Mark Gendron
Microsoft Developer Network Technology Group
August 12, 1996
Click to open or copy the files in the Build421 sample application for this technical article.
Click to open or copy the files in the Build65 sample application for this technical article.
Upgrading to a new version of Microsoft® SQL Server can be a daunting prospect—the plethora of new features can seem overwhelming and the idea of introducing something new into a system after you have smoothed out all the wrinkles may seem less than appealing. Modifying your database schema to use new features can be costly and may have unintended effects on your system. Nevertheless, the gains can also be worth the cost in terms of better performance, simpler code, and easier maintenance in the future.
The purpose of this article is to guide the reader through the process of updating a Microsoft SQL Server version 4.21 database to take advantage of new features introduced in versions 6.0 and 6.5. To illustrate the upgrade process, a sample version 4.21 database is provided. This article does not emphasize the mechanics of performing a server upgrade, which is covered in the product documentation.
There are good reasons to upgrade to Microsoft® SQL Server version 6.5 even if you do not wish to invest significant budget and development time in updating your code and adopting new features. For example, simply upgrading your server to version 6.5 will allow you to take advantage of internal optimizations to the Microsoft SQL Server product. You may also benefit from easier system administration via new tools like SQL Enterprise Manager (introduced in version 6.0).
Upgrading from version 4.21 can be as simple as installing the new version on your server and checking your database for a few simple "gotchas." Upgrading can also be as complex as redesigning your database and your client applications to take advantage of a host of new features.
This article examines upgrading from your version 4.21 database to version 6.5 by addressing the following areas:
To demonstrate the issues discussed in this article, I have developed a sample database that can be built in both versions 4.21 and 6.5 of Microsoft SQL Server. This is a simple database for organizing and managing content for a World Wide Web site and publishing that content. The database tracks both hierarchical content organization (directories and/or virtual roots) and hyperlinks.
This article is not intended to deal with database design. Database purists will note that this is neither a logical model nor a complete physical model. It is a simplistic physical design that is adequate for our purposes.
Samples used in this article were developed on the following versions of Microsoft SQL Server:
The development server was a Dell Omniplex 590 running Microsoft Windows NT® version 4.0 (build 1314).
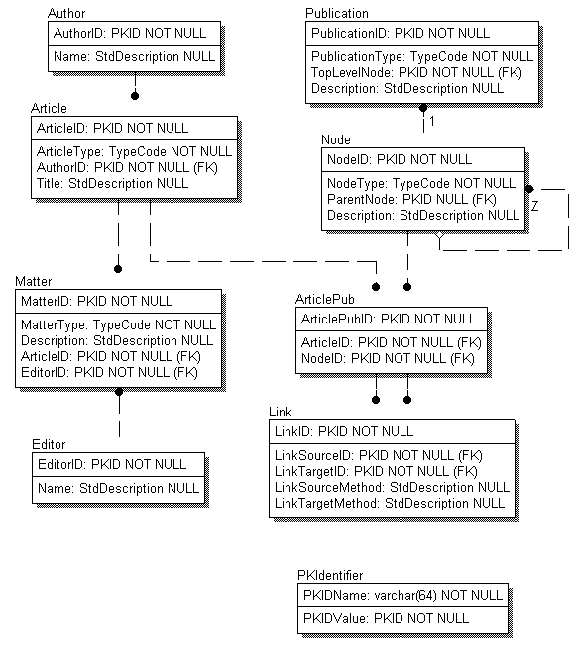
Figure 1. Sample database schema for Microsoft SQL Server version 4.21
Figure 1 (above) shows the relationships of the following tables in the database:
The database contains the following stored procedures:
User-defined datatypes are used in the sample database to make the design easier to follow. Some of these would obviously not be appropriate in a real-world physical database implementation.
To build the sample database you will need to follow the steps below. Note that there are separate versions of the sample scripts for versions 4.21 and 6.5. The script names are the same for each version.
Assuming that you will be upgrading your current Microsoft SQL Server version 4.21 installation to run version 6.5, there are basically two ways to proceed:
The mechanics of the upgrade process are explained quite well in the documentation that accompanies versions 6.0 and 6.5. You may refer to Upgrading SQL Server in the online documentation to review these steps. Although I will refer to some of these steps, they will not be covered extensively in this article.
