Microsoft Corporation
October 1998
Summary: Discusses how to use Microsoft® Visual Studio® version 6.0 to access Microsoft SQL Server™ 7.0. (10 printed pages) Provides answers to a number of questions that developers have been asking, including:
What's New
Using Visual Studio to Access SQL Server 7.0
ActiveX Data Objects
Using ADO to Access Data
Current Applications and the New Platform
Performance Optimizations
Taking Advantage of the New Features
This version of SQL Server is far more sophisticated than the 6.5 version. It redefines the basic data structure used to store the data. The engine used to query and manage the database management system (DBMS) has been reengineered extensively. SQL Server 7.0 is designed to leverage many of the distributed architecture and data logic innovations Microsoft has introduced and refined over the past decade. It uses new technologies involving Microsoft ActiveX® Data Objects (ADO) 2.0, OLE DB, Component Object Model (COM), and Distributed COM (DCOM).
The top six things that developers will probably be interested in are:
These topics are covered on the Visual Studio Web site at http://msdn.microsoft.com/vstudio/ and the MSDN Web site at http://msdn.microsoft.com/default.htm.
There isn't a wizard to correct poor design. In too many cases, "relationally challenged" designs make the transition to scalable applications an exercise in frustration. Be sure to start with a good, solid, normalized design before trying to scale to SQL Server, regardless of the language. The tools included with Visual Studio can make development of client/server or multitiered designs more productive with fewer lines of code.
A unique and unrivaled feature of Visual Studio is its ability to stop and interact with SQL Server to facilitate the "conversation" these applications carry on with the DBMS. Because of the very nature of SQL Server, applications engage in a conversational dialog with the engine. Developers can easily use Visual Studio's "immediate" window to enter "questions" or commands in the form of queries and get "answers" from SQL Server. They can also use SQL Server's ability to return trace and debug information through the Enterprise Edition's T-SQL (Transact SQL) debugging option. This helps the developer see what the engine is thinking, the process being used to run the query and, when things go wrong, what errors have occurred.
Note In some cases, your user might feel the need to ask "ad hoc" questions about the information stored in the database. Some applications have exposed a dialog box that lets users enter an SQL query. The big problem here has been the lack of control over those queries. A poorly constructed query can cause huge system performance problems. Now, with the new DSS included in SQL 7.0, you can create predefined, efficient queries to point your users to that won't cause huge system delays.
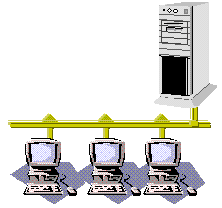
The majority of these applications access SQL Server using "client/server" technology. This comparatively simple approach establishes a connection with SQL Server over a local area network (LAN), or simply against the locally running version of SQL Server, submits one or more queries, processes the results, and disconnects. These applications include hard-coded T-SQL queries or parameter queries or, in most cases, invoke T-SQL stored procedures. The applications can interface with SQL Server with any of the API or object-level interfaces. They manage ordinary row data and Binary Large Objects (BLOBs), as well as TEXT and all of the other SQL Server data types.
Figure 1. Client/server LAN
Most developers use the client/server paradigm to access SQL Server because it provides speed and flexibility, as well as the ease of development that many customers (and developers) demand. There is also quite a bit of industry experience to draw on when developers need help or just a book to read when they get to a tough part of the development process.
However, this paradigm usually requires a dedicated LAN or wide area network (WAN) for its connections, and more than just a browser for the client. This means that client/server applications can be more expensive to deploy—especially in cases where developers include hard-coded queries in the front-end applications.
A client system need not be as powerful as one that has to perform a broad range of other tasks, because client/server applications do not have to be particularly resource-intensive. Most well-written applications have a fairly small footprint and don't place much load on the network. As a matter of fact, client/server applications connected over low-speed remote access server (RAS) modem connections can perform quite nicely.
Client/server designs often rely on server-side code to manipulate the database. This logic is usually implemented as stored procedures, triggers, and rules coded in T-SQL. When used in conjunction with appropriate security measures, this centrally managed code can increase security and dramatically improve performance. In addition, because the application does not contain hard-coded queries, it makes the inevitable changes to the underlying schema or data access logic more manageable. In many cases, these changes do not require redeployment of the client applications.
