Martin Heller
March 1999
Summary Discusses ways in which the Microsoft® Visual C++® compiler can optimize source code for speed and size and tells why code size matters. (21 printed pages) Covers code generation; optimization switches and pragma statements supported by Visual C++; choosing the best switches on a per-project basis; and overriding switches at the function level.
Introduction
Principles of Code Optimization
Optimizations in Microsoft Visual C++
Timing and Profiling with Visual C++
Summary
The Microsoft Visual C++ Development System is often the language of choice for producing small, fast programs. Visual C++ 6.0 is the leading C++ compiler for 32-bit Microsoft Windows® and has a number of features that aid in producing fast programs. In this article, we explore those features—optimization settings, profiling, and delayed loading—and discuss how to use them effectively.
This article assumes that the reader is familiar with C++.
In an ideal world, software would design itself to your specifications, automatically reduce itself to the smallest possible memory footprint, compile instantly, and always run at the fastest possible speed. In the real world, developers still have to write programs in some sort of programming language. To get the absolutely smallest, fastest code, a programmer can work in assembly language, but that can be prohibitively labor-intensive for all but the most time-critical code.
Most programmers do most of their coding in a high-level language, which is then compiled to an assembly language and linked into an executable program image. During the development process, programmers are quite sensitive to build speed and ease of debugging; when it comes time to release the code for production, run-time speed and size become of paramount importance. Throughout this paper, we'll be concentrating on production code run-time size and speed concerns.
There are many ways to make code run quickly. Often, the controlling factor for the speed of a program is the algorithm used, rather than any optimization done by the compiler. For instance, a sorting program written using the HeapSort algorithm will run rings around a BubbleSort, because the HeapSort algorithm performs far fewer comparisons when the number of items in the list is large.
A search algorithm using array structures usually runs faster than a search algorithm using dynamically allocated linked lists, because an array is contiguous in memory and is likely to reside on a few pages of virtual memory; it will most probably reside in RAM. On the other hand, a dynamically allocated linked list tends to be scattered in memory, and a linked list search is likely to generate page faults. On the other hand, adding an element to and removing an element from an ordered linked list are usually faster than the corresponding operations using arrays, because they don't require moving the other list elements.
Sometimes it is just not important to make code run quickly. For example, user interface code that responds to a keystroke in a tenth of a second is indistinguishable from user interface code that responds to a keystroke in a millisecond—the throughput is still limited by the user's typing speed. ASWATSS (All Systems Wait At The Same Speed) applies here. When code does not have to be fast, it is worthwhile to make it as small as possible.
On the other hand, it is often important to make your code run quickly, especially code that is executed often or in a tight loop. Once you have chosen the best data structures and algorithms for the job and written the cleanest C++ code you can, you want the compiler to turn that into the fastest and/or smallest run-time program possible.
A number of standard ways exist for optimizing code for speed; you can find in any book on writing compilers, and it is worthwhile to go into some of them before we dive into the details of Visual C++. Some of these speed optimizations also minimize the program's size, and others trade size for speed. Often, global compiler optimizations change the order of execution of the generated instructions, making it difficult to debug optimized compiled programs at the source code level.
Common subexpression elimination looks for repeated computations in a formula and rewrites the formula to have a lower instruction count. For instance, we might have a formula that reads:
Y=a*(y1-avg)+b*(y1-avg)+c*(y1-avg);
The compiler can reduce the instruction count by saving the repeated intermediate result in a variable, equivalent to
Temp=(y1-avg);
Y=a*Temp+b*Temp+c*Temp;
A second pass through this code would yield the following:
Temp=(y1-avg);
Y=Temp*(a+b+c);
These optimizations have turned three subtractions, three multiplications, and two additions into one subtraction, one multiplication, and two additions. Most likely, the optimized code will be smaller than the unoptimized code, as well as faster.
Copy propagation and dead store elimination work to remove unused intermediate variables from the calculation stream, improving both size and speed. This can eliminate a load, store, and a memory location for each variable optimized away; the gains are considerably more dramatic when whole structures are eliminated, as in the common C++ case of returning a copy of a struct:
int foo(struct S sp) {
struct S sa=sp; return sa.i }
The copy propagation optimization turns this into:
int foo(struct S sp) {
return sp.i }
Often, some code inside a loop, which is repeated many times, does not change values during the loop's execution. These loop invariants can be calculated once before the loop runs. Removing or hoisting loop invariants generally improves speed without affecting size very much. For example, invariant hoisting can remove the arithmetic from the inside of this loop:
for (i=0;i<1000;i++) {
A[i] = a + b; }
The product is
t = a+b;
for (i=0;i<1000;i++) {
A[i] = t; }
This saves 999 addition operations at the cost of one temporary variable, which is likely to go into a register.