Whether you upgrade Microsoft SQL Server or reinstall it, and regardless of whether you will make significant changes to your database, any upgrade effort requires due diligence to protect your data. You will want to back up everything in sight to protect against any difficulties in the upgrade process. You may also want to test the referential integrity of your data and identify any referential integrity breakdowns before you upgrade. Although this has nothing to do with the upgrade process itself, let's face it: Changes make customers nervous, and rightfully so. If problems are identified after the upgrade, you may take some heat for it, even if the problems have nothing to do with your upgrade. A little extra coverage never hurt anyone—least of all a developer or a system administrator!
The issues covered in this section are:
All too often, Microsoft SQL Server databases are "documented" only in the system tables. This is an unfortunate side-effect of overly ambitious development schedules and/or careless developers. Even if the database was religiously documented during development, subsequent changes may not be reflected in the documentation. Care should be taken to have the documentation updated whenever a change is made to the database. Unfortunately, in a world of late-night fixes and overworked operations personnel, this does not always happen.
Even if you do have database documentation and it appears to be accurate, you may want to buy some additional peace of mind by reverse-engineering the production database to produce a "snapshot" of its design prior to the upgrade. If discrepancies are found after the upgrade, this snapshot will prove valuable in determining whether they arose during the upgrade process or afterward. This, too, may provide some valuable coverage.
Taking a snapshot of the database is simple if you have a database modeling tool like ERwin by Logic Works to do this work for you. If you don't have appropriate software, you can still produce some crude (but accurate) scripts by using Transact-SQL commands. A trick that I like to use is to generate these statements for all database objects by linking to the system tables. For example, the following statement will generate an SP_HELP command for each table in the database:
SELECT 'sp_help '
+ name + char(10)
+ 'go' + char(10)
FROM sysobjects
WHERE type = 'U'
You can then paste the resulting SP_HELP commands into ISQL/W and generate definitions for all tables, indexes, primary keys, and foreign keys in your database. A similar statement can be used to generate scripts for all triggers and stored procedures:
SELECT 'sp_helptext '
+ name
+ char(10)
+ 'go'
+ char(10)
FROM sysobjects
WHERE type in ('TR','P')
ORDER BY type, name
Similar commands can be used to document other database objects, such as rules, defaults, and views. With luck, the scripts that you generate will match both your published documentation and the scripts in your source code management system.
Before upgrading, use the DBCC command to check the consistency of your database. There are several DBCC options available. You should at least use CHECKDB and NEWALLOC. These options will verify your data and index page linking, index sorting, pointer consistency, page and extent usage, and so on.
If problems are found, you will need to take steps to repair the database before proceeding. Be sure to back up the database before doing so.
By default, the Microsoft SQL Server version 4.21 setup program uses the 850 Multilingual character set and a binary sort. In version 6.5, the default character set is ISO and the default sort is dictionary order, case-insensitive.
If you upgrade your existing server, version 6.5 will use the same character set and sort order that was selected for your version 4.21 database. If you prefer to uninstall version 4.21 and install version 6.5, be sure to select the correct character set and sort order. If they are different after you upgrade, you can expect to see different results from some of your queries.
A properly designed relational database will include primary and foreign key declarations to define referential integrity rules. Because version 4.21 lacks declarative referential integrity (DRI), your database should also include triggers to enforce each foreign key relationship. If any of these triggers are missing or have been compromised in any way, your data may contain breakdowns in referential integrity. In other words, you may have a child entity containing one or more records whose foreign key attribute(s) do not have a matching primary key value in the parent entity.
For example, in our database there are four Author records defined in our sample data set. The AuthorID values for these records are 1 through 4. If the Article table were to contain a record in which AuthorID (the foreign key) was set to 5, then the Article record would reference an Author record that does not exist. This is an example of a breakdown in referential integrity.
Writing queries to verify referential integrity can be time-consuming if your database is large or if there are a large number of foreign key declarations. If the database includes triggers to enforce all foreign key relationships, this is a good sign that there should be few—if any—referential integrity breakdowns. If you see "danger signs," you may want your test plan to include a full set of queries to check referential integrity. "Danger signs" include:
If you discover referential integrity breakdowns, you should resolve these before upgrading your database. Depending on the circumstances of the breakdown, you may want to work with your customer to resolve these or quietly resolve them yourself. If you find significant problems with the database architecture, you may need to push for more development and test resources than you had originally planned for. With luck, the bearer of bad tidings will not be slain.
