations only. Use the preceding formula and set memory for 975,000 2-KB pages with the following commands:
Sp_configure memory, 975000
Reconfigure with override
A stop and restart of SQL Server is required for this configuration option to take effect. For more information, please refer to Inside Microsoft SQL Server 6.5, pages 122-124 and page 743.
The hash buckets setting goes hand in hand with the memory setting for SQL Server. Hash buckets are used by SQL Server to speed access to a given 2-KB page in the SQL Server data cache. Each hash bucket uses 8 bytes of RAM. Because that is cheap in terms of memory and it is costly to performance if too few hash buckets are set, it is better to over-allocate than under-allocate hash buckets.
To configure hash buckets, execute the following command in ISQL/W: "sp_configure 'hash buckets', <value>" where <value> is expressed as the number of hash buckets SQL Server will allocate for use. A general rule of thumb to follow for setting this option is to set the number of hash buckets at a ratio of one hash bucket for every two or three SQL Server 2-KB memory pages allocated for SQL Server memory. For servers that are not running SQL Server version 6.5, Enterprise Edition with more than 1 GB of RAM, the hash buckets should be set at the maximum value of 265,003 hash buckets by executing the following commands in ISQL/W:
Sp_configure 'hash buckets', 265003
Reconfigure with override
Windows NT-based servers running SQL Server 6.5 Enterprise Edition will allow a maximum of 16 million hash buckets to be configured. In this case, utilize the general rule of specifying one hash bucket for every two or three SQL Server 2-KB memory page allocated. Assume a server has 3 GB of RAM and is running Windows NT version 4.0, Enterprise Edition and SQL Server 6.5 Enterprise Edition. Then assume the SQL Server has been configured to allocate 2.8 GB of RAM to SQL Server memory (this is equivalent to 1,400,000 SQL Server 2-KB pages). Given the number of 2-KB pages allocated to SQL Server, and using the general rule described above, an appropriate setting would be 700,000 hash buckets. To configure this value in SQL Server, Enterprise Edition, execute the following commands in ISQL/W:
Sp_configure 'hash buckets', 700000
Reconfigure with override
A stop and restart of SQL Server is required for the hash buckets configuration option to take effect.
Use DBCC SQLPERF (HASHSTATS) to track hash bucket chains while SQL Server is running in production, preferably when SQL Server is at its busiest point of the day. With this command, look for the value in the column "Longest" for the row with the Type 'BUFHASH'. This value will indicate the longest hash bucket chain. This should be less than 4. See Inside Microsoft SQL Server 6.5, starting at page 753, for more information on this topic.
If necessary, increase the hash buckets value to keep buffer chains < 4. The shorter the chains, the quicker the data page lookups. For more information, please refer to Inside Microsoft SQL Server 6.5, starting at page 753.
For servers with large amounts of RAM, the SQL Server default of 30 percent for the amount of SQL Server memory to set aside as SQL Server procedure cache may be significantly larger than necessary. Therefore, this excess should be given to SQL Server data cache by reducing the procedure cache percentage. To configure procedure cache, execute the following command in ISQL/W: "sp_configure 'procedure cache',<value>" where <value> is the percentage of SQL Server memory to be allocated to the SQL Server procedure cache.
Example: Assume that 900,000 2-KB pages of RAM (1.8 GB of RAM) has been allocated to SQL Server memory with the default of 30 percent procedure cache allocation. Windows NT/SQL Performance Monitor: "SQL Server-Procedure Cache Object: Max Procedure Cache Used %" indicates that this counter never rises above 30 percent. This means that SQL Server is using 30 percent of 30 percent of 1.8 GB RAM = .3 x .3 x 1.8 GB = 162 MB of RAM for SQL Server procedure cache and wasting the rest (.3 x 1800 MB – 162 MB = 378 MB). In this case the procedure cache can be reduced so that SQL Server is only allocating what is needed, plus some padding. 12 percent would be a better. To configure SQL Server procedure cache setting, execute the following commands:
Sp_configure 'procedure cache', 12
Reconfigure with override
SQL Server needs to be stopped and restarted for this setting to take effect.
Be sure to leave a generous safety margin for procedure cache while reducing the percentage and to monitor procedure cache usage, carefully monitoring the procedure cache utilization after the change has been made. It is not worthwhile to try to squeeze out every possible byte for SQL Server data cache, because performance typically will not benefit from smaller incremental increases and procedure caching performance can be degraded if procedure cache percentage is reduced too aggressively. For more information, please refer to the book Inside Microsoft SQL Server 6.5, starting at page 745. (See the "References" section of this article.)
The default of 8 is sufficient for typical lower-end disk subsystems. With a high-end Redundant Array of Inexpensive Disks (RAID) storage subsystem attached, Windows NT-based servers are capable of very high disk I/O transfer rates. The setting of 8 may do a disservice to the RAID subsystem because it is capable of completing many more simultaneous disk transfer requests than a low-end disk subsystem. If, in addition to this, SQL Server write activity dictates that more disk transfer capability is needed, set this value higher.
A good value for 'max async io' is one that allows checkpoint to be "fast enough." The goal is to make checkpoint fast enough to finish before another checkpoint is needed (based on desired recovery characteristics), but not so fast that the system is seriously perturbed by the event (disk queuing, which will be discussed in further detail in the section "Top Windows NT/SQL Performance Monitor Objects and Counters to Watch When Diagnosing a Slow SQL Server or Optimizing SQL Server").
A rule of thumb for setting 'max async io' for SQL Servers running on larger disk subsystems is to multiply the number of physical drives available to do simultaneous I/O by 2 or 3. Then watch Windows NT/SQL Performance Monitor for signs of disk activity or queuing issues. The main negative impact of setting this configuration option too high is that it may cause the checkpoint to monopolize disk subsystem bandwidth required by other SQL Server I/O operations, such as reads.
To set this value, execute the following command in ISQL/W: "sp_configure 'max async io', <value>" where <value> is expressed as the number of simultaneous disk I/O requests that the SQL Server system will be able to submit to Windows NT during a checkpoint operation, which submits the request to the physical disk subsystem. See the section to follow, "Disk I/O Performance" for more information on disk I/O tuning. This configuration option is dynamic (that it, does not require a stop and restart of SQL Server to take effect).
SQL Server lock structures are 28 bytes and lock owner structures are 32 bytes. The sp_configure command increases both of these structure allocations at the same time under the generic label of 'locks.' If several users have the same page locked, one lock structure plus a lock owner structure for each user is needed.
Because the internal memory cost of locks is relatively low, it does not hurt to overestimate. When SQL Server runs out of locks, it doesn't affect performance. SQL Server will provide an error message (SQL Server error message number 1204, "SQL Server has run out of LOCKS") indicating that the number of locks needs to be increased. It is best to avoid the error message by setting locks higher on busy systems.
To set this value, execute the following command in ISQL/W: "sp_configure locks, <value>" where <value> is expressed as the number of locks for SQL Server to make available. To provide some general guidance as to where to set locks, consider the following calculation: (user connections) x (maximum number of tables simultaneously accessed by any user at the same time) x (maximum rows per table accessed by any user at the same time). This estimation is approximate because it assumes no lock escalation and much more data page activity than is likely. But it can help provide a navigation point. For more information, please refer to Inside Microsoft SQL Server 6.5, page 749.
Like SQL Server locks, open objects do not consume much memory (about 70 bytes per open object) and don't affect performance if set too low. But an annoying error message to applications will result if SQL Server runs out of open objects, so it is better to overestimate. To set this value, execute the following command in ISQL/W: "sp_configure 'open objects', <value>" where <value> is expressed as the number of tables, views, rules, stored procedures, defaults, and triggers that may be simultaneously accessed. It is not necessary to use another open object if an object is accessed more than once.
The default of 500 open objects for SQL Server 6.5 will not be enough for larger production SQL Server systems, so a higher estimate will need to be made for open objects. Estimate open objects by estimating the maximum number of tables, views, rules, stored procedures, defaults, and triggers that will be open at any one time for the SQL Server. For example, SQL Server environments that work with SAP/R3 will contain more than 8,000 stored procedures on SQL Server. On a system like this, set open objects to at least 20,000 to be safe, with the following commands in ISQL/W:
Sp_configure 'open objects', 20000
Reconfigure with override
In other cases, consider starting with 5,000, and do not hesitate to increase to 20,000 or even 50,000 if necessary. Note that open objects are used for all SQL Server temporary objects, so all open objects is not merely the number of persistent objects in the user databases but also the ones in tempdb. Consider the open objects setting a high water mark of all user database and tempdb objects combined. For more information, please refer to Inside Microsoft SQL Server 6.5, page 750.
For maximum performance, match SQL Server's network packet size to Windows NT and the underlying physical network packet size as dictated by the network. Transfer over the wire is done at the most efficient rate this way. Matching network packet sizes also saves valuable CPU resources because SQL Server won't have to spend cycles splitting data packets to match what it thinks is physical network packet size. To set this option, execute the following command in ISQL/W: "sp_configure 'network packet size', <value>" where <value> is expressed in terms of the number of bytes that SQL Server will pack into each data packet to be sent across the network. The default of 4,096 bytes matches most common network implementations. Talk to network administrators and determine the packet byte size supported. If it is not 4,096, it is advantageous to match SQL Server's network packet size to the network environment's packet size. For more information, please refer to, Inside Microsoft SQL Server 6.5, page 756.
As each user connects to SQL Server, an allocation of 27 KB of memory needs to be made. The 27 KB times the setting for user connections is in some sense reserved, but not allocated, at SQL Server startup time because SQL Server calculates the number of user connections specified and multiplies by 27 KB to come up with the amount of memory to set aside for user connections. This reservation of memory will take away from how much memory SQL Server will allocate for the data and procedure caches out of the available RAM configured as SQL Server memory. It is important not to configure user connections higher than necessary because it wastes RAM that could have been used for data cache. But again, don't cut things too close and risk running out of user connections in production.
Consider the following scenario: Assume 600 MB of RAM is available on a SQL Server. It is a dedicated SQL Server, so plan on leaving 50 MB to Windows NT and giving the rest to SQL Server for maximum performance. To configure, execute the following command in ISQL/W:
sp_configure memory, 275000Then set the number of user connections available (suppose this is known to be 2,000). Execute the following command:
sp_configure 'user connections', 2000This means that there is (275,000 x 2 KB) – (2,000 x 27 KB) = 496,000 KB or 496 MB available to SQL Server data and procedure caches, which may or may not be sufficient for database I/O operations.
In general, to set this option, execute the following command in ISQL/W: "sp_configure 'user connections', <value>" where <value> is expressed as the number of users that can be connected simultaneously to the SQL Server system. For more information, please refer to Inside Microsoft SQL Server 6.5, page 748.
This section requires observation of several Windows NT/SQL Performance Monitor disk counters. In order to enable these counters, run the command 'diskperf –y' from a Windows NT command window and restart Windows NT.
Physical hard drives experiencing disk queuing will hold back Windows NT disk I/O requests while they catch up on I/O processing. SQL Server response time will be degraded for these drives. This costs query execution time.
If using RAID, it is necessary to know how many physical hard drives are associated with each drive array that Windows NT sees as a single physical drive in order to calculate disk queuing per physical drive. Ask a hardware expert to explain the small computer system interface (SCSI) channel and physical drive distribution in order to understand how SQL Server data is held by each physical drive and how much SQL Server data is distributed on each SCSI channel.
There are several choices for looking at disk queuing via Windows NT/SQL Performance Monitor. Logical disk counters are associated with the logical drive letters assigned by Windows NT Disk Administrator, whereas physical disk counters are associated with what Windows NT Disk Administrator sees as a single physical device. Note that what looks to Windows NT Disk Administrator like a single physical device may either be a single hard drive or a RAID array, which consists of several hard drives. Current Disk Queue is an instantaneous measure of disk queuing, whereas Average Disk Queue averages disk queuing measurement over the Performance Monitor sampling. Take note of any counter where "Logical Disk: Average Disk Queue > 2," "Physical Disk Average Disk Queue > 2," "Logical Disk: Current Disk Queue > 2," or "Physical Disk: Average Disk Queue > 2."
These recommended measurements are specified per physical hard drive. If a RAID array is associated with a disk queue measurement, the measurement needs to be divided by the number of physical hard drives in the RAID array to determine the disk queuing per physical hard drive.
Note On physical hard drives or RAID arrays that hold SQL Server log files, disk queuing is not a useful measure because SQL Server Log Manager does not queue more than a single I/O request to SQL Server log file(s). Instead, execute the command DBCC SQLPERF(WAITSTATS) and look for a nonzero value returned in the resultset for the row labeled "WriteLog waits/tran."
Please see "Disk I/O Performance" for more information on disk I/O tuning.
This means that Windows NT's processors are receiving more work requests than they can handle as a group. Therefore, Windows NT needs to place these requests in a queue.
Some processor queuing is actually an indicator of good overall SQL Server I/O performance. If there is no processor queuing and if CPU utilization is low, it may be an indication that there is a performance bottleneck somewhere else in the system, the most likely candidate being the disk subsystem. Having a reasonable amount of work in the processor queue means that the CPUs are not idle and the rest of the system is keeping pace with the CPUs.
A general rule of thumb for a good processor queue number is to multiply the number of CPUs on the system by 2.
Processor queuing significantly above this calculation needs to be investigated. Excessive processor queuing costs query execution time. Several different activities could be contributing to processor queuing. Eliminating hard and soft paging will help save CPU resources. Other methods that help reduce processor queuing include SQL query tuning, picking better SQL indexes to reduce disk I/O (and, hence, CPU), or adding more CPUs (processors) to the system.