In fact, C and C++ have a register keyword that programmers can use to designate variables that will be used heavily and might best be kept in a CPU register, because register access is generally faster than memory access. Compilers can also optimize their register allocation without explicit guidance, and many (including Visual C++) ignore the register keyword, because they can do a better optimization job than the programmer can.
Register usage optimization generally improves both speed and size. It is one of the most important speed and size optimizations on processors such as the Intel® x86 family, which have few general-purpose registers.
In very tight inner loops, a significant percentage of the CPU time can be spent doing counter arithmetic and conditional jumps. Loop unrolling allows the compiler to turn the loop into straight-line code, which improves speed at the expense of size. On x86 processors, loop unrolling can make a dramatic speed improvement if multiple-byte operations can replace single-byte operations that run in the same number of clocks. A concrete example is a character-processing loop that uses the code LODSW instead of LODSB to load two bytes per memory access instead of one.
Inline function expansion can also improve speed at the expense of size. The compiler can replace a function call—and its attending parameter passing, stack maintenance, and jump overhead—with an inline version of the function body. However, if inline expansion is combined with global optimizations such as common subexpression elimination and loop invariant removal, the overall effect can be to improve both speed and size, sometimes dramatically.
On modern pipelined processors, instruction order can make a huge difference in execution speed, because addresses can be pre-fetched if the order is right and cannot be if the order is unfavorable. Michael Abrash, in his Zen of Code Optimization (Coriolis, 1994), discusses how a simple three-instruction inner loop written in assembly language is sped up by a factor of two on 80486 processors. This is accomplished by swapping the order of two instructions and splitting the third, a complex instruction, into two simpler instructions.
Processors with dual execution pipelines, such as the Intel Pentium, are even trickier to optimize. Code that manages to keep both Pentium execution pipelines filled and executing simultaneously can run up to twice as quickly as code that does not. In general, a stream of simple instructions will run faster on a Pentium than a stream of fewer complex instructions, at the cost of creating a larger program. As Abrash points out, Pentium optimization can often double both speed and code size at the same time.
The Pentium Pro, which has two longer execution pipelines, makes instruction scheduling a lot less important than it is on the Pentium and 486 but makes branch prediction more important. It is capable of "dynamic execution," meaning it can take instructions out of order in a 12-stage instruction pre-fetch pipeline. It also has a sizable on-chip memory cache. However, instruction pre-fetching only works when the processor correctly predicts the instruction stream; if it guesses wrong about what branch the execution will take, it has to flush the pre-fetch pipeline and reload it from the correct branch.
You may be wondering why we keep emphasizing code size along with code speed. With 128 megabytes (MB) of RAM a common configuration, who cares?
In fact, code size can make a huge difference in execution speed, especially on a multitasking operating system such as Windows. There are two events that can directly slow code down because of size: a cache miss and a page fault. A cache miss causes a minor delay when a memory location is not in the CPU cache. A page fault causes a major delay when a virtual memory location is not in physical memory and has to be fetched from disk. A large working set—the sum of code and data that has to be in memory for the program to run—makes both cache misses and page faults more likely.
On an 80486 machine, reading a byte from the primary CPU memory cache takes one cycle, while reading the byte from RAM that is not in the cache—a cache miss—takes more like 13 cycles. If a secondary cache is present and has the requested byte, the timing will be intermediate between these two extremes.
The 80486 has one 8 kilobyte (KB) cache for both code and data. If the code and data for an inner loop all fit into cache, the loop can run at its maximum speed; if they don't, it can't.
On the Pentium, Pentium with MMX, Pentium Pro, Pentium II, Celeron, Xeon, and Pentium III machines, there are separate instruction and data caches on the CPU chip. If the code for a loop can all fit into the CPU's instruction cache, it will run much faster than if it cannot, because there will be no delay for fetching code. Likewise, if all the working memory can fit into the data cache, the program will run much faster, because there will be no delay for fetching data.
In addition, the secondary cache, of which there is often 512 KB on a Pentium II motherboard, is usually shared between code and data. Assuming the primary caches are not big enough, a situation develops where if the total of the working code and data can fit into the secondary cache, the program runs much faster than if they cannot.
A page fault happens when a part of a program is not in RAM but has to be retrieved from the virtual memory page file on the hard disk. Because disk is very much slower than RAM, one page fault can represent a huge slowdown.