Beginning with Microsoft SQL Server version 6.0, new keywords and reserved words were introduced that may conflict with attribute names in your version 4.21 database. Some of these keywords are specific to Microsoft SQL Server and some have been introduced for ANSI compliance. A list of these keywords can be found in the online documentation.
You probably know that you should run the CHKUPG.EXE utility to identify any keyword or reserved word conflicts in your version 4.21 database. If you are using attribute names that conflict with any keywords or reserved words, you will need to correct this before you upgrade. Unfortunately, CHKUPG.EXE is not as thorough as you might expect it to be. Consider the following table definition and stored procedure:
CREATE TABLE CheckUpgrade
/* keywords */
(identitycol int NOT NULL,
constraint int,
floppy varchar(24),
/* reserved words */
cascaded bit,
deferred tinyint,
retaindays smallint)
CREATE PROCEDURE TestCheckUpgrade
AS BEGIN
CREATE TABLE #temp1
/* keywords */
(identitycol int NOT NULL,
constraint int,
floppy varchar(24),
/* reserved words */
cascaded bit,
deferred tinyint,
retaindays smallint)
DROP TABLE #temp1
END
Both of these objects use keywords and reserved words as identifiers (bold text). Let's run CHKUPG.EXE and see what happens.
Database: Content
Status: 0
(No problem)
Missing objects in Syscomments
None
Keyword conflicts
Column name: CheckUpgrade.CASCADED [SQL-92 keyword]
Column name: CheckUpgrade.CONSTRAINT
Column name: CheckUpgrade.DEFERRED [SQL-92 keyword]
Column name: CheckUpgrade.FLOPPY
Column name: CheckUpgrade.IDENTITYCOL
Column name: CheckUpgrade.RETAINDAYS [SQL-92 keyword]
What's this? CHKUPG.EXE found the violations in the CheckUpgrade table definition, but it missed the violations in the TestCheckUpgrade procedure! This stored procedure will build correctly in version 4.21, but it cannot be built in versions 6.0 or 6.5. If you try to upgrade your server, the database that contains this procedure will not upgrade successfully.
Another situation that CHKUPG.EXE will not detect is syntax that is valid in version 4.21 but not in versions 6.0 or 6.5. Here is an example:
CREATE PROCEDURE AuthorSummary
AS BEGIN
SELECT AuthorID,
COUNT(*)
FROM Article
GROUP BY ArticleType
END
In version 4.21, your query may roll up (group) its results by an attribute that is not included in the SELECT list. ANSI-92 prohibits this, so this stored procedure will not compile in version 6.0 or 6.5. This procedure could be upgraded by adding ArticleType to the SELECT list.
Naturally, CHCKUPG.EXE cannot detect any conflicts in code that does not exist in your database. Any embedded Transact-SQL commands outside your database may also contain keyword and reserved word conflicts. You will need to look very carefully at your client applications, your production batch scripts, and so on. If your system only allows database access via stored procedures, this will not be a problem because you will identify and correct those stored procedures when you test your database.
If you are concerned about keyword and reserved-word conflicts (and you should be), you should seriously consider testing all of your database build scripts on a server running Microsoft SQL Server version 6.5 before you perform your upgrade.
If you use any third-party tools that have not been upgraded for compatibility with Microsoft SQL Server versions 6.0 and 6.5, you will need to consider their effect on your development and maintenance efforts. Code generators that are only SQL Server version 4.21–aware may violate any of the keywords, reserved words, or syntax that have been discussed. Data modeling packages that were designed for version 4.21 will not recognize the new sysconstraints system table; they will not be able to generate or interpret the declarative referential integrity enhancements that will be discussed later in this article.
If you use a third-party tool that must create or interpret objects in your database, it is a safe bet that this tool must be upgraded to work with version 6.0 or 6.5. Unless you can live without this tool, you will want to investigate before proceeding with your upgrade.