This means that Windows NT is going to disk for paging (hard page fault). This costs disk I/O + CPU resources. It is necessary to reduce memory given to SQL Server or add more RAM to the server. For more information, see the section below, "More on Memory Tuning."
This means that Windows NT is soft paging, that is, there are application(s) on the server requesting memory pages still inside RAM but outside the Windows NT Working Set. This consumes additional CPU resources that could be used by SQL Server. On a dedicated SQL Server machine, SQL Server will likely be the cause of this behavior, which can be verified and resolved with the next line item in this section.
Note that until SQL Server actually accesses all of its data cache pages for the first time, the first access to each page will cause a soft fault. So do not be concerned with initial soft faulting occurring as SQL Server starts up and the data cache is first being exercised. For more information, see the section immediately following, "More on Memory Tuning."
This indicates that the SQL Server process is producing the soft page faulting. This costs CPU resources. To prevent this soft paging from happening, set SQL Server's Working Set to be exactly the same as SQL Server memory allocation. Execute the following command in ISQL/W: "sp_configure 'set working set size', 1."
This may be an issue for DBAs trying to configure SQL Server memory close to the maximum amount of RAM available on a server with more than 1.5 GB of RAM. In order to do so, it may be necessary to reduce the default 1-MB thread stack for all SQL Server threads. This includes worker, Read-Ahead Manager, backup, and other threads.
It is easy to reduce the thread stack default. Use the following command in the Mssql\Binn directory: "EDITBIN /STACK: 65536 sqlservr.exe" to reduce the virtual memory assigned to each SQL Server connection to 64 KB (less than this would not be a good idea). Refer to Microsoft KnowledgeBase Article ID: Q160683 - INF: "How to Use Editbin to Adjust SQL Server Thread Stack Size" and Inside Microsoft SQL Server 6.5, page 744, for more information.
Note that with Microsoft SQL Server 6.5, Enterprise Edition in conjunction with Windows NT 4.0 Server, Enterprise Edition, it is possible to set memory on Intel®–based servers to allow Windows NT to address up to 3 GB of RAM (Alpha–based systems running Windows NT 4.0 and SQL Server 6.5, Enterprise Edition products are able to address up to 2 GB of RAM at this time). In this environment, it is realistic to set up to 2.8 GB of RAM for SQL Server data cache, thereby providing more caching capability than would have been possible without the Enterprise Edition products. Be sure to increase hash buckets appropriately in conjunction with increasing memory.
Refer to SQL Server Books Online, "More about Memory," for more guidelines on how to set memory. It provides a chart with recommended memory settings given a certain amount of RAM < 500 MB.
Realistically, it should be possible to configure Windows NT 4.0/SQL Server 6.5 to use 1.8 GB on a dedicated 2 GB RAM server.
Ask users how many user connections they need and set the number of SQL Server user connections accordingly. Keep in mind that a given user application might need more than a single connection per workstation.
SQL Server needs to reserve (but not allocate until a user connection is actually made) approximately 27 KB of memory that cannot be used for other SQL Server processing per user connection out of the SQL Server memory pool. It is best to keep the user connections at the required level, with a little padding. Ask users for their best judgement here. Watch the Windows NT/SQL Performance Monitor's paging counters for guidance. It is best to give SQL Server as much RAM as feasible on a dedicated SQL Server.
There is a DBCC trace flag available (-T1081) that tells SQL Server to allow index pages to remain in data cache longer than data pages. Normal behavior is that the SQL Server Buffer Manager will not allow an aged index or data page any passes before freeing that 2-KB page for incoming index or data pages demanding a free buffer. The 1081 flag tells the SQL Server Buffer Manager to give aged index pages one additional pass as the Buffer Manager is deciding which pages to move out of cache to free space for new pages coming in. The term "aged page" means that the data cache page's turn has come up in the SQL Server Buffer Manager's list of cache pages to free. Chapter 3 of Inside Microsoft SQL Server 6.5 provides more detailed information on the architecture of the Buffer Manager.
This trace flag may enhance performance in situations where the data pages brought into cache tend to be random, one-use-only pages and indexes are used to bring in the data pages. The theory is that the upper parts of the index binary tree structure tend to remain in cache and will save time and I/O if this index is needed again because only the leaf-level data pages need to be brought into the data cache. There is also the condition that using this trace flag tends only to bring performance gains if the cache-hit ratio for the SQL Server is poor due to the random and one-time-use nature of data page access, there is enough room in the rest of the data cache to bring in other required data and index pages from other index binary trees, and if the index binary tree is used fairly regularly to retrieve data pages. Also keep in mind that in most systems, very frequently utilized index pages will tend to remain in cache anyway because the Buffer Manager keeps track of the usage. The best approach is to monitor performance for a period with and without the trace flag enabled to see if it makes any difference. For more information, please refer to page 764 of Inside Microsoft SQL Server 6.5.
Set up SQL Server to use the 1081 setting with the following procedure:
The Windows NT/SQL Performance Monitor counter "Memory: Pages/Sec" is a good indicator of the amount of paging that Windows NT is performing and of how adequate the server's current RAM configuration is. Excessive paging needs to be addressed by decreasing SQL Server memory to give more memory to Windows NT and/or possibly adding more RAM to the Windows NT-based server. The best performance is ensured by keeping "Memory: Pages/Sec" at or close to zero. This means Windows NT and all its applications, including SQL Server, are not going to the Windows NT paging file to satisfy any data-in-memory requests, so the amount of RAM on the server is sufficient.
Pages/Sec can be greater than zero, however a relatively high performance penalty (disk I/O) is paid every time data is retrieved from the Windows NT paging file versus RAM.
A subset of the hard paging information in Windows NT/SQL Performance Monitor is how many times per second Windows NT had to read from the Windows NT paging file to resolve memory references, which is represented by "Memory: Page Reads/Sec." If "Memory: Page Reads/Sec > 5," this is bad for performance. Reduce SQL Server memory setting until Pages/Sec = 0. If this setting brings SQL Server memory to a lower level than desired, it is a sign that more RAM needs to be installed into this server.
There is no counter called Soft Faults per Second. Calculate the number of soft faults per second with the computation:
"Memory: Page Faults/Sec" - "Memory: Page Input/Sec" = Soft Page Faults per Second
Soft faults generally are not as bad as hard faults for performance because they consume CPU resources. Hard faults consume disk I/O resources. The best environment for performance is to have no faulting of any kind.
It is worth taking a moment to understand the difference between "Memory: Pages Input/Sec" and "Memory: Page Reads/Sec." "Memory: Pages Input/Sec" indicates the actual number of Windows NT 4-KB pages being brought in from the disk to satisfy page faults. "Memory: Page Reads/Sec" indicates how many disk I/O requests are made per second in order to satisfy page faults, which provides a slightly different point of view of the faulting that is occurring. So, a single Page Read could contain several Windows NT 4-KB pages. Disk I/O performs better as the packet size of data increases (64 KB or more), so it may be worthwhile to consider both of these counters at the same time. It is also important to remember that for a hard disk, completing a single read or write of 2 KB is almost as expensive in terms of time spent as a single read or write of 64 KB. Consider the following situation: 200 page reads consisting of eight 4-KB pages per read could conceivably finish faster than 300 page reads consisting of a single 4-KB page. Note that we are comparing 1,600 4-KB page reads finishing faster than 300 4-KB page reads. The key fact here is applicable to all disk I/O analysis: Don't just watch the number of Disk Bytes/Sec, also watch Disk Transfers/Sec because both are relevant. This will be discussed further in the section "Disk I/O Performance" to follow.
It is useful to compare "Memory: Page Input/Sec" to "Logical Disk: Disk Reads/Sec" across all drives associated with the Windows NT paging file and "Memory: Page Output/Sec" to "Logical Disk: Disk Writes/Sec" across all drives associated with the Windows NT paging file because these comparisons provide a measure of how much disk I/O is strictly related to paging versus other applications (that is, SQL Server). Another easy way to isolate Windows NT paging file I/O activity is to make sure that the Windows NT paging file is located on a separate set of drives from all other SQL Server files. Separating the Windows NT paging file from the SQL Server files can also help disk I/O performance because it allows disk I/O associated with Windows NT paging to be performed in parallel with disk I/O associated with SQL Server.
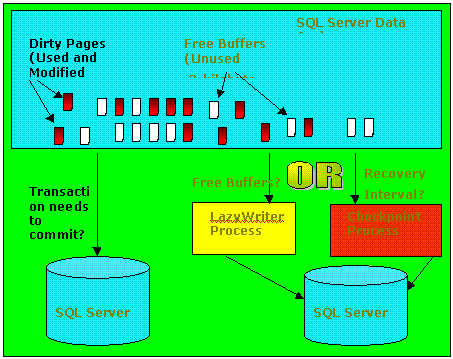
Figure 1.SQL Server disk write activity
Figure 1 illustrates the three activities that will account for SQL Server disk write activity, so it is valuable to understand what logging, LazyWriter, and Checkpoint do, how they are different, and when they occur. This builds a foundation for learning how to tune (or guide a server hardware expert in tuning) the disk subsystem for maximum performance with SQL Server.
LazyWriter produces free buffers, which are 2-KB data cache pages without any data in them. Free buffers are needed when new data or index pages are brought into the SQL Server data cache. Based on how long data and index pages have been in the cache, how recently the pages have been used, and the current number of free buffers available for use, the Buffer Manager makes decisions on which cache pages to tell LazyWriter to physically write to the SQL Server database files. As LazyWriter flushes each 2-KB cache buffer out to the disk, it needs to initialize the cache page's identity so that other data can be written into the free buffer.
SQL Server automatically configures free buffers to equal 5 percent of the configured value for SQL Server memory. Monitor "SQL Server: Cache - Number of Free Buffers" to see if this value dips. Optimally, LazyWriter keeps this counter level throughout SQL Server operations. It means that LazyWriter is keeping up with the user demand for free buffers. It is bad for "SQL Server: Cache - Number of Free Buffers" to hit zero because this would indicate there were times when the user load demanded a higher level of free buffers than LazyWriter was able to provide.
If LazyWriter is having problems keeping the free buffer level at the configured value (or at least regularly above 50 percent of the configured free buffer level), it could mean that the disk subsystem is not able to provide the disk I/O performance that LazyWriter needs (compare drops in free buffer level to any disk queuing to see if this is true). Or, it might be that 'max lazywriter io' needs to be set higher in order to refresh free buffers faster.
In disk subsystem terms, 'max lazywriter io' controls the number of simultaneous I/O requests that LazyWriter can have submitted to Windows NT (and in turn, to the disk I/O subsystem) at the same time. It is possible to set 'max lazywriter io' higher so that more dirty pages flush out of the SQL Server data cache at the same time onto disk. This helps keep the free buffer level up to the configured level, but it is important to be careful that the hard drives are not queuing up disk I/O requests.
Avoid increasing the configured free buffer level above the 5 percent default. Increasing the configured level of free buffers increases the number of pages in the data cache that must be constantly emptied out by LazyWriter. This takes away from the number of data and index pages that can remain in the cache to help increase cache-hit ratio.
"SQLServer: I/O Lazy Writes/Sec" in Windows NT/SQL Performance Monitor indicates LazyWriter activity. A nonzero value indicates the number of 2-KB pages being physically written out to disk. A zero value for this counter indicates that LazyWriter is turned off. It is best for performance if LazyWriter does not have to turn itself on and off regularly because this costs CPU. It is better for LazyWriter to be running constantly to keep the free buffer level up. If LazyWriter is turning itself on and off, consider reducing 'max lazywriter io' so that LazyWriter is not doing as many simultaneous cache flushes. This will cause LazyWriter to spread out the cache flushes it does over a longer period of time and will help keep LazyWriter constantly active. Be careful that the reduction does not cause LazyWriter to be unable to maintain configured free buffer level.
Monitor the current level of disk queuing in the Windows NT/SQL Performance Monitor by looking under the counter for "(Logical or Physical) Disk: Average Disk Queue" or "Current Disk Queue" and ensure the disk queue is less than 2 for each physical drive associated with any SQL Server activity. For systems that employ hardware RAID controllers and disk arrays, remember to divide the number reported by Logical/Physical Disk counters by the number of actual hard drives associated with that logical drive letter or physical hard drive number (as reported by Windows NT Disk Administrator) because Windows NT and SQL Server are unaware of the actual number of physical hard drives attached to a RAID controller. It is very important to be aware of the number of drives associated with a RAID array controller in order to properly interpret the disk queue numbers that Windows NT/SQL Performance Monitor reports, as well as for other performance reasons that will be described in the sections "Disk I/O Performance" and "RAID."
When a checkpoint occurs, the entire data cache is swept and all dirty pages are written out to the SQL Server data files. Dirty pages are any data cache pages that have had modifications made to them since being brought into the cache. A buffer written to disk by Checkpoint still contains the page and users can read or update it without rereading it from disk, which is not the case for free buffers created by LazyWriter.
To make Checkpoint more efficient when there are a large number of pages to flush out of the cache, SQL Server will sort the data pages to be flushed in the order the pages appear on disk. This will help minimize disk arm movement during cache flush and potentially take advantage of sequential disk I/O. Checkpoint also submits 2-KB disk I/O requests asynchronously to the disk subsystem. This allows SQL Server to finish submitting required disk I/O requests faster because Checkpoint doesn't wait for the disk subsystem to report back that the data has been actually written to disk. It is important to watch disk queuing on hard drives associated with SQL Server data files to see if Checkpoint is sending down more disk I/O requests than the disk(s) can handle. If this is true, more disk I/O capacity must be added to the disk subsystem so that it can handle the load.