Stored procedures can embody a simple SELECT query or extremely sophisticated logic. This logic returns selected data from one or more tables, performs complex data modification operations, or simply returns status of the database. In essence, this technique moves many of the low-level data operations and business logic to SQL Server. Stored procedures can return one or more result sets, and often require parameters passed in both directions. These stored procedures form the foundation of most professional client/server implementations. That's why Visual Studio has placed so much emphasis on supporting stored procedures. Visual Studio 6.0 provides T-SQL debugging that walks developers right into a stored procedure as it is executing—directly from the development environment.
SQL Server 7.0 continues to rely heavily on stored procedures to provide high-security, high-speed, and highly adaptable interfaces to data. What has changed is that now these procedures are reentrant. That is, once procedures are loaded into memory, they can be shared by more than one client at a time. This saves a great deal of server-side memory, as well as processing, disk I/O, and time. Visual Studio applications don't have to do anything special to reap the benefits of this innovation, as long as they are calling stored procedures to do their queries.
While not encouraged, many applications rely heavily on "cursors" to manage query result sets. Simply put, a cursor is a set of pointers to the data rows qualified by the SQL query. How efficiently Visual Studio and the Data Access Object (DAO) interfaces handle these structures plays a major role in the overall performance of the application. Because of this, it is equally important for both the client and server to manage cursors efficiently. SQL Server 7.0 has further improved its server-side cursor handling so those applications and stored procedures that depend on this approach can work more efficiently—especially in multiuser situations. The Visual Studio developer does not need to make any changes to take advantage of these innovations—that is taken care of under the covers.
The next evolutionary step in application design moves even more logic out of the client and onto a "middle-tier" system. This is attractive because it makes the client applications "lighter" and reduces the need to redeploy when the underlying business logic or data access interface needs to change. This approach make changes in the client registry to redirect object-level component access to a remote server using DCOM. This architecture permits developers to reference "business objects" instead of low-level result sets. It also permits many clients to reference the logic simultaneously. This architecture raises a number of issues, among them reentrancy, session state management, transaction management, connection sharing, and security. In the past, DCOM designs called for developer-implemented systems to manage these issues and C-developed components to contain the logic.
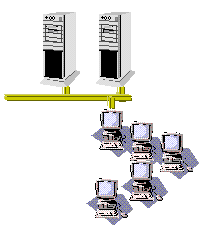
Figure 2. Distributed component architecture
Visual Studio 6.0 and Microsoft Transaction Server (MTS) changed all of this. Now developers can build their own apartment-model threaded and fully-compiled components. Once created, a simple drag-and-drop operation enables MTS to manage how, when, and where the components are executed. This innovation opened an entirely new paradigm for developers anxious to move more data-specific code out of deployed client applications. Now developers can implement object-based interfaces to data that shielded the low-level data access, business rules, transactions, and physical operations from the client.
Note Much of the magic (and heavy work) here is provided by MTS. It handles a litany of details, including (but not limited to) resource management, component registration, code sharing, transactions, connection pooling and much, much more. For more information, see www.microsoft.com/com/default.asp.
DCOM architectures can also leverage existing client/server implementations because the remotely executed components can (and should) still access stored procedures for their low-level data access operations. However, this design changes how transactions are managed and how the client application approaches a number of basic problems. Visual Studio is designed to make this transition easier by exposing all of the needed object references using its Microsoft IntelliSense® development tips. This makes accessing evolving COM components easier, as well as adds flexibility in how these components are created. Microsoft Transaction Server includes plenty of examples written in Microsoft Visual Basic® to make this process painless.
Some of the fundamental differences developers should be aware of include:
The latest innovation in data access architectures leverages the universal connectivity provided by the Internet (and your corporate intranet). This technology depends on a client-side browser. No, the browser does not have to be a Microsoft Internet Explorer browser, because many of these designs only expect simple Hypertext Markup Language (HTML) support. Yes, many of the more efficient designs leverage Internet Explorer 4.0's dynamic HTML extensions, Remote Data Services (RDS), and other features—but users are often accustomed to waiting for their results.