If you want to take advantage of some of the latest Microsoft SQL Server features, consider investing a bit more time and budget in your upgrade. There are a host of new features in version 6.5 that can be adopted at varying costs and with minimal impact on other aspects of your system. The following features will be addressed:
Microsoft SQL Server version 6.0 introduced Declarative Referential Integrity (DRI). DRI offers ANSI-standard attribute constraints such as PRIMARY KEY, FOREIGN KEY, CHECK, DEFAULT, and UNIQUE. To enhance the DRI capability of version 6.0, the new Identity property has also been introduced. The DRI capabilities of Microsoft SQL Server offer more sophisticated methods for enforcing your business rules in your database. In some cases (though not all), you will be able to eliminate complex triggers and replace them with simple DRI constraints in your CREATE TABLE statements. Microsoft SQL Server will enforce these constraints automatically without the need for you to write any additional code.
Business rules that can be modeled with simple Boolean expressions can usually be enforced with DRI. For example, the following rules can be enforced with the CHECK constraint:
There are some business rules that cannot be modeled with DRI constraints but can be enforced with triggers. Here are some business rules that cannot be enforced using DRI constraints:
Constraints are defined in a new system table called sysconstraints.
A primary key consists of one or more fields that uniquely identify a record in a table. A foreign key is one or more fields that refer to a primary key in another table. In our example, consider the Author and Article tables, and their primary and foreign keys:
CREATE TABLE Author
(AuthorID PKID,
Name StdDescription)
exec sp_primarykey Author, AuthorID
CREATE TABLE Article
(ArticleID PKID,
ArticleType TypeCode,
AuthorID PKID,
Title StdDescription NULL)
exec sp_primarykey Article, ArticleID
exec sp_foreignkey Article, Author, AuthorID
Here we have created the two tables, declared a primary key on each, and declared a foreign key in the Article table. Unfortunately, defining these keys does not mean that the database will enforce them! In version 4.21, primary and foreign key declarations are for documentation purposes only; calling sp_primarykey and sp_foreignkey simply creates entries in the syskeys table and Microsoft SQL Server does nothing more with them. To enforce the primary keys, a unique index must be created:
CREATE UNIQUE CLUSTERED INDEX XPKAuthor
ON Author (AuthorID)
In order to enforce the foreign key, several triggers must be created:
| Table | Operation | Trigger |
| Author | Delete | tD_Author |
| Author | Update | tU_Author |
| Article | Insert | tI_Article |
| Article | Update | tU_Article |
Each trigger must check whether the requested operation violates the foreign key relationship. If it does, the trigger will roll back the transaction and raise an error message.
This multistep process of declaring and enforcing referential integrity is one reason why referential integrity breakdowns are so common in version 4.21 databases: Tables may be defined with primary and foreign key declarations but without unique indexes and triggers to actually enforce the relationship rules.
Beginning with Microsoft SQL Server version 6.0, triggers are no longer needed to enforce foreign key relationships, and unique indexes are not required to enforce primary keys. In their place, ANSI-standard attribute constraints are introduced. Consider the updated declarations for the Author and Article tables:
CREATE TABLE Author
(AuthorID PKID IDENTITY(1,1) PRIMARY KEY CLUSTERED,
Name StdDescription NULL)
CREATE TABLE Article
(ArticleID PKID IDENTITY(1,1) PRIMARY KEY CLUSTERED,
ArticleType TypeCode,
AuthorID PKID FOREIGN KEY (AuthorID) REFERENCES Author(AuthorID),
Title StdDescription NULL)
Table definitions in versions 6.0 and 6.5 also allow ANSI-standard DEFAULT and CHECK constraints, which can replace the old-style defaults and rules. Using defaults and rules required that the defaults and rules first be created and then bound to either a specific column or to a user-defined datatype. The ANSI-standard DEFAULT and CHECK constraints simplify this process considerably. Note that the version 4.21 rule syntax and default syntax are still supported for backward compatibility. They can still be useful if you want to define these constraints for a user-defined datatype rather than defining them column by column.
By defining primary and foreign keys in the table declaration, we eliminate the need for the calls to sp_primarykey and sp_foreignkey. Unique indexes need no longer be explicitly declared on the primary key attributes, and we can do away with the triggers—the database enforces the relationships automatically. That's a lot of code that we can eliminate. Less code means less maintenance and fewer chances to forget to build an object or relationship when recreating the database.
In the above examples, I tossed in a little something extra: an Identity property. The Identity property allows you to specify a column that will be automatically populated with an incremented value each time a new record is added to the table. In the above examples, we have specified that we will start at 1, and increment by 1. This is the default seed and increment, but it is never a bad idea to specify such information for clarity.