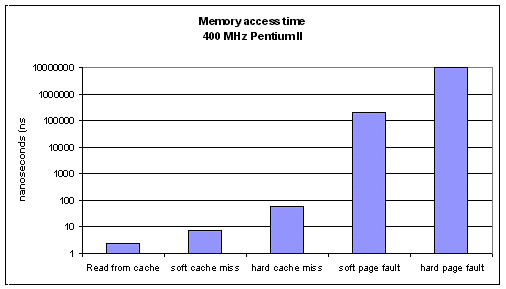
Consider a typical 400-megahertz (MHz) Pentium II desktop machine. One clock cycle is 2.5 nanoseconds, or 2.5x10-9 seconds, and a read from the primary CPU cache takes one cycle—or effectively less, if the read can be pre-fetched and the instruction can run in parallel with another one. A minimum delay for missing the primary cache is 3 cycles, or 7.5 nanoseconds; a minimum delay for missing the secondary cache is 14 cycles, or 35 nanoseconds. The maximum delay for missing the secondary cache is the full memory access time, typically 60 nanoseconds, which is 24 cycles.
Now, what happens if a page fault occurs? The code has to be retrieved from disk, which in the worst case could take more than 10 milliseconds (ms), which is 10-2 seconds, 10,000,000 nanoseconds, and 4,000,000 cycles. The worst case rarely happens, fortunately: most disk drives have internal RAM for caching, and Windows also dedicates RAM to a disk cache. Together these two caches typically improve disk throughput and effective access time by about a factor of 50.
Therefore, a typical "soft" page fault incurs a 200-microsecond penalty, which is 80,000 CPU cycles. To put that in human terms, if it took 1 second to read a byte from the primary CPU cache, it would take almost a day to process a page fault.
When are you likely to have a page fault? One example: the total of all the code and data in the operating system (including the disk cache), plus all the programs the user is running, does not fit into memory. To look at this another way, every program sharing the system needs to be parsimonious with memory; one memory hog can slow the whole system to a crawl by making every program "thrash" with page faults.
That is not to say that all of every program needs to have its size minimized: it makes perfect sense to optimize CPU-intensive inner loops for speed. Just don't optimize your user interface and other non-CPU-intensive code for speed at the expense of size.
Now that we know why code should be small, we can discuss size optimizations. We mentioned common subexpression elimination earlier as a speed optimization; it is usually also a size optimization.
Dead code elimination is a pure size optimization. The compiler can often tell a code branch or a function is never called; instead of emitting the useless code, it can suppress it and save space. Of course, the compiler can't do this for exported functions.
As we discussed earlier, on the Pentium machine a stream of many simple instructions often runs faster than a stream of fewer complex instructions that accomplish the same end. We gave an example that doubled both speed and size. If we guide the compiler to favor size over speed, it can generate the smallest instruction stream for a given C++ statement instead of the fastest instruction stream. The optimum strategy for most Windows programs is to favor size for most code and to favor speed only for "hot spots" in the code.
In many programs, there are code branches that are called infrequently. For instance, a word processing program is typically asked to print once or twice a day but asked to edit continuously. The printing code, especially if it implements a background reformatting and paginating thread, tends to be large. To keep the size of the program and its load time down, the programmer can make it so the printing code is only loaded when it is needed.
There are several ways to implement dynamic loading. In our example, the main editing program can spawn a separate printing program. It can also dynamically load a printing library, call its functions, and release it when printing is complete. Visual C++ has a way to make this easy to do.
We've mentioned hot spots several times, but we haven't really defined them or explained how to find them. A hot spot is a function or code section that consumes enough cycles or time to slow your program down; it's the computer equivalent of the chemist's "rate-limiting step." Often, CPU hot spots are to be found in the inner loops of your own code. On some occasions, however, they turn out to reside in third-party library code. In unusual cases, hot spots turn up in compiler run-time library functions and in very rare cases, in system API functions. I/O-bound functions can suffer from I/O hot spots and bottlenecks that slow the program down even though the CPU is only lightly loaded.
You can find your program's hot spots by profiling. Profiling tells you such information as what functions are called the most, what functions are using the most clock and CPU time, and how often individual lines of code are called.
Once you have found a hot spot, you can determine how long the function or code section takes by timing it, typically inside a loop to lengthen the run time and improve the measurement accuracy. You can also figure out how long a CPU hot spot will take by looking at the assembly language generated by the compiler and counting clocks, although counting clocks is very hard on processors such as the Pentium II that perform dynamic execution. While you can get some idea of performance by looking at C and C++ source code, it's hard to do accurately unless you really understand what the compiler will do with it when it generates and optimizes the object code.
With that in mind, we'll focus in on the Visual C++ Development System and look at some small, concrete examples. We will cover the compiler's code-generation optimizations, the delay-load helper, and some special cases involving the run-time libraries and system APIs.