Adjust Checkpoint's dirty page flushing behavior with the use of the sp_configure options 'max async io' and 'recovery interval'; 'max async io' controls the number of 2-KB cache flushes that the Checkpoint process can have simultaneously submitted to Windows NT (and, in turn, to the disk I/O subsystem). If disk queuing occurs at unacceptable levels during checkpoints, turn down 'max async io.' If it is necessary for SQL Server to maintain its currently configured level of 'max async io,' then add more disks to the disk subsystem until disk queuing comes down to acceptable levels.
If, on the other hand, it is necessary to increase the speed with which SQL Server executes Checkpoint and the disk subsystem is already powerful enough to handle the increased disk I/O while avoiding disk queuing, increase 'max async io' to allow SQL Server to send more disk I/O requests at the same time, potentially improving I/O performance. Watch the disk queuing counters carefully after changing 'max async io.' Be sure to watch disk read queuing in addition to disk write queuing. If 'max async io' is set too high for a given disk subsystem, Checkpoint will tend to queue up a large number of disk write I/O requests. This can cause SQL Server read activity to be blocked. "SQL Server: I/O - Outstanding Reads" is a good counter to watch in Performance Monitor to looked for queued SQL Server reads. Physical Disk and Logical Disk objects in Performance Monitor provide the "Average Disk Read Queue Length" counter, which can also used to monitor queued disk read I/O requests. If disk read queuing is being caused by Checkpoint, the choices are to either decrease 'max async io' or to add more hard drives so that the checkpoint and read requests can be simultaneously handled.
"Recovery interval" is associated with SQL Server checkpoints, and there is often confusion about this topic. Common points of confusion include 1) what the Checkpoint process is doing every 60 seconds and 2) what the sp_configuration option "recovery interval" really means. The SQL Server Checkpoint process is a simple loop, which automatically scans the databases once per minute. For tempdb and any database marked 'truncate log on checkpoint,' it calls the dump tran (which also does a checkpoint). Otherwise, if the log record threshold is exceeded, it executes an actual checkpoint, which will flush dirty pages for that database. Note that only the dirty pages for the database(s) that have reached the log record threshold will be written to disk. Dirty pages from databases that have not reached the threshold will not be written. The threshold is specified globally by recovery interval but the log record count is kept separately for each database. Checkpoint checks the databases in the order it finds them in sysdatabases and completes the action on the current database before going on to the next (a long checkpoint in one database could delay the processing of others). To perform the checkpoint (or dump tran), the automatic checkpoint just calls the same code that is executed to process a T-SQL checkpoint (or dump tran) command received from a user.
Recovery interval does not mean SQL Server checkpoints are used to flush dirty pages out of the cache whenever the time period specified with recovery interval has elapsed. It is very possible with the default recovery interval of 5 minutes and a very inactive database for a SQL Server system not to flush dirty pages by Checkpoint for many days or weeks. On the other hand, with a heavily updated Online Transaction Processing (OLTP) system, SQL Server might determine that a checkpoint is necessary every 60 seconds because there are enough pages in data cache written every 60 seconds that the number of log records written exceeds the calculated number of log records associated with the configured recovery interval.
The default of 5 minutes for recovery should be fine for most SQL Server configurations. Reducing the recovery interval will reduce the number of transaction log records that can be written before Checkpoint sweeps the cache for dirty pages. This effectively reduces the amount of disk write I/O that Checkpoint will send to the disk subsystem and checkpoints will complete faster.
More information on Checkpoint is provided in Inside Microsoft SQL Server 6.5, pages 90, 755, and 759.
Like all other major relational database management system (RDBMS) products, SQL Server ensures that all write activity (insert, update, and delete) performed on the database will not be lost if something were to interrupt SQL Server's online status (such as power failure, disk drive failure, fire in the data center, and so on). One thing that helps guarantee recoverability is the SQL Server logging process. Before any implicit (single SQL query) or explicit (defined transaction that issues a Begin Tran/COMMIT or ROLLBACK command sequence) transaction can be completed, SQL Server's Log Manager must receive a signal from the disk subsystem that all data changes associated with that transaction have been written successfully to the associated log file. This rule guarantees that if the SQL Server is abruptly shut down for whatever reason and the transactions written into the data cache are not yet flushed to the data files (remember that flushing data buffers is Checkpoint's or LazyWriter's responsibility), the transaction log can be read and reapplied in SQL Server upon turning on the SQL Server. Reading the transaction log and applying the transactions to SQL Server after a server stoppage is referred to as recovery.
Because SQL Server must wait for the disk subsystem to complete I/O to SQL Server log files as each transaction is completed, it is important that the disks containing SQL Server log files have sufficient disk I/O handling capacity for the anticipated transaction load.
The method of watching out for disk queuing associated with SQL Server log files is different from SQL Server database files. Due to the fact that SQL Server Log Manager never queues more than one I/O request to the SQL Server log files, using Windows NT/SQL Performance Monitor Disk Queue counters is not a useful measure. Instead, use DBCC SQLPERF(WAITSTATS) in ISQL/W. Among other things, this command provides information about whether SQL Server needed to wait to physically write records to the SQL Server log file(s). DBCC SQLPERF(WAITSTATS) provides this information as "WriteLog millisec/tran," which indicates the number of milliseconds that SQL Server had to wait to physically write to the log file(s). Consider associating more physical hard drives with SQL Server log files if "WriteLog millisec/tran" returns nonzero values. This is a good way to help make sure SQL Server transactions never have to wait on the hard drives to complete the transactions.
It is okay to use a caching controller for SQL Server log files (in fact, it's a necessity for the highest performance) if the controller guarantees that data entrusted to it will be written to disk eventually even if the power fails. For more information on caching controllers, please refer to the section following titled "Effect of On-Board Cache of Hardware RAID Controllers."
For more information, please refer to Inside Microsoft SQL Server 6.5, page 765, or search in SQL Server Books Online for the keywords, "dbcc sqlperf".
The SQL Server Read-Ahead Manager boosts SQL Server I/O performance with the following methodology: When SQL Server detects that a SQL query is going to fetch a substantial amount of data from the database (table scan, for instance) the Read-Ahead Manager starts a read-ahead thread up to fetch the data in 16-KB extents from disk and read them into the data cache. The Read-Ahead Manager follows the page chain to read pages before the application discovers it needs them (if it is processing sequentially). This way, the data is in the cache for the query engine to operate on. The performance gain is produced by the fact that the Read-Ahead Manager is operating in 16-KB chunks. Otherwise, the query engine would have had to read data off of disk in 2-KB chunks.
There are two important read-ahead Performance Monitor counters to watch: "SQL Server: RA—Pages Fetched into Cache/Sec" and "SQL Server: RA—Pages Found in Cache/Sec." Read-ahead (RA) reads in a block of eight pages and then attempts to add each page to the hash table (table of contents for the page cache). If the page is already hashed (that is, the application read it in first and read-ahead wasted a read), it counts as 'page found in cache.' If the page is not already hashed (that is, successful read-ahead), it counts as 'page placed in cache.'
It should not be necessary to adjust RA parameters that determine when SQL Server initiates read-ahead operations. It may be necessary to adjust how many simultaneous read-aheads SQL Server can manage when there will be hundreds or thousands of simultaneous queries and many of these queries may benefit from read-ahead. In this case, SQL Server will likely benefit from tuning "RA slots per thread" and "RA worker threads." How many simultaneous read-ahead operations SQL Server can manage is dictated by the calculation "RA slots per thread" multiplied by "RA worker threads." By default, this is 5 x 3 = 15 read-ahead operations at one time simultaneously run by the SQL Server Read-Ahead Manager.
To tune read-ahead operations, it is necessary to know how well the disk I/O subsystem can handle the increased I/O load caused by increased read-aheads and how many read-ahead operations a particular SQL Server user environment needs. The information on disk I/O in the section "Disk I/O Performance" will give information on how to detect disk I/O bottlenecks caused by read-ahead or other activity. The approach to take in tuning read-ahead should be to increase "RA slots per thread" and "RA worker threads" slowly, watch Windows NT/SQL Performance Monitor under load for signs of any disk queuing, and see how the adjustment affects overall query performance.
One caveat about the Read-Ahead Manager is that too much read-ahead can be detrimental overall to performance because it can fill cache with pages that were not needed, requiring additional I/O and CPU that could have been used for other purposes.
Inside Microsoft SQL Server 6.5 gives some recommendations on page 761-762 for setting these two items. On quad-processor machines, the maximum recommended setting for "RA worker threads" is 20. The maximum recommended setting for "RA slots per thread" is 10 on any server. On eight-processor machines, it is possible to increase "RA worker threads" above levels mentioned here. Remember, however, that providing SQL Server with the ability to create more threads can put more pressure on the system CPUs. It is a good objective to not raise these settings higher than necessary.
When configuring a SQL Server that will only contain a few gigabytes of data and not sustain heavy read or write activity, it is not as important to be concerned with the subject of disk I/O and balancing of SQL Server I/O activity across hard drives for maximum performance.
But to build larger SQL Server databases that will contain hundreds of gigabytes of data and/or will sustain heavy read and/or write activity, it is necessary to drive configuration around maximizing SQL Server disk I/O performance by load-balancing across multiple hard drives.
One of the most important aspects about database performance tuning in general is I/O performance tuning. SQL Server is certainly no exception to this philosophy. Unless SQL Server is running on a machine with enough RAM to hold the entire database, I/O performance will be dictated by how fast reads and writes of SQL Server data can be processed by the disk I/O subsystem.
A good rule of thumb to remember is that the typical Wide Ultra SCSI hard drive available from hardware vendors (when this article was last updated) is capable of providing Windows NT and SQL Server with about 75 nonsequential (random) and 150 sequential I/O operations per second. Advertised transfer rates in terms of megabytes for these hard drives range around 10 MB/second. Keep in mind that it is much more likely for a SQL Server database to be constrained by the 75/150 I/O transfers per second than the 10 MB/second transfer rate. This is illustrated by the following calculations:
(75 random I/O operations per second) X (2-KB transfer) = 150 KB per second
This calculation indicates that by doing strictly random read or write SQL Server operations on a given hard drive (single page reads and writes), it is reasonable to expect at most 150 KB per second of I/O processing capability from that hard drive. This is much lower than the advertised 10 MB/second I/O handling capacity of the drive. SQL Server Checkpoint and LazyWriter will perform I/O in 2-KB transfer sizes.
(150 random I/O operations per second) X (2-KB transfer) = 300 KB per second
This calculation indicates that by doing strictly sequential read or write SQL Server operations on a given hard drive (single page reads and writes), it is reasonable to expect at most 300 KB per second of I/O processing capability from that hard drive.
(150 sequential I/O operations per second) X (16-KB transfer) = 2,400 KB (2.4 MB) per second
This calculation indicates that by doing strictly sequential read or write SQL Server operations on a given hard drive, it is reasonable to expect at most 2.4 MB per second of I/O processing capability from that hard drive. This is much better than the random I/O case but still much less than the 10 MB/second advertised transfer rates. SQL Server Read-Ahead Manager and Log Manager perform disk I/O in the 16-KB transfer rate. The Log Manager will write sequentially to the log files. The Read-Ahead Manager might perform these operations sequentially, but this is not necessarily the case. Page splitting will cause a 16-KB read to be nonsequential. This is one reason why it is important to eliminate and prevent page splitting.
(75 random I/O operations per second) X (16-KB transfer) = 1200 KB (1.2 MB) per second
The preceding calculation illustrates a worst-case scenario for read-aheads, assuming all random I/O. Note that even in the completely random situation, the 16-kilobtye transfer size still provides much better disk I/O transfer rate from disk (1,200 KB per second) than the single-page transfer rates (150 KB per second):
Hopefully, the preceding section helped clarify why SQL Server single-page I/Os are not as efficient as SQL Server extent I/Os.
Keep an eye on "SQL Server: I/O Page Reads/Sec" because it indicates how many 2-KB pages SQL Server had to read from disk to satisfy queries. It is very hard to eliminate 2-KB single page reads from disk. That is because many queries ask for single rows from a table. This is the common scenario for online transacting processing (OLTP) systems. It doesn't make sense from a performance standpoint for SQL Server to initiate read-ahead on a table for a given query when only a single row of data is needed. Decision Support Systems (DSS) or Data Warehousing (DW) scenarios differ from OLTP systems in that sequential reading of large amounts of data is common. In the DSS/DW case, there should be more read-ahead activity and less activity on the counter "SQL Server: /O Page Reads/Sec." One more point about "SQL Server: I/O Page Reads/Sec": While it is very unlikely there will be no single 2-KB page reads from the system, watch "SQL Server: I/O Page Reads/Sec" for periods when single page reads are high and can be related by time periods back to certain queries by SQL Trace (See sections to follow on "Tips for Using SQLTrace" and "Tips for Using Windows NT/SQL Performance Monitor" on how to match fluctuations in Performance Monitor counters back to specific points in time). This may be a sign that an SQL query is reading more data than it needs to and pinpoints that query for more detailed query tuning.