Using the Identity property on the primary key attributes has several advantages over the method we used in the sample version 4.21 database:
By using the Identity property, our InsertArticle procedure can be rewritten as follows (note that the deleted code is displayed in bold type for clarity):
CREATE PROCEDURE InsertArticle
(@ArticleID PKID OUT,
@ArticleType TypeCode,
@AuthorID PKID,
@Title StdDescription)
AS BEGIN
DECLARE @ArtID PKID
DECLARE @rc int
EXECUTE @rc = GetNextPKID
@PKIDName = 'ArticleID',
@PKIDValue = @ArtID OUT
IF @rc = -1 GOTO ERROR_EXIT
INSERT INTO Article
(ArticleID,
ArticleType,
AuthorID,
Title)
VALUES
(@ArtID,
@ArticleType,
@AuthorID,
@Title)
IF @@rowcount <> 1 GOTO ERROR_EXIT
SUCCESS:
SELECT @ArticleID = @ArtID
SELECT @ArticleID = @@IDENTITY
RETURN 0
ERROR_EXIT:
/* Raise an error message. */
RETURN -1
END
Note the use of the new global variable, @@IDENTITY. After an INSERT statement involving an Identity column, this global variable will always contain the most recently assigned Identity value for the current process.
It is possible to insert specific values into an Identity column by setting the table's IDENTITY_INSERT option, as follows:
SET IDENTITY_INSERT Article ON
/* INSERT statement including IDENTITY value */
SET IDENTITY_INSERT Article OFF
This technique is useful when loading data for which you must guarantee specific Identity values to maintain referential integrity. For an example of how to use the IDENTITY_INSERT option, see the data load scripts for the version 6.5 sample database.
Microsoft SQL Server version 6.5 introduces support for the following ANSI-standard join clauses:
Although the old-style join operators are still supported for compatibility, this support may be dropped in future releases of Microsoft SQL Server. Refer to the Microsoft SQL Server version 6.5 online documentation, Future Feature Support note, for more information about future support for old-style features.
A significant feature of the ANSI-standard join operators is that the WHERE clause and its operators are no longer overloaded to provide both joins and restrictions. When the ANSI-standard join operators are used, the WHERE clause is used only for restrictions—"equal to," "greater than," and so on.
The following sections provide some sample queries, using the old-style join syntax and the ANSI-standard operators. (The cross join is rarely used, and it will not be discussed further here.)
Consider the following query, which lists all technical articles and their authors:
SELECT a.Title,
au.Name
FROM Article a,
Author au
WHERE a.AuthorID = au.AuthorID
AND a.ArticleType = 'Technical Article'
Note that the WHERE clause contains both a join and a restriction and that both clauses use the "=" operator. In the join clause, the "=" operator is overloaded to indicate both the type of join (in this case, a natural join) and which attributes should be compared in the join. This same query written using the ANSI-standard INNER JOIN operator looks like this:
SELECT a.Title,
au.Name
FROM Article a INNER JOIN Author au
ON a.AuthorID = au.AuthorID
WHERE a.ArticleType = 'Technical Article'
Note that the WHERE clause no longer contains join information. Furthermore, the two components of the join (the type of join and the attributes used in the join) are no longer specified with a single overloaded operator. The type of join is specified with the INNER JOIN operator, while the "ON" keyword and "=" operator describe the attributes used in the join.
Following is an example of an outer join using the old join syntax. This join lists all articles and the editors to which they are assigned (if any).
SELECT a.Title,
m.EditorID
INTO #temp1
FROM Article a,
Matter m
WHERE a.ArticleID *= m.ArticleID
SELECT t.Title AS 'Article',
e.Name AS 'Editor'
FROM #temp1 t,
Editor e
WHERE t.EditorID *= e.EditorID
drop table #temp1
This query looks quite different when the ANSI-standard LEFT OUTER JOIN operator is used. Note that Microsoft SQL Server is much happier about performing this query in a single SELECT statement when the ANSI-standard operators are used.