The Visual C++ Development System can perform almost all the general code optimizations we've discussed, plus a bunch more. You can control what optimizations are applied to your code with compiler switches and with pragma statements.
The Visual C++ Development System can perform copy propagation and dead store elimination, common subexpression elimination, register allocation, function inlining, loop optimizations, flow graph optimizations, peephole optimizations, scheduling, and stack packing. We've already explained most of these in general terms. It doesn't do loop unrolling in a general way, although it does unroll loops for a few small special cases such as block memory moves.
In addition to hoisting invariants out of loops, Visual C++ can perform operation strength reductions and induction variable elimination. For example, the code:
for(i=0;i<10;i++) {
A[i*4]=5;
}
becomes
for(t=0;t<40;t+=4) {
A[t]=5;
}
This code replaces an expensive multiply with a cheap add.
Flow graph optimizations rearrange common instructions in if-then-else blocks. Tail splitting eliminates jumps by bringing common return statements into the blocks, so that
if(x) {
b = 1;
} else {
b = 2;
}
return b;
becomes
if(x) {
b = 1;
return b;
} else {
b = 2;
return b;
}
which is a speed optimization.
Tail merging, on the other hand, pulls duplicate instructions out of the blocks, which is a size optimization. Tail merging turns the following:
if(x) {
bar()
b = 1;
} else {
foo()
b = 1;
}
into this:
if(x) {
bar()
} else {
foo()
}
b = 1;
Stack packing reuses stack space for objects that aren't in scope at the same time. One variation lets function parameters share the stack with the function's local variables, thus possibly eliminating a stack frame setup as well as reducing the memory used.
Frame pointer omission lets the compiled code access locals and parameters using the ESP register (on Intel CPUs) instead of the EBP register. This eliminates the overhead of frame setup and cleanup and allows the use of EBP as a general register, but at a cost in code size. ESP reference instructions are larger than EBP references. Overall, frame pointer omission is usually a win, and Visual C++ uses it when it is enabled and the compiler's heuristic rules say it is safe and worthwhile.
Peephole optimizations work at the object code level to replace the originally generated instruction sequences with faster or smaller sequences. For example, the source code x=0 might, after register optimization, emit the following Intel instruction:
mov eax,0.
Peephole optimization would change this to the smaller:
xor eax,eax
Other peephole optimizations trade size for speed or speed for size, as discussed earlier; they also work better on some processors than on others. Scheduling optimizations—spreading out memory accesses to make it possible for memory pre-fetches and pairing instructions that can execute in parallel—are also highly CPU-dependent.
You can control the Visual C++ code generation and optimization using compiler switches. In the development environment, you can set switches from the project settings dialog. The switches that affect code generation start with /G, and switches that control optimization start with /O.
The Intel version of Visual C++ can target Pentium CPUs (/G5), Pentium Pro CPUs (/G6), or a "blend" of Pentium and Pentium Pro optimization options (/GB, the default). Pentium II and Celeron CPUs have the same pipeline characteristics as Pentium Pros. In general, the default /GB switch will give good results, as it targets the most common current processor.
In Visual C++ 6.0, /GB does not really blend optimizations but instead maps to /G5. The compiler designers chose this, because /G6 hurts the Pentium by growing the code to avoid partial stalls on register accesses. The Pentium instruction pairing optimizations in /G5 do not matter to the Pentium Pro or Pentium II. If you are mostly targeting Pentium Pro or Pentium II machines and don't care about performance on Pentium machines, you can sometimes gain a little speed by using /G6.
Visual C++ has a number of other optimization switches to control its behavior. The three most common settings are /Od, which disables all optimizations for debugging purposes, /O1, which minimizes code size, and /O2, which maximizes code speed. These three settings can be chosen from the drop-down list in the Optimizations category on the C/C++ tab of the Visual C++ Project Settings dialog box, as Disable (Debug), Minimize Size, and Maximize Speed. The custom setting allows for finer control.
The /O1 switch, for minimizing size, is the equivalent of /Ogsyb1 /Gfy. /Og enables global optimization, and /Os favors smaller code size over speed. This is best for most code. /Oy enables frame pointer omission, and /Ob1 enables inlining of functions explicitly declared inline.
The /Gf switch enables string pooling, a size optimization that lets the compiler place a single copy of identical strings into the .exe file. The /Gy switch makes it possible for the compiler to make all individual functions packaged functions (COMDATs). This means the linker can exclude or order individual functions in a DLL or .exe file, which in turn reduces the run-time size of the program.
The /O2, for maximizing speed, is the equivalent of /Ogityb1 /Gfy. The two changes from /O1 are the addition of /Oi, which makes it possible for the compiler to expand intrinsic functions inline, and the change from /Os to /Ot, which favors faster code over smaller code.