The terms sequential and nonsequential (random) have been used quite a bit to refer to hard disk operations. It is worthwhile to take a moment to explain what these terms mean in relation to a disk drive. A single hard drive consists of a set of drive platters and each of these drive platters provide services for read/write operations with a set of arms with read/write heads that can move across the platters and read information from the drive platter or write data onto the platters. With respect to SQL Server, there are two important points to remember about hard drives:
A typical hard disk provides a maximum transfer rate of around 10 MB per second or 75 nonsequential/150 sequential disk transfers per second. Typical RAID controllers have an advertised transfer rate of about 40 MB per second or (very approximately) 2,000 disk transfers per second. Peripheral Component Interconnect (PCI) buses have an advertised transfer rate of about 133 MB per second. The actual transfer rates achievable for a device will differ from the advertised rate, but that is not too important for our discussion here. What is important to understand is how to use these transfer rates as a rough starting point for determining the number of hard drives to associate with each RAID controller and, in turn, how many drives and RAID controllers can be attached to a PCI bus without I/O bottleneck problems.
In the previous section, "How Advertised Disk Transfer Rates Relate to SQL Server," it was calculated that the maximum amount of SQL Server data that can be read from or written to a hard drive in a second is 2.4 MB. Assuming a RAID controller can handle 40 MB per second, it is possible to roughly calculate the number of hard drives that should be associated with one RAID controller by dividing 40 by 2.4 to get about 16. This means that at most 16 drives should be associated with that one controller when SQL Server is doing nothing but sequential I/O of 16 KB. Similarly, it was previously calculated that with all nonsequential I/O of 16 KB, the maximum data sent up from the hard drive to the controller would be 1.2 MB per second. Dividing 40 MB per second by 1.2 MB per second gives us the result of 33. This means that at most 33 hard drives should be associated with the single controller in the nonsequential 16-KB scenario.
Another way to figure out how many drives should be associated with a RAID controller is to look at disk transfers per second instead of looking at the megabytes per second. If a hard drive is capable of 75 nonsequential (random) I/Os per second, it follows that about 26 hard drives working together could theoretically produce 2,000 nonsequential I/Os per second, enough to hit the maximum I/O handling capacity of a single RAID controller. On the other hand, it would only take about 13 hard drives working together to produce 2,000 sequential I/Os per second and keep the RAID controller running at maximum throughput, because a single hard drive can sustain 150 sequential I/Os per second.
Moving on to the PCI bus, note that RAID controller and PCI bus bottlenecks are not nearly as common as I/O bottlenecks related to hard drives. But for the sake of illustration, let's assume that it is possible to keep a set of hard drives associated with a RAID controller busy enough to push 40 MB per second of throughput through the controller. The next question would be, "How many RAID controllers can be safely attached to the PCI bus without risking a PCI bus I/O bottleneck?" To make a rough estimation, divide the I/O processing capacity of the PCI bus by the I/O processing capacity of the RAID controller: 133 MB/second divided by 40 MB/second gives the result that approximately three RAID controllers can be attached to a single PCI bus. Note that most large servers come with more than one PCI bus so this would increase the number of RAID controllers that could be installed in a single server.
These calculations help illustrate the relationship of the transfer rates of the various components that comprise a disk I/O subsystem (hard drives, RAID controllers, and PCI bus) and are not meant to be taken literally. This is because the calculations assume all sequential or all nonsequential data access, which is not likely to ever be the case in a production SQL environment. In reality, a mixture of sequential, nonsequential, 2-KB, and 16-KB I/O will occur. Other factors will make it difficult to estimate exactly how many I/O operations can be pushed through a set of hard drives at one time. On-board read/write caching available for RAID controllers increases the amount of I/O that a set of drives can effectively produce. How much more is hard to estimate for the same reason that it is hard to estimate exactly the amount of 2-KB versus 16-KB I/O a SQL Server environment will need. This document will talk more about this type of caching in the section "Effect of On-Board Cache of Hardware RAID Controllers."
But hopefully, this section has helped to foster some insight into what advertised transfer rates really mean to SQL Server.
I/O characteristics of the hardware devices on the server have been discussed. Now the discussion will move to how SQL Server data and index structures are physically placed on disk drives. Just enough about these structures will be described so that the knowledge can apply to disk I/O performance. For more details, there is a very comprehensive discussion on SQL Server internal structures in Inside Microsoft SQL Server 6.5, Chapter 6, starting on page 207 in the section titled "Internal Storage—The Details." Similar information is found in The SQL Server 6.5 Performance Optimization and Tuning Handbook, Chapters 2 and 3, "SQL Server Storage Structures" and "Indexing."
SQL Server data and index pages are both 2 KB in size. SQL Server data pages contain all of the data associated with rows of a table, except text and image data. In the case of text and image data, the SQL Server data page containing the row associated with the text/image column will contain a pointer to a chain of more 2-KB pages that contain the text/image data.
SQL Server index pages contain only the data from columns that comprise a particular index. This means that index pages effectively compress information associated with many more rows into a 2-KB page than a 2-KB data page does. An important I/O performance concept to understand is that part of the I/O performance benefit of indexes comes from this information compression. This is true if the columns picked to be part of an index form a relatively low percentage of the rowsize of the table. When an SQL query asks for a set of rows from a table where columns in the query match certain values in the rows, SQL Server can save I/O operations and time by reading the index pages to look for the values, and then access only the rows in the table required to satisfy the query instead of having to perform I/O operations to scan all rows in the table to locate the required rows. This is true if the indexes defined are properly selected; this document will talk about that in the section "Index Selection."
There are two types of SQL Server indexes and both are built upon binary tree structures formed out of 2-KB index pages. The difference is at the bottom of the binary tree structures, which are referred to as the leaf level in SQL Server documentation. The upper parts of index binary tree structures are referred to as nonleaf levels of the index. A binary tree structure is built for every single index defined on a SQL Server table. These binary trees must be maintained whenever rows are added, deleted, or modified in the table. This is why having more indexes than necessary hurts SQL Server performance.
The following diagram illustrates the structural difference between nonclustered and clustered indexes. Key points to remember are that in the nonclustered index case the leaf-level nodes contain only the data that participates in the index, and that at the nonclusterered index leaf-level nodes index rows contain pointers to quickly locate the remaining row data on the associated data page. In the worst-case scenario, each row access from the nonclustered index will require an additional nonsequential disk I/O to retrieve the row data. In the best-case scenario, many of the required rows will be on the same data page and thus allow retrieval of several required rows with each data page fetched. In the clustered index case, the leaf-level nodes of the index are the actual data rows for the table. Therefore, no pointer jumps are required for retrieval of table data. Range scans based on clustered indexes will perform well because the leaf level of the clustered index, and hence all rows of that table, are physically ordered on disk by the columns that comprise the clustered index and due to this fact will perform I/O in 16-KB extents. Hopefully, if there is not a lot of page splitting on the clustered index binary tree (nonleaf and leaf levels), these 16-KB I/Os will be physically sequential. The dotted lines indicate that there are other 2-KB pages present in the binary tree structures but not shown.
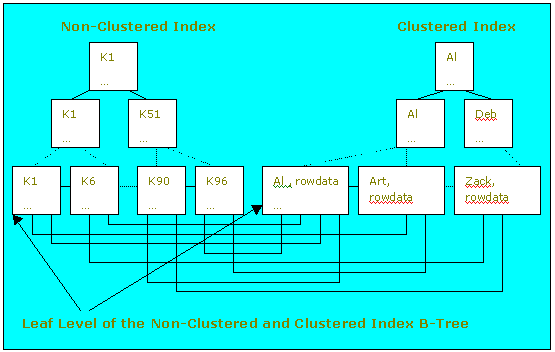
Figure 2. Non-clustered and clustered indexes
There can only be one clustered index per table. There is a simple physical reason for this. While the upper parts (commonly referred to in SQL Server documentation as nonleaf levels) of the clustered index binary tree structure are organized just like the nonclustered index binary tree structures, the bottom level of the clustered index binary tree are the actual 2-KB data pages associated with the table. There are two performance implications here:
Nonclustered indexes are most useful for fetching few rows with good selectivity from large SQL Server tables based on a key value. As mentioned before, nonclustered indexes are binary trees formed out of 2-KB index pages. The bottom or leaf level of the binary tree of index pages contains all the data from the columns that comprised that index from the leaf level 2-KB page to the associated 2-KB data page. When a nonclustered index is used to retrieve information from a table based on a match with the key value, the index binary tree is traversed until the a key match is found at the leaf level of the index. Then a pointer jump is made if columns from the table are needed that did not form part of the index. This pointer jump will likely require a nonsequential I/O operation on the disk. It might even require the data to be read from another disk if the table and its accompanying index binary tree(s) are large. If multiple pointers lead to the same 2-KB data page, less of an I/O performance penalty will be paid because it is only necessary to read the 2-KB page into the data cache once. For each row returned for an SQL query that involves searching with a nonclustered index, one pointer jump is required. These pointer jumps are the reason that nonclustered indexes are better suited for SQL queries that return only one or a few rows from the table. Queries that require many rows to be returned are better served with a clustered index.
A special case of nonclustered index is the covering index. The definition of a covering index is a nonclustered index built upon all the columns required to satisfy an SQL query, both in the selection criteria and the WHERE predicate. Covering indexes can save a huge amount of I/O and bring a lot of performance to a query. But it is necessary to balance the costs of creating a new index (and another binary tree index structure that needs to be updated every time a row is written or updated) against the I/O performance gain the covering index will bring. If a covering index will greatly benefit a query or set of queries that will be run often on SQL Server, the creation of that covering index may be worth the cost.
Select col1,col3 from table1 where col2 = 'value'
Create index indexname1 on table1(col2,col1,col3)
The index created, called "indexname1" in this example, is a covering index because it includes all columns from the SELECT statement and the WHERE predicate. This means that during the execution of this query, SQL Server does not need to access the data pages associated with table1. SQL Server can obtain all of the information required to satisfy the query by using the index called indexname1. Once SQL Server has traversed the binary tree associated with indexname1 and found the range of index keys where col2 is equal to 'value', SQL Server knows that it can fetch all of required data (col1,col2,col3) from the leaf level (bottom level) of the covering index. This provides I/O performance in two ways:
Please note also that the index was created with col2 first in the CREATE INDEX statement. This is important to remember. The SQL Server 6.5 query optimizer only makes use of the first column of a compound index such as this. So, if one of the other columns had been specified as the first column of the compound index, SQL Server would have ignored the index within the context of the example query above.
In general, if the covering index is small in terms of the number of bytes from all the columns in the index compared to the number of bytes in a single row of that table, it may make sense to use a covering index.
When a SQL Server environment involves many SQL queries on a given table, these queries ask for a large proportion of the columns of the table, and because it is not possible to reduce the set of columns requested, it may be very difficult to rely on covering indexes for help. Having many indexes (of any kind) on a table will slow down SQL Server at write time because insert/update/delete activity requires updating associated information in the index binary tree structures.
How indexes are chosen significantly affects the amount of disk I/O generated and, subsequently, performance. The previous sections described why nonclustered indexes are good for retrieval of a small number of rows and clustered indexes are good for range scans. Here is some additional information about index selection.
For indexes that will contain more than a single column, be sure to put the most selective column first. This is very important in helping the SQL Server query optimizer use the index effectively. Also try to keep indexes as compact (fewest number of columns and bytes) as possible.
In the case of nonclustered indexes, selectivity is important, because if a nonclustered index is created on a large table with only a few unique values, using that nonclustered index will not save I/O during data retrieval. In fact, using the index would likely cause much more I/O than a sequential table scan of the table. Some examples of good candidates for a nonclustered index are invoice numbers, unique customer numbers, social security numbers, and telephone numbers.
Clustered indexes are much better than nonclustered indexes for queries matching columns that don't have a lot of unique values because clustered indexes physically order table data by clustered index order, allowing for sequential 16-KB I/O on the key values. Remember that it is important to get rid of page splitting on a clustered index to ensure sequential I/O. Some examples of possible candidates for a clustered index include states, company branches, date of sale, ZIP codes, and customer district. It would tend to be a waste to define a clustered index on the columns that have very unique values unless typical queries on the system fetch large sequential ranges of the unique values. The key question to ask when trying to pick the best column from each table to create the clustered index on is, "Will there be a lot of queries that need to fetch a large number of rows based on the order of this column?" The answer is very specific to each SQL Server environment. One company may do a lot of queries based on ranges of dates whereas another company may do a lot of queries based on ranges of bank branches.
Samples of WHERE predicates that benefit from clustered indexes:
…WHERE <column_name> > some_value
…WHERE <column_name> BETWEEN some_value AND some_value
…WHERE <column_name> < some_valueClustered index selection really involves two major decisions on the part of the DBA or SQL application developer. First, determine which column of the table will benefit most from the clustered index in terms of providing sequential I/O for range scans. Second, and just as important, is using the clustered index to affect the physical placement of table data in order to avoid hot spots on the hard drive(s) that the table is located on. A hot spot occurs when data is placed on a hard disk in such a way that many queries are trying to access data on that disk at the same time. This creates a disk I/O bottleneck, because more concurrent disk I/O requests are being received by that hard disk than it can handle. Solutions are to either stop fetching as much data from this disk or to spread the data across multiple disks to support the I/O demand. This type of consideration for the physical placement of data can be critical for good concurrent access to data among hundreds or thousands of SQL Server users.
These two decisions often conflict with each other and the best overall decision will have to balance the two. In high-user-load environments, improving concurrency by avoiding hot spots can often be more valuable than the performance benefit of placing the clustered index on that column.