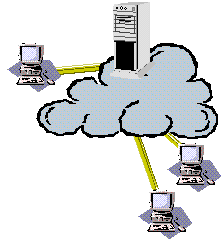
Figure 3. Web-based architecture
Visual Studio 6.0 takes the development of Web-based applications to a new plane. Developers can create applications that run on Microsoft Internet Information Server (IIS) and output HTML 3.2. This means all developers can use their existing skills and languages to build COM components that can run on any browser, anywhere. How does Visual Studio 6.0 access SQL Server? Well, just as you would access SQL Server from any program. You can use dedicated connections or, better yet, MTS and pooled connections. You can also use familiar ADO code to build result sets that can bind to grid controls or text boxes—just like when the target was a Microsoft Windows®-specific platform.
ActiveX Data Objects (ADO) is Microsoft's strategic, high-level interface to all kinds of data. ADO provides consistent, high-performance access to data, whether you're creating a front-end database client or middle-tier business object using an application, tool, language, or even an Internet browser. ADO is an object interface to OLE. ADO is the single data interface you need to know for 1- to n-tier client/server and Web-based data-driven solution development.
ActiveX Data Objects (ADO) is Microsoft's newest object-level data access interface. Visual Studio can use ADO just as any other COM interface—including the new Remote Data Services. This paradigm permits component developers to pass ADO Recordset objects back to the client, where more ADO code exposes it to the client application. Because Internet Explorer 4.0 includes support for RDS, this approach is especially handy when creating browser-based data retrieval applications. This same technology can be used in distributed architectures as well. Because the RDS code includes a data source control, you can also bind these disjoint result sets to data-aware bound controls.
ADO 2.0 expanded its functionality to rival that supported by RDO 2.0. ADO now supports a comprehensive event model, as well as a number of entirely new data access strategies. These include the ability to create stand-alone Recordset objects and persist them to files on the client. These can be resurrected and updated long after the connection has been dropped. In fact, you can create Recordset objects without the benefit of a connection at all.
ADO is now built into Visual Studio—everywhere it accesses data. This means that the designers, wizards, and debuggers all know about ADO connections and commands. ADO is also built into the new designers like the Data Environment and Data Form Designers and the Data View window. This makes it even easier to get at data, wherever it is—not just relational data from Visual Studio.
When working with SQL Server, it is possible to use ADO to create applications that connect through traditional client/server technology or from middle-tier or Web-based component code. ADO is ideally suited for the remote component architectures, because it supports even more sophisticated dissociate result set management. With ADO, you can build a Recordset object in a component and pass it back to the client application (or a Web page), where it can be managed by client-side code. For more information on ADO and RDS, see http://www.microsoft.com/data/.
For the most part, your current applications will run against SQL Server 7.0. Consider that there are several facets to this question. First, the raw (low-level) interface(s): SQL Server 7.0 still uses a proprietary Tabular Data Stream (TDS) interface to link to the outside world. The existing programmatic interfaces, including DB-Library, Open Database Connectivity (ODBC), and OLE DB, all use TDS. Question: Will existing VBSQL or DB-Library-based applications still work against SQL Server 7.0? The answer is yes, but the newest enhancements will not be incorporated in new versions of this now-outdated interface. You won't be forced to convert your VBSQL applications. You will be under increased pressure to do so as the gap widens between what you can do with OLE DB or ADO, and what you can do with DB-Library.