In Visual C++, a master optimization setting applies to each build target, typically Disable (Debug) for Microsoft® Win32® Debug targets, and Minimize Size for Win32 Release targets. However, you can override the switch settings on a module by module basis, so if the TightLoop.cpp module needs better speed, you can set its optimization to Maximize Speed without affecting the rest of your project.
You can also override specific optimization settings for a project. There are cases, for instance, when /O2 /Ob2, which favors speed and makes it possible for any function to be inlined, is the best setting for a CPU-intensive module with functions that are called from inner loops. In the visual development environment project settings dialog, you can achieve this by applying the Any suitable box for inline function expansion to the CPU-intensive module.
The /GF switch works likes /Gf but puts common strings in read-only memory, which is safer and more efficient for big applications than putting them into read/write memory. If your application tries to change a shared string when compiled with /GF, it will generate a fault. If it tries to change a shared string when compiled with /Gf, it will succeed, and the string will be changed everywhere it is used, which is probably not your intention.
The /Gr switch sets the default calling convention to __fastcall, which can speed up and shrink some programs by an additional 1 to 2 percent. Functions compiled for __fastcall can take some of their arguments in the ECX and EDX registers, with the rest of the arguments pushed onto the stack in right-to-left order. Using the __fastcall convention takes some thought if you have functions that contain inline assembly language.
To get optimization control at the function level, you can use the Visual C++ optimization pragmas. For instance, to make the one CPU-intensive function in the module BagOfCode.cpp run quickly while minimizing the size of the rest of the functions, you can select Minimize Size for the project and/or module and bracket the relevant function with #pragma optimize statements:
function pokey() {
//non-critical code here
}
#pragma optimize("t",on)
function NeedForSpeed() {
//time-critical code here
}
#pragma optimize("t",off)
function pokey2() {
//more non-critical code here
}
In this example, we've turned on optimization option "t" for one function, which is the equivalent of setting /Ot to favor code speed over code size.
How good is the Visual C++ optimization? Let's consider how it does with the CPU-intensive Dhrystone integer benchmark, measured on a 400 MHz Pentium II.
| Settings | Dpack1 size | Dpack2 size | Dhrystone |
| /Od (debug) | 19 KB | 6 KB | 225 MIPS |
| /O1 (min. size) | 13 KB | 2 KB | 600 MIPS |
| /O2 (max. speed) | 14 KB | 2 KB | 715 MIPS |
| /O2 /Ob2 (max. speed and inlining) | 14 KB | 2 KB | 850 MIPS |
What we see here is world-class optimization, both for speed and size. Getting a value of more than 800 million Dhrystone operations per second on a 400 MHz Pentium II processor means the benchmark is averaging more than two operations per cycle. This implies the working code fits into instruction cache, most data memory accesses are being pre-fetched or cached, and additional optimizations have eliminated some of the operations in the count implied by the C source code.
Note that the 35 percent speed gain for /O2 /Ob2 over /O1 came at a modest 8 percent cost in the size of the Dpack1 object module and a 6 percent cost in the 2 modules combined. By the way, I tried changing the target CPU to a Pentium Pro with the /G6 switch, but it had no discernible effect on the results of this benchmark.
Of course, your mileage may vary: It is unusual to find code that uses pure integer simple operations in tight loops such as the Dhrystone. Your own code may show different results, which may be more or less sensitive to the compiler's optimization settings. It is this sort of analysis, however, that can help you choose your compiler switches intelligently.
Earlier, we discussed the high expense of a page fault relative to a CPU cycle. We also pointed out loading a lot of unnecessary code can cause page faults during a program's operation as well as slowing the program's initial load. Aside from keeping your code small to begin with by careful design and intelligent use of the compiler's optimizations, you can help to avoid this problem by loading code only when needed.
Windows has always supported dynamic link libraries (DLLs) and dynamic function loading. Unfortunately, calling LoadLibrary and GetProcAddress to load a function and balancing LoadLibrary calls with FreeLibrary calls are somewhat tedious and error-prone tasks for developers.
The Visual C++ linker now supports the delayed loading of DLLs in a way that's almost transparent. You can call functions from your code as though they are statically linked and specify the /delayload:<dllname> linker switch for each DLL you do not want loaded with the .exe. You also must link to Delayimp.lib, which contains the delay load helper routines. The linker generates a load thunk for imported functions in delay-loaded DLLs.
A thunk is a short writeable code block that contains a function pointer; Windows uses thunks to implement code relocation and to bridge between 16-bit and 32-bit functions. The thunk we're talking about here is what enables transparent delayed loading. It is initially set to call the delay-load helper routine.