Here is a common scenario to help illustrate clustered index selection. Suppose a table contains an invoice date column, a unique invoice number column, and other data. Suppose that about 10,000 new records are inserted into this table every day and that SQL queries often need to search this table for all records for one week's worth of data and many users need concurrent access to this table. The invoice number would not be a good candidate for the clustered index for several reasons. First, invoice numbers are unique and users don't tend to search on ranges of invoice numbers, so placing invoice numbers physically in sequential order on disk is not likely to be helpful because range scans on invoice numbers will likely not happen. Second, the values for invoice number likely increase monotonically (1001,1002,1003, and so on). If the clustered index is placed on invoice number, inserts of new rows into this table will all happen at the end of the table (beside the highest invoice number) and, therefore, on the same physical disk location, creating a hot spot.
Next, consider the invoice date column. In trying to maximize sequential I/O, invoice date would be a good candidate for a clustered index because users often are searching for one week's worth of data (about 70,000 rows). But from the concurrency perspective, invoice date may not be a good candidate for the clustered index. If the clustered index is placed on an invoice date, all data will tend to be inserted at the end of the table, given the nature of dates, and a hot spot will occur on the hard disk that holds the end of the table.
There is no perfect answer in the above scenario. It may be necessary to decide that it is worth the risk of hot spotting and choose to place the clustered index on invoice date in order to speed up queries involving invoice date ranges. If this is the case, carefully monitor disk queuing on the disks associated with this table and keep in mind that the inserts will likely need to queue up behind each other trying to get at the end of the table. My recommendation in this scenario is to not define a clustered index on invoice date or on invoice number because of the hot-spotting potential. Instead, find a column on the table that has data distributed in such a way that it does not follow the sequential pattern of invoice date and invoice number and has a fairly even distribution. If a clustered index is created on this evenly distributed data, invoice date and invoice number will be evenly distributed on disk. This even distribution, in conjunction with FILLFACTOR and PAD_INDEX, which will be discussed in the next section, will provide open data page areas throughout the table to insert data. These areas will be physically distributed evenly across the disks associated with this table. If a column with this type of distribution did not exist on the table, a possible solution could be an integer column added to the table and populated with values that are evenly distributed and the clustered index could be created on the column. This "filler" or "dummy" column with a clustered index defined on it is not being used for queries, but to distribute data I/O across disk drives evenly to improve table access concurrency and overall I/O performance. This can be a very effective methodology with large and heavily accessed SQL tables.
Let's consider another example that is more pleasant to work with. Suppose a table consists of invoice number, invoice date, invoice amount, sales office where the sale originated from, and other data. Suppose 10,000 records are inserted into this table every day. In this case, users most often query invoice amounts based on sales office. Thus, sales office should be the column on which the clustered index is created because that is the range on which scans are based. And because new rows being inserted will likely have a mix of different sales offices, inserts should be spread evenly across the table and across the disks on which the table is located.
Another way to think about hot spots is within the context of selects. If many users are selecting data with key values that are very close to but not the same row as each other, a majority of disk I/O activity will tend to occur within the same physical region of the disk I/O subsystem. This disk I/O activity can be spread out more evenly by defining the clustered index for this table on a column that will spread these key values evenly across the disk. If all selects are using the same unique key value, using a clustered index will not help balance the disk I/O activity of this table. Use of RAID (either hardware or software) would help alleviate this problem as well by spreading the I/O across many disk drives.
The type of behavior described here can be viewed as disk access contention. It is not locking contention. But sometimes the two can be related and resolved at the same time. SQL Server shared read locks are compatible with each other, so it is possible to have many read locks on the same 2-KB page without conflict. Other SQL Server locks, which are required for write activities, will necessarily block other incompatible write locks from accessing the same 2-KB page until the first lock is finished. Note that if SQL Server locking contention is occurring because many queries are trying to write rows on the same 2-KB page, redistribution of data by picking another column to place the clustered index on can help remedy the locking contention by distributing the problem column's data evenly. This reorients the physical ordering of the table data on the disk so that queries that were previously trying to lock the same 2-KB page for rows will now be locking different 2-KB pages for the same data. This technique works well unless some type of index is required on the problem column to help speed up queries. If a nonclustered index is placed on the problem column, locking contention will occur on the nonleaf 2-KB pages of the nonclustered index. When performing inserts only, use Insert Row Level (IRL) locking on that table. Use the command: "sp_tableoption 'tablename', 'insert row lock', 'true'" in ISQL/W to enable IRL locking for a particular table. When performing updates, IRL will not help. The only choice is not to have an index on that column to alleviate disk access or locking contention and find other columns that can be indexed to help queries.
Another recommendation is to be sure to define a clustered index on each table, even if queries accessing this table will not be using range scans, because SQL Server depends on the clustered index for disk space management purposes. Without a clustered index present, SQL Server inserts will always happen at the end of the table and hot spotting can occur. If there is no column on the table that will require range scans, pick the column that has the smallest byte size (example: integer) and distributes the data evenly across the disk.
If a SQL Server database will be experiencing a large amount of insert activity, it will be important to plan for providing and maintaining open space on index and data pages to prevent page splitting. Page splitting occurs when an index page or data page can no longer hold any new rows and a row needs to be inserted into the page because of the logical ordering of data defined in that page. When this occurs, SQL Server needs to create and link in a new 2-KB page to the full page and divide up the data on the full page among the two pages so that both pages now have some open space. This will consume system resources and time. It can also be detrimental in terms of optimal index page placement. Splitting the pages when inserts are performed can also cause deadlocks, even with IRL in most cases, because SQL Server needs exclusive locks for the pages involved.
When indexes are built initially, SQL Server places the index binary tree structures on contiguous physical pages, which allows for optimal I/O performance scanning the index pages with sequential I/O. When page splitting occurs and new pages need to be inserted into the logical binary tree structure of the index, SQL Server must allocate new 2-KB index pages somewhere. This occurs somewhere else on the hard drive and will break up the physically sequential nature of the index pages. This switches I/O operations from sequential to nonsequential and cuts performance in half. Excessive amounts of page splitting should be resolved by rebuilding the index to restore the physically sequential order of the index pages. This same behavior can be encountered on the leaf level of the clustered index, thereby affecting the data pages of the table.
In Windows NT/SQL Performance Monitor, keep an eye on "SQL Server: I/O Single Page Writes/Sec." Nonzero values for this counter tends to indicate that page splitting is occurring and that further analysis should be done with DBCC SHOWCONTIG.
The DBCC SHOWCONTIG is a very helpful command that can be used to reveal whether excessive page splitting has occurred on a table. Scan Density is the key indicator that DBCC SHOWCONTIG provides. It is good for this value to be as close to 100 percent as possible. If this value is well below 100 percent, rebuild the clustered index on that table with DBCC DBREINDEX to defragment the table.
Rebuilding a clustered index with DBCC DBREINDEX with the SORTED_DATA option is the fastest method. DBCC DBREINDEX is also the only way to rebuild a clustered index on a table with constraints on the column. If there are no constraints on the table, it is possible to drop and re-create the clustered index to rebuild the index and defragment the table.
SQL Server provides the FillFactor option on CREATE INDEX and DBCC REINDEX to provide a way to specify that amount of open space to leave on index and data pages. The PAD_INDEX option for CREATE INDEX applies what has been specified for the FillFactor option and applies the open space percentage on the nonleaf-level index pages. Without the PAD_INDEX option FillFactor mainly affects the leaf-level index pages of the clustered index. It is a good idea to use the PAD_INDEX option with FillFactor. More information on proper syntax for FillFactor and PAD_INDEX in Create Index and DBCC REINDEX can be found in SQL Server Books Online.
The optimal value to specify for FillFactor depends on how much new data is expected to be added within a given time frame into a 2-KB index page and data page. It is important to keep in mind that SQL Server index pages typically contain many more rows than data pages because index pages only contain the data for columns associated with that index, whereas data pages hold the data for the entire row. Also bear in mind how often there is a maintenance window that will permit the rebuilding of indexes to avoid page splitting. Strive toward rebuilding the indexes only as the majority of the index and data pages have become filled with data. Part of what allows this to happen is the proper selection of clustered index for a given table. If the clustered index distributes data evenly so that new row inserts into the table happen across all of the data pages associated with the table, the data pages will fill evenly. Overall, filling data pages evenly will provide more time before page splitting starts to occur and it is necessary to rebuild the clustered index. The other part of the decision is the FillFactor, which should be selected partly on the estimated number of rows that will be inserted within the key range of a 2-KB page for a given time frame and how often scheduled index rebuilds can occur on the system.
This is another situation in which a judgement call must be made, based on the performance tradeoffs between leaving a lot of open space on pages versus page splitting. If a small percentage for FillFactor is specified, it will leave large open spaces on the index and data pages. This helps avoid page splitting but will also negate some of the performance effect of compressing data onto a page. SQL Server performs faster if more data is compressed on index and data pages because it can generally fetch more data with fewer pages and I/Os if the data is more compressed on the pages. Specifying too high a FillFactor may leave too little open space on pages and allows pages to overflow too quickly, causing page splitting.
Before using FillFactor and PAD_INDEX, remember that reads tend to far outnumber writes, even in an OLTP system. Using FillFactor will slow down all reads, because it spreads tables over a wider area (reduction of data compression). Before using FillFactor, it is a good idea to use Performance Monitor to compare SQL Server reads to SQL Server writes and only use these options if writes are a substantial fraction of reads (for example, more than 30 percent).
If writes are a substantial fraction of reads, the best approach in a very busy OLTP system is to specify as high a FillFactor as feasible that will leave a minimal amount of free space per 2-KB page but still prevent page splitting and still allow the SQL Server to reach the next available time window for rebuilding the index. This method balances I/O performance (keeping the pages as full as possible) and page splitting avoidance (not letting pages overflow). This may take some experimentation with rebuilding the index with varying FillFactor settings and then simulating load activity on the table to validate an optimal value for FillFactor. The best practice, once the optimal FillFactor value has been determined, is to automate the scheduled rebuilding of the index as a SQL Server Task. Search in SQL Server Books Online with the string "creating a task" for more information on how to create SQL Server Tasks.
In the situation where there will be no write activity into the SQL Server database, FillFactor should be set at 100 percent so that all index and data pages are filled completely for maximum I/O performance.
When scaling databases past a few gigabytes it is important to have at least a basic understanding of Redundant Array of Inexpensive Disks (RAID) technology and how it relates to database performance.
The benefits of RAID are:
Mirroring is implemented by writing information onto two sets of drives, one on each side of the mirrored pairs of drives. If there is a drive loss with mirroring in place, the data from the lost drive can be rebuilt by replacing the failed drive and rebuilding the data from the failed drive's matching drive on the other side of the mirrorset. Most RAID controllers provide the ability to do failed drive replacement and rebuilding from the other side of the mirrored pair while Windows NT and SQL Server are online (commonly referred to as "hot-Plug"-capable drives). One advantage of mirroring is that it is the best-performing RAID option when fault tolerance is required. Each Windows NT/SQL Server write in the mirroring situation costs two disk I/O operations, one on each side of the mirrorset. The other advantage is that mirroring is more fault tolerant than parity RAID implementations. Mirroring can sustain at least one failed drive and might be able to survive failure of up to half the drives in the mirrorset without forcing the system administrator to shut down the server and recover from file backup. The disadvantage of mirroring is cost. The disk cost of mirroring is one drive for each drive's worth of data. RAID 1 and its hybrid, RAID 0+1 (sometimes referred to as RAID 10 or 0/1) are implemented via mirroring.
Parity is implemented by calculating recovery information about data written to disk and writing this parity information on the other drives that form the RAID array. If a drive should fail, a new drive is inserted into the RAID array and the data on the failed drive is recovered by taking the recovery information (parity) written on the other drives and using this information to regenerate the data from the failed drive. RAID 5 and its hybrids are implemented via parity. The advantage of parity is cost. To protect any number of drives with RAID 5, only one additional drive is required. Parity information is evenly distributed among all drives participating in the RAID 5 array. The disadvantages of parity are lack of performance and fault tolerance. Due to the additional costs associated with calculating and writing parity, RAID 5 requires 4 disk I/O operations for each Windows NT/SQL Server write, as compared to 2 disk I/O operations for mirroring. Read I/O operation costs are the same for mirroring and parity. Compaq's "Configuration and Tuning of Microsoft SQL Server 6.5 for Windows NT on Compaq Servers" goes into more detail about this I/O cost difference. Also, RAID 5 can sustain only one failed drive before the array must be taken offline and recovery from backup media must be performed to restore data.
Note As a general rule of thumb, be sure to stripe across as many disks as necessary to achieve solid performance. Windows NT/SQL Performance Monitor will indicate if Windows NT disk I/O is bottlenecking on a particular RAID array. Be ready to add disks and redistribute data across RAID arrays and/or SCSI channels as necessary to balance disk I/O and maximize performance.
Many hardware RAID controllers have some form of read and/or write caching on their controllers. Take advantage of this available caching with SQL Server because it can significantly enhance the effective I/O handling capacity of the disk subsystem. The principle of these controller-based caching mechanisms is to gather smaller and potentially nonsequential I/O requests coming in from the host server (hence, SQL Server) and try to batch them together with other I/O requests for a few milliseconds so that the batched I/Os can form larger (32–128 KB) and possibly sequential I/O requests to send to the hard drives. This, in keeping with the principle that sequential I/O is good for performance, helps produce more disk I/O throughput for the fixed number of I/Os that hard disks are able to provide to the RAID controller. RAID controller caching does not magically allow the hard disks to process more I/Os per second, it just uses some organization to arrange incoming I/O requests to make best possible use of the underlying hard disks' fixed amount of I/O processing ability.
RAID controllers usually protect their caching mechanism with some form of backup power. The backup power can help preserve the data written in the cache for some period of time (perhaps days) in case of a power outage. In production environments, adequate Uninterruptible Power Supply (UPS) protection further benefits the server by giving the RAID controller more protection and battery backup time, which it can use to flush data to disk in case power to the server is disrupted.