SQL Server 7.0 still supports both American National Standards Institute (ANSI) SQL and the T-SQL extensions supported in version 6.5 and earlier, so your SQL queries should still work. However, what SQL Server 7.0 does with the query once it starts processing that query has changed. In earlier versions, you had two choices when it came time to run a query. You could submit an "ad hoc" T-SQL statement that the engine compiled, created a query plan for, and executed. You could also submit a stored procedure that used a stored query plan. In some cases, you ran ODBC queries that created temporary stored procedures (in TempDB) for your connection that speeded up the process of running ad hoc or parameter queries not yet committed to permanent stored procedures. There were problems with these approaches. For example, despite the fact that SQL Server was running hundreds or thousands of identical client applications, running the same set of queries, it could not leverage the compiled query plans created for other (identical) clients. Even when you used a stored procedure, SQL Server had to load a new copy into memory unless there happened to be a copy of the stored procedure lying around not being used.
SQL Server 7.0 changes much of this by having completely redesigned the query compiler and processor, as well as how the queries are executed in memory. To start with, SQL Server 7.0 now permits other clients running the same query to use the executing query plan compiled and loaded by another client. That's because SQL Server 7.0's running queries are now reentrant. This means that when program "A" runs a query:
Select * From Authors Where Au_ID = 18
another client running the identical query, or even one that is similar but uses a different constant for the comparison, can share the same query plan at the same time. For example if program "B" or another instance of program "A" runs:
Select * From Authors Where Au_ID = 35
the SQL Server 7.0 engine can reuse the running or cached query plan—thus saving the time and resources required to recompile a query that would result in the same plan.
Imagine the improvements in performance this yields. Yes, SQL Server actually gets faster as more clients are added. This innovation also means that SQL Server no longer needs to reload additional copies of stored procedures when a stored procedure is in use. It simply permits the client to share the version already running. Another nuance here is that SQL Server 7.0 no longer creates TempDB stored procedures to be executed by the client. Because running queries can be shared by all clients of the database, the new engine has no need to store compiled queries and reload them when recalled in parameter queries.
The real magic of this innovation is what you have to do as an ADO developer to get at it: absolutely nothing. If you are executing stored procedures, these are shared more efficiently and run just as before. If you are executing ad hoc queries or rdoQuery, ADO commands, or UserConnection queries that were compiled into TempDB queries, you can still do so. But now, in all cases SQL Server 7.0 tries to use a query in the procedure cache instead of compiling a new query plan and executing it.
SQL Server 7.0 clearly makes far better use of random access memory (RAM) and its procedure cache to manage this magic. This innovation means faster performance and higher levels of scalability. It also means that your applications don't really have to change at all. You can take advantage of these changes:
Note Ad hoc queries are those T-SQL statements that you hard-code into your application or let the user build directly (shame on you) or indirectly through options the code or user chooses.
Consider that SQL Server 7.0 will support virtually all of your existing applications as is. However, also consider that in some cases you have to build applications that need to access data in both connected and disconnected modes. That is, the application must continue to work and process data even when the system cannot see the network. A common scenario implements the disconnected database with Microsoft Jet (or Microsoft Access, which is really the same thing), and the connected database with SQL Server. This has meant creating an ODBC/RDO connection to Jet. This is the source of a number of issues because the ODBC drivers for Jet were never really intended for this kind of task. Now that SQL Server 7.0 can run on both Microsoft Windows NT® and Windows 9x systems, this kind of architecture can be revisited. It might be time to consider reimplementing and use ADO to communicate to both databases, or even a better scenario: Use SQL Server replication to connect your Windows 9x SQL Server to your central Windows NT SQL Server.
Consider that SQL Server 7.0 improves how TEXT and IMAGE data types are stored, but it also increases the size of pages to accommodate larger VarChar data types. With SQL Server 7.0, you can store slightly less than 8,000 bytes in a VarChar column (8,000 less the size of the key). This means the need to store complex page-based data types can be reduced or eliminated.
Consider that SQL Server 7.0 also supports cost-based locking. This means that when it makes sense to lock rows, SQL Server 7.0 does so. This can play a significant role in more sophisticated designs as developers build systems dependent on high-performance applications and components.
Consider that Microsoft is also working toward more efficient deployment scenarios, so dependence on large, multicomponent applications being distributed to client workstations is becoming less popular. Web-based implementations seem to address many of these problems—and while these designs have a few issues of their own, they tend to reduce total cost of ownership. So, in many cases, you should think about these alternatives as new projects are being designed.