So, when your code first uses a DLL that has been marked for delayed loading, the delay-load helper function is called. It checks the stored handle for the DLL, sees it has not been loaded, and brings it into memory with LoadLibrary. On the first use of each function in the DLL, the helper function retrieves its entry point with GetProcAddress and saves it in the thunk. On subsequent uses of the function, the function is called directly from the stored pointer in the thunk.
You can explicitly unload delay-loaded DLLs after you are done with them by calling the following:
__FUnloadDelayLoadedDLL
It is not necessary to do so, however.
There are three areas where the C/C++ run-time library can sometimes cause a hot spot: memory allocation, memory copying, and file I/O.
The C run-time library memory allocation package—the brains behind malloc and free as well as the C++ new and delete methods—suballocates small memory blocks from the Windows global heap and allocates large memory blocks directly in the global heap. While the run-time library heap allocator had a reputation for lackluster performance in the past, the Visual C++ 6.0 version has improved vastly, and now has excellent performance.
There are a few areas where you can still improve on malloc, however. If you know you must have a large address space that will be sparsely populated (for a hash table, for example), you can benefit from using VirtualAlloc to reserve the full range of address space and selectively commit the blocks you'll require. This will cut down on your memory setup time and will also cut your working set size, helping to avoid page faults.
If your application uses the heap very heavily with a few sizes of memory blocks, you might be able to improve on the performance of malloc by creating one or more private heaps with HeapCreate and allocating blocks from them with HeapAlloc. Keep all the allocations of a given size together in one private heap to get the best results. This can help because a heap in which all the blocks are the same size is very easy to manage.
The issue that arises with memory copying is the opposite of what you might expect: Sometimes enabling intrinsics for run-time library functions (which insert a short instruction stream inline instead of making a function call) can make the program run slower. If you look at the source code for the run-time library version of memcpy, for instance, you'll find the routine takes care to pre-align unaligned buffers and to use the widest possible memory instructions, which copy four bytes per cycle on Intel CPUs. The compiler intrinsics do a good job in general on aligned buffers, and using the intrinsics can expose the code to improvement by the global optimizer.
Which you choose depends on your needs. If you do not care about code size and are dealing mostly with aligned buffers and/or mostly small buffers, the intrinsics are the way to go. If your buffers are big and might not be aligned, use the run-time library functions.
If you compile with /O1, Visual C++ will disable inline intrinsic function expansion, and if you compile with /O2, it will enable expansion. You can override the default behavior within a module by issuing the following:
#pragma intrinsic( function1 [, function2, ...] )
to enable expansion of specific intrinsic functions, or:
#pragma function( function1 [, function2, ...] )
to force calls to specific run-time library functions.
In many programs, the hot spots are not in CPU-bound functions but instead in I/O bound functions. For instance, loading documents can be a major time drain in a desktop publishing program that deals with large image files.
While using the C and C++ run-time library functions is convenient and portable, it is not always the most efficient choice. Two options available in the Win32 API can offer dramatic speed improvements: memory-mapped files and asynchronous file I/O.
A memory-mapped file, also called a mapped view of a file, makes the file look like RAM by bringing the file into the application's address space. Creating a file mapping and opening a mapped view of a file are effectively instant operations, and the application's subsequent access to the file can be fully cached by the system. If your application bogs when first opening a file because it reads all of a large file sequentially, then switching to a mapped view could make a dramatic difference. Mapped files are supported in all 32-bit versions of Windows. The following sample demonstrates how to use a mapped file.
//
// Open a handle to a file
//
FileHandle = CreateFile(
ImageName,
GENERIC_READ | GENERIC_WRITE,
FILE_SHARE_READ,
NULL,
OPEN_EXISTING,
0,
NULL
);
//
// Create a file mapping object for the entire file
//
MappingHandle = CreateFileMapping(
FileHandle,
NULL,
PAGE_READWRITE,
0,
0,
NULL
);
//
// Release our handle to the file
//
CloseHandle( FileHandle );
//
// Map the file into our address space
//
BaseAddress = MapViewOfFile(
MappingHandle,
FILE_MAP_READ | FILE_MAP_WRITE,
0,
0,
0
);
//
// Data in the file is now accessable using pointers based at BaseAddress
//
//
// Release our handle to the mapping object
//
CloseHandle( MappingHandle );
//
// Unmap the file when you are done
//
UnmapViewOfFile( BaseAddress );
Asynchronous file I/O makes it possible for your application to interleave processing with file transfers. There are several forms of asynchronous file I/O available in the Win32 API. Once you start an overlapped I/O operation, you can wait on an event to notify you of the operation's completion, use a completion callback routine, or use I/O completion ports. Support for these in Windows 9x is unfortunately very limited—for example, ReadFileEx works only on communications resources and sockets.