SELECT a.Title,
e.Name
FROM (Article a LEFT OUTER JOIN Matter m
ON a.ArticleID = m.ArticleID)
LEFT OUTER JOIN Editor e
ON m.EditorID = e.EditorID
Suppose you want to produce a list that displays all articles and all editors, and also indicates when an article is assigned to an editor. This would be a rather challenging query in Microsoft SQL Server version 4.21, but the ANSI-standard FULL OUTER JOIN syntax makes it a snap:
SELECT a.Title AS 'Article',
e.Name AS 'Editor'
FROM (Article a FULL OUTER JOIN Matter m
ON a.ArticleID = m.ArticleID)
FULL OUTER JOIN Editor e
ON m.EditorID = e.EditorID
The results look like this:
Article Editor
------------------------------------------------- --------------------
(null) Tina Brockwell
(null) Mindy H. Cameron
Converting from MS Cardfile to SQL Server Steve Landers
Using Distributed Transactions in SQL Server 6.5 Mark Cromwell
Overview of Microsoft Internet Technologies (null)
Microsoft Distributed Leaflet API (null)
Using the Identity property allows us to eliminate the GetNextPKID procedure. Nevertheless, let's resurrect that procedure for a moment because it provides a perfect opportunity to demonstrate how to verify both old and new column values in a single UPDATE statement. This offers the advantage of reducing the time during which locks are held, which may improve performance in a multi-user situation.
The GetNextPKID procedure uses an explicit transaction containing a SELECT statement followed by an UPDATE. This prevents multiple clients from retrieving the same primary key value. Beginning with version 6.0, it is possible to include variable assignments in the SET list of an UPDATE operation. The single UPDATE operation is an implicit transaction, eliminating the need for BEGIN TRAN and COMMIT TRAN. This results in the lock being held for a shorter period of time and simplifies the code.
Using this technique, GetNextPKID can be rewritten as shown below. Note that the old GetNextPKID procedure assumed that the PKIdentifier table contains the next available primary key value, while the new version assumes that PKIdentifier contains the most recently used primary key value.
CREATE PROCEDURE TestMe
(@PKIDName varchar(64),
@PKIDValue PKID OUT)
AS BEGIN
DECLARE @PKID PKID
UPDATE PKIdentifier
SET PKIDValue = PKIDValue + 1, @PKID = PKIDValue
WHERE PKIDName = @PKIDName
IF @@ROWCOUNT <> 1
BEGIN
/* Raise an error message. */
RETURN -1
END
SELECT @PKIDValue = @PKID
RETURN 0
END
Microsoft SQL Server version 6.0 introduced the ANSI-compliant CASE expression. The CASE expression can substantially reduce the complexity of your code when you need to evaluate a large number of conditional values.
To demonstrate the CASE expression, let's return to the InsertArticle procedure. The ArticleType parameter will accept just about anything that the user cares to enter. This is not a great idea. In the real world, we would probably make this attribute a foreign key to a table containing defined article types. For demonstration purposes, let's see how the CASE expression could be used to evaluate user inputs and select an appropriate article type. The following code can be inserted into the ArticleInsert procedure to evaluate the ArticleType parameter prior to the INSERT operation. Notice that this code is written to be case-insensitive.
/*
* Evaluate the user-entered @ArticleType,
* and select an appropriate predefined type code.
*/
SELECT @ArticleType=
CASE
WHEN CHARINDEX('TEC', UPPER(@ArticleType)) <> 0 THEN 'Technical Article'
WHEN CHARINDEX('WH', UPPER(@ArticleType)) <> 0 THEN 'Whitepaper'
WHEN CHARINDEX('BA', UPPER(@ArticleType)) <> 0 THEN 'Backgrounder'
WHEN CHARINDEX('SP', UPPER(@ArticleType)) <> 0 THEN 'Specification'
WHEN CHARINDEX('DO', UPPER(@ArticleType)) <> 0 THEN 'Documentation'
ELSE 'Unknown'
END
There is more to upgrading from Microsoft SQL Server version 4.21 than simply dumping your database and running the setup program. Although you can take a minimalist approach to upgrading your SQL Server database, you may also want to examine your data and your database more closely in order to ensure a smooth transition and lots of happy customers. Your upgrade effort may provide an opportunity to uncover hidden problems in your existing database, and correct them before they cause unexpected problems.
Significant changes have been introduced in versions 6.0 and 6.5—changes that may require you to rewrite some of your code from your version 4.21 database. There are also many new features that you can adopt to reduce the amount of code you must maintain, increase reliability, and keep your customers happy.