RAID 1 and RAID 0+1 offer the best data protections and best performance among RAID levels but cost more in terms of disks required. When the cost of hard disks is not a limiting factor, RAID 1 or RAID 0+1 are the best RAID choices in terms of both performance and fault tolerance.
RAID 5 provides fault tolerance at the best cost but has half the write performance of RAID 1 and 0+1 because of the additional I/O that RAID 5 has to do reading and writing parity information onto disk.
Best disk I/O performance is achieved with RAID 0 (disk striping with no fault-tolerance protection), but because there is no fault tolerance with RAID 0, this RAID level can only be typically used for development servers or other testing environments.
Many RAID array controllers provide the options of RAID 0+1 (also referred to as RAID 1/0 and RAID 10) over physical hard drives. RAID 0+1 is a hybrid RAID solution. On the lower level, it mirrors all data just like RAID 1. On the upper level, the controller stripes data across all of the levels below. Thus, RAID 0+1 provides maximum protection (mirroring) alongside high performance (striping). These striping and mirroring operations are transparent to Windows NT and SQL Server because they are managed by the RAID controller. The difference between RAID 1 and RAID 0+1 is on the hardware controller level and does not affect the customer in terms of physical hard drives required. RAID 1 and RAID 0+1 require the same number of drives for a given amount of storage. For more specifics on RAID 0+1 implementation of specific RAID controllers, contact the hardware vendor that produced the controller.
The following diagram illustrates the difference between RAID 0, RAID 1, RAID 5, and RAID 0+1. Be sure to contact the appropriate hardware vendors to learn more about RAID implementation specific to the hardware running SQL Server.
Figure 3. Common RAID levels
This is a very handy feature that allows disks to be added dynamically to a physical RAID array while SQL Server and Windows NT are online, as long as there are hot-plug slots available. Many hardware vendors offer hardware RAID controllers, which are capable of providing this functionality. Data is automatically restriped across all drives evenly, including the newly added drive, and there is no need to shut down SQL Server or Windows NT. It is advantageous to use this functionality by leaving hot-plug hard drive slots free in the disk array cages. Thus, if SQL Server is regularly overtaxing a RAID array with I/O requests (this will be indicated by Disk Queue Length for the Windows NT logical drive letter associated with that RAID array), it is possible to install one or more new hard drives into the hot-plug slot while SQL Server is still running. The RAID controller will redistribute some existing SQL data to these new drives so that SQL data is evenly distributed across all drives in the RAID array. Then the I/O processing capacity of the new drives (75 nonsequential/150 sequential I/Os per second) is added to the overall I/O processing capacity of the RAID array.
In Windows NT/SQL Performance Monitor, Logical and Physical Disk Objects provide effectively the same information. The difference is that Logical Disks in Performance Monitor is associated with what Windows NT sees as a logical drive letter. Physical Disks in Performance Monitor is associated with what Windows NT sees as a single physical hard disk.
To enable Performance Monitor counters, use the command diskperf.exe from the command line of a Windows NT command prompt window. Use 'diskperf –y' so that Performance Monitor will report Logical and Physical disk counters. This works when using hard drives or sets of hard drives and RAID controllers, without the use of Windows NT software RAID.
When utilizing Windows NT software RAID, use 'diskperf –ye' so that that Performance Monitor will report Physical disk counters across the Windows NT stripesets correctly. When 'diskperf –ye' is used in conjunction with Windows NT stripesets, Logical counters will not report correct information and should be disregarded. If Logical disk counter information is required in conjunction with Windows NT stripesets, use 'diskperf –y' instead. With 'diskperf –y' and Windows NT stripesets, Logical disk counters will be reported correctly but Physical disk counters will not report correct information and should be disregarded.
Note The effects of the diskperf command are not in effect until Windows NT has been restarted.
Note that hardware RAID controllers present the multiple physical hard drives that compose a single RAID mirrorset or stripeset to Windows NT as one single physical disk. Windows NT can proceed with Disk Administrator to associate logical drive letters to a hard disk and doesn't need to be concerned with how many hard disks are really associated with the single hard disk that the RAID controller has presented to it.
It is important to be aware of how many physical hard drives are associated with a RAID array because this information will be needed when determining the number of disk I/O requests that Windows NT and SQL Server are sending to each physical hard drive. Divide the number of disk I/O requests that Performance Monitor reports as being associated with a hard drive by the number of actual physical hard drives known to be in that RAID array.
In order to get a rough estimate of I/O activity per hard drive in a RAID array, it is important to multiply the number of disk write I/Os reported by Windows NT/SQL Performance Monitor by either 2 (RAID 1 and 0+1) or 4 (RAID 5). This will give a more accurate account of the number of actual I/O requests being sent to the physical hard drives, because it is at this physical level that the I/O capacity numbers for hard drives apply (75 nonsequential and 150 sequential per drive). But don't expect to be able to calculate exactly how much I/O is hitting the hard drives this way when the hardware RAID controller is using caching, because caching can significantly change the amount of I/O that is actually hitting the hard drives for the reasons explained above.
It is best to concentrate on disk queuing versus actual I/O per disk because, after all, why worry about I/O if it is not causing a problem? Windows NT can't see the number for physical drives in a RAID array, so to assess disk queuing per physical disk accurately, it is important to divide the disk queue length by the number of physical drives participating in the hardware RAID disk array that contains the logical drive being observed. Keep this number under 2 for hard drives containing SQL Server files. Try to keep this number 0 for hard drives containing SQL Server log files.
Windows NT provides fault tolerance to hard disk failure by providing mirrorsets and stripesets (with or without fault tolerance) by the Windows NT operating system instead of a hardware RAID controller. Windows NT Disk Administrator is used to define either mirrorsets (RAID 1) or stripesets with parity (RAID 5). Windows NT Disk Administrator also allows definition stripesets with no fault tolerance (RAID 0).
Software RAID utilizes more CPU resources, because Windows NT is the component managing the RAID operations versus the hardware RAID controller. Thus, performance with the same number of disk drives and Windows NT software RAID may be a few percent less than the hardware RAID solution if the system processors are nearly 100 percent utilized. But Windows NT software RAID will generally help a set of drives service SQL Server I/O better overall than those drives would have been able to service SQL Server separately, reducing the potential for an I/O bottleneck, leading to higher CPU utilization by SQL Server and thus better throughput. Software RAID can provide a better cost solution for providing fault tolerance to a set of hard drives.
For more information about configuring Windows NT software RAID, refer to Chapter 4, "Planning a Reliable Configuration," in Windows NT Server Online Help.
When dealing with smaller SQL Server databases located on a few disk drives, disk I/O parallelism will likely not come into play. But when dealing with large SQL Server databases stored on many disk drives, performance can be enhanced by using disk I/O parallelism to make optimal use of the I/O processing power of the disk subsystem.
Here are the areas of SQL Server activity that can be separated across different disk I/O channels to help maximize performance:
Distinct disk I/O channels refer mainly to distinct sets of hard drives or distinct RAID arrays, because hard drives are the most likely point of disk I/O bottleneck. But also consider distinct sets of RAID or SCSI controllers and distinct sets of PCI buses as ways to separate SQL Server activity if additional RAID controllers and PCI buses are available.
Transaction logging is primarily sequential write I/O. So, there is a lot of I/O performance benefit associated with separating SQL Server transaction logging activity from other nonsequential disk I/O activity. That allows the hard drives containing the SQL Server log files to concentrate on sequential I/O. (Remember that hard drives can provide 150 I/Os per second this way, as compared to 75.) There are times when the transaction log will need to be read as part of SQL Server operations like SQL Server replication, rollbacks, and deferred updates.
Tempdb is a database created by SQL Server to be used as a shared working area for a variety of activities, including temporary tables, sorting, subqueries and aggregates with GROUP BY or ORDER BY, queries using DISTINCT (temporary worktables have to be created to remove duplicate rows), cursors, and implementation of ODBC SQLPrepare by temporary stored procedures. If a SQL Server environment calls for extensive use of tempdb, consider putting tempdb onto a set of disks that separate it from other SQL files. This allows I/O operations to tempdb to occur in parallel to I/O operations to other SQL Server files for related transactions, and enhances performance.
The easiest way to keep tempdb separate from user databases is to keep the master database and any SQL devices used for tempdb expansion on disk drives or RAID arrays separate from the other SQL database devices holding busy databases. The master, Msdb, and model databases are not used much during production compared to user databases, so it is typically not necessary to consider them in I/O performance tuning considerations. The master database is normally used only for adding new logins, databases, devices, and other system objects.
There is additional administration involved with physically separating SQL Server tables and indexes from the rest of its associated database, so only do this for very active tables and indexes.
Large tables that will experience a lot of query or write activity can benefit from separation from other SQL Server files. The principle is to define a SQL Server database device on a disk drive or set of drives through RAID that do not contain other SQL Server data or log files. Then use the stored procedure sp_addsegment to create a segment and associate it with the database device. Next use the SEGMENT option of the CREATE TABLE statement to place the table on the segment. More information can be found by searching on "create table statement" and segment_name and sp_addsegment in SQL Server Books Online.
Segments can also be used to separate nonclustered indexes physically from their associated table, and this may bring useful disk I/O parallelism when it is known that a large table will need to regularly use certain indexes extensively for user queries. Use of the SEGMENT option of the CREATE INDEX statement allows for the physical placement of the index on a separate disk drive or set of drives via RAID.
BCP can be utilized with segments to physically partition a table at load time. End the BCP batch when the partitioning key changes, direct all future allocations to the new segment with sp_placeobject, and then start a new BCP batch for the next segment. Page splitting will destroy the partitioning over time (same as FILLFACTOR) but if only reads, updates, and deletes are done, it will stay partitioned forever.
The separation of SQL Server I/O activities is quite convenient with the use of hardware RAID controllers, RAID hot-plug drives, and online RAID expansion. When configuring a server to run SQL Server and configuring the drives for maximum I/O performance, the approach that provides the most flexibility is arranging the RAID controllers so that a separate RAID SCSI channel is provided for each of the separate SQL activities mentioned above. Because many RAID controllers provide more than one SCSI channel (some have two or three), and because it is unlikely to see an I/O bottleneck at the RAID controller level (it will be much more likely at the hard disk level), it is okay to start by splitting up SQL files by activity across RAID controller SCSI channels. But distinct SQL activities need to go on separate sets of physical hard drives. RAID controllers with more than one SCSI channel will be able to define distinct RAID arrays (mirrorsets or fault-tolerant stripesets) along each of its SCSI channels. Each of these distinct RAID arrays will look like a single physical drive in Windows NT Disk Administrator. It is then possible to associate logical drive letters to these RAID arrays and place SQL Server files on distinct RAID arrays based on type of activity.
Each RAID SCSI channel should be attached to a separate RAID hot plug cabinet to take full advantage of online RAID expansion (if available through the RAID controller). If the system is configured this way, it is possible to relate disk queuing back to a distinct RAID SCSI channel and its drive cabinet as Performance Monitor reports the queuing behavior during load testing or heavy production loads. If a drive cabinet is a hot-plug RAID cabinet, the RAID controller supports online RAID expansion, and slots for hot-plug hard drives are available in the cabinet, it is possible to overcome disk queuing on that RAID array by simply adding more drives to the RAID array until the Windows NT/SQL Performance Monitor reports that disk queuing for the RAID array has reached acceptable levels (0 for SQL Server log files, less than 2 for other SQL Server files). This can be done while SQL Server is online.
The techniques just described for optimizing disk I/O parallelism require varying levels of administration. Separation using segments does require regular attention. Some DBAs may prefer to avoid this administrative overhead. Instead of partitioning I/O capacity to separate areas, DBAs can consider creating a single large I/O "pool of drives" (excluding transaction log). The pool of drives may be a single RAID array that is represented in Windows NT as a single logical drive letter; or it may be multiple sets of RAID arrays that have a Windows NT stripeset with no fault tolerance defined across all of the RAID arrays to form a single logical drive letter to Windows NT and SQL Server. This simplifies SQL Server administration a great deal and may be more than sufficient in providing disk subsystem performance to SQL Server. The single pool of drives can be watched for disk queuing and, if necessary, more hard drives can be added to the pool to prevent disk queuing. This technique helps optimize for the common case, where it is not known which parts of databases may see the most usage. It is better not to have one-third or half of available I/O capacity segregated away on some other disk partition because 5 percent of the time SQL Server might be doing I/O to it. Overall, this simpler methodology may help make I/O capacity always available for common SQL Server operations.
By concentrating on key words to look for and with a little practice, you can use SQL Server 6.5 text-based ShowPlan to focus attention on problem SQL tables and queries. SQL Server Books Online provides information on meaning of terms displayed in ShowPlan output.
ShowPlan words to pay special attention to:
Reformatting
Indicates SQL Server thought it was a good idea to build a worktable and then create a clustered index on that worktable in tempdb for optimal performance. It's better to have that index placed well on the table in the first place.
Table Scan
Not always a bad word. If the table is small, a table scan will be very efficient. If the table is really big, it is important to define a better index on that table to prevent the table scan.
Worktable
Indicates that tempdb is being used for worktable creation. If many work tables are being created, pay attention to any heavy disk I/O activity to tempdb and watch for disk queuing. Consider moving tempdb onto its own disk I/O channel with a sufficient amount of drives for its I/O needs.
For more information on ShowPlan, please refer to Chapter 23 of SQL Server Books Online, "Understanding ShowPlan Output."