The most efficient of these three mechanisms, the I/O completion port, is supported only in Microsoft Windows NT® 3.5 and later. It is appropriate for server applications that do a lot of file handling; it scales well; and it takes advantage of multiple CPUs. Another very efficient mechanism, scatter/gather I/O, is only supported on Windows NT 4.0 and later. The following example demonstrates using an I/O completion port to generate several write operations to run in parallel:
hFile = CreateFile(
FileName,
GENERIC_READ | GENERIC_WRITE,
FILE_SHARE_READ | FILE_SHARE_WRITE,
NULL,
fRaw ? OPEN_EXISTING : OPEN_ALWAYS,
FileFlags,
NULL
);
if ( hFile == INVALID_HANDLE_VALUE ) {
printf("Error opening file %s %d\n",FileName,GetLastError());
return 99;
}
hPort = CreateIoCompletionPort(
hFile,
NULL, // new completion port
(DWORD)hFile, // per file context is the file handle
0
);
ZeroMemory(&ov,sizeof(ov));
ov.Offset = 0;
PendingIoCount = 0;
//
// Issue the writes
//
for (WriteCount = 0; WriteCount < NumberOfWrites; WriteCount++){
reissuewrite:
b = WriteFile(hFile,Buffer,BufferSize,&n,&ov);
if ( !b && GetLastError() != ERROR_IO_PENDING ) {
//
// we reached our limit on outstanding I/Os
//
if ( GetLastError() == ERROR_INVALID_USER_BUFFER ||
GetLastError() == ERROR_NOT_ENOUGH_QUOTA ||
GetLastError() == ERROR_NOT_ENOUGH_MEMORY ) {
//
// wait for an outstanding I/O to complete and then go again
//
b = GetQueuedCompletionStatus(
hPort,
&n2, // number of bytes
&key, // per file context
&ov2, // per I/O context is the overlapped struct
(DWORD)-1
);
if ( !b ) {
printf("Error picking up completion write %d\n",GetLastError());
return 99;
}
PendingIoCount--;
goto reissuewrite;
}
else {
printf("Error in write %d (pending count = %d)\n",
GetLastError(),PendingIoCount);
return 99;
}
}
PendingIoCount++;
ov.Offset += BufferSize;
}
//
// Pick up the I/O completion
//
for (WriteCount = 0; WriteCount < PendingIoCount; WriteCount++){
b = GetQueuedCompletionStatus(
hPort,
&n2,
&key,
&ov2,
(DWORD)-1
);
if ( !b ) {
printf("Error picking up completion write %d\n",GetLastError());
return 99;
}
}
Finding code bottlenecks can be a challenge worthy of a master detective, especially in distributed applications. If a user running a browser in New York reports that a Web client-server application is slow, the problem could be in a Microsoft ActiveX® control on the user's machine, an overburdened Web server in Virginia, an inefficient middle-layer COM object running on the Web server, an overloaded database in Cleveland, or a missing index on the database.
You can use the Microsoft Visual Studio® Analyzer to find bottlenecks in distributed applications, by collecting timing data on the interactions between components across all tiers and systems in the application. Visual Studio Analyzer is appropriate for isolating the component causing the bottleneck, but it is less appropriate for finding the hot spot code within a component.
If a C++ component is causing the bottleneck, you can zoom in on the hot spot with the Visual C++ Profiler or with a third-party profiling tool such as Numega's TrueTime or Rational's Visual Quantify.
Normally, you start profiling in Visual C++ at the function level. You can enable function-level profiling using a check box in the General category of the Link tab of the Project Settings dialog box. After you rebuild the project, it will be ready for profiling.
To do the actual profiling:
Your program will run—albeit more slowly than usual—and eventually your function timing information will appear in the run-time environment's Profile output tab. Careful examination of the output should suggest the function containing the hot spot, and you can then try drilling down to the source code line level in that function with another run of the Profiler.
When you get down to the hot inner loop, it is often useful to time your code. Doing this accurately can be a challenge.
One problem is that the standard Windows time-of-day clock, which is used by the C run-time library routine clock(), is not very precise. The cure for this is to use a high-resolution timer.
A second problem is that other processes running on Windows—including system processes—can compete with the process you are trying to time. The cure for this is to run your test process at a higher-than-normal priority, using the Win32 function SetThreadPriority.
There are two ways to access a high-resolution timer in a Win32 program. One is to use the system function QueryPerformanceCounter to read the high-resolution timer before and after the code being timed. The other (on recent Intel CPUs) is to use the RDTSC instruction to read the high-resolution timer directly from the CPU. In either case, you'll have to determine the high-resolution clock frequency ahead of time to turn clock ticks into seconds. The following code sample uses the QueryPerformanceCounter method and falls back to using clock() only if the system has no performance counter. To use it in your own program, call DoBench(myfunc); the return value will be the myfunc run time in seconds.
#include "time.h"
enum { ttuUnknown, ttuHiRes, ttuClock } TimerToUse = ttuUnknown;
LARGE_INTEGER PerfFreq; // ticks per second
int PerfFreqAdjust; // in case Freq is too big
int OverheadTicks; // overhead in calling timer
void DunselFunction() { return; }
void DetermineTimer()
{
void (*pFunc)() = DunselFunction;
// Assume the worst
TimerToUse = ttuClock;
if ( QueryPerformanceFrequency(&PerfFreq) )
{
// We can use hires timer, determine overhead
TimerToUse = ttuHiRes;
OverheadTicks = 200;
for ( int i=0; i < 20; i++ )
{
LARGE_INTEGER b,e;
int Ticks;
QueryPerformanceCounter(&b);
(*pFunc)();
QueryPerformanceCounter(&e);
Ticks = e.LowPart - b.LowPart;
if ( Ticks >= 0 && Ticks < OverheadTicks )
OverheadTicks = Ticks;
}
// See if Freq fits in 32 bits; if not lose some precision
PerfFreqAdjust = 0;
int High32 = PerfFreq.HighPart;
while ( High32 )
{
High32 >>= 1;
PerfFreqAdjust++;
}
}
return;
}
double DoBench(void(*funcp)())
{
double time; /* Elapsed time */
// Let any other stuff happen before we start
MSG msg;
PeekMessage(&msg,NULL,NULL,NULL,PM_NOREMOVE);
Sleep(0);
if ( TimerToUse == ttuUnknown )
DetermineTimer();
if ( TimerToUse == ttuHiRes )
{
LARGE_INTEGER tStart, tStop;
LARGE_INTEGER Freq = PerfFreq;
int Oht = OverheadTicks;
int ReduceMag = 0;
SetThreadPriority(GetCurrentThread(),
THREAD_PRIORITY_TIME_CRITICAL);
QueryPerformanceCounter(&tStart);
(*funcp)(); //call the actual function being timed
QueryPerformanceCounter(&tStop);
SetThreadPriority(GetCurrentThread(), THREAD_PRIORITY_NORMAL);
// Results are 64 bits but we only do 32
unsigned int High32 = tStop.HighPart - tStart.HighPart;
while ( High32 )
{
High32 >>= 1;
ReduceMag++;
}
if ( PerfFreqAdjust || ReduceMag )
{
if ( PerfFreqAdjust > ReduceMag )
ReduceMag = PerfFreqAdjust;
tStart.QuadPart = Int64ShrlMod32(tStart.QuadPart, ReduceMag);
tStop.QuadPart = Int64ShrlMod32(tStop.QuadPart, ReduceMag);
Freq.QuadPart = Int64ShrlMod32(Freq.QuadPart, ReduceMag);
Oht >>= ReduceMag;
}
// Reduced numbers to 32 bits, now can do the math
if ( Freq.LowPart == 0 )
time = 0.0;
else
time = ((double)(tStop.LowPart - tStart.LowPart
- Oht))/Freq.LowPart;
}
else
{
long stime, etime;
SetThreadPriority(GetCurrentThread(),
THREAD_PRIORITY_TIME_CRITICAL);
stime = clock();
(*funcp)();
etime = clock();
SetThreadPriority(GetCurrentThread(), THREAD_PRIORITY_NORMAL);
time = ((double)(etime - stime)) / CLOCKS_PER_SEC;
}
return (time);
}
This paper discusses how the Visual C++ compiler can optimize source code for speed and size and examines the reasons why code size matters. We have gone over the code generation and optimization switches and pragmas supported by Visual C++, how to choose the best switches for your project, and why and how to override them at the function level.
We've learned how to mark DLLs for delayed loading, and we've discussed run-time library issues in the areas of memory allocation, memory copying, and file I/O. Finally, we discussed how to profile your code to locate hot spots, and how to time code accurately.
Truly optimizing your program is, unfortunately, a lot more work than just throwing a compiler switch, even with a great optimizing compiler such as Visual C++. You can get there, though, with good algorithms, good data structures, good code, and an ongoing commitment to performance testing and tuning.
Martin Heller consults, develops software, and writes from Andover, Massachusetts. You can reach him at meh@mheller.com.