In graph mode, take note of the Max and Min values. Don't put too much emphasis on the average, because heavily polarized data points throw this off. Study the graph shape and compare to Min/Max to get an accurate feel for the behavior.
Use the <backspace> key to highlight counters with a white line.
Use the logging feature. It is possible to use Windows NT/SQL Performance Monitor to log all available Windows NT and SQL Server performance monitor objects/counters in a log file while at the same time looking at Performance Monitor interactively (chart mode). The setting of sampling interval determines how quickly the log file grows in size. Log files can get big very fast (for example, 100 MB in one hour with all counters turned on and a sampling interval of 15 seconds). Hopefully, on the test server, there will be a couple of gigabytes free to store these types of files. But if conserving space is important, try running with a large log interval so that Performance Monitor does not sample the system as often. Try 30 or 60 seconds. This way all of the counters are resampled with reasonable frequency, but a smaller log file size is maintained.
Performance Monitor also consumes a small amount of CPU and disk I/O resources. If a system doesn't have a lot of disk I/O and/or CPU to spare, consider running Performance Monitor from another machine to monitor the SQL Server over the network (graph mode only—it tends to be more efficient to log Performance Manager information locally on the SQL Server as compared to sending the information across a local area network, or LAN) or maybe reduce the logging to only the most critical counters.
It is good practice to log all counters available during performance test runs into a file for later analysis. That way any counter can be examined further at a later time. Configure Performance Monitor to log all counters into a log file and at the same time monitor the most interesting counters in one of the other modes, like graph mode. This way, all of the information is recorded but the most interesting counters are presented in an uncluttered Performance Monitor graph while the performance run is taking place.
Starting the logging feature
Stopping the logging feature
This feature is very handy for observing what Windows NT/SQL Performance Monitor recorded for a given time period if performance problems are known to have happened at that time on a server.
If there are problems getting the SQL Server counters to appear in Windows NT/SQL Performance Monitor, try referring to the following Microsoft Knowledge Base articles, available through the MSDN Library CD:
ID: Q127207 Missing Objects and Counters in Performance Monitor [winnt]
ID: Q103109 Changes to Performance Monitor After Installing SQL Server [winnt]
ID: Q112610 PRB: Performance Monitor for SQL Performance Counters Missing [sqlserver]
ID: Q115786 Counters in PerfMon Disappear after Removing SQL Server [winnt]
ID: Q173180 PRB: Cannot Reinstall SQL Server After Deleting Files Manually [sqlserver]
If none of these articles help, verify that the following NT Registry key is in place. Use regedt32.exe to look for "HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\MSSQLServer\Performance." If this key is not present, use regedt32.exe to manually add the key. Check for the presence of the following four basic performance monitor values and manually add the values with the following strings if they are not already present:
Close: REG_SZ: CloseSQLPerformanceData
Open: REG_SZ: OpenSQLPerformanceData
Collect: REG_SZ: CollectSQLPerformanceData
Library: REG_SZ: sqlctr60.dll
Another less common problem that may occur is that Performance Monitor files in \winnt\system32 can become problematic and need to be refreshed with the originals. One symptom of this may be that upon trying to start Performance Monitor, a dialog box pops up stating "Computer not found." The files are:
\winnt\system32\perfh009.dat
\winnt\system32\perfc009.dat
Refresh these two files by using expand.exe (available from the Windows NT Server installation CD) to decompress the original perfh009.da_ and perfc009.da_ from the Windows NT Server installation CD. First, copy these two compressed files into the \winnt\system32 directory. For more details about the expand.exe commands, type "expand /?" from the command line of the command prompt window. If necessary, copy the expand.exe executable from Windows NT installation media over to \winnt\system32.
The syntax for expanding the files is:
Expand perfh009.da_ perfh009.dat
Expand perfc009.da_ perfc009.dat
Figure 4. Performance Monitor examples
It is appropriate in performance tuning SQL Server to keep all of the server's processors busy to maximize performance but not so busy that processor bottlenecks occur.
The performance tuning challenge is that if CPU is not the bottleneck, something else is the bottleneck (a primary candidate being the disk subsystem), so the CPU is being wasted; CPU is usually the hardest resource to expand (above some configuration specific level, such as 4 or 8 on many current systems), so it should be seen as a good sign that CPU utilization is above 95 percent. At the same time, the response time of transactions should be monitored to ensure they are within reason; if not, >95 percent CPU usage may simply mean that the workload is just too much for the available CPU resources and either CPU has to be increased or workload has to be reduced or tuned.
Look at the Windows NT/SQL Performance Monitor counter "Processor: Processor Time %" to make sure all processors are consistently below 95 percent utilization on each CPU. "System: Processor Queue" is the processor queue for all CPUs on a Windows NT system. If "System: Processor Queue" is greater than 2, it indicates a CPU bottleneck. When a CPU bottleneck is detected, it is necessary to either add processors to the server or reduce the workload on the system. Reducing workload could be accomplished by query tuning or improving indexes to reduce I/O and, subsequently, CPU usage.
Another Performance Monitor counter to watch when a CPU bottleneck is suspected is "System: Context Switches/Sec" because it indicates the number of times a second that Windows NT and SQL Server had to change from executing on one thread to executing on another. This costs CPU resources. Context switching is a normal component of a multithreaded, multiprocessor environment, but excessive context switching will bog down a system. The approach to take is to worry about context switching only if there is processor queuing. If processor queuing is observed, use the level of context switching as a gauge when performance tuning SQL Server. Reduce the number of threads being used by SQL Server and watch to see its effect on context switching. "Max worker threads" and "RA worker threads" are the primary settings that should be used to eliminate too much thread usage by SQL Server. RA worker threads were discussed previously. Max worker threads are also modified via sp_configure or SQL Enterprise. Reduce max worker threads and watch processor queuing and context switching to monitor the effect.
DBCC SQLPERF (THREADS) provides more information about I/O, memory, and CPU usage mapped back to system process IDs. SQL Server Books Online contains more information on this. Execute the following SQL query to take a survey of current top consumers of CPU time: "select * from sysprocesses order by cpu desc."
Disk Write Bytes/Sec and Disk Read Bytes/Sec counters provide an idea of the data throughput in terms of bytes per second per logical drive. Weigh these numbers carefully along with Disk Reads/Sec and Disk Writes/Sec. Don't let a low amount of bytes per second lead you to believe that the disk I/O subsystem is not busy! Remember that a single hard drive is capable of supporting a total of 75 nonsequential or 150 sequential disk reads and disk writes per second.
As long as SQL Server log files are located on one set of logical drives and SQL Server data files on another separate set of logical drives, it is easy to use Performance Monitor Logical Drive counters to pinpoint the source of a disk bottleneck. Monitor the "Disk Queue Lengths" for all logical drives associated with SQL Server files and determine which files are associated with excessive disk queuing.
If Performance Monitor indicates that some of the logical drives are not as busy as others, there is the opportunity to move SQL Server device files from logical drives that are bottlenecking to drives that are not as busy. This will help spread disk I/O activity more evenly across hard drives.
One simple way to rebalance disk I/O when disk queuing is occurring is to use the SQL Server system stored procedure called sp_movedevice to relocate SQL Server database device files.
Caution Use sp_movedevice prior to moving the physical device or the database will be marked suspect. More information on sp_movedevice is available on SQL Server Books Online.
If there is more than one SCSI channel available and disk queuing is still occurring, it is possible that the SCSI channel is being saturated with I/O requests. This would be more likely to occur if many disk drives (10+) are attached to the SCSI channel and they are all performing I/O at full speed. In this case, it would be beneficial to take half of the disk drives and connect them to another SCSI channel to balance that I/O.
The "SQL Server: Cache Hit Ratio" can be made artificially high if Read-Ahead Manager is the component loading required pages in cache. It is possible to test this theory in benchmarking the application with Read-Ahead Manager turned off versus Read-Ahead Manager turned on and comparing cache-hit ratio. To turn off RA manager, use sp_configure to set RA worker threads to zero.
If it is discovered that the cache-hit ratio stays the same whether Read-Ahead Manager is there or not and the cache-hit ratio is high (> 95 percent), celebration is in order because that means there is sufficient RAM and adequate data cache allocation for this SQL Server. If the cache-hit ratio deteriorates dramatically after turning off Read-Ahead Manager, it is necessary to set SQL Server memory higher, which might mean adding more RAM to the server.
SQLTrace is a very handy tool to help pinpoint SQL queries that are consuming significant resources from a system. On busy OLTP systems, SQLTrace will return a very large amount of information that is difficult to go through by visual inspection. An easy way to overcome this tidal wave of information and take advantage of SQLTrace's debugging ability is setting up SQL Trace to trace SQL queries and their associated system resource consumption into a text-based log file and then use the SQL Server BCP utility to load this log file back into SQL Server for quick analysis by SQL query. Here is how to do it:
/* CREATES TABLE TO RECEIVE SQL TRACE DATA VIA BCP */
CREATE TABLE SQLTrace (
Event char(12) NULL ,
UserName char(30) NULL ,
ID int NULL ,
SPID int NULL ,
StartTime datetime NULL,
EndTime datetime NULL,
Application char(30) NULL,
Data text NULL ,
Duration int NULL,
CPU int NULL ,
Reads int NULL ,
Writes int NULL ,
NT_Domain varchar(30) NULL ,
NT_User varchar(30) NULL ,
HostName varchar(30) NULL ,
HostProcess varchar(13) NULL )
GO
Use the following instruction to import SQL Trace log information into a the SQL table defined above:
bcp master..sqltrace in c:\<pathname>\<sqltracefile>.log /Usa /c /P<sa password>
CREATE INDEX cpu_index ON SQLTrace(CPU)
GO
CREATE INDEX PhysicalDiskRead_index ON SQLTrace(Reads)
GO
CREATE INDEX PhysicalDiskWrites_index ON SQLTrace(Writes)
GO
CREATE INDEX duration_index ON SQLTrace(Duration)
GO
CREATE INDEX ntuser_index ON SQLTrace(NT_User)
GO
CREATE INDEX starttime_index ON SQLTrace(StartTime)
GO
select username,data from sqltrace order by CPU desc
select username,data from sqltrace order by reads desc
select username,data from sqltrace order by writes descThis topic comes up quite often. It is almost always better not to use this option. SQL Server data cache is used for all databases, including tempdb. Putting tempdb in RAM reduces SQL Server's flexibility for sharing that RAM to both tempdb and other databases. If a SQL Server's cache-hit ratio is really good, even with Read-Ahead Manager turned off (by setting RA worker threads to 0), with tempdb placed in RAM, and significant use of tempdb, it is okay to keep tempdb in RAM. But my recommendation is to concentrate on providing tempdb with its own set of disks to balance disk I/O and make sure there is minimal disk queuing on these disks for best tempdb performance. For maximum disk I/O performance, place tempdb on a RAID 0 array because tempdb holds temporary data and is re-created each time SQL Server is restarted anyway.
If it is known that a lot of ORDER BYs and GROUP BYs are used in a SQL Server environment, it means that SQL Server will create a lot of worktables to support these operations. If worktables are being created for REFORMATTING (creating a clustered index on a worktable because SQL Server didn't have a good index to work with on the real table), it is important to examine this table closely and place an index on the table where SQL Server needs it. Thus, SQL Server won't have to create the worktable in the first place.
If tempdb is placed in RAM and the SQL Server data cache is not holding enough of the frequently accessed pages from other databases, the cache-hit ratio will degrade and any disk I/O savings provided by having tempdb in RAM will be negated by the increased disk I/O required now that other data pages required have to be read off the disk instead of from the SQL Server data cache.
If there is plenty of RAM available on a server and it is observed that, during testing, cache-hit ratio stays really good (99 percent) at peak query loads with Read-Ahead Manager turned off (RA Worker Threads set to 0) and tempdb in RAM, there is a good case for keeping tempdb in RAM because the SQL Server is gaining disk write I/O performance to tempdb and not paying any penalty for it during the rest of its SQL Server operations that read data from the data cache. This will particularly benefit performance if the nature of a SQL Server application environment's tempdb operations are one-time-use only read and write operations.
Here are some tips for dealing with SQL Server deadlocking:
sp_tableoption tablename, 'insert row lock', TRUE
Caution Don't go right to IRL as your primary method to try to resolve deadlocking. It has sometimes been know to increase deadlocking.
Inside Microsoft SQL Server 6.5 has a detailed section on analyzing and resolving deadlock problems starting on page 685.
SQL Server I/O can be strongly influenced by the order in which a given SQL query joins tables. The best performance scenario is for SQL query to join tables with smallest number of row matches first to tables with larger number of row matches in ascending order, using efficient indexes to minimize pages fetched. This is due to the nature of nested iteration joins. The SQL Server 6.5 Performance Optimization and Tuning Handbook gives more information about this topic starting on page 87.
When SQL Server processes a join, it needs to select an outside table that gets scanned first to retrieve rows that match the criteria set by the SQL query. If this table is large, there will hopefully be a good index on that table that will reduce I/O. SQL Server then needs to pick the inside tables. The number of times the inside tables need to be accessed is determined by the number of rows found in the outside table that satisfy the query's join condition, referred to as SCAN COUNT in STATISTICS I/O output. The I/O performance of the scans of the inside table can be optimized by making sure that a good index is in place on the columns involved in the join criteria of the inside table.
The order in which tables appear in SHOWPLAN output indicates the SQL Server join order. The STATISTICS I/O output is not in the same order as join order, just the order that the tables appear in the query.
A general rule of thumb to follow with respect to join order is to make sure that for each SQL query with N tables, the query contains at least N-1 join conditions. On slow SQL queries, watch I/O counts, SHOWPLAN join order, and join conditions to help give SQL Server more flexibility with join ordering.
Example:
select * from tab1, tab2, tab3 where tab1.c1 = tab2.c1The preceding query has three tables in the join and, according to the N/N-1 rule, it should have at least two join conditions. It does not hurt to make the number of join conditions N instead of N-1 since it will give the SQL Server optimizer more flexibility when deciding on join order. If the above query is slow, modify the query, making sure there are indexes on column c1 on all tables unless the table is small enough to table scan efficiently:
select * from tab1,tab2,tab3 where tab1.c1 = tab2.c1 and tab2.c1 = tab3.c1 and tab1.c1 = tab3.c1
If the query is still slow at this point, verify the last time that the indexes were updated with DBCC SHOW_STATISTICS and run UPDATE STATISTICS if there have been a lot of rows added since the index was created or the last time UPDATE STATISTICS was executed.
Use of inequality operators in SQL queries will force databases to use table scans to evaluate the inequalities. This can create very high I/O if these queries regularly deal with very large tables.
Examples:
WHERE <column_name> != some_value
WHERE <column_name> <> some_value
Any WHERE expression with NOT in it
If these types of queries need to be run in your database environment, try to restructure the queries to get rid of the NOT keyword. For example:
Instead of:
select * from tableA where col1 != "value"Try using:
select * from tableA where col1 < "value" and col1 > "value"
This lets SQL Server make use of use of the index (preferably clustered in this case) if it is built on col1 versus needing to resort to a table scan.
After using SQLTrace to pinpoint SQL queries that are consuming a significant number of resources, use ISQL/W and ShowPlan to further analyze problem queries.
Look for opportunities to reduce the size of the resultset being returned by eliminating columns in the select list that do not need to be returned, eliminating the number of rows being returned, or redefining indexes so that overall I/O required by the SQL query is reduced.
This method can be especially helpful to SQL programmers who do SQL work with ActiveX® Data Objects (ADO), Remote Data Objects (RDO), and/or Data Access Object (DAO) in Visual Basic®, Visual C++, or Visual C++ and Microsoft Foundation Classes (MFC). ADO, RDO, DAO, and MFC provide programmers with great database development interfaces that allows them to gain rich SQL rowset functionality without needing a lot of SQL programming experience. But these benefits come at a cost. Programmers can expose themselves to performance problems if they do not take into careful account the amount of data their application is returning to the client, stay aware of where the SQL Server indexes are placed, and how the SQL Server data is arranged. SQLTrace and ShowPlan are very helpful tools for pinpointing these problem queries.
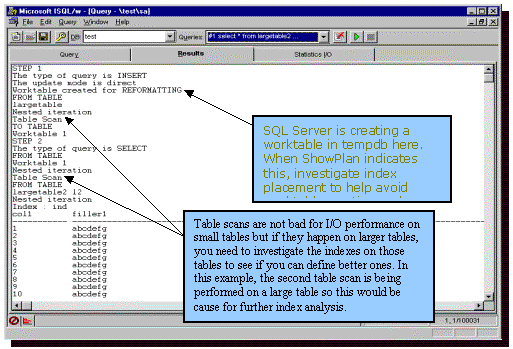
Figure 5. ShowPlan examples
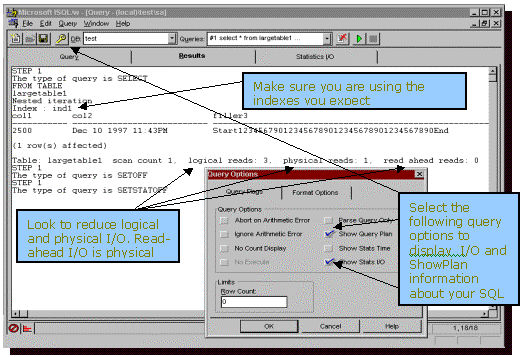
Figure 6. ShowPlan examples
On very hot (heavily accessed) tables, if there are columns that a SQL application does not need regularly, it makes sense to move them to another table. The more columns that are eliminated, the better for reducing I/O and increasing performance.
For those parties implementing SQL Server database systems on EMC Symmetrix Enterprise Storage Systems, there are some disk I/O balancing methods that should be kept in mind because of the unique nature of EMC Symmetrix Storage that will help avoid disk I/O bottleneck problems and maximize performance.
Symmetrix Storage Systems contain up to 4 GB of RAM cache and contain internal processors within the disk array that help speed the I/O processing of data without using host server CPU resources. Within the Symmetrix box, there are four major components to understand when balancing disk I/O. One issue is the 4-GB cache inside the Symmetrix. There are up to 32 SA channels that can be used to cable up to 32 SCSI cards from Windows NT host servers into the Symmetrix. All of these SA channels can simultaneously request data from the 4-GB cache. Then, within the Symmetrix box, there are up to 32 connectors, called DA controllers, which are internal SCSI controllers that connect all of the internal disk drives within the Symmetrix into the 4-GB internal cache. And, finally, there are the hard drives themselves.
A note about the EMC hard drives: They are SCSI hard drives with the same I/O capability as the other SCSI drives that have been discussed in this article (75/150 rule applies here). One feature commonly used with EMC technology is referred to as "hyper-volumes." A hyper-volume is defined as a logical division of an EMC hard drive such that to Windows NT Disk Administrator, the hyper-volume looks just like another physical drive, so they can be manipulated with Windows NT Disk Administrator like any other disk drive. Multiple hyper-volumes can be defined on an EMC drive. It is very important, when conducting database performance tuning on EMC storage, to be sure to work closely with EMC field engineers to identify how hyper-volumes are defined (if there are any), because it is important to avoid overloading a physical drive with database I/O. This can happen easily if two or more hyper-volumes are believed to be separate physical drives but in reality are two or more hyper-volumes on the same physical drive.
The best way to take advantage of the EMC architecture with respect to SQL Server is to ensure SQL Server I/O activities are divided evenly among distinct DA controllers. This is because DA controllers are assigned to a defined set of hard drives. As we have described in this document, it is unlikely that you will bottleneck a SCSI controller. What we are concerned about in this case is not that the DA controller will suffer an I/O bottleneck, but that the set of hard drives associated with a DA controller may suffer a bottleneck. Within the context of DA controllers and their associated disk drives, SQL Server disk I/O balancing is accomplished the same way as with any other vendor's disk drives and controllers (which has already been discussed in this article). With EMC storage, it is critical to be aware of where all hyper-volumes are located.
In terms of monitoring the I/O on a DA channel or separate physical hard drives, get help from EMC technical support staff because this I/O activity is occurring beneath the 4-GB EMC cache and is not visible to Windows NT/SQL Performance Monitor. EMC storage has internal monitoring tools that will allow an EMC technical support engineer to monitor I/O statistics within the EMC unit. Performance Monitor can only see I/O coming to and from an EMC storage unit by the I/O coming from an SA channel. This is enough information to indicate that a given SA channel is queuing Windows NT disk I/O requests, but not enough to tell which disk or disks are causing the disk queuing. If an SA channel is queuing, it not necessarily the SA channel causing the bottleneck; it could be (and more likely is) the disk drives that are causing the delay in servicing disk I/O. One way to isolate the disk I/O bottleneck between the SA channels and the DA channels and drives is to add another SCSI card to the host server and connect it to another SA channel. If Performance Monitor indicates that I/O across both SA channels has not changed in volume and disk queuing is still occurring, it indicates that it is not the SA channels that are causing the bottleneck. Another way to isolate the I/O bottleneck is to have an EMC engineer monitor the EMC system and analyze which drives or DA channels are bottlenecking, using EMC monitoring tools.
Divide SQL Server activities evenly across as many of the disk drives as are available. If working with smaller database that will sustain a large amount of I/O, consider carefully the size of hyper-volume to have EMC technical engineers define. Suppose the SQL Server will consist of a 30-GB database. EMC hard drives can provide up to 23 GB in capacity. So, it is possible to fit the entire database onto two drives. From a manageability and cost standpoint, this might seem appealing, but from an I/O performance standpoint, it is not. An EMC storage unit may have more than 100 internal drives to work with. Involving only two drives for SQL Server may lead to I/O bottlenecks. Consider defining smaller hyper-volumes, perhaps 2 GB each. This means close to 12 hyper-volumes may be associated with a given 23-GBhard drive. Assuming 2-GB hyper-volumes, 15 hyper-volumes will be required to store the database. Make sure that each hyper-volume is associated with a separate physical hard drive. Do not use 12 hyper-volumes from one physical drive and then another 3 hyper-volumes associated on another physical drive because that is the same as using two physical drives (150 nonsequential I/O and 300 sequential I/O across the two drives). But with 15 hyper-volumes, each of which are associated with a separate physical drive, SQL Server will be utilizing 15 physical drives for providing I/O (1,125 nonsequential/2,250 sequential I/O activity per second across the 15 drives).
Also consider employing several EMC SA channels from the host server to divide the I/O work across controllers. This makes a lot of sense for host servers that support more than a single PCI bus. In this case, consider using one SA channel per host server PCI bus to divide I/O work across PCI buses as well as SA channels. On EMC storage systems, each SA channel is associated to specific DA channel and, hence, a specific set of physical hard drives. Because SA channels read and write their data to and from the 4-GB RAM cache (inside the EMC storage system), it is unlikely that the SA channel will be a point of I/O bottleneck. In keeping with the idea that SCSI controller bottlenecks are not likely, it is probably best to invest time in concentrating on balancing SQL Server activities across physical drives versus worrying too much about how many SA channels to utilize.
"Be prepared!" is a motto that is very applicable to this area. Proactively surf the http://www.microsoft.com/support/ for latest known issues related to SQL Server and other Microsoft products.
Verify that the latest Windows NT and SQL Server Service Packs are installed on the server. To download the latest service packs go to http://www.microsoft.com/ntserver/default.asp or http://www.microsoft.com/sql/default.asp and then go to the download area. Note that some of the service packs need to be unzipped with the "-d" option in order to unzip properly and create required subdirectories. Service pack installation will fail if the service packs are unzipped improperly.
There is some really helpful and practical information in this book. Contains solutions to common problems such as representing and querying hierarchical data. Chapter 28 is dedicated to Optimizing SQL queries.
This is a great book that gets right to the critical subject matter on SQL Server performance tuning.
This book gives some good DBA and application developer guidance. It covers many SQL Server topics in addition to many chapters oriented toward performance.
More detailed information about RAID, RAID terminology, and disk arrays.
Order via phone in North America by calling 1-800-MSPRESS. This book provides great insight into SQL Server internal data structures, implementation details, configuration options, cursors, SQL Server application development guidance and much more. The author was development chief of the SQL Server team for many years. This book provides great information about how all components of SQL Server function. It complements the following recommended reading item.
There are many useful Compaq white papers related to Microsoft products on http://www.compaq.com/support/techpubs/. Here are three of the most relevant to SQL Server performance tuning:
30-page white paper from Compaq's Windows NT integration team. It details hardware performance characteristics of Compaq hard drives. This white paper provides a more detailed drill-down into physical drive behavior. The information contained in this paper will be pretty much applicable to whatever SCSI hard drive available from Compaq or other vendors.
Another Compaq white paper describes maximizing performance for SQL Server backup and restores. It is a comprehensive description of how the Compaq Database Engineering team utilized SQL Server 6.5 striped dump technology and multiple DLT tape drives to achieve backup and restore speeds around 50 GB per hour. Required reading DBAs that need to work with larger SQL Server databases.
Microsoft SQL Server Books Online has a very useful performance section in the Database Developers Companion, Chapter 5. Also, SQL Server Books Online provides information on the meaning of terms displayed in ShowPlan output in the chapter "Understanding ShowPlan Output." Install SQL Server Books Online on hard disk, either with the SQL Server client utilities or with the SQL Server full server installation.
Microsoft SQL Server Developer's Resource Kit. Available on the MSDN Library CD (Technical Articles/Database and Messaging Services/Microsoft SQL Server). All documents are in Microsoft Word 97 format and are saved as self-extracting ZIP files. Many white papers covering various SQL Server topics are available for download in this kit.
The following Microsoft Knowledge Base articles are included on the MSDN Library CD:
ID: Q110352 INF: Optimizing Microsoft SQL Server Performance
ID: Q125770 INF: Locking Behavior of Updates and Deletes in SQL Server
ID: Q162361 INF: Understanding and Resolving SQL Server Blocking Problems
ID: Q167711 INF: Understanding Bufwait and Writelog Timeout Messages
ID: Q102020 INF: How to Monitor Disk Performance with Performance Monitor
ID: Q167610 INF: Assessing Query Performance Degradation
ID: Q89385 INF: Optimizer Index Selection with Stored Procedures
ID: Q166967 INF: Proper SQL Server Configuration Settings
ID: Q117143 INF: When and How to Use dbcancel() or sqlcancel()
The following articles can also be found on the MSDN Library CD:
Shapiro, Adam. "Microsoft SQL Server Performance Tuning and Optimization for Developers, Part 1: Overview of Performance Issues." (Conference Papers/Tech*Ed 97 Conference Papers/Data Management)
Shapiro, Adam. "Microsoft SQL Server Performance Tuning and Optimization for Developers, Part 2: The Query Optimizer." (Conference Papers/Tech*Ed 97 Conference Papers/Data Management)
Shapiro, Adam. "Microsoft SQL Server Performance Tuning and Optimization for Developers, Part 3: Configuring SQL Server for Performance." (Conference Papers/Tech*Ed 97 Conference Papers/Data